-
MyBatis框架的搭建以及使用教程
MyBatis文章目录
Mybatis框架的搭建以及使用教程
目录
概述:Mapper映射器是 MyBatis 中最重要的文件,文件中包含一组 SQL 语句(例如查询、添加、删除、修改),这些语句称为映射语句或 SQL映射语句
前言
MyBatis是一个开源、轻量级的数据持久化框架,是JDBC和Hibernate的替代方案。MyBatis内部封装了JDBC,简化了加载驱动、创建连接、创建statement等繁杂的过程,开发者只需要关注SQL语句本身。
提示:以下是本篇文章正文内容,下面案例可供参考一、Mybatis框架搭建步骤
第一步:准备工作
1.下载并添加MyBatis依赖包
官网地址:https://github.com/mybatis/mybatis-3/releases
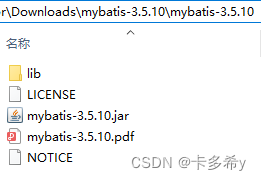
上图中的
mybatis-3.5.10.jar是MyBatis的核心包,mybatis-3.5.10.pdf是MyBatis官方使用手册,lib文件夹下的jar文件是MyBatis的依赖包。我们需要将核心包
mybatis-3.5.10.jar和lib目录下的依赖包,以及MySQL的JDBC驱动包,全部添加至项目构建路径中。2.创建数据库表结构
- DROP TABLE IF EXISTS `website`;
- CREATE TABLE `website` (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `name` varchar(20) COLLATE utf8_unicode_ci NOT NULL,
- `url` varchar(30) COLLATE utf8_unicode_ci DEFAULT '',
- `age` tinyint(3) unsigned NOT NULL,
- `country` char(3) COLLATE utf8_unicode_ci NOT NULL DEFAULT '',
- `createtime` timestamp NULL DEFAULT NULL,
- PRIMARY KEY (`id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
3.创建实体类
在
src目录下创建一个名为com.apesource.entity的包,在该包中创建实体类Website。注意,在类中声明的属性名称与数据表
website的字段名称,保持完全一致。- import java.util.Date;
- public class Website {
- private int id;
- private String name;
- private String url;
- private int age;
- private String country;
- private Date createtime;
- @Override
- public String toString() {
- return "Website [id=" + id + ", name=" + name + ", url=" + url + ", age=" + age + ", country=" + country
- + ", createtime=" + createtime + "]";
- }
- }
第二步:SQL映射文件
在
src目录下创建com.apesource.mapper包,在该包下创建映射文件WebsiteMapper.xml- "1.0" encoding="UTF-8"?>
- mapper
- PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
- "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
- <mapper namespace="com.apesource.mapper.WebsiteMapper">
- <insert id="insertWebsite" parameterType="com.apesource.entity.Website">
- insert into website
- (name,url,age,country)
- values(#{name},#{url},#{age},#{country})
- insert>
- <select id="selectAllWebsite"
- resultType="com.apesource.entity.Website">
- select * from website
- select>
- mapper>
namespace属性,该属性值通常设置为“包名+SQL映射文件名”,用于指定唯一的命名空间。子元素
、在定义的
SQL语句中,“#{}”表示一个占位符,相当于“?”,而“#{name}”表示该占位符用于接收参数中的名称为name的参数值。第三步:核心配置文件
MyBatis核心配置文件主要用于配置数据库连接和MyBatis运行时所需的各种特性,包含了设置和影响MyBatis行为的属性。在
src目录下创建MyBatis的核心配置文件mybatis-config.xml,在该文件中配置了数据库环境和映射文件的位置,具体内容如下:- "1.0" encoding="UTF-8"?>
- configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
- "http://mybatis.org/dtd/mybatis-3-config.dtd">
- <configuration>
- <settings>
- <setting name="logImpl" value="LOG4J" />
- settings>
- <environments default="development">
- <environment id="development">
- <transactionManager type="JDBC" />
- <dataSource type="POOLED">
- <property name="driver" value="com.mysql.cj.jdbc.Driver" />
- <property name="url"
- value="jdbc:mysql://localhost:3306/my_db?charset=utf8mb4&useSSL=false&useTimezone=true&serverTimezone=GMT%2B8" />
- <property name="username" value="root" />
- <property name="password" value="......" />
- dataSource>
- environment>
- environments>
- <mappers>
- <mapper resource="com/apesource/mapper/WebsiteMapper.xml" />
- mappers>
- configuration>
第四步:日志文件
MyBatis默认使用log4j输出日志信息,如果开发者需要查看控制台输出的SQL语句,可以在classpath路径下配置其日志文件。在mybatisDemo的src目录下创建log4j.properties文件,其内容如下:- # Global logging configuration
- log4j.rootLogger=ERROR,stdout
- # MyBatis logging configuration...
