-
8086汇编笔记
寄存器
8086CPU 有 14 个寄存器,每个寄存器有一个名称
这些寄存器分别是 AX、BX、CX、DX、SI、DI、SP、BP、IP、CS、SS、DS、ES、PSW通用寄存器 —— AX、BX、CX、DX
AX 累加寄存器(accumulate register)
BX 基地址寄存器(based register)
CX 计数器 (count register)
DX 数据寄存器(data registered)
这 4 个为 16 位通用寄存器,都可以分别为两个独立的 8 位寄存器来用:- AX 可分为 AH 和 AL;
- BX 可分为 BH 和 BL;
- CX 可分为 CH 和 CL;
- DX 可分为 DH 和 DL;
AH 为 AX 的高 8 位, AL 为 AX 的低 8 位
段寄存器 —— CS、DS、SS、ES
8086 CPU 有 4 个段寄存器CS、DS、SS、ES。当 8086 CPU 要访问内存时由这 4 个 段寄存器提供内存单元的段地址。
CS 代码段寄存器(code segment)
DS 数据段(data segment)
SS 栈段寄存器(stack segment)
ES 附加段寄存器(extra segment)
注: 段寄存器不能使用 ADD、SUB 指令进行修改CS 代码段寄存器 和 IP
CS 为代码段寄存器 (段地址)
IP 位置指针寄存器 (偏移地址)
IP 又称为指令指针寄存器(instructor point),代码在运行时会自动修改 IP 寄存器的值由于 8086 地址总线是有 20 位,可以传送 20 位地址,达到 1MB 寻址能力。 8086 CPU 又是 16 位结构,所以寻址 采用 CS*16 + IP 两个寄存器进行寻址。
而 IP 位置指针寄存器最小可指向 16位 地址,也就是 64KB的内存
CSS*16 + IP: CSS 左移4位 + IPCSS IP 物理地址 0001H 0008H (0001H<<4) + 0008H = 00018H 0022H 0008H (0022H<<4) + 0008H = 00228H 8000H 0008H (8000H<<4) + 0008H = 80008H CS: IP 指向的内存当中的内容会被当做指令来运行
修改 CS、IP 的指令
声明: MOV 指令不能用于设置 CS、IP 寄存器中的值。
若想同时修改 CS、IP 的内容,可用形容:JMP 段地址: 偏移地址
JMP 2AE3H:3H ,执行后:CS=2AE3H,IP=0003H,CPU 将从 2AE33H 地址读取指令。
JMP 3H:0B16H ,执行后:CS=0003H,IP=0B16H,CPU 将从 00B46H 地址读取指令。DS 数据段寄存器 和 [address]
CPU 要读取一个内存单元的时候,必须给出这个内存单元的地址,在8086 中,内存地址由段地址和偏移地址组成。 8086 中有一个 DS 寄存器,通常用来存放要访问数据的段地址。
DS 寄存器的使用
mov ax, 0100H ; mov ds, 0100H # 错误用法,非法操作 mov ds, ax mov al, [0]- 1
- 2
- 3
- 4
说明:
- mov al, 0; 该语句就是从 ds地址段 * 16 + 0 内存中获取数据并传送给 al 寄存器;
- #mov ds, 0100H # 错误用法: 8086 不支持将数据直接送入到 DS 段寄存器的操作,所以使用 mov ds, ax 方法修改 ds 段寄存器
SS 栈段寄存器 和 SP 堆栈指针寄存器
栈有两种操作:入栈和出栈
入栈就是将一个元素放到栈顶,出栈就是从栈顶去除一个元素。栈顶的元素总是最后入栈,需要出栈时,又最新被从栈中取出。栈的这种操作被称为:LIFO(Last In First Out)
SS*16 +SP = 当前栈顶地址, 任意时刻,SS:SP 指向镇定元素
栈操作又出栈POP 和 入栈 PUSH, 入栈和出栈操作会修改 SP 堆栈指针寄存器PUSH 入栈指令执行过程
入栈时栈顶从高地址想低地址方向负增长
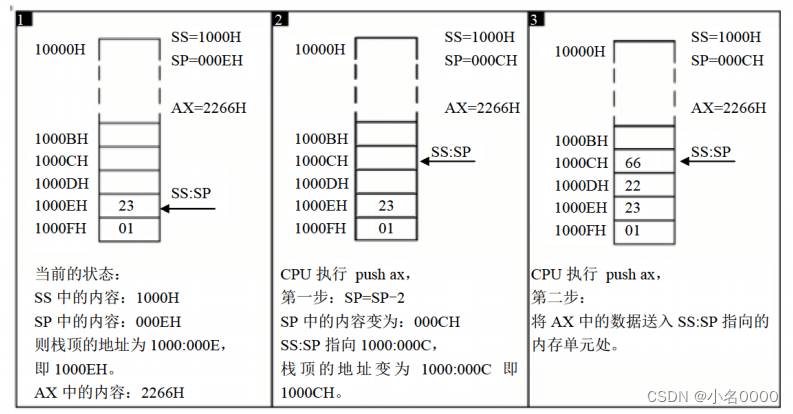
POP 出栈指令执行过程
出栈时栈顶从低地址向高地址方向增长

特殊寄存器 SP、IP、 SI、DI
SP
SP 堆栈指针寄存器(tack point)
SI 和 DI
si 和 di 是 8086 中和 bx 功能相近的寄存器, si 和 di 不能分成两个 8 位寄存器来使用。
数据存取的方式:- mov ax, [bx+idata]
- mov ax, [bx+idata]
- mov ax, [si+idata]
