-
SpringCloud - Nacos 结合 K8s 优雅关闭服务(平滑升级)
问题描述
在生产环境中使用springcloud框架,由于服务更新过程中,容器服务会被直接停止,部分请求仍被分发到终止的容器,导致服务出现500错误,这部分错误请求数据占用比较少,因为Pod滚动更新都是一对一。因为部分用户会产生服务器错误的情况,考虑使用优雅的终止方式,将错误请求降到最低,直至滚动更新不影响用户。这里结合nacos使用来分析。
在 K8s 的滚动升级中,比如 5 个 Pod 服务在升级过程中,会先启动一半左右(比如:3 个新的启动),然后下线一部分服务……直到所有的旧服务被新服务完全替代,简单粗暴的理解滚动升级。如果我们不涉及 Nacos 还好,因为 K8s 会保证在升级过程中,因为负载的情况很有可能在升级过程中会一部分请求打到旧服务里,但是如果在旧服务准备关闭服务时,旧情求还没返回回去的话就会出现 HTTP 连接关闭情况等一些不可预测的意外发生,导致本次请求的业务失败,这是在生产上绝不能出现的事故。针对 K8s 的优雅关闭问题,我们可以继续往下看,下面会介绍 Nacos & K8s 一个结合优雅关闭的方案。
我们来再谈谈 Nacos 在这里如果无优雅关闭的话会出现的情况,其实和 K8s 的本质很类似,假如我们已经解决了 K8s 的优雅关闭问题,那和 Nacos 之间又有什么联系呢?
我们可以想象下,还是举例上面的 5 个 Pod 的情景,在一个 Pod 启动时,服务的也自然会注册到 Nacos 上去,同理可得,在服务关闭时,Nacos 注册列表里服务也自然会被下线。那么类似的情况也会出现,如果说此时的情求打到旧服务上面,但是由于 Nacos 有监听时间(默认 30s)拉取一次最新情况,以及在每个 Pod 服务里本地也有一份缓存映射表(也有一个窗口时间更新),所以很有可能在这个窗口期之内,还有一些的旧的请求访问负载到旧服务里,但是这里会出现两种情况
- K8s Pod 服务已下线,但是 Nacos 在窗口时间之内注册列表未更新,导致请求达到一个根本不存在的旧服务里
- 旧请求已经打到旧服务里,但是高峰期时,程序处理较慢,还没来及返回响应体,服务就被关闭了
以上这两种情况都会导致本次请求出现失败,生产上更是无语~ 所以我们针对 Nacos 的优雅关闭情况也会有一个解决方案,见“Nacos & K8s 优雅关闭方案”
解决思路
在 K8s 服务滚动升级时,每个 Pod 只需要管好自己如何优雅关闭即可,步骤如下
- 在 K8s 关闭前(preStop 钩子函数配置,在执行关闭服务前执行)先发送给服务进行将它自己在 Nacos 服务列表里的权重设置为 0,这一步为的是在从现在开始,请求再也不会打到本 Pod 上,直到本 Pod 被完全关闭
- 在第 1 步 Nacos 权重为 0 后,因为 Nacos 更新窗口期时间默认 30s 以及每个 Pod 服务里都有一份 Nacos 服务列表映射缓存(也有一个窗口期更新时间);所以我们在权重为 0 后,还需要一定的时间(必须大于 Nacos 窗口期时间)让程序继续跑,为的是处理旧的请求能有时间处理并返回,所以在 preStop 里配置 sleep 睡眠时间让 K8s 关闭机制睡眠一定时间后才开始执行关闭服务命令,这样一来就可以解决我们上述说的 2 个问题,包括 K8s 自己优雅关闭的处理旧请求问题
Ps1:注意上面提到的 Nacos 自己和服务本地的两个窗口时间,所以其实只要将 sleep 时间大于 max(nacos窗口时间,服务本地窗口时间)最大值即可,当然保险起见在这基础上再加一些时间给程序处理旧请求的时间,因为很有可能在 max 最大时间的最后一秒又有一个请求打到旧服务里,所以需要额外再加一点时间
Ps2:当然这里有些人会说为什么不直接用代码执行 Nacos 下线,而是改权重为零呢?其实这个问题是为了保险起见,理论上下线也可以的,只是就怕下线会引起其他一些意外发生,非常熟悉 Nacos 源码可以试试,这边只是改权重是作为保险方案
解决方案
- 服务里需要新增一个 Controller 方法供 K8s Curl 调用
- import com.alibaba.cloud.nacos.NacosDiscoveryProperties;
- import com.alibaba.nacos.api.NacosFactory;
- import com.alibaba.nacos.api.PropertyKeyConst;
- import com.alibaba.nacos.api.exception.NacosException;
- import com.alibaba.nacos.api.naming.NamingService;
