-
java中的IO流
前言
我们不能总操纵内存中的数据,我们也想操纵硬盘上的数据。硬盘上的数据都是储存在文件中的,所以我们首先需要有操作文件的类(File),File类与我们后面要讲到的输入、输出流类的关系是什么呢?可以看一个构造函数来看:

可以看到文件字节输入流Inpustream可以以File对象作为初始化的参数。1、File类
java.io.File类:文件和文件目录路径的抽象表示形式,与平台无关
1.1 构造器
1. public File(String pathname) 以pathname为路径创建File对象,可以是绝对路径或者相对路径,如果 pathname是相对路径,则默认的当前路径在系统属性user.dir中存储。 绝对路径:是一个固定的路径,从盘符开始 相对路径:是相对于某个位置开始 2. public File(String parent,String child) 以parent为父路径,child为子路径创建File对象。 3. public File(File parent,String child) 根据一个父File对象和子文件路径创建File对象- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
构造器创建的文件类型,仍然是内存中的,并不是在内存中。
1.2 相关方法
文件重定向
注意此方法是将文件直接放到另一个文件所在的目录,是整个文件的移动并重命名,里面的内容没有改变。
public boolean renameTo(File dest):把文件重命名为指定的文件路径 比如:file1.renameTo(file2)为例: 要想保证返回true,需要file1在硬盘中是存在的,且file2不能在硬盘中存在。 @Test public void test4(){ File file1 = new File("hello.txt"); File file2 = new File("D:\\io\\hi.txt"); boolean renameTo = file2.renameTo(file1); System.out.println(renameTo); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
判断当前文件的类型/权限:文件或文件夹/是否可读、可写、可隐藏
注意下面的返回值是true的前提是文件是在硬盘当中实际存在的
public boolean isDirectory():判断是否是文件目录 public boolean isFile() :判断是否是文件 public boolean exists() :判断是否存在 public boolean canRead() :判断是否可读 public boolean canWrite() :判断是否可写 public boolean isHidden() :判断是否隐藏- 1
- 2
- 3
- 4
- 5
- 6
创建文件/目录、删除文件/目录(硬盘层面)
这些方法都是无参方法,直接用File对象调用即可。
创建硬盘中对应的文件或文件目录public boolean createNewFile() :创建文件。若文件存在,则不创建,返回false,创建文件如果给的是绝对路劲,则文件的目录一定要存在,此文件才能创建成功。 public boolean mkdir() :创建文件目录。如果此文件目录存在,就不创建了。如果此文件目录的上层目录不存在,也不创建。 public boolean mkdirs() :创建文件目录。如果此文件目录存在,就不创建了。如果上层文件目录不存在,一并创建 删除磁盘中的文件或文件目录 public boolean delete():删除文件或者文件夹 删除注意事项:Java中的删除不走回收站。- 1
