-
B+树索引(2)之索引的推导
B+树索引(2)之索引的推导
一个简单的索引方案
在探寻索引方案时我们思考一个问题,为什么在一个表数据存在多个数据页中时,查询数据都需要遍历所有的数据页呢?因为数据页没有规律性,数据页之间仅仅是通过File Header文件头中的上一页下一页属性关联,自然需要遍历双向链表查询,知道这个后我们可以做如下探索。
演示环境搭建
创建测试表index_test,其中c1定义为主键
mysql> CREATE TABLE index_test( -> c1 INT, -> c2 INT, -> c3 CHAR(1), -> PRIMARY KEY(c1) -> ) ROW_FORMAT = Compact; Query OK, 0 rows affected (0.01 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
行格式结构如下所示
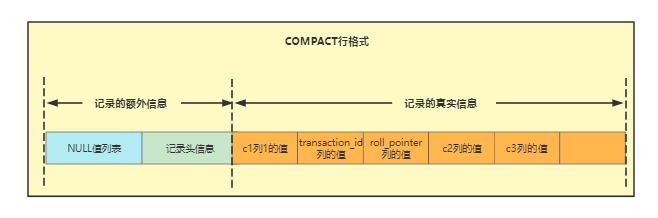
为了后续操作行记录只留取记录头信息中的next_record、record_type两个属性,同时保留记录真实信息中的c1、c2、c3的值结构如下
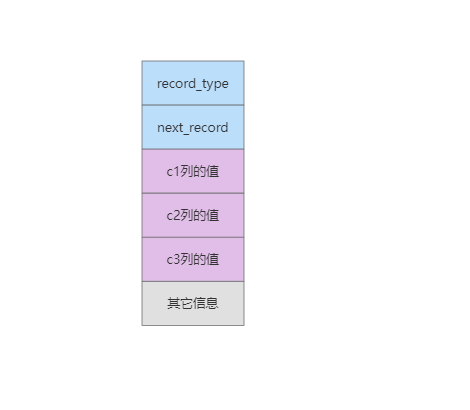
那么一个数据页就可以如下表示
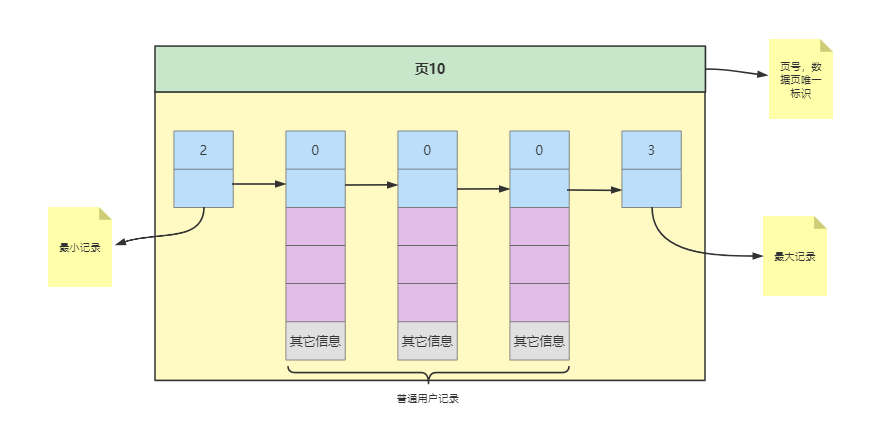