- mov ax, [di+si+idata]
- mov ax, [bx+di+idata]
mov ax, [bx+si+idata] 指令的含义:(ax) = ((ds*16) + (bx) + (si) + idata)
BX、SI、DI、DP 和 寻址方式
BX、SI、DI、DP 这四个寄存器可以用在 […] 中来进行单元的寻址。
正确的寻址方式:- mov ax, [bx]
- mov ax, [bx+si]
- mov ax, [bx+di]
- mov ax, [dp]
- mov ax, [dp+si]
- mov ax, [dp+di]
错误的寻址方式:
- mov ax, [ax]
- mov ax, [cx]
- mov ax, [dx]
- mov ax, [ds]
BX、SI、DI、DP 这四个寄存器可以在 […] 中单个出现,或只能以 4 种组合出现:
- mov ax, [bx]
- mov ax, [di]
- mov ax, [si]
- mov ax, [dp]
- mov ax, [bx + si]
- mov ax, [bx + di]
- mov ax, [dp + si]
- mov ax, [dp + di]
- mov ax, [bx + si + idata]
- mov ax, [bx + di + idata]
- mov ax, [dp + si + idata]
- mov ax, [dp + di + idata]
idata 解释说明立即数
**BX、SI、DI、DP ** 寻址错误组合方式
- mov ax, [di + si]
- mov ax, [bx + dp]
寻址方式:
寻址方式 含义 名称 常用格式举例 [idata] EA = idata; SA = (ds) 直接寻址 [idata] [bx] EA = (bx); SA=(ds) 直接寻址 [bx] [si] EA = (si); SA=(ds) [di] EA = (di); SA=(ds) [bp] EA = (bp); SA=(ds) [bx+idata] EA = (bx) + idata; SA=(ds) 寄存器相对寻址 用于结构体:[bx].idata;
用于数组:idata[si];
用于二维数组:[bx][idata][si+idata] EA = (si) + idata; SA=(ds) [bi+idata] EA = (di) + idata; SA=(ds) [bp+idata] EA = (bp) + idata; SA=(ds) [bx+si] EA = (bx) + (si); SA=(ds) 寄存器相对寻址 用于二维数组:[bx][si] [bx+di] EA = (bx) + (di); SA=(ds) [bp+si] EA = (bp) + (si); SA=(ds) [bp+si] EA = (bp) + (di); SA=(ds) [bx+si+idata] EA = (bx) + (si) + idata;
SA=(ds)相对基址变址寻址 用于表格(结构)中的数组项:[bx].idata[si]
用于二维数组:[bx][si][bx+di+idata] EA = (bx) + (di) + idata;
SA=(ds)[bp+si+idata] EA = (bp) + (si) + idata;
SA=(ds)[bp+di+idata] EA = (bp) + (di) + idata;
SA=(ds)标志寄存器
CPU 内部的寄存器中,有一种特殊的寄存器(对于不同的处理机制,个数和结构都可能不同)具体以下 3 种作用。
- 用来存储相关指令的某种执行结果;
- 用来为 CPU 执行相关指令提供行为依据;
- 用来控制 CPU 的相关工作方式。
flag 和 其它寄存器不一样,其它寄存器用来存放数据的,都是整个寄存器具有一个含义。而 flag 寄存器是按位起作用,也就是说,它的每一个位有专门的意义,记录特定的信息。
8086CPU 的 falg 寄存器的结构图

ZF 标志
flag 的第 6 位是 ZF, 零标志位。它记录相关指令执行后,其结果是否为 0,如果结果为 0, 那么 zf = 1;如果结果不为 0,那么 zf = 0。
对于 zf 的值,我们可以这样看,zf 标记相关指令的计算结果是否为 0,如果为 0,则 zf 要记录下 是0 这样的肯定信息。在计算机中 1 表示逻辑真,表示肯定,所以当结果为 0 的时候 zf = 1,表示” 结果是 0 “。如果结果为 0,则 zf 要记录下” 不是 0 “ 这样的否定信息。在计算机中 0 表示逻辑假,表示否定,所以当结果不为 0的是否 zf = 0,表示 “结果不是 0”。