- 2
- 3
- 4
- 5
- 6
- 7
总结
File类中涉及到关于文件或文件目录的创建、删除、重命名、修改时间、文件大小等方法,
并未涉及到写入或读取文件内容的操作。如果需要读取或写入文件内容,必须使用IO流来完成。
后续File类的对象常会作为参数传递到流的构造器中,指明读取或写入的"终点".IO流
Java程序中,对于数据的输入/输出操作以“流(stream)” 的方式进行。
IO流分类

其中节点流又称为文件流。对于节点流与文件流的定义:**节点流是直接从数据源或目的地读写数据。**这一点是相对于处理流来说的,处理流是是“连接”在已存在的流(节点流或处理流)之上,通过对数据的处理为程序提供更为强大的读写功能

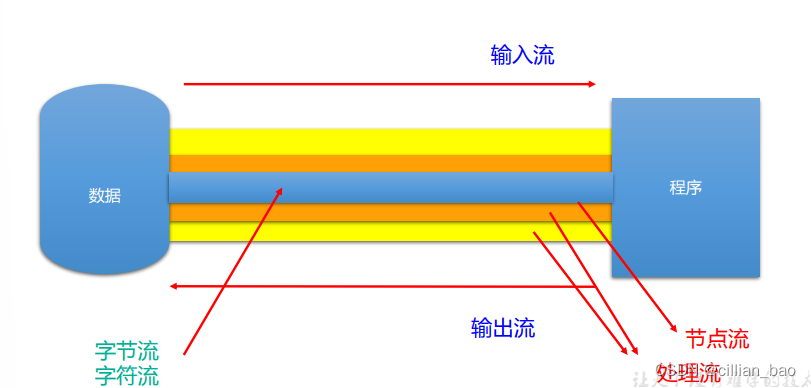
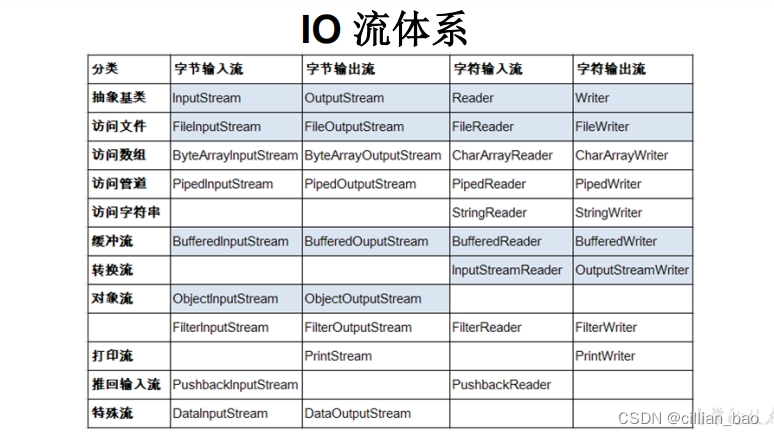
重点为阴影部分。

对于字节流,我们在读取与输出的时候要注意强制类型转换,否则会引起乱码。
区分字符流与字节流的原因(他们各有利弊):
字符流是由 Java 虚拟机将字节转换得到的,这个过程还算是比较耗时。
如果我们不知道编码类型就很容易出现乱码问题。unicode狭义来说只是一个字符集,而utf-8是编码规则,通俗说UTF-8是Unicode的一种实现方式,Unicode有多种实现方式,还有ucs-2(utf-16)。编码规则才涉及到字节的问题。答案中说unicode中中文是两个字节,这句话是不严谨的。因为Unicode只是字符集,是ucs-2这种编码方式中中文是两个字节
文件流
FileReader读入类(Extends InputStreamReader)
FileReader从上图中可以看出是字符输入流,该类继承于InputStreamReader。
该类除了构造方法之外其余所有的方法都直接继承,并没有重写父类中的方法。
FileReader的创建会导致IoException异常,这个异常使用什么类型的好呢?throws还是try… catch,try…catch更好,防止流在中间阻塞,而最后没有关闭,会导致内存的泄露。
操作的几个步骤:- 首先进行读入操作,需要有文件对象(万事万物皆对象)File类实例化
- 真正读入操作是需要用流的,流的实例化
- 具体的操作
- 资源的关闭(流资源的关闭)
read方法的使用
有相应的重载方法。
FileWriter写出类
从内存中写出数据到硬盘的文件里。
说明:- 输出操作,对应的File可以不存在的。并不会报异常
- File对应的硬盘中的文件如果不存在,在输出的过程中,会自动创建此文件。
File对应的硬盘中的文件如果存在:
如果流使用的构造器是:FileWriter(file,false) / FileWriter(file):对原有文件的覆盖
如果流使用的构造器是:FileWriter(file,true):不会对原有文件覆盖,而是在原有文件基础上追加内容
联合使用FileReader与FileWriter实现字符文件的复制
不能使用字符流处理图片等二进制文件
FileInputStream与FileOutputStream的使用
结论:
- 对于文本文件(.txt,.java,.c,.cpp),使用字符流处理
- 对于非文本文件(.jpg,.mp3,.mp4,.avi,.doc,.ppt,…),使用字节流处理
