-
「解析」COCO 数据读取与模型结果解析
最近在学习实例分割,使用的 COCO数据集训练,但是在Github上看到的代码,问题太多了,跑出来的结果简直惨不忍睹,其中模型存在一些问题,但是这次也让我意识到了 辅助代码的重要性,特别是COCO数据集的读取与测试时的解析,真的是一点都不容出错,否则,你会怀疑人生的!
1、json 文件批量转换为 COCO数据集
在训练COCO数据集的时候,一直困惑一个问题,就是类别中的 0 是背景,还是第一个类的标签。此疑惑可以在 coco的 json文件中 或者 labelme 的 labelme2coco.py 中找到答案,
在 labelme2coco.py 中,对 json文件转换时,首先会去除掉
__ignore__标签,然后会看到_background_被置为 0。因此,在后面解析的时候,标签 0 对应的便是背景此外,在使用 labelme 标注数据的时候,需要添加以下两个默认标签
__ignore__ _background_- 1
- 2
在此,建议小伙伴在使用 labelme转化自己制作的数据集时,
data["categories"]中不保存_background_,此目的是为了与 COCO官方数据集的格式保持一致,这样子在训练的时候,基本不需要修改代码,可以省事省力,较为方便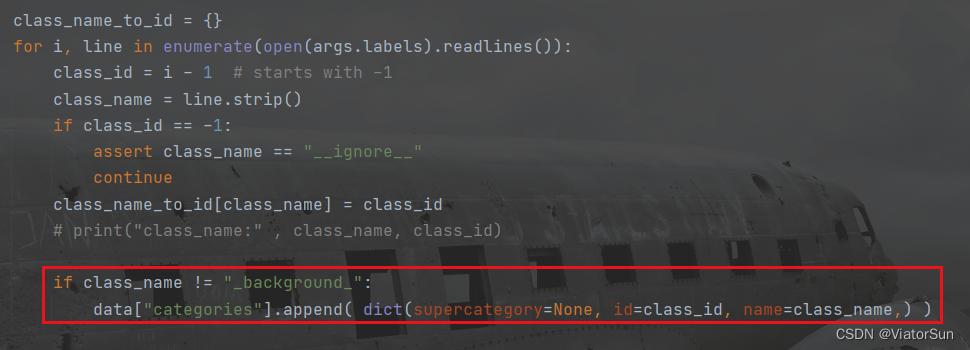
在 COCO2017 数据中,可以看到
categories部分并没有保存背景,而是直接从person: 1开始的

2、COCO 标签映射
细心的小伙伴通过上图,应该可以看出,标签对应的
id并不是连续的 1-80,而是1-90,其中缺少一部分id,在此需要映射下,映射关系可以参考下图,
不过 coco有个好的方法来解决映射问题,在加载 json文件时,通过 enumerate 枚举,让后使其达到上方映射关系,【因为作者训练时使用的类从0开始,背景为 num_class,因此采用的 i,如果小伙伴使用1开始,则采用 i+1 即可】
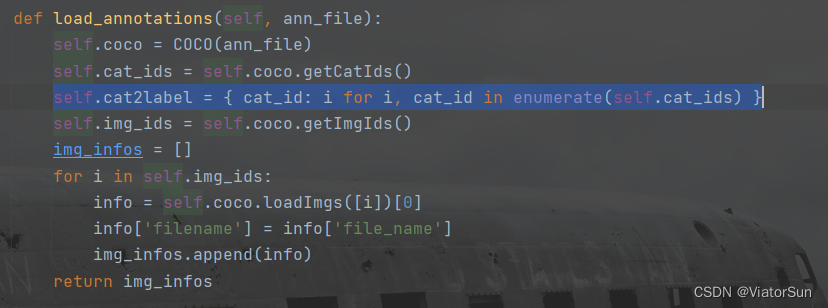
这样,就完成了coco数据集训练前的读取与 映射了
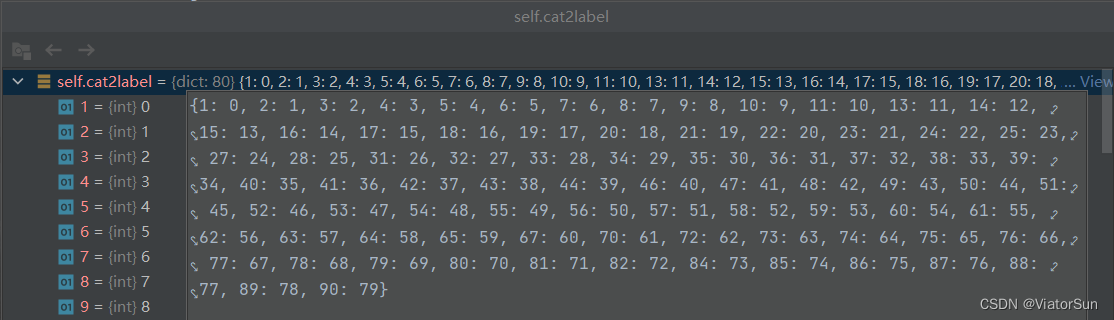
3、coco 数据集训练结果 解析
通过上图,我们可以看到标签在训练时被映射成了连贯的标号,并且有时还是从 0开始,因此,在训练完之后,需要将输出结果进行解析,从
0-num_class-1 ——> 原始标签 id解析的时候,我们需要按照下方的对应关系,进行逆向解析,这样才能得到 正确的标签