举例:mov ax, 1 dec ax ; 执行后结果为 0, 则 zf = 1, 表示结果为 0 mov ax, 0 inc ax ; 执行后结果为 1, 则 zf = 0, 表示结果为 1- 1
- 2
- 3
- 4
- 5
注意:
在 8086CPU 的指令集中,有的指令的执行是影响标志寄存器的,比如 add、sub、mul、div、inc、or、and、dec 等,它们大都是运算指令(进行逻辑或算术运算);有的指令执行对标志寄存器没有影响,比如 mov、push、pop 等,它们大都是传送指令。PF 标志
flag 的第 2 位是 PE,奇偶标志位。它记录相关指令执行后,其结果的所有 bit 位中 1 的个数是否位偶数。如果 1 的个数是偶数, pf = 1,反之 pf = 0;
举例:
mov ax, 01B and ax, 10B ; 执行结果11B,则 pf = 1,表述执行结果 1 的数量位偶数 dec ax ; 执行结果10B,则 pf = 0,表述执行结果 1 的数量位奇数- 1
- 2
- 3
SF 标志
flag 的第 7 位是 SF,符号标志位。它记录相关指令后,其结果是否位负数。如果结果为负, sf =1,如果非负数,fs = 0。
计算机中通常用补码表示符号数据。计算机中的额一个数据可以看作是有符号数,也可以看成无符号数。00000001B,可以看作无符号数 1,也可以看作有符号数 +1;
10000001B,可以看作无符号数129,也可以看作有符号数 -127(-127 = ~10000001 + 1)。CF 标志
flag 的 第 0 位 是 CF,进位标志。一般情况下,在进行无符号数运算的时候,它记录了运算结果的最高位有效位向高位的进位制,或从高位的借位值。
对于位数为 N 的无符号数来说,其对应的二进制信息的最高位,即第 N-1 位,就是它的最高有效位,而假想存在的第 N 位,就是相对于最高有效位的更高位

OF 标志
汇编指令
MOV
mov 指令有以下几种形式
传送方式 操作说明 示例 mov 寄存器, 数据 将数据传送到寄存器 mov ax, 08H mov 寄存器1, 寄存器2 将寄存器2中的数据传送到寄存器1中 mov ax, bx mov 寄存器, 内存单元 将内存单元中的数据传送到寄存器中 mov ax, [0] mov 内存单元, 寄存器 将寄存器中的数据传送到内存中 mov [0], ax mov 段寄存器, 寄存器 将寄存器中的数据传送到段寄存器中 mov ds, ax
mov 指令不能修改 cs 寄存器mov 寄存器, 段寄存器 将段寄存器中的数据传送到寄存器中 mov ax, cs
mov ax, dsmov 寄存器
汇编指令 控制CPU完成额操作 用高级语言的语法描述 MOV AX, 18 将 18 送入到寄存器 AX AX = 18 MOV AH, 78H 将 78H 送入到寄存器 AX AX = 0x78 MOV BX, AX 将 寄存器 AX 中的值送入到寄存器 AB BX = AX MOV AL, [0] 将 DS 地址段相对偏 0 个字节内存中的数据送入到 AL AL = address[DS<<4+0] MOV AX, 0100H
MOV DS, AX将 AX 寄存器中的值送入到 DS 寄存器中
错误写法:MOV DS, 1000HDS = AX ADD
加法指令
汇编指令 控制CPU完成额操作 用高级语言语法描述 MOV AX, 18 将 18 送入到寄存器 AX AX = 18 ADD AX, 8 将寄存器 AX 中的值加上 8 AX += 8 ADD AX, B 将 AX 和 BX 中的数值相加,结果存放在 AX 中 AX += BX ADC
adc 是带进位加法指令,它利用了 CF 位上记录的进位值。
指令格式:adc 操作对象1, 操作对象2
功能: 操作对象1 = 操作对象1 + 操作对象2 + CF
比如指令 adc ax, bx 实现的功能是:(ax) = (ax) + (bx) + CFSUB
减法指令
汇编指令 控制CPU完成额操作 用高级语言的语法描述 SUB AX, BX 将 AX 减去 BX 寄存器中的值,然后送入到 AX寄存器中 AX -= BX INC、DEC
inc 增量 increment
inc 自减 decrementinc ax ; ax +=1 dec ax ; ax -= 1- 1
- 2
PUSH 和 POP
PUSH 和 POP 指令有以下几种形式
传送方式 操作说明 示例 push 寄存器 入栈将寄存器中的值送入到栈顶 [SS:SP] = 寄存器
SP += 2push 段寄存器 入栈将寄存器中的值送入到栈顶 [SS:SP] = 段寄存器