- log4j.logger.com.apesource=DEBUG
- # Console output...
- log4j.appender.stdout=org.apache.log4j.ConsoleAppender
- log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
- log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
第五步:创建测试类
在
src目录下创建一个名为com.apesource.test的包,在该包中创建MyBatisTest测试类。在测试类中首先使用输入流读取配置文件,然后根据配置信息构建SqlSessionFactory对象。接下来通过SqlSessionFactory对象创建SqlSession对象,并使用SqlSession对象的方法执行数据库操作。- import java.io.IOException;
- import java.io.InputStream;
- import java.util.List;
- import org.apache.ibatis.io.Resources;
- import org.apache.ibatis.session.SqlSession;
- import org.apache.ibatis.session.SqlSessionFactory;
- import org.apache.ibatis.session.SqlSessionFactoryBuilder;
- public class Test {
- public static void main(String[] args) throws IOException {
- // 读取配置文件mybatis-config.xml
- InputStream config = Resources.getResourceAsStream("mybatis-config.xml");
- // 根据配置文件构建SqlSessionFactory
- SqlSessionFactory ssf = new SqlSessionFactoryBuilder().build(config);
- // 通过SqlSessionFactory创建SqlSession
- SqlSession ss = ssf.openSession();
- // SqlSession执行文件中定义的SQL,并返回映射结果
- // 添加网站
- Website website = new Website();
- website.setName("猿究院");
- website.setUrl("https://www.apesource.com");
- website.setAge(21);
- website.setCountry("CN");
- // 执行添加映射操作
- ss.insert("com.apesource.mapper.WebsiteMapper.insertWebsite", website);
- // 执行查询映射操作
- List
listWeb = ss.selectList("com.apesource.mapper.WebsiteMapper.selectAllWebsite"); - for (Website site : listWeb) {
- System.out.println(site);
- }
- // 提交事务
- ss.commit();
- // 关闭 SqlSession
- ss.close();
- }
- }
二、MyBatis核心对象
MyBatis 的核心接口和类包括:
SqlSessionFactoryBuilder、SqlSessionFactory、SqlSession使用步骤:
- 首先,获取
SqlSessionFactoryBuilder对象,可以根据XML配置文件或者Configuration类的实例构建该对象。 - 其次,通过
SqlSessionFactoryBuilder对象来获取SqlSessionFactory对象。 - 最后,获取
SqlSessionFactory对象之后,就可以进一步获取SqlSession实例。SqlSession对象中完全包含以数据库为背景的所有执行 SQL 操作的方法,用该实例可以直接执行已映射的 SQL 语句。
三、MyBatis工具类
基于MyBatis核心对象生命周期与作用域,制作一个MyBatis工具类
- public class MyBatisUtils {
- private static SqlSessionFactory factory = null;
- static {
- String config = "mybatis-config.xml";
- try {
- InputStream in = Resources.getResourceAsStream(config);
- factory = new SqlSessionFactoryBuilder().build(in);
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- public static SqlSession getSqlSession() {
- SqlSession sqlSession = null;
