-
Spark基础【RDD依赖关系--源码解析】
一 RDD依赖关系
1 RDD血缘关系
相邻两个RDD之间的关系,称之为依赖关系,多个连续的依赖关系称之为血缘关系
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区
def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[*]").setAppName("WordCount") val sc = new SparkContext(conf) val lines: RDD[String] = sc.textFile("data/word.txt") println(lines.toDebugString) println("******************") /** * (2) data/word.txt MapPartitionsRDD[1] at textFile at Spark01_WordCount_Dep.scala:13 [] * | data/word.txt HadoopRDD[0] at textFile at Spark01_WordCount_Dep.scala:13 [] */ val words: RDD[String] = lines.flatMap(_.split(" ")) println(words.toDebugString) println("******************") /** * (2) MapPartitionsRDD[2] at flatMap at Spark01_WordCount_Dep.scala:17 [] * | data/word.txt MapPartitionsRDD[1] at textFile at Spark01_WordCount_Dep.scala:13 [] * | data/word.txt HadoopRDD[0] at textFile at Spark01_WordCount_Dep.scala:13 [] */ val wordToOne: RDD[(String, Int)] = words.map((_,1)) println(wordToOne.toDebugString) println("******************") /** * (2) MapPartitionsRDD[3] at map at Spark01_WordCount_Dep.scala:21 [] * | MapPartitionsRDD[2] at flatMap at Spark01_WordCount_Dep.scala:17 [] * | data/word.txt MapPartitionsRDD[1] at textFile at Spark01_WordCount_Dep.scala:13 [] * | data/word.txt HadoopRDD[0] at textFile at Spark01_WordCount_Dep.scala:13 [] */ val wordCount: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _) println(wordCount.toDebugString) // +-:shuffle,存在落盘操作,(2)为分区数量 println("******************") /** * (2) ShuffledRDD[4] at reduceByKey at Spark01_WordCount_Dep.scala:25 [] * +-(2) MapPartitionsRDD[3] at map at Spark01_WordCount_Dep.scala:21 [] * | MapPartitionsRDD[2] at flatMap at Spark01_WordCount_Dep.scala:17 [] * | data/word.txt MapPartitionsRDD[1] at textFile at Spark01_WordCount_Dep.scala:13 [] * | data/word.txt HadoopRDD[0] at textFile at Spark01_WordCount_Dep.scala:13 [] */ wordCount.collect().foreach(println) sc.stop() }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
2 RDD依赖关系
所谓的依赖关系,其实就是两个相邻RDD之间的关系
RDD的依赖关系主要分为两大类:
- 窄依赖 OneToOneDependency,上游(旧)RDD一个分区的数据被下游(新)RDD的一个分区独享,多个上游RDD分区的数据被一个下游RDD分区独享,也称之为窄依赖,类比独生子女
- 宽依赖 ShuffleDependency,上游(旧)RDD一个分区的数据被下游(新)RDD的多个分区共享
因为shuffle存在将分区数据打乱重新组合的操作,所以shuffle属于宽依赖,类比二胎三胎
def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[*]").setAppName("WordCount") val sc = new SparkContext(conf) val lines: RDD[String] = sc.textFile("data/word.txt") println(lines.dependencies) println("******************") //List(org.apache.spark.OneToOneDependency@18d910b3) val words: RDD[String] = lines.flatMap(_.split(" ")) println(words.dependencies) println("******************") //List(org.apache.spark.OneToOneDependency@18d910b3) val wordToOne: RDD[(String, Int)] = words.map((_,1)) println(wordToOne.dependencies) println("******************") //List(org.apache.spark.OneToOneDependency@18d910b3) val wordCount: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _) println(wordCount.dependencies) println("******************") //List(org.apache.spark.ShuffleDependency@2daf06fc) wordCount.collect().foreach(println) sc.stop() }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
窄依赖,宽依赖源码