SP += 2push 内存单元 入栈将内存单元字中的值送入到栈顶 [SS:SP] = [01000H]
SP += 2push 数据 入栈将数据字值送入到栈顶 [SS:SP] = [01000H]
SP += 2pop 寄存器 出栈将寄存器栈顶中的值传送到寄存器中 寄存器 = [SS:SP]
SP -= 2pop 段寄存器 出栈将寄存器栈顶中的值传送到段寄存器中 [SS:SP] = 段寄存器
SP += 2AND、OR
and 指令: 逻辑与指令,按位进行与运算
or 指令: 逻辑或指令,按位或指令DIV
div 是除法指令,使用 div 做触发的时候因该注意以下问题。
- 除数:有 8 位和 16 位两种,在一个 reg 或内存单元中。
- 被除数:默认是放在 AX 或 DX 和 AX 中,如果除数为 8 位,被除数则为 16 位,默认放在 AX 中存放;如果除数位 16 位, 被除数则为 32 位,在 DX 和 AX 中存放, DX 存放高 16 位, AX 存放低 16 位。
- 结果:如果除数为 8 位,则 AL 存储除法操作的商, AH 存储除法操作的余数;如果除数为 16 位, 则 AX 存储除法操作的商, DX 中存储除法操作的余数。
格式如下:
div reg div 内存单元- 1
- 2
示例:
- div byte ptr ds:[0] 含义:
(al) = (ax) / ((ds)*16+0) 的商
(ah) = (ax) / ((ds)*16+0) 的商 - div word ptr es:[0]
(ax) = [ (dx) * 10000H + (ax) ] / ((es)*16 + 0) 的商
(dx) = [ (dx) * 10000H + (ax) ] * ((es)*16 + 0) 的余数
MUL
mul 指令是应用在做乘法的
mul 指令注意事项:- 两个相乘的数:两个相乘的数,要么都是 8 位,要么都是 16 位。如果是 8 位,一个默认放在 AL 中,零个放在 8 位 reg 或内存字节单元中;如果是 16 位,一个默认在 AX 中, 另一个放在 16位 reg 或 内存字单元中。
- 结果:如果是 8 位乘法,结果默认放在 AX 中;如果是 16 位相乘,结果默认在 DX 中存放,低位在 AX 中放。
格式:
mul reg mul 内存单元- 1
- 2
内存单元可以用不同地 寻址方式给出,比如:
mul byte ptr ds:[0] 含义: (ax) = (al) * ((ds)*16 + 0); mul word ptr ds:[bx+si+8] 含义: (ax) = (ax) * ((ds)*16 +(bx) + (si) + 8) 结果的低 16 位 (ax) = (ax) * ((ds)*16 +(bx) + (si) + 8) 结果的高 16 位- 1
- 2
- 3
- 4
- 5
- 6
示例:
; 8 位数据与 8 位数据相乘,结果存放在 ax中 mov al, 100 ; al = 100 mov ah, 25 ; ah = 25 mul ah ; ax = 100 * 25 ; 16 位数据与 16 位数据相乘,结果存放在 dx 和 ax 中 mov ax, 1000 ; ax = 1000 mov bx, 2500 ; bx = 2500 mul bx ; ax = (1000 * 2500) & 0xFFFF ; dx = (1000 * 2500) >> 15- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
转移指令(OFFSET、JMP、JCXZ, LOOP)
8086 中 转移行为分为以下几类:
- 只修改 IP 时,称为段内转移,比如 jmp ax;
- 同时修改 CS 和 IP 时,称为段间转移,比如: jmp 1000:0
由于转移指令对 IP 的修改范围不同,段转移又分为:短转移 和 近转移
- 短转移 IP 的修改范围为 -128 ~ 127
- 近转移 IP 的修改分为时 -32768 ~ 32768。
8086 的转移指令分为为以下几类: - 无条件转移指令(如: jmp)
- 条件转移指令
- 循环指令(如:loop)
- 过程
- 中断
OFFSET
操作符 offset 在汇编语言中时编译器处理的符号,它的功能时获取标号的偏移地址。
比如:assume cs: codesg codesg segment: start: mov ax, offset start ; 相当于 mov ax, 0 s: mov ax, offset s ; 相当于 mov ax, 3 codesg ends end start- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