- if (factory != null) {
- sqlSession = factory.openSession();
- }
- return sqlSession;
- }
- }
四、MyBatis Mapper
概述:
Mapper映射器是MyBatis中最重要的文件,文件中包含一组SQL语句(例如查询、添加、删除、修改),这些语句称为映射语句或SQL映射语句1.作用:
- 定义参数类型
- 配置缓存
- 提供
SQL语句和动态SQL - 定义查询结果和
POJO的映射关系
2.实现方式:
- 通过
XML文件方式实现:在xml文件中,使用SQL语句的映射配置。
- <select id="selectPerson" parameterType="int" resultType="hashmap">
- SELECT * FROM PERSON WHERE ID = #{id}
- select>
- <insert id="insertAuthor">
- insert into Author (id,username,password,email,bio)
- values (#{id},#{username},#{password},#{email},#{bio})
- insert>
- <update id="updateAuthor">
- update Author set
- username = #{username},
- password = #{password},
- email = #{email},
- bio = #{bio}
- where id = #{id}
- update>
- <delete id="deleteAuthor">
- delete from Author where id = #{id}
- delete>
通过注解的方式实现:在映射器接口中,使用
@select、@insert等注解进行SQL语句的映射配置- public interface UserMapper{
- @Insert("insert into user(id,name) values(#{id},#{name})")
- public int insert(User user);
- @Select("Select * from user")
- @Results({
- @Result(id = true, column = "id", property = "id"),
- @Result(column = "name", property = "name"),
- @Result(column = "sex", property = "sex"),
- @Result(column = "age", property = "age")
- })
- List
queryAllUser(); - }
SQL语句存在动态SQL或者比较复杂,使用注解写在Java文件里可读性差,且增加了维护的成本。所以一般建议使用XML文件配置的方式,避免重复编写 SQL 语句。3.XML实现映射器
XML定义映射器分为两个部分:接口和XML首先,定义一个映射器接口
WebsiteMapper:- package com.apesource.mapper;
- public interface WebsiteMapper {
- public List
selectAllWebsite(); - }
然后,定义一个
XML映射文件WebsiteMapper.xml:- "1.0" encoding="UTF-8"?>
- PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
"com.apesource.mapper.WebsiteMapper"> resultType="com.apesource.entity.Website">select * from website下面对上述 XML 文件进行讲解。
namespace用来定义命名空间,该命名空间和定义接口的全限定名一致。元素表明这是一条查询语句,id属性 用来标识这条SQL的映射名称。resultType属性表示使用Website类型的对查询结果进行封装。
最后,在
MyBatis配置文件mybatis-config.xml中添加映射文件的引用:<mapper resource="com/apesource/mapper/WebsiteMapper.xml" />测试类:用
SqlSession来获取Mapper,并调用selectAllWebsite()方法,查询所有网站信息。- public class Test {
- public static void main(String[] args) throws IOException {
- InputStream config = Resources.getResourceAsStream("mybatis-config.xml");
- SqlSessionFactory ssf = new SqlSessionFactoryBuilder().build(config);
- SqlSession ss = ssf.openSession();
- WebsiteMapper websiteMapper = ss.getMapper(WebsiteMapper.class);
- List