- import com.alibaba.nacos.api.naming.pojo.Instance;
- import com.chinadaas.platform.dsp.executor.common.domain.vo.ResultVO;
- import com.chinadaas.platform.dsp.executor.common.util.ResultUtil;
- import lombok.extern.slf4j.Slf4j;
- import org.springframework.web.bind.annotation.PostMapping;
- import org.springframework.web.bind.annotation.RequestMapping;
- import org.springframework.web.bind.annotation.RestController;
- import javax.annotation.Resource;
- import java.util.List;
- import java.util.Properties;
- /**
- * @author Lux Sun
- * @date 2022/8/5
- */
- @Slf4j
- @RestController
- @RequestMapping("/nacos")
- public class NacosController {
- @Resource
- private NacosDiscoveryProperties nacosDiscoveryProperties;
- @PostMapping("/stop")
- public ResultVO
- // 当前 Nacos 权重设为 0
- Properties properties = new Properties();
- properties.put(PropertyKeyConst.NAMESPACE, nacosDiscoveryProperties.getNamespace());
- properties.put(PropertyKeyConst.SERVER_ADDR, nacosDiscoveryProperties.getServerAddr());
- String serviceName = nacosDiscoveryProperties.getService();
- NamingService namingService = NacosFactory.createNamingService(properties);
- List
instanceList = namingService.getAllInstances(serviceName); - for (Instance instance : instanceList) {
- log.info(instance.toString());
- if (instance.getIp().equals(nacosDiscoveryProperties.getIp())) {
- instance.setWeight(0);
- namingService.registerInstance(serviceName, instance);
- }
- }
- log.info("Nacos 服务权重为 0");
- return ResultUtil.buildSucc();
- }
- }
- K8s preStop 执行 Linux 命令,当然这个在【Deployments】里找到对应的服务,点【编辑】即可
curl -X POST 'http://localhost:6060/nacos/stop' && sleep 100 && PID=`pidof java` && kill -SIGTERM $PID && while ps -p $PID > /dev/null; do sleep 1; done;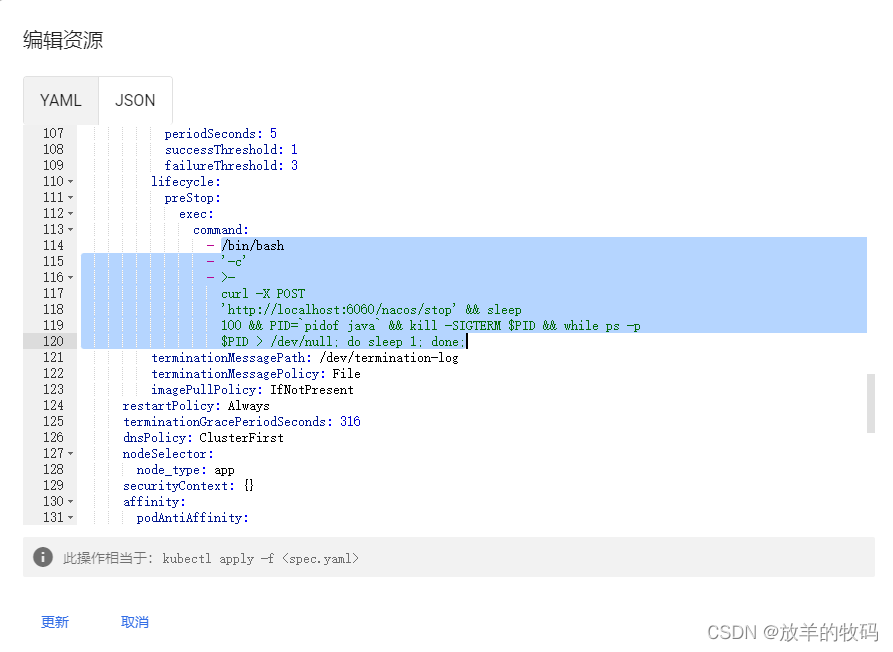
- 你以为这样就完了吗?
- K8s 关闭机制里还有一个重要参数 terminationGracePeriodSeconds(默认 30s),这个参数用来干嘛呢?简而言之,就是 K8s 在执行关闭过程中,因为上面有一些命令需要执行,难免会出现一些意外,导致程序一直卡死在那边,所以 K8s 有一个补偿机制,就是如果关闭流程消耗的时间大于这个参数时间时,马上 K8s 强制关闭,所以这个时间必须大于 sleep 的时间,这可以理解了吧?!