JMP
无条件转移指令,又称为短转移,可以只修改 IP, 也可以同时修改 CS 和 IP。
jmp 指令要给出两种信息:- 转移的目的地址
- 转移的距离(段间转移、段内转移、段内近转移)
不同的给出目的的地址方法,和不同的转移地址,对应不同格式 jmp 指令
jmp short 标号(转到标号出指令指令)
这种格式的 jmp 指令实现的时段内转移,它对 IP 的修改范围为 -128 ~ 127,也就是说,它向前转移最多越过 128 个字节,向后转移最多越过 127 个字节。short 说明指令进行短转移。 标号 指令了转移的目的地
示例:assume cs: codesg codesg segment start: mov ax, 0 jmp short s add ax, 1 s: inc ax codesg ends end start- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
上面的代码的执行结束后 ax 的值 为 1,因为代码执 jmp short s 结束后将改变 IP 寄存器指向 s 代码短的首地址,从而运行 inc ax
jmp near ptr 标号(段内转移)
near ptr 标号实现的时段内近转移,对 IP 的操作: (IP) = (IP) + 16 位位移操作
- 16 位位移 = 标号出的地址 -jmp 指令后的第一个自己的地址;
- near ptr 指明此处的位移位 16 位位移,进行的时段内近转移
- 16 位位移的范围位 -32768 ~ 32767,用补码表示
- 16 位位移由编译程序在编译时算出。
jmp word ptr 内存单元地址(段内转移)
jmp word ptr 内存单元地址(段内转移)
功能:从内存单元地址出开始存放一个字,时转移的目的的偏移地址mov ax, 0123H mov ds:[0], ax jmp word ptr ds:[0]- 1
- 2
- 3
jmp dword ptr 内存单元地址(段键转移)
jmp dword ptr 内存单元地址(段键转移)
功能:从内存单元地址出开始存放两个字,高地址出的字时转移的目的段地址,低地址是转移的目的的偏移地址。
(CS) = (内存单元地址 + 2)
(IP) = (内存单元地址)
比如,下面的指令:mov ax, 0123H mov ds:[0], ax mov word ptr ds:[2], 0 jmp dword ptr ds:[0]- 1
- 2
- 3
- 4
汇编指令 控制CPU完成额操作 用高级语言的语法描述 JMP 2AE3H:3H 将 2AE3H 送入CS寄存器中
将0003H 送入 IP 寄存器中CS = 2AE3H,
IP = 0003HJMP AX 将 AX 寄存器中的值送入到 IP 寄存器 IP = AX JCXZ
jcxz 指令为有条件转移指令,所有的有条件转移指令都是短转移,在对应的机器码中包含转移的位移,而不是目的地址。对应 IP 的修改范围都为: -128 ~ 127。
操作指令格式:jcxz 标号(如果(cx) = 0,转移到标号出执行。
操作:当 (cx) = 0 时, (IP) = (IP) + 8 位位移;
8 位位移 = 标号出的地址 -jcxz 指令后的第一个字节的地址;
8 位位移的范围位 -128 ~ 127,用补码表示;
8 位位移由编译器程序在编译时算出。当 (cs) ≠ 0 时,什么也不做(程序向下执行)。
我们从 jcx 的功能可以看出, “ jcxz 标号”的功能相当于:
if( (cs) == 0 ) jmp short 标号;assume cs:code ; @description 找到数据段 2000H 出内存首个数据为 0 的段地址偏移, ; 并存放到 dx 中 code segment start: mov ax, 2000H mov ds, ax mov bx, 0 s: mov ch, 0 mov cl, [bx] jcxz ok ; cx == 0 时,代码段短跳转到 ok 处 inc bx jmp short s ok: mov dx, bx mov ax, 4c00H int 21H code ends end start- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
LOOP
loop 指令为循环指令,所有的循环指令都是 短转移,在对应的机器码中包含转移的位移,而不是目的地址。对 IP 的修改范围都是: -128 ~·127.