websitelist = websiteMapper.selectAllWebsite(); - for (Website site : websitelist) {
- System.out.println(site);
- }
- ss.commit();
- ss.close();
- }
- }
4.select 标签:
在
MyBatis中,select标签用于映射查询操作。例如- resultType="com.apesource.entity.Website"
- parameterType="string">
- SELECT id,NAME,url FROM website WHERE NAME LIKE CONCAT ('%',#{name},'%')
以上是一个
id为selectWebsiteListLikeName的映射语句,参数类型为string,返回结果类型为Website。执行SQL语句时可以定义参数,参数可以是一个简单的参数类型,例如int、float、String;也可以是一个复杂的参数类型,例如JavaBean、Map等。MyBatis提供了强大的映射规则,执行SQL后,MyBatis会将结果集自动映射到指定的JavaBean中参数的传递使用
#{参数名},相当于告诉MyBatis生成PreparedStatement参数。对于JDBC,该参数会被标识为“?”。以上 SQL 语句如果使用JDBC实现,实现代码如下:- String sql = "SELECT id,NAME,url FROM website WHERE NAME LIKE CONCAT ('%',?,'%')";
- PreparedStatement ps = conn.prepareStatement(sql);
- ps.setString(1,name);
5.传递多个参数:
- 使用
Map传递参数 - 使用注解传递参数
- 使用
JavaBean传递参数
6.区别:
以上
3种方式的区别如下:- 使用
Map传递参数会导致业务可读性的丧失,继而导致后续扩展和维护的困难。 - 使用
@Param注解传递参数会受到参数个数的影响。当n≤5时,它是最佳的传参方式,因为它更加直观;当n>5 时,多个参数将给调用带来困难。 - 当参数个数大于
5个时,建议使用JavaBean方式
7.insert标签:
MyBatisinsert标签用来定义插入语句,执行插入操作。当MyBatis执行完一条插入语句后,就会返回其影响数据库的行数。【示例】
在
WebsiteMapper.xml映射文件中,增加"insertNewWebsite" parameterType="com.apesource.entity.Website"> - insert into website(name,url,age)values(#{name},#{url},#{age})
- 在
WebsiteMapper接口中定义一个insertNewWebsite()方法,代码如下:
public int insertNewWebsite(Website website);8.主键(自动递增)回填:
在某些业务场景下,我们可能需要将这个刚刚生成的主键回填到请求对象(原本不包含主键信息的请求对象)中,供其他业务使用。此时,我们就可以通过在
keyProperty和useGeneratedKeys属性,来实现该功能。- <insert id="insertNewWebsite"
- parameterType="com.apesource.entity.Website"
- useGeneratedKeys="true"
- keyProperty="id">
- insert into website(name,url,age)values(#{name},#{url},#{age})
- insert>
9.自定义主键:
在某些业务场景下,我们可能需要将这个刚刚生成的主键回填到请求对象(原本不包含主键信息的请求对象)中,供其他业务使用。此时,我们就可以通过在
keyProperty和useGeneratedKeys属性,来实现该功能- <insert id="insertNewWebsite"
- parameterType="com.apesource.entity.Website"
- useGeneratedKeys="true"
- keyProperty="id">
- insert into website(name,url,age)values(#{name},#{url},#{age})
- insert>
10.resultMap 元素:
resultMap是MyBatis中最复杂的元素,主要用于解决实体类属性名与数据库表中字段名不一致的情况,可以将查询结果映射成实体对象。11.resultMap元素的构成:
type属性表示需要的实体类,id属性是resultMap的唯一标识。- 子元素
用于配置构造方法。当一个 POJO 没有无参数构造方法时使用。 - 子元素
用于表示哪个列是主键。允许多个主键,多个主键称为联合主键。 - 子元素
用于表示 POJO 和 SQL 列名的映射关系。 - 子元素
、 和 用在级联的情况下。
12.resultType和resultMap的区别:
MyBatis的每一个查询映射的返回类型都是resultMap,只是当我们提供的返回类型是resultType时,MyBatis会自动把对应的值赋给resultType所指定对象的属性,而当我们提供的返回类型是resultMap时,MyBatis会将数据库中的列数据复制到对象的相应属性上,可用于复制查询。需要注意的是,