索引方案探索
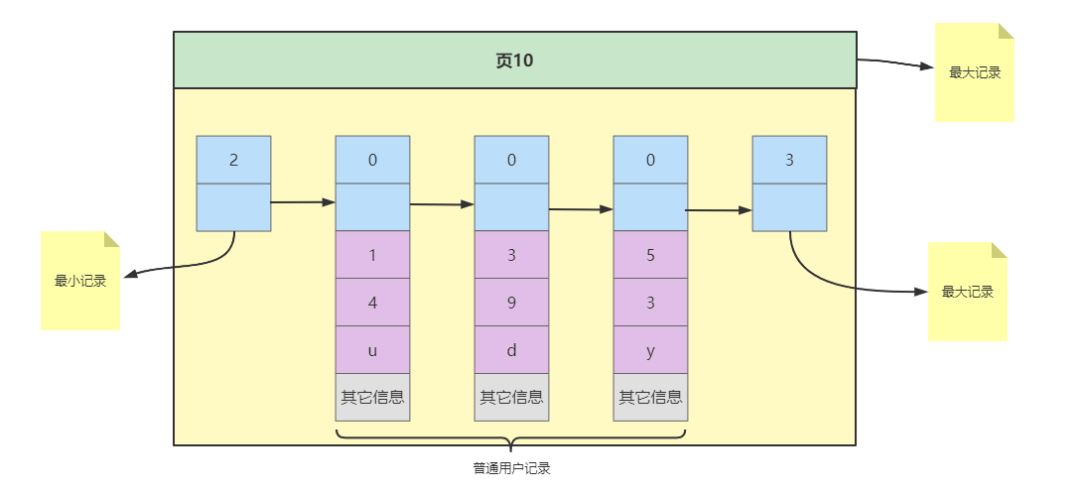
了解完页结构后,我们将测试表中插入三条数据,sql如下
INSERT INTO index_test VALUES(1, 4, 'u'), (3, 9, 'd'), (5, 3, 'y');- 1
这些记录就会在数据页中形成单链表,如下所示
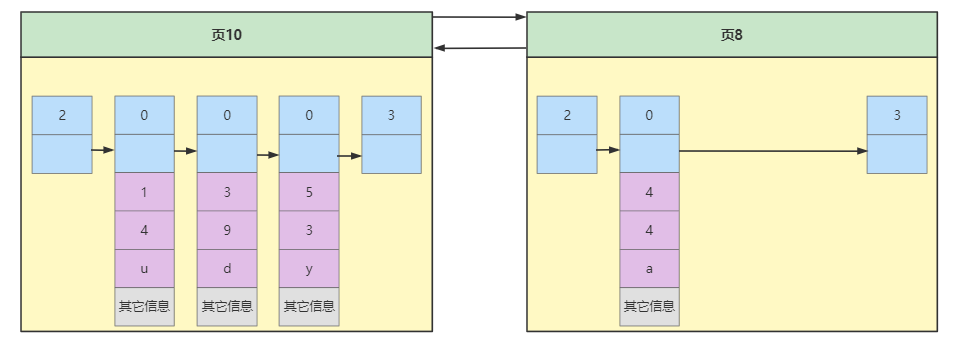
为方便演示假设一个数据页中最多存放3条业务记录,所以当用户再插入一条记录时就需要再申请一个数据页用于存放业务数据,数据页与数据页将会形成双向链表。
INSERT INTO index_test VALUES(4, 4, 'a');- 1
定义规则
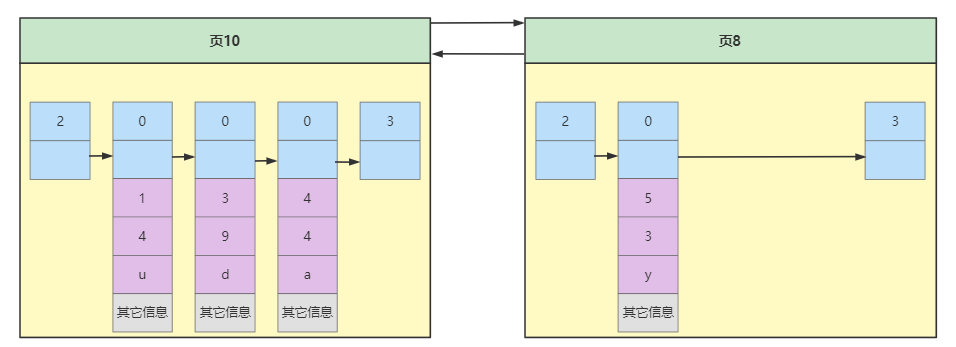
这里需要注意的是分配的空间可能不连续,所以只能通过数据页的File Header的上一页下一页关联,为了让数据页有规律性,那么数据页中的记录显然也是要有规律,我们可以暂定上一页主键的最大值需要小于下一页主键的最小值,上面数据页10的最大主键值为5,数据页8的最大主键值为4,显然不符合这种规定,那么我们就需要将记录转移,使数据页符合规则,这个过程被称为页分裂。最终结果如下
建立目录
数据页之间存在规律后,我们还是不能快速定位到某个数据页,这时我们可以参考数据页中的页目录设计,给所有的数据页设计一个目录,每个目录项分为两部分存放。