指令格式: loop 标号 ((cx)=(cx)-1) ,如果 (cx)≠0 ,转移到标号出执行。
loop 指令操作:- (cx) = (cx) - 1
- 如果 (cx) ≠ 0, (IP) = (IP) + 8 位位移
8 位位移 = 标号出的地址 -loop 指令的第一个地址的字节;
8 位位移的范围为 -128 ~ 127,用补码表示;
8 位位移由编译程序在编译时算出。
如果 (cx)=0 , 什么都不做
loop 指令格式是:loop 标号, CPU 执行 loop 指的时候,要进行两步操作
- (cx) = (cx-1)
- 判断 cx 中的值,不为零则转至标号出执行程序,如果为零则向下执行。
从 loop 的功能可以看出, loop 标号 的功能相当于:
(cx–)–;
if((cx) ≠ 0) jmp short 标号;CALL 和 RET
call 和 ret 指令都是转移指令,他们都修改 IP, 或同时修改 CS 和 IP。它们经常被共同用来实现子程序的设计
ret 和 retf
ret 指令用栈中的数据,修改 IP 的内容,从而实现近转移;
retf 指令用栈中的数据,修改 CS 和 IP 的内容,从而实现远转移。
CPU 执行 ret 指令时,进行下面两步操作:- (IP) = ((ss) * 16 + (sp))
- (sp) = (sp) + 2
上面两句酷似做了:
- pop IP
CPU 执行 retf 指令时,进行下面 4 步操作:
- (IP) = ((ss) * 16 + (sp))
- (sp) = (sp) + 2
- (CS) = ((ss) * 16 + (sp))
- (sp) = (sp) + 2
上面两句酷似做了:
- pop IP
- pop CS
让代码循环执行示例:
assume cs: code stack segment db 16 dup (0) stack ends code segment start: mov ax, stack mov ss, ax mov sp, 16 mov ax, 0 push cs ; 将 (cs)入栈 push offset start ; 将 start 入栈 retf ; pop ip; pop cs; retf执行结束后将跳转到代码开始处 code ends end start- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
call 指令
CPU 执行 call 指令时,进行两步操作
- 将当前 IP 或 CS 和 IP 压入栈中;
- 转移
call 指令不能实现短转移,除此之外,call 指令实现转移的方法和 jmp 指令的原理相同
call 标号
call 标号(将当前的 IP 压栈后,转到标号处执行命令)
cpu 执行此处格式的 call 指令时,进行如下操作:- (sp) = (sp) - 2;
- (IP) = (IP) + 16位位移
16 位位移 = 标号处的地址 -call 指令后的第一个字节的地址;
16 位位移的范围为 -32768 ~ 32767,用补码表示
16 位位移由编译程序在编译时算出。
call far ptr 标号
call far ptr 标号 实现的是段转移。
CPU 执行此种格式的 call 指令是,进行如下操作。- (sp) = (sp) - 2
((ss) * 16 + (sp)) = (CS)
(sp) = (sp) - 2
((ss)*16) + (sp)) = (IP) - (CS) = 标号所在的段的段地址
(IP) = 标号所在的段中的偏移地址
CPU 执行 call far ptr 标号 指令的时候相当于做了:
- pop cs
- pop ip
- jmp far ptr 标号
call 16 位 reg
指令格式: call 16 位 reg
功能:(sp) = (sp) - 2 ((ss) * 16 + (sp)) = (IP) (IP) = (16 位 reg)- 1
- 2
- 3
CPU 执行 call 16 位 reg 指令的时候相当于做了:
- push ip
- jum 16 位 reg
示例:
mov ax, 6 call ax- 1
- 2
call word ptr 内存单元地址
指令格式: call word ptr 内存单元地址
功能:(sp) = (sp) - 2 ((ss) * 16 + (sp)) = (IP) (IP) = (内存单元地址)- 1
- 2
- 3
CPU 执行 call 16 位 reg 指令的时候相当于做了:
- push ip