resultMap和resultType不能同时使用。五、MyBatis 关联查询
1.概述:
关联关系是一个数据库实体的概念,有 3 种级联关系,分别是一对一级联、一对多级联以及多对多级联。例如,一个角色可以分配给多个用户,也可以只分配给一个用户。大部分场景下,我们都需要获取角色信息和用户信息,所以会经常遇见以下 SQL。
- SELECT r.*,u.* FROM t_role r
- INNER JOIN t_user_role ur ON r.id = ur.id
- INNER JOIN t_user u ON ur.user_id = u.id
- WHERE r.id = #{id}
在级联中存在 3 种对应关系。
- 一对多,例如:角色和用户、项目组和软件工程师、用户和收货地址。
- 一对一,例如:商品简介和商品详情、学生基本信息和学籍档案信息。
- 多对多,例如:订单与商品、玩家与组队
2.一对一关联查询:
一对一级联关系在现实生活中是十分常见的,例如:一个学生基本信息对应一个学籍档案。
在
MyBatis中,通过- <association property="studentCard" column="cardId"
- javaType="com.apesource.entity.StudentCard"
- select="com.apesource.mapper.StudentCardMapper.selectStuCardById" />
在
property:指定映射到实体类的对象属性。column:指定表中对应的字段(即查询返回的列名)。javaType:指定映射到实体对象属性的类型。select:指定引入嵌套查询的子 SQL 语句,该属性用于关联映射中的嵌套查询。
一对一关联查询可采用以下两种方式:
- 分步查询,通过两次或多次查询,为一对一关系的实体 Bean 赋值。
- 单步查询,通过关联查询实现。
3.多对多关联查询:
实际应用中,由于多对多的关系比较复杂,会增加理解和关联的复杂度,所以应用较少。
MyBatis没有实现多对多级联,推荐通过两个一对多级联替换多对多级联,以降低关系的复杂度,简化程序。例如,一个订单可以有多种商品,一种商品可以对应多个订单,订单与商品就是多对多的级联关系。可以使用一个中间表(订单记录表)将多对多级联转换成两个一对多的关系。
六、MyBatis 动态SQL
1.概述:
动态 SQL 是
MyBatis的强大特性之一。在JDBC或其它类似的框架中,开发人员通常需要手动拼接SQL语句。根据不同的条件拼接SQL语句是一件极其痛苦的工作。例如,拼接时要确保添加了必要的空格,还要注意去掉列表最后一个列名的逗号。而动态SQL恰好解决了这一问题,可以根据场景动态的构建查询。
动态SQL只有几个基本元素,大量的判断都可以在MyBatis的映射XML文件里配置,以达到许多需要大量代码才能实现的功能。所以,使用动态SQL,可以 大大减少了编写代码的工作量,更体现了MyBatis的灵活性、高度可配置性和可维护性。MyBatis的动态SQL包括以下几种元素,如下所示:元素
作用
备注
if
判断语句
单条件分支判断
choose(when、otherwise)
相当于 Java 中的 switch case 语句
多条件分支判断
where
set辅助元素
用于处理一些SQL拼装问题
foreach
循环语句
在in语句等列举条件常用
2.if 标签:条件判断:
MyBatisif类似于 Java 中的if语句,是MyBatis中最常用的判断语句。使用if标签可以节省许多拼接SQL的工作,把精力集中在XML的维护上。if语句使用方法简单,常常与test属性联合使用。语法如下:- <if test="判断条件">
- SQL语句
- if>
3.choose标签:多重条件分支:
有时候,我们不想使用所有的条件,而只是想从多个条件中选择一个使用。针对这种情况,MyBatis 提供了
choose元素,它有点像 Java 中的switch语句。MyBatis中动态语句Java中的switch-case-default多重分支条件语句。由于MyBatis并没有为if提供对应的else标签,如果想要达到的效果,可以借助动态语句
- <choose>
- <when test="判断条件1">
- SQL语句1
- <when test="判断条件2">
- SQL语句2
- <when test="判断条件3">
- SQL语句3
- <otherwise>
- SQL语句4
- otherwise>
- choose>
SQL语句,SQL语句。这类似于Java的switch语句,switch,case,default。4.where标签:处理查询条件:
如果在多重
if条件的查询过程中,如果在where条件中,没有设置条件1=1那么可能就会变成下面这样一条错误的语句:SELECT id,name,url,age,country FROM website AND name LIKE CONCAT('%',#{name},'%')显然以上语句会出现
SQL语法异常,但加入“1=1”这样的条件又非常奇怪,所以MyBatis提供了where标签。主要用来简化SQL语句中的条件判断,可以自动处理AND/OR条件,语法如下:- <where>
- <if test="判断条件">
- AND/OR ...