使用字节流FileInputStream处理文本文件,可能出现乱码。如果文本文件中有中文字符的话,因为在utf8中三个字节表示一个字符,输出的时候会有乱码,但是可以实现复制操作,直接实现文本文件的搬运。
缓冲流
主要是用于提高节点流的操作效率,提高流的读取与写入的速度。
需要先造出节点流,在节点流的基础上造缓冲流。
注意资源关闭的顺序,先关外层的流,再关外层的流,其实关闭外层流的同时,内层流也会自动的进行关闭。关于内层流的关闭,我们可以省略。
能够提高读写速度的原因:内部具有缓冲区。
其内部具有flush()函数,执行清空缓冲区的操作。
达到缓冲大小,自动执行flush()函数
BufferedInputStream是字节缓冲输入流, 从源头(通常是文件)读取数据(字节信息)到内存的过程中不会一个字节一个字节的读取,而是会先将读取到的字节存放在缓存区,并从内部缓冲区中单独读取字节。这样大幅减少了 IO 次数,提高了读取效率。(缓冲区大小默认为8192字节)
BufferedOutputStream 是字节缓冲输出流,其与BufferedInputStream原理类似,操作正好相反。
BufferedReader (字符缓冲输入流)和 BufferedWriter(字符缓冲输出流)类似于 BufferedInputStream(字节缓冲输入流)和BufferedOutputStream(字节缓冲输入流),内部都维护了一个字节数组作为缓冲区。不过,前者主要是用来操作字符信息。转换流
- InputStreamReader:将一个字节的输入流转换为字符的输入流
- OutputStreamWriter:将一个字符的输出流转换为字节的输出流
转换流:属于字符流
作用:提供字节流与字符流之间的转换 - 解码:字节、字节数组 —>字符数组、字符串
- 编码:字符数组、字符串 —> 字节、字节数组
IDEA中的单元测试不支持从控制台输入数据进行测试。
标准输入输出流
System.in:其实是获取了
System.out::实际是用于获取一个 PrintStream对象(PrintStream其实是打印流),print方法实际调用的是 PrintStream 对象的 write 方法,PrintStream 属于字节打印流,与之对应的是 PrintWriter (字符打印流)。PrintStream 是 OutputStream 的子类,PrintWriter 是 Writer 的子类。打印流
可以通过System中的setOut方法进行标准输出流的更改,一般的默认标准输出流是输出到屏幕。
PrintStream ps = null; try { FileOutputStream fos = new FileOutputStream(new File("D:\\IO\\text.txt")); // 创建打印输出流,设置为自动刷新模式(写入换行符或字节 '\n' 时都会刷新输出缓冲区) ps = new PrintStream(fos, true); if (ps != null) {// 把标准输出流(控制台输出)改成文件 System.setOut(ps); } for (int i = 0; i <= 255; i++) { // 输出ASCII字符 System.out.print((char) i); if (i % 50 == 0) { // 每50个数据一行 System.out.println(); // 换行 } } } catch (FileNotFoundException e) { e.printStackTrace(); } finally { if (ps != null) { ps.close(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