- jum [内存偏移地址]
示例:
call word ptr [0005H]- 1
call dword ptr 内存单元地址
指令格式:call dword ptr 内存单元地址
将 CS 和 IP 入栈,在进行内短端元地址的跳转
cpu 执行 call dword ptr 内存单元地址 指令时,相当于进行了push CS push IP jmp dword ptr 内存单元地址- 1
- 2
- 3
指令应用示例:
mov sp, 10H mov ax, 0123H mov ds:[0], ax mov dword ptr ds:[2],0 call dword ptr ds:[0] 执行后, (CS)=0, (IP)=0123H, (SP)=0CH- 1
- 2
- 3
- 4
- 5
- 6
- 7
伪指令
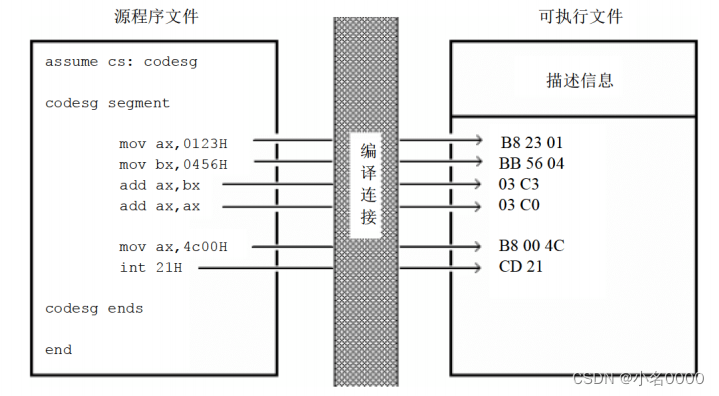
用汇编语言写的源程序,包括汇编指令和伪指令,我们编程的最终目的时让计算机完成一定的任务。程序中的汇编指令组成了最终由计算机执行的程序,而源程序中的伪指令是由编译器来处理的,它们并不实现我们变成的最终目的。这里所说的程序就是指源程序中最终由计算机执行、处理的指令或数据。
注意,将程序文件总的所有内容称为源程序,将源程序中最终由计算机执行、处理的指令或数据,称为程序。程序最先以汇编指令的形式存储在源程序中,经编译、连接后转变为机器码,存储在可执行文件中。
segment、ends
segment 和 ends 是一对成对使用的伪指令,这是在编译器编译的汇编程序时,必须要用到的一对伪指令。segment 和 ends 的功能时定义一段,segment 说明一个段开始,ends 说明一个段结束。一个段必须有一个名称来标识,使用格式为:
段明 segment . . . 段名 ends- 1
- 2
- 3
- 4
- 5
示例:
assume cs: codesg codesg segment mov ax, 0123H mov bx, 0456H add ax, bx add ax, ax mov ax, 4c00H int 21H codesg ends- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
一个汇编程序时有多个段组成的,这些段被用来存放代码、数据或当作栈空间来使用。一个源程序中所有将被计算机处理的信息:指令、数据、栈,被划分到不同的段中。
end
end 是一个汇编程序结束标记,编译器在编译汇编程序的过程中,如果碰到了伪指令 end,就结束对程序的编译。所以,在编写程序的时候,如果程序写完了,要在结尾加上伪指令 end。否则,编译器在编译程序时,无法知道程序在何处结束。
assume
assume 这条伪指令的含义是 “假设” 。它假设某一段寄存器和程序中的某一个用 segment…ends 定义的段相关联。通过 assume 说明这个种关联,在需要的情况下,编译程序可以将段寄存器和某一段具体相联系。assume 并不是一条非要深入理解不可的伪指令,以后编译时,记着用 assume 将有特定用途的段和相关的段寄存器关联起来即可。
start
DW、DB、DD、DUP
dw 指令:定义子类型,dw 即 define word。
db 指令:定义字节变量的定义符,db 即 define byte
dd 指令:定义双字节变量, dd 即 double word
dup 指令: 该指令与 dw、db、dd 伪指令配合使用,用来进行数据重复。; 初始数据段 data segment ; 定义 8 个字型数据 dw 0123H, 0456H, 0798H, 0abcH, 0edfH, 0fedH, 0ebaH, 0987H ; 定义 16 个字节数据类型 db 'welcome to masm!' ; 定义 1 个双字数据类型 dd 1 ; 定义 32 个字类型数据, 初始值都是 0 dw 32 dup (0) ; 定义 9 个字节数据类型,初始值为('abcabcabc') db 3 dup ('abc')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
WORD PTR 和 BYTE PTR
ptr 既 point 的缩写
word ptr :指明了指令寄存器访问的内存单元是一个字单元
byte ptr :指明了指令寄存器访问的内存单元是一个字节单元
示例:- mov word ptr ds:[0], 1
- add byte ptr [bx], 2
程序示例
Hello world!