- </if>
- </where>
if语句中判断条件为true时,where关键字才会加入到组装的SQL里面,否则就不加入。where会检索语句,它会将where后的第一个SQL条件语句的AND或者OR关键词去掉。5.set标签:动态更新:
在
Mybatis中,update语句可以使用set标签动态更新列。set标签可以为SQL语句动态的添加set关键字,剔除追加到条件末尾多余的逗号。示例
要求:根据
id修改网站名称或者网址等信息- <update id="updateWebsite" parameterType="com.apesource.entity.Website">
- UPDATE website
- <set>
- <if test="name !=null and name!=''">name=#{name},if>
- <if test="url !=null and url!=''">url=#{url},if>
- <if test="age !=null and age!=''">age=#{age},if>
- set>
- where id=#{id}
- update>
6.foreach 标签:迭代遍历:
当
SQL语句中含有in关键字进行列表值匹配时,需要迭代条件集合来生成的情况,可以使用foreach来实现SQL条件的迭代。Mybatisforeach标签用于循环语句,它很好的支持了数据和List、set接口的集合,并对此提供遍历的功能。语法格式如下:- <foreach item="item" index="index" collection="list|array|map key" open="(" separator="," close=")">
- 参数值
- foreach>
foreach标签主要有以下属性,说明如下。item:表示集合中每一个元素进行迭代时的别名。index:指定一个名字,表示在迭代过程中每次迭代到的位置。open:表示该语句以什么开始,既然是 in 条件语句,所以必然以(开始。separator:表示在每次进行迭代之间以什么符号作为分隔符,既然是 in 条件语句,所以必然以,作为分隔符。close:表示该语句以什么结束,既然是 in 条件语句,所以必然以)结束。
使用
foreach标签时,collection属性是必选,但在不同情况下该属性的值是不一样的,主要有以下3种情况:- 如果传入的是单参数且参数类型是一个
List,collection属性值为list。 - 如果传入的是单参数且参数类型是一个
array数组,collection的属性值为array。 - 如果传入的参数是多个,需要把它们封装成一个
Map,当然单参数也可以封装成Map。Map的key是参数名,collection属性值是传入的List或array对象在自己封装的Map中的key。
7.
#{}与${}的区别:默认情况下,使用 #{}参数语法时,MyBatis会创建 PreparedStatement参数占位符,并通过?占位符安全地设置参数。 这样做更安全,更迅速,通常也是首选做法,不过有时你就是想直接在 SQL 语句中直接插入一个不转义的字符串。 比如 ORDER BY 子句,这时候你可以:ORDER BY ${columnName},这个时候${}将直接在SQL语句中进行字符串的拼接。
具体区别点总结如下:
1使用#{}会产生1个?占位符,并使用PreparedStatement进行处理。而${}则进行的是字符串的拼接。
2使用#{}可以预防SQL注入,而${}无法防止SQL注入。
3${}一般用于在SQL中拼接数据库表名、视图或关键字,例如动态使用order by 进行排序时,就需要使用${}来拼接排序字段名称和排序规则。七、MyBatis 批处理
1.概述:
批处理是
JDBC编程中的一种优化手段。JDBC在执行SQL语句时,会将SQL+参数值,利用JDBC驱动包,在底层使用基于TCP协议的网络请求将SQL语句发送到数据库。如果SQL语句数量较多,一次执行一条SQL语句,一方面会减小请求包的有效负载,另一个方面会增加耗费在网络通信上的时间,与执行时间的开销必然加大,影响程序执行的效果与性能。通过批处理的方式,我们就可以在
JDBC客户端缓存多条SQL语句,然后将多条SQL语句以打包的方式,批量发送到数据库执行,这样就可以有效地降低上述两方面的损耗,从而提高系统性能。可以通过
show VARIABLES LIKE 'max_allowed_packet';查看MySQL通信时的最大数据包容量。假设
max_allowed_packet的值为33554432字节,则33554432字节 =32M,也就是规定大小不能超过32M。根据实践经验,批处理最好设置为max_allowed_packet的50%。在结合
MyBatis框架进行批处理操作时,通常使用两种方式:- 使用动态
SQL进行批量添加。 - 使用
MyBatis BATCH模式进行批量添加
2.使用动态SQL进行批量添加
该方式基于
SQL语句中的批量添加数据的语法形式:- INSERT INTO 表名(字段1,字段2,字段3)
- VALUES(值1,值1,值1,),
- (值2,值2,值2,),
- (值3,值3,值3,),
- (值4,值4,值4,),
- (值5,值5,值5,);
按照该语法形式,则
SQL映射接口中insertNewWebsiteBatch方法如下所示:- public interface WebsiteMapper {
- // 批量添加网站信息
- public int insertNewWebsiteBatch(List
websiteList) ; - }
SQL映射文件中的配置如下所示:- <insert id="insertNewWebsiteBatch">
- INSERT INTO website (name, url, age, country, createtime)
- VALUES
- <foreach collection="list" item="website" separator=",">
- (#{website.name},#{website.url},#{website.age},#{website.country},now())
- foreach>
- insert>
测试:
- try (SqlSession sqlSession = MyBatisUtils.getSqlSession();) {
- WebsiteMapper websiteMapper = sqlSession.getMapper(WebsiteMapper.class);
- int r = websiteMapper.insertNewWebsiteBatch(websiteList);
- sqlSession.commit();
- System.out.println("影响行数:" + r);
- }
适用场景:该种方式适合数据量较小的情况下,一次性将
SQL语句全部发送给MySQL执行。如果数据量较大,为了能配合max_allowed_packet参数要求的数据包容量,则需要在批处理的基础上,分批执行SQL语句。3.