数据流
存取基本数据类型与String 类型,使其持久化到硬盘中,在需要的时候在通过相应的方法读取到相应的变量中。
写入与读取数据一致。
刷新操作,会将内存中的数据写入文件。对象流
DataInputstream以及ObjectInputStream,这两个流都属于处理流,需要在文件流的基础上初始化
DataInputstream对于基本数据类型的读取
FileInputStream fileInputStream = new FileInputStream("input.txt"); //必须将fileInputStream作为构造参数才能使用 DataInputStream dataInputStream = new DataInputStream(fileInputStream); //可以读取任意具体的类型数据 dataInputStream.readBoolean(); dataInputStream.readInt(); dataInputStream.readUTF();- 1
- 2
- 3
- 4
- 5
- 6
- 7
ObjectInpustream 对于对象引用类型的读取
ObjectInputStream input = new ObjectInputStream(new FileInputStream("object.data")); MyClass object = (MyClass) input.readObject(); input.close();- 1
- 2
- 3
用于存储和读取基本数据类型数据或对象的处理流。它的强大之处就是可以把Java中的对象写入到数据源中,也能把对象从数据源中还原回来。
对象的序列化机制:对象序列化机制允许把内存中的Java对象转换成平台无关的二进制流,从而允许把这种二进制流持久地保存在磁盘上,或通过网络将这种二进制流传输到另一个网络节点。//当其它程序获取了这种二进制流,就可以恢复成原来的Java对象。
如果想要使得自定义的对象能够进行序列化,需要满足那些要求:
需要我们的对象类实现序列化接口(Serializable接口:一个标识接口,内部没有任何方法)
序列版本号声明:public static final long serialVersionUID=xxxL;- 1
Person需要满足如下的要求,方可序列化
1.需要实现接口:Serializable
2.当前类提供一个全局常量:serialVersionUID
3.除了当前Person类需要实现Serializable接口之外,还必须保证其内部所有属性也必须是可序列化的。(默认情况下,基本数据类型可序列化)
补充:ObjectOutputStream和ObjectInputStream不能序列化static和transient修饰的成员变量RandomAccessFile类(即可输入,也可输出)
RandomAccessFile直接继承于java.lang.Object类,实现了DataInput和DataOutput接口
RandomAccessFile既可以作为一个输入流,又可以 作为一个输出流
如果RandomAccessFile作为输出流时,写出到的文件如果不存在,则在执行过程中自动创建。
如果写出到的文件存在,则会对原有文件内容进行覆盖。(默认情况下,从头覆盖)
可以通过相关的操作,实现RandomAccessFile“插入”数据的效果
其中的seek()功能移动指针方法
比如我们下载文件时候的功能,使用多线程断点下载。