assume cs: code, ds: data data segment string db 'Hello World!', 13, 10, '$' data ends code segment start: mov ax, data mov ds, ax lea dx, string mov ah, 9 int 21H mov ax, 4c00H int 21H code ends end start- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
函数式编程 - 计算数据 3 次方
计算 data 段第一组数据的 3 次方,结果存放在后面一组 dword 单元中
assume cs:code, ds: data data segment dw 1, 2, 3, 4, 5, 6, 7, 8 dd 16 dup (0) code segment start: mov ax, data mov ds, ax mov si, 0 ; ds:si 指向第一组 word 单元 mov di, 16 ; ds:di 指向的二组 dword 单元 mov cx, 8 s: mov bx, [si] call cube mov [di], ax mov [di+2], dx add si, 2 add di, 4 loop s mov ax, 4c00H int 21H cube: mov ax, bx mul bx mul bx ret code ends end start- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
字符串小写转换为大写字母
assume cs:code, ds: data ; 定义数据段 data segment db 'conversation' data ends code segment start: mov ax, data mov ds, ax mov si, 0 mov cx, 12 call capital mov ax, 4c00H int 21H ; 将小写字母转为大写字母 capital: and byte ptr [si], 11011111B ; 转大写 inc si loop capital ret code ends end start- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
全称
段寄存器:
特殊功能寄存器:
sp——stack point——堆栈指针寄存器
bp——base point——基础指针
si——source index——源变址寄存器
di——destination index——目的变址寄存器
psw——program state word——程序状态字
Psw的常用标志:
OF(11位-overflow flag-溢出标志位)——OV(overflow-溢出)——NV(not overflow-没溢出)
DF(10位-direction flag-方向标志位)——DN(down-下方)——UP(up-上方)
IF(9位-interrupt flag-中断标志位)——EI(enable interrupt-允许中断)——DI(disabled interrupt-不允许中断)
TF(8位-trap flag-陷阱标志位)——
SF(7位-sign flag-负号标志位)——NG(negative-负)——PL(plus-正)
ZF(6位-zero flag-零值标志位)——ZR(zero-为零)——NZ(not zero-不为0)
AF(4位-auxiliary carray flag-辅助进位标志位)——AC(auxiliary carry-有辅助进位)NA(not auxiliary carry-没有辅助进位)
PF(2位-parity flag-奇偶标志位)——PE(parity even-偶)——PO(parity odd-奇)
CF(0位-carry flag-进位标志位)——CY(carried-有进位)——NC(not carried-没进位)
-
相关阅读:
PHP项目学习笔记-萤火商城https://www.yiovo.com/doc
算法自学__线性筛
IO流:字符输入流Reader的超详细用法及底层原理
1.7 C++基础知识_运算符重载_类外函数
【外企面试】Java技术管理与架构面试参考
前端研习录(11)——CSS3新特性——圆角及阴影讲解及示例说明
04 【计算属性 侦听器】
Domino Volt 1.0.5中的可视化流程设计器
ssm工业关键设备监测运维系统毕业设计-附源码191400
C++11 学习之路
- 原文地址:https://blog.csdn.net/qq_41906031/article/details/126237174