terminationGracePeriodSeconds: 120- terminationGracePeriodSeconds 讲解
在 Kubernetes 中,Pod 停止时 kubelet 会先给容器中的主进程发 SIGTERM 信号来通知进程进行 shutdown 以实现优雅停止,如果超时进程还未完全停止则会使用 SIGKILL 来强行终止,容器终止流程
- 1、Pod 被删除,状态置为 Terminating。
- 2、kube-proxy 更新转发规则,将 Pod 从 service 的 endpoint 列表中摘除掉,新的流量不再转发到该 Pod。
- 3、如果 Pod 配置了 preStop Hook ,将会执行。
- 4、kubelet 对 Pod 中各个 container 发送 SIGTERM 信号以通知容器进程开始优雅停止。
- 5、等待容器进程完全停止,如果在 terminationGracePeriodSeconds 内 (默认 30s) 还未完全停止,就发送 SIGKILL 信号强制杀死进程。
- 6、所有容器进程终止,清理 Pod 资源。
Ps:优雅退出,业务侧需要做的任务是处理SIGTERM信号
进程优雅退出的方法
1、preStop-webhook
- lifecycle:
- preStop:
- exec:
- command:
- - sleep
- - 5s
2、调整优雅终止时间,terminationGracePeriodSeconds 默认是30s。自己视情况而定(terminationGracePeriodSeconds 一定大于 sleep 的时间)
特别说明: preStop Hook 并不会影响 SIGTERM 的处理,因此有可能 preStopHook 还没有执行完就收到 SIGKILL 导致容器强制退出。因此如果 preStop Hook 设置了 n 秒,需要设置terminationGracePeriodSeconds 为 terminationGracePeriodSeconds+n 秒。
更多小知识
- Kubernetes终止生命周期
1 - K8S 启动新POD
2 - K8S等待新POD进入Ready(Running) 状态
3 - K8S创建Endpoint。此时,k8s创建endpoint,将新服务纳入负载均衡
4 - 用户删除pod,Pod设置为”Terminating”状态,并从所有服务的Endpoints列表中删除。此时,Pod停止获得新的流量。但在Pod中运行的容器不会受到影响
5 - preStop Hook被执行。 preStop Hook是一个发送到Pod中的容器特殊命令或Http请求
6 - SIGTERM信号被发送到Pod。 此时,Kubernetes将向pod中的容器发送SIGTERM信号。这个信号让容器知道它们很快就会关闭
7 - Kubernetes等待优雅的终止 此时,Kubernetes等待指定的时间称为优雅终止宽限期。默认情况下,这是30秒。值得注意的是,这与preStop Hook和SIGTERM信号并行发生。Kubernetes不会等待preStop Hook完成
- K8s 部署服务流程图
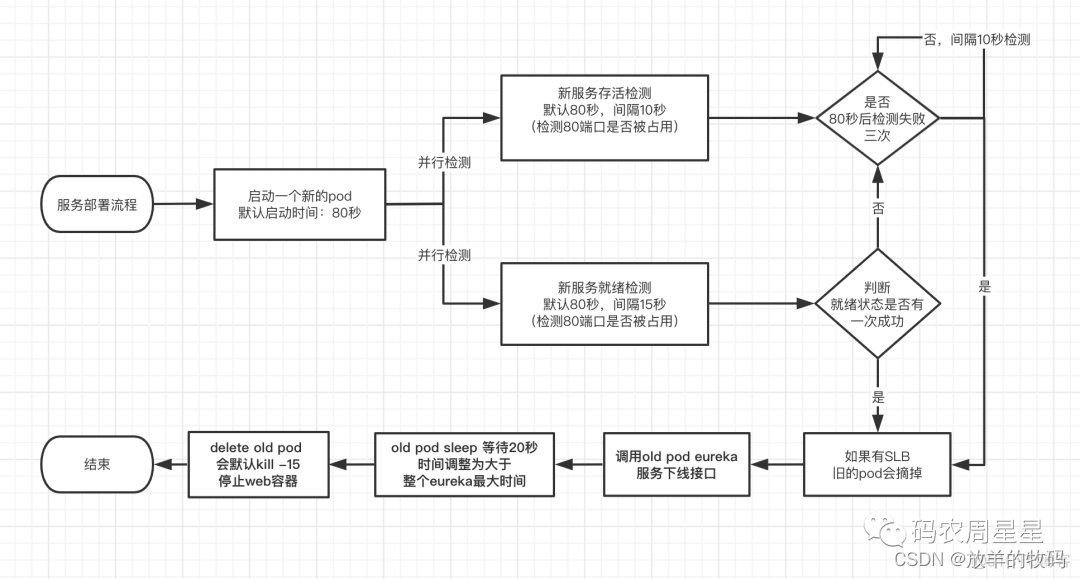
- Nacos 心跳检测时间
Nacos 目前支持临时实例使用心跳上报方式维持活性,发送心跳的周期默认是 5 秒,Nacos 服务端会在 15 秒没收到心跳后将实例设置为不健康,在 30 秒没收到心跳时将这个临时实例摘除。这里要注意30秒这个时间
- Nacos & K8s 正常更新流程
当更新某一个应用时,先给nacos发送这个模块下线通知,等待30s中后再更新这个应用。应用启动时会自动注册到nacos中。现在把该应用部署到k8s中,需要实现上面说的正常更新流程。这里就牵涉到使用k8s中的容器生命周期钩子PreStop。
- Kubernetes 钩子函数
PostStart:这个钩子在容器创建后立即执行。但是并不能保证钩子将在容器ENTRYPOINT之前运行,因为没有参数传递给处理程序。 主要用于资源部署、环境准备等。不过需要注意的是如果钩子花费时间过长以及于不能运行或者挂起,容器将不能达到Running状态。
PreStop:钩子在容器终止前立即被调用。它是阻塞的,意味着它是同步的,所以它必须在删除容器的调用出发之前完成。主要用于优雅关闭应用程序、通知其他系统等。如果钩子在执行期间挂起,Pod阶段将停留在Running状态并且不会达到failed状态