RandomAccessFile 中有一个文件指针用来表示下一个将要被写入或者读取的字节所处的位置。我们可以通过 RandomAccessFile 的 seek(long pos) 方法来设置文件指针的偏移量(距文件开头 pos 个字节处)。如果想要获取文件指针当前的位置的话,可以使用 getFilePointer() 方法。
应用:
RandomAccessFile 比较常见的一个应用就是实现大文件的 断点续传 。何谓断点续传?简单来说就是上传文件中途暂停或失败(比如遇到网络问题)之后,不需要重新上传,只需要上传那些未成功上传的文件分片即可。分片(先将文件切分成多个文件分片)上传是断点续传的基础。常见的IO模型
BIO (Blocking I/O):同步阻塞IO
同步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。在客户端连接数量不高的情况下,是没问题的。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
NIO (Non-blocking/New I/O) 非阻塞IO
对应 java.nio 包,提供了 Channel , Selector,Buffer 等抽象。NIO 中的 N 可以理解为 Non-blocking,不单纯是 New。它是支持面向缓冲的,基于通道的 I/O 操作方法。 对于高负载、高并发的(网络)应用,应使用 NIO 。
Java中的IO是I/O 多路复用模型,不单单是非阻塞IO,同步非阻塞 IO 模型中,应用程序会一直发起 read 调用,等待数据从内核空间拷贝到用户空间的这段时间里,线程依然是阻塞的,直到在内核把数据拷贝到用户空间。相比于同步阻塞 IO 模型,同步非阻塞 IO 模型确实有了很大改进。通过轮询操作,避免了一直阻塞。但是,这种 IO 模型同样存在问题:应用程序不断进行 I/O 系统调用轮询数据是否已经准备好的过程是十分消耗 CPU 资源的。
IO 多路复用模型中,线程首先发起 select 调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。read 调用的过程(数据从内核空间 -> 用户空间)还是阻塞的。
Java 中的 NIO ,有一个非常重要的选择器 ( Selector ) 的概念,也可以被称为 多路复用器。通过它,只需要一个线程便可以管理多个客户端连接。当客户端数据到了之后,才会为其服务
AIO:异步IO模型
异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
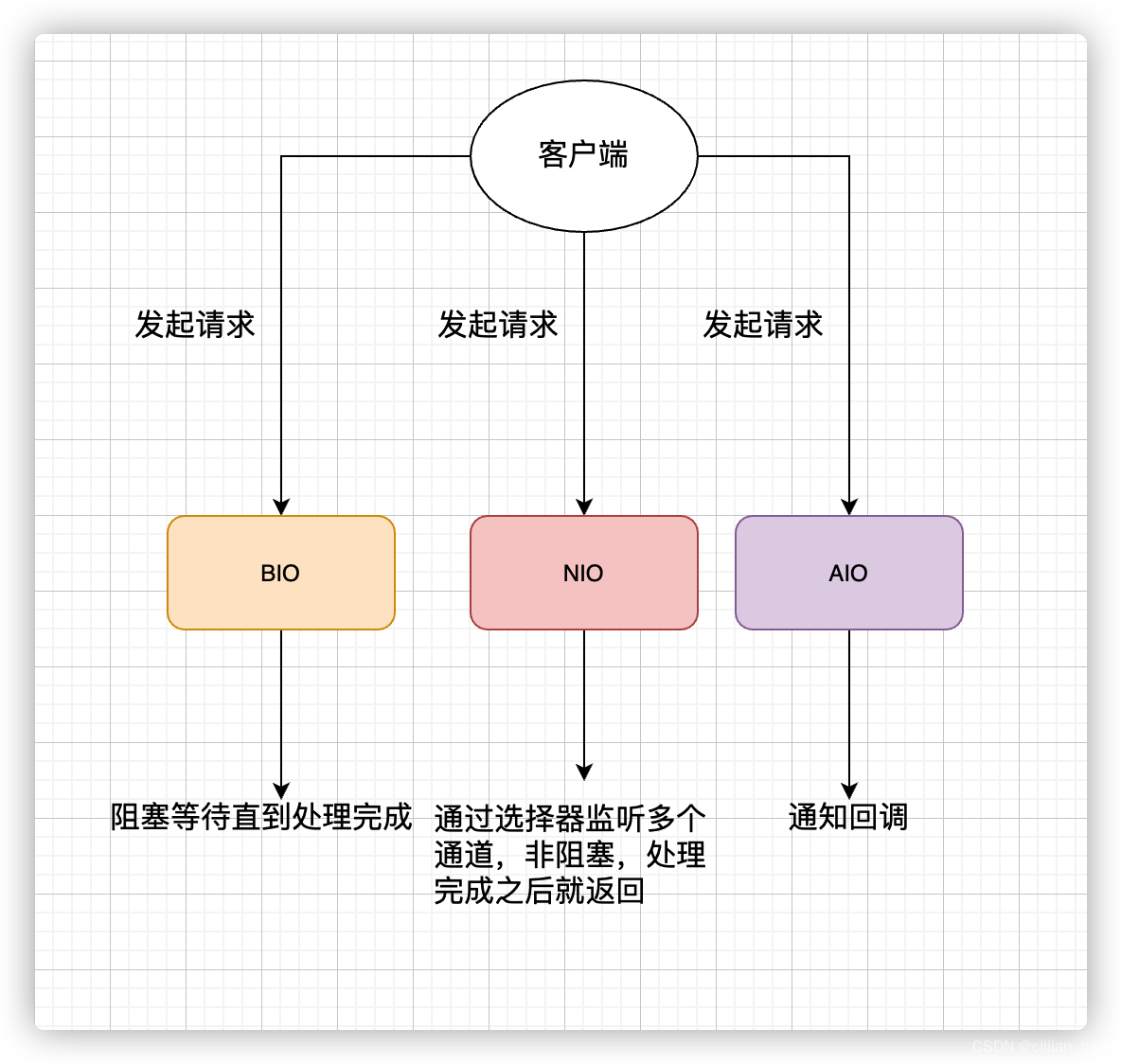
参考
Java IO模型注解:https://javaguide.cn/java/io/io-model.html#aio-asynchronous-i-o
-
相关阅读:
【youcans 的 OpenCV 例程 300篇】244. 特征检测之 BRIEF 特征描述
【学习笔记】深度学习分布式系统
SpringCloud-gateway网关入门使用
【开源】基于正点原子alpha开发板的第三篇系统移植
Ubuntu手动安装Docker
WPF开发经验-实现自带触控键盘的TextBox
老生常谈,永恒之蓝-winxp
3.3日学习打卡----初学Redis(一)
网页JS自动化脚本(七)使用在线jQuery来操作元素
Safari 背景为绿色,设置 Safari 访问页面时的背景颜色 theme-color
- 原文地址:https://blog.csdn.net/cillian_bao/article/details/125488937