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) { override def getParents(partitionId: Int): List[Int] = List(partitionId) }- 1
- 2
- 3
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag]( @transient private val _rdd: RDD[_ <: Product2[K, V]], val partitioner: Partitioner, val serializer: Serializer = SparkEnv.get.serializer, val keyOrdering: Option[Ordering[K]] = None, val aggregator: Option[Aggregator[K, V, C]] = None, val mapSideCombine: Boolean = false, val shuffleWriterProcessor: ShuffleWriteProcessor = new ShuffleWriteProcessor) extends Dependency[Product2[K, V]]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
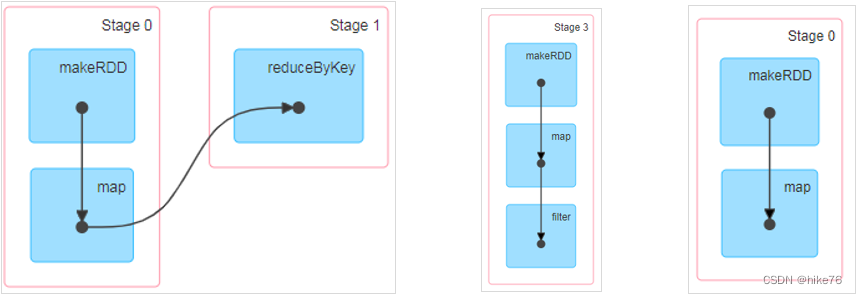
3 RDD阶段划分
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。例如,DAG记录了RDD的转换过程和任务的阶段
主要为shuffle设计,如果存在shuffle,需要一个完整的阶段(resultStage)一分为二,前一个阶段(shuffleMapStage)用于写数据和进行数据的落盘,前一个阶段执行完成才可以进行下一个阶段,resultStage包含shuffleMapStage
阶段划分源码:
private[scheduler] def handleJobSubmitted(jobId: Int, finalRDD: RDD[_], func: (TaskContext, Iterator[_]) => _, partitions: Array[Int], callSite: CallSite, listener: JobListener, properties: Properties): Unit = { // 存储阶段的变量 var finalStage: ResultStage = null try { // New stage creation may throw an exception if, for example, jobs are run on a // HadoopRDD whose underlying HDFS files have been deleted. // 决定阶段如何划分 finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite) } catch { case e: Exception => logWarning("Creating new stage failed due to exception - job: " + jobId, e) listener.jobFailed(e) return } } …… private def createResultStage( rdd: RDD[_], func: (TaskContext, Iterator[_]) => _, partitions: Array[Int], jobId: Int, callSite: CallSite): ResultStage = { // 获取或创建上一级阶段(是否有shuffle,即是否有一分为二的可能) // 传入一个RDD,由runJob传入,而collect方法调用runJob方法 // 所以传入的RDD是当前调用collect方法的RDD(最后一个RDD) val parents = getOrCreateParentStages(rdd, jobId) val id = nextStageId.getAndIncrement() // 不论是否有shuffle,都会存在一个完整的阶段 val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite) stageIdToStage(id) = stage updateJobIdStageIdMaps(jobId, stage) stage } …… private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = { // 获取shuffle依赖,即判断这个RDD是否存在shuffle,返回一个集合,集合调用map方法 // 使得每一个shuffle都执行getOrCreateShuffleMapStage // 执行getShuffleDependencies的结果:parent中的一个依赖转换成getOrCreateShuffleMapStage getShuffleDependencies(rdd).map { shuffleDep => getOrCreateShuffleMapStage(shuffleDep, firstJobId) }.toList } …… private[scheduler] def getShuffleDependencies( // 返回一个集合 rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = { val parents = new HashSet[ShuffleDependency[_, _, _]] val visited = new HashSet[RDD[_]] val waitingForVisit = new Stack[RDD[_]] // 将RDD加入到集合中 waitingForVisit.push(rdd) // 判断集合是否为空 while (waitingForVisit.nonEmpty) { // 获取刚添加的RDD val toVisit = waitingForVisit.pop() // RDD是否被访问过 if (!visited(toVisit)) { // 访问RDD visited += toVisit // 获取调用collect方法的RDD的依赖 toVisit.dependencies.foreach { // 是shuffle,将依赖添加到集合中 case shuffleDep: ShuffleDependency[_, _, _] => parents += shuffleDep case dependency => waitingForVisit.push(dependency.rdd) } } } parents } …… private def getOrCreateShuffleMapStage( shuffleDep: ShuffleDependency[_, _, _], firstJobId: Int): ShuffleMapStage = { shuffleIdToMapStage.get(shuffleDep.shuffleId) match { createShuffleMapStage(shuffleDep, firstJobId) } …… def createShuffleMapStage[K, V, C]( shuffleDep: ShuffleDependency[K, V, C], jobId: Int): ShuffleMapStage = { // 依赖的RDD(调用collec方法RDD的上游RDD) val rdd = shuffleDep.rdd // 此阶段用于shuffle 的 map操作,用于写文件 val stage = new ShuffleMapStage( id, rdd, numTasks, parents, jobId, rdd.creationSite, shuffleDep, mapOutputTracker) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