简单说一下 Pod 终止的过程
- 用户发送命令删除 Pod,Pod 进入 Terminating 状态
- service 摘除 Pod 节点
- 当 kubelet 看到 Pod 已被标记终止,开始执行 preStop 钩子,假如 preStop hook 的运行时间超过了 grace period,kubelet 会发送 SIGTERM 并等 2 秒
- K8s Pod Hook 回顾
Pod Hook是由kubelet发起的,当容器中的进程启动前或者容器中的进程终止之前运行,这是包含在容器的生命周期之中。我们可以同时为Pod中的所有容器都配置hook。
在k8s中,理想的状态是pod优雅释放,并产生新的Pod。但是并不是每一个Pod都会这么顺利- Pod卡死,处理不了优雅退出的命令或者操作
- 优雅退出的逻辑有BUG,陷入死循环
- 代码问题,导致执行的命令没有效果
对于以上问题,k8s的Pod终止流程中还有一个"最多可以容忍的时间",即grace period (在pod的.spec.terminationGracePeriodSeconds字段定义),这个值默认是30秒,当我们执行kubectl delete的时候也可以通过--grace-period参数显示指定一个优雅退出时间来覆盖Pod中的配置,如果我们配置的grace period超过时间之后,k8s就只能选择强制kill Pod。
Kubernetes等待指定的时间称为优雅终止宽限期。默认情况下,这是30秒。值得注意的是,这与preStop Hook和SIGTERM信号并行发生。Kubernetes不会等待preStop Hook完成。如果你的应用程序完成关闭并在terminationGracePeriod完成之前退出,Kubernetes会立即进入下一步。
如果您的Pod通常需要超过30秒才能关闭,请确保增加优雅终止宽限期(通过terminationGracePeriodSeconds来实现)
简单的说Kubernetes终止生命周期的每一步
- Pod 设置为Terminating状态,并从所有服务的Endpoints列表中删除
- 此时,Pod停止停止,但是Pod中运行的容器不受影响
- PreStop Hook被执行
- preStop Hook发送容器特殊命令或者Http请求到Pod中,Pod应用程序在接收到SIGTERM(该SIGTERM信号是用于导致程序终止的通用信号。不同于SIGKILL,该信号可以被阻止,处理和忽略。这是礼貌地要求程序终止的正常方法),如果使用第三方代码或者管理系统无法控制,则preStop Hook是在不修改应用程序的情况下触发
- SIGTERM信号发送给Pod
- 此时,Kubernetes将向Pod中的容器发送SIGTERM信号,这个信号即通知容器他们很快将进行关闭。
- Kubernetes等待优雅的终止
- 此时,Kubernetes等待指定的时间称为优雅终止宽限期。默认情况下,这是30秒(可以修改),值得注意的是,PreStop Hook和SIGTREM信息是属于并行执行,Kubernetes不会等待PreStop Hook完成。
如果Pod在terminationGracePeriod完成之前推出,Kubernetes将进如释放阶段,如果容器在优雅终止宽限期(terminationGracePeriod限定时间),则会发送SIGKILL信号并强制删除。与此同时,所有的Kubernetes对象也会被清除
-
相关阅读:
视频融合技术平台解决方案
数组OJ题汇总(一)
【RocketMQ】RocketMQ存储结构设计
【场景化解决方案】构建门店通讯录,“门店通”实现零售门店标准化运营
Apereo CAS反序列化漏洞中数据加解密研究
paho-mqtt 库揭秘
Spring Data【Spring Data Redis、Spring Data ElasticSearch】(二)-全面详解(学习总结---从入门到深化)
【使用Cpolar将Tomcat网页传输到公共互联网上】
【34. 在排序数组中查找元素的第一个和最后一个位置】
浪潮信息面向全行业公布设计指南,以开放规范促进生成式AI多元算力发展
- 原文地址:https://blog.csdn.net/Dream_Weave/article/details/126379544