MyBatis BATCH模式:该方式基于
MyBatis的BatchExecutor对SQL语句进行批处理执行,由于MySQL的批处理执行机制要求,必须在连接字符串中添加参数rewriteBatchedStatements=true,才可以真正开启批处理机制。1. SqlSession的获取:
由于获取的
SqlSession用于执行批处理,所以获取方式比之前的普通执行方式有所不同,必须设置SqlSessionFactory的ExecutorType,这样在创建SqlSession时,内置的Executor为BatchExecutor。- if (ExecutorType.BATCH == executorType) {
- executor = new BatchExecutor(this, transaction);
- }
所以,执行批处理时,创建
SqlSession的代码如下所示:SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH, false);工具类
MyBatisUtils封装代码如下:- public class MyBatisUtils {
- private static SqlSessionFactory factory = null;
- static {
- try {
- SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
- factory = builder.build(Resources.getResourceAsStream("mybatis-config.xml"));
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- public static SqlSession getSqlSession() {
- SqlSession session = null;
- if(factory != null ) {
- // 创建普通执行模式的SqlSession
- // 该模式下的执行器类型默认为ExecutorType.SIMPLE
- // 所以,使用的Executor执行器对象类型为SimpleExecutor
- session = factory.openSession();
- }
- return session;
- }
- public static SqlSession getBatchSqlSession() {
- SqlSession session = null;
- if(factory != null ) {
- // 创建批处理模式的SqlSession
- // 该模式下的执行器类型默认为ExecutorType.BATCH
- // 所以,使用的Executor执行器对象类型为BatchExecutor
- session = factory.openSession(ExecutorType.BATCH);
- }
- return session;
- }
- }
2. SQL映射
- <insert id="insertNewWebsite"
- parameterType="com.apesource.entity.Website">
- insert into
- website(name,url,age,country,createtime)values(#{name},#{url},#{age},#{country},now())
- </insert>
- // 添加新网站信息
- public int insertNewWebsite(Website site);
3. 批量执行
- try (SqlSession sqlSession = MyBatisUtils.getBatchSqlSession();) {
- WebsiteMapper websiteMapper = sqlSession.getMapper(WebsiteMapper.class);
- // 添加5w条记录
- for (int i = 0; i < 50000; i++) {
- int r = websiteMapper.insertNewWebsite(new Website());
- // 每1000条执行1次批处理
- if (i != 0 && i % 1000 == 0) {
- sqlSession.commit();
- }
- }
- sqlSession.commit();
- }
每
1000条执行1次批处理时,如果执行sqlSession.commit()则代表本次批处理的中的所有SQL语句全部通过Executor一次性发送给MySQL执行,并清除本地缓存与操作。八、MyBatis 缓存
1.概述:
缓存可以将数据保存在内存中,是互联网系统常常用到的。目前流行的缓存服务器有
MongoDB、Redis、Ehcache等。缓存是在计算机内存上保存的数据,读取时无需再从磁盘读入,因此具备快速读取和使用的特点。
和大多数持久化框架一样,MyBatis提供了一级缓存和二级缓存的支持。默认情况下,MyBatis只开启一级缓存。2.一级缓存:
一级缓存是基于