在此,作者采用的是下方的代码,进行逆向解析,
result小伙伴们需要根据自己的情况进行修改,下方代码仅做参考def result2json(img_id, result): rel = [] seg_pred = result[0][0].cpu().numpy().astype(np.uint8) cate_label = result[0][1].cpu().numpy().astype(np.int) cate_score = result[0][2].cpu().numpy().astype(np.float) num_ins = seg_pred.shape[0] for j in range(num_ins): realclass = COCO_LABEL_MAP[cate_label[j]] re = {} score = cate_score[j] re["image_id"] = img_id re["category_id"] = int(realclass) re["score"] = float(score) outmask = np.squeeze(seg_pred[j]) outmask = outmask.astype(np.uint8) outmask = np.asfortranarray(outmask) rle = maskutil.encode(outmask) rle['counts'] = rle['counts'].decode('ascii') re["segmentation"] = rle rel.append(re) return rel- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
coco 标签对应中英文名
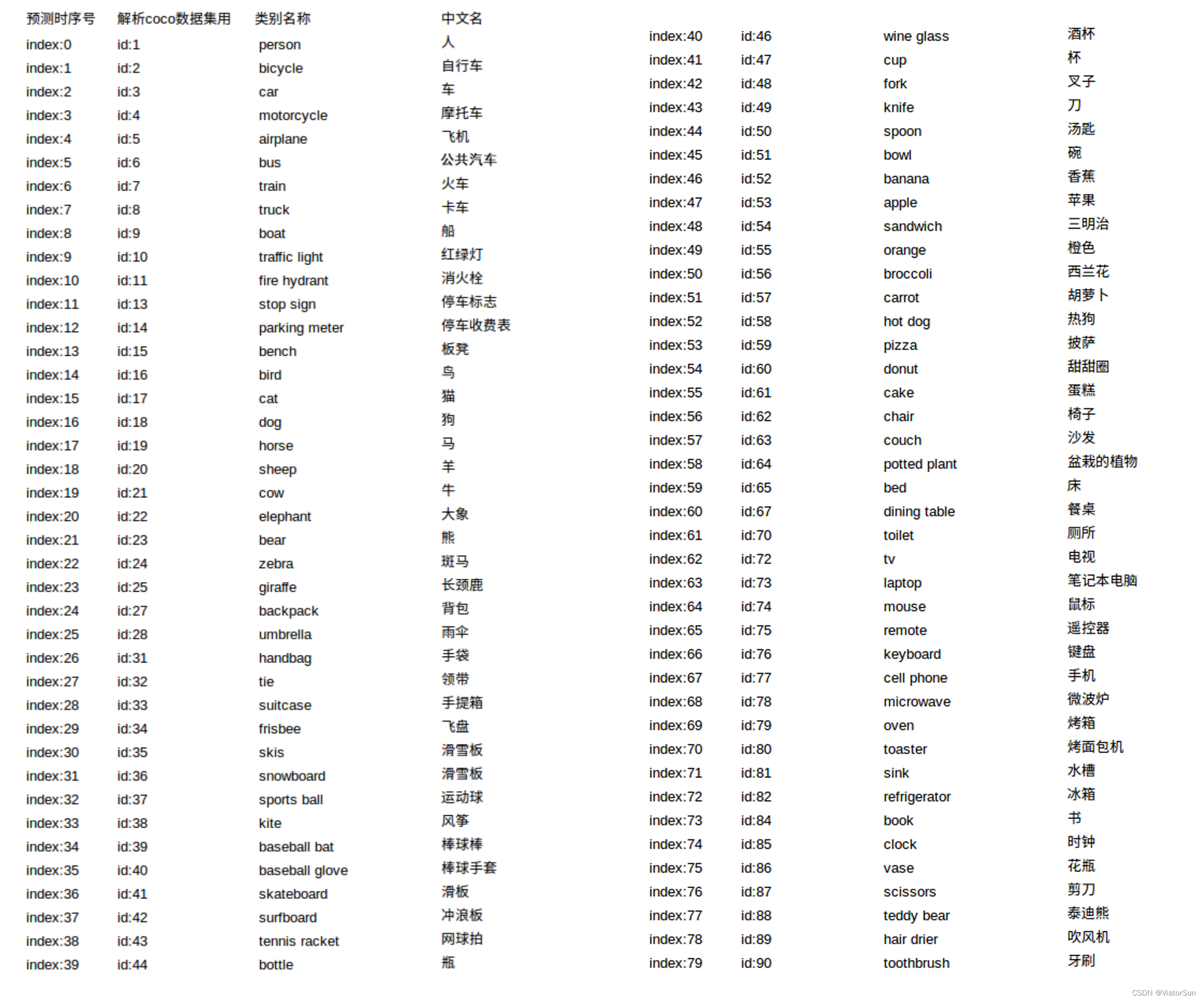
-
相关阅读:
docker安装MySQL
AI入门之深度学习:基本概念篇
8086与8088
【开源分享】基于Html开发的房贷计算器,模仿新浪财经
猕猴桃的红色果肉受到特定的激活-抑制系统的控制
ModStartCMS v4.9.0 用户注册IP,后台登录优化
QChart使用说明
java反射(易懂)
flutter开发实战-应用更新apk下载、安装apk、启动应用实现
Kafka - 3.x 副本不完全指北
- 原文地址:https://blog.csdn.net/ViatorSun/article/details/126326302