-
第一部分取某一页的最小主键值。
-
第二部分取某一数据页的页号。
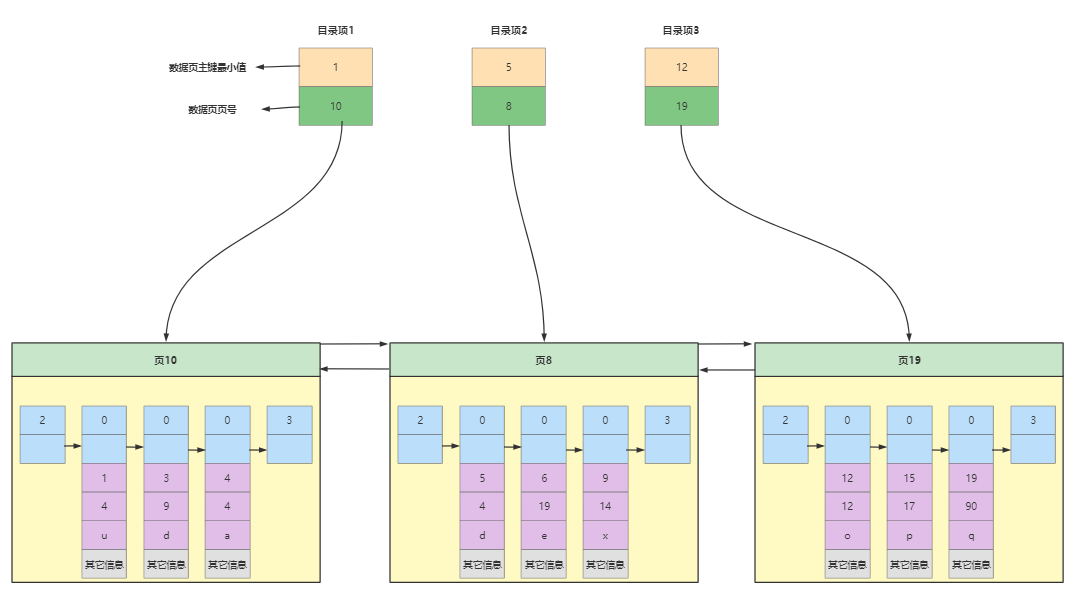
那么数据页的结构就可以变为如下所示
查找演示
到这里查找又变得如此简单,如果需要查询主键值为9的值
-
通过二分法定位到是页8原因是(5 < 9 < 12)。
-
再根据之前提到的数据页中查找记录的方法(二分法)即可得到记录。
这种根据数据页做的目录,我们可以简单称为索引~。
-
相关阅读:
【源码】JavaWeb+Mysql招聘管理系统 课设
JavaScript的Web api接口
基础在线:如何搭建docker环境完整教程和镜像设置
React-Router 5.0 制作导航栏+页面参数传递
python之*用法
面试官:小伙子,说说C/C++是如何进行内存管理的?我:……
解决Pyinstaller打包文件太大的办法(绝对有效,亲测!!!)
〖Python 数据库开发实战 - MySQL篇㊱〗- 综合案例 - 关于数据表 password 字段的数据加密
民安智库(第三方满意度调研公司)医院满意度调查:用数据说话,让服务更贴心
网络原理——No.4 传输层_TCP协议中的延迟应答, 捎带应答, 面向字节流与TCP的异常处理
- 原文地址:https://blog.csdn.net/zzf1233/article/details/126373506