总结:阶段的数量 = shuffle操作的个数 + 1
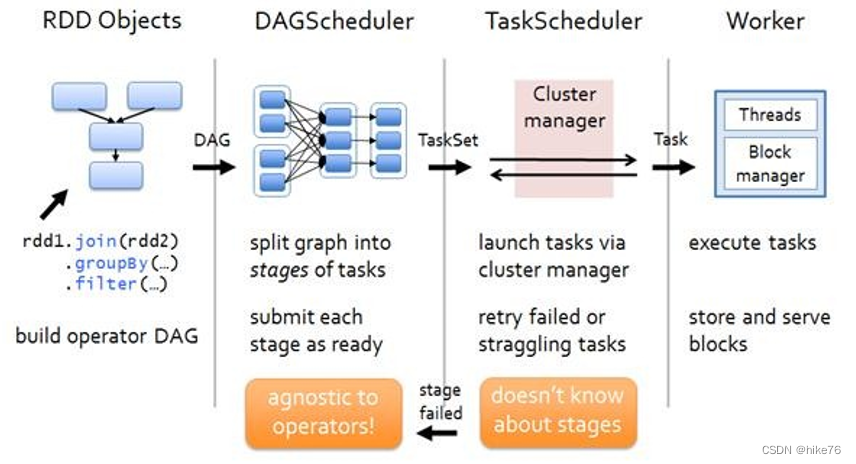
4 RDD任务划分
RDD任务切分中间分为:Application、Job、Stage和Task
- Application:初始化一个SparkContext即生成一个Application;
- Job:一个Action算子就会生成一个Job;
- Stage:Stage等于宽依赖(ShuffleDependency)的个数加1;
- Task:一个Stage阶段中,最后一个RDD的分区个数就是Task的个数。
注意:Application->Job->Stage->Task每一层都是1对n的关系
任务划分源码:
private[scheduler] def handleJobSubmitted(jobId: Int, finalRDD: RDD[_], func: (TaskContext, Iterator[_]) => _, partitions: Array[Int], callSite: CallSite, listener: JobListener, properties: Properties): Unit = { submitStage(finalStage) // var finalStage: ResultStage = null,ResultStage就是调用collect方法的RDD } private def submitStage(stage: Stage): Unit = { val jobId = activeJobForStage(stage) if (jobId.isDefined) { logDebug(s"submitStage($stage (name=${stage.name};" + s"jobs=${stage.jobIds.toSeq.sorted.mkString(",")}))") // 判断当前阶段状态是否合法 if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) { // 获取上一个阶段,resultStage上一个阶段是shuffleMapStage val missing = getMissingParentStages(stage).sortBy(_.id) logDebug("missing: " + missing) // 如果没有上一个阶段 if (missing.isEmpty) { logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents") // 如果为空,提交任务 submitMissingTasks(stage, jobId.get) } else { // 提交上一层阶段shuffleMapStage for (parent <- missing) { // 递归 submitStage(parent) } waitingStages += stage } } } else { abortStage(stage, "No active job for stage " + stage.id, None) } } private def submitMissingTasks(stage: Stage, jobId: Int): Unit = { val tasks: Seq[Task[_]] = try { val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array() stage match { case stage: ShuffleMapStage => stage.pendingPartitions.clear() // partitionsToCompute决定任务的数量 partitionsToCompute.map { id => val locs = taskIdToLocations(id) val part = partitions(id) stage.pendingPartitions += id // 构建任务 new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber, taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId), Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier()) } } val partitionsToCompute: Seq[Int] = stage.findMissingPartitions() override def findMissingPartitions(): Seq[Int] = { mapOutputTrackerMaster .findMissingPartitions(shuffleDep.shuffleId) .getOrElse(0 until numPartitions) } val numPartitions = rdd.partitions.length // 在Stage.scala下,RDD为调用collect方法的RDD- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
总结:任务的数量 = 所有阶段(ResultStage + shuffleMapStage)最后一个RDD的分区数
-
相关阅读:
Uniapp 应用消息通知插件 Ba-Notify
递归-汉罗塔及其变种
WPF退出程序时弹出确认对话框
【算法专题突破】双指针 - 三数之和(7)
HTML小游戏2—— 2048网页版(附完整源码)
c++、php、java、python、javascript对比,同一功能用5种编程语言写一遍,谁才是最好的编程语言?
【计组笔记】04_存储系统(一)
基于C#实现的文件管理文件系统
支持中文!秒建 wiki 知识库的开源项目,构建私人知识网络
AIRIOT答疑第2期|如何使用物联网平台的数据采集与控制引擎?
- 原文地址:https://blog.csdn.net/weixin_43923463/article/details/126331666