PerpetualCache(MyBatis自带)的HashMap本地缓存,作用范围为SqlSession域内。当sessionflush(刷新)或者close(关闭)之后,该session中所有的cache(缓存)就会被清空。
在参数和 SQL 完全一样的情况下,我们使用同一个SqlSession对象调用同一个mapper的方法,往往只执行一次SQL。因为使用SqlSession第一次查询后,MyBatis会将其放在缓存中,再次查询时,如果没有刷新,并且缓存没有超时的情况下,SqlSession会取出当前缓存的数据,而不会再次发送SQL到数据库。
由于SqlSession是相互隔离的,所以如果你使用不同的SqlSession对象,即使调用相同的Mapper、参数和方法,MyBatis还是会再次发送SQL到数据库执行,返回结果。3.二级缓存:
二级缓存是全局缓存,作用域超出
SqlSession范围之外,可以被所有SqlSession共享。也可以理解为是SqlSessionFactory范围的缓存。二级缓存与一级缓存原理相同,默认也是采用
PerpetualCache,使用HashMap作为存储,不同在于其存储作用域为Mapper(Namespace)范围,并且可自定义存储源,例如Ehcache等第三方中间件。作用域为namespance是指对该namespance对应的配置文件中所有的select操作结果都缓存,这样不同线程之间就可以共用二级缓存。4.二级缓存的执行流程:
- 当一个
sqlseesion执行了一次select后,关闭此session的时候,会将查询结果缓存到二级缓存 - 当另一个
sqlsession执行select时,首先会在一级缓存中找,如果没找到,就回去二级缓存中找,找到了就返回,就不用去数据库了,从而减少了数据库压力提高了性能。
5.二级缓存的配置:
MyBatis的全局缓存配置需要在mybatis-config.xml的settings元素中设置,代码如下:
- <settings>
- <setting name="cacheEnabled" value="true" />
- settings>
- 在
mapperSQL映射文件(如WebsiteMapper.xml)中设置缓存,默认不开启缓存。需要注意的是,二级缓存的作用域是针对mapper的namescape,只有再次在同一个namescape内(com.apesource.mapper.WebsiteMapper)的查询才能共享这个缓存,代码如下:
- <mapper namescape="com.apesource.mapper.WebsiteMapper">
- <cache
- eviction="FIFO"
- flushInterval="60000"
- size="512"
- readOnly="true" />
- ...
- mapper>
属性
说明
eviction
代表的是缓存回收策略,目前 MyBatis 提供以下策略。
- LRU:使用较少,移除最长时间不用的对象;
- FIFO:先进先出,按对象进入缓存的顺序来移除它们;
- SOFT:软引用,移除基于垃圾回收器状态和软引用规则的对象;
- WEAK:弱引用,更积极地移除基于垃圾收集器状态和弱引用规则的对象。
flushInterval
刷新间隔时间,单位为毫秒,这里配置的是 100 秒刷新,如果省略该配置,那么只有当 SQL 被执行的时候才会刷新缓存。
size
引用数目,正整数,代表缓存最多可以存储多少个对象,不宜设置过大。设置过大会导致内存溢出。这里配置的是 1024 个对象。
readOnly
只读,默认值为 false,意味着缓存数据只能读取而不能修改,这样设置的好处是可以快速读取缓存,缺点是没有办法修改缓存。
- 在 SQL映射文件配置支持
cache后,如果需要对个别查询进行调整,可以单独设置cache是否启用,代码如下:
- <select id="selectWebsiteList" resultType="com.apesource.entity.Website" usecache="false">
- ...
- select>
总结
以上就是今天要讲的内容,本文仅仅简单介绍了MyBatis的使用,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Ordinary Java Object,普通的 Java对象)映射成数据库中的记录。
- 相关阅读:
DEJA_VU3D - Cesium功能集 之 069-空间坐标系之包围圆
软考中级-软件设计师-第1章 软件设计师考试介绍
【云原生实战】KubeSphere实战——多租户系统实战
Java-IO流之字符流(下篇)
LTSPICE仿真那些事
SpringCloud系列(13)--Eureka服务名称修改和服务IP显示
Python | 执行shell 命令的几种方法
ES6 入门教程 5 字符串的新增方法 5.7 实例方法:padStart(),padEnd() ~ 5.11 实例方法:at()
vue实现文件上传压缩优化处理
多伦多 Pwn2Own 大赛首日战报!三星 Galaxy S23 被黑两次
- 原文地址:https://blog.csdn.net/qq_17845335/article/details/126351453
