-
Python爬虫xpath语法及案例使用
Python爬虫之xpath语法及案例使用
---- 钢铁侠的知识库 2022.08.15
我们在写Python爬虫时,经常需要对网页提取信息,如果用传统正则表达去写会增加很多工作量,此时需要一种对数据解析的方法,也就是本章要介绍的Xpath表达式。
Xpath是什么
XPath,全称 XML Path Language ,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的搜索。所以在做爬虫时完全可以使用 XPath 做相应的信息抽取。
XPath 的选择功能十分强大,它提供了非常简洁明了的路径选择表达式。另外,它还提供超过 100 个内置函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有想要定位的节点都可以用 XPath 来选取。
下面介绍实战中常用的几个知识点,详细也可以看W3C介绍: XPath 教程
Xpath语法介绍
路径常用规则
表达式 描述 实例 nodename 选取此节点的所有子节点 xpath('//div') 选取了div节点的所有子节点 / 从根节点选取 xpath('/div') 从根节点上选取div节点 // 选取所有当前节点,不考虑位置 xpath('//div') 选取所有的div节点 . 选取当前节点 xpath('./div') 选取当前节点下的div节点 .. 选取当前节点的父节点 xpath('..') 回到上一个节点 @ 选取属性 xpath('//@calss') 选取所有的class属性 谓语规则
谓语被嵌在方括号内,用来查找某个特定的节点或包含某个制定的值的节点
表达式 结果 xpath('/body/div[1]') 选取body下的第一个div节点 xpath('/body/div[last()]') 选取body下最后一个div节点 xpath('/body/div[last()-1]') 选取body下倒数第二个div节点 xpath('/body/div[positon():heart:]') 选取body下前两个div节点 xpath('/body/div[@class]') 选取body下带有class属性的div节点 xpath('/body/div[@class="main"]') 选取body下class属性为main的div节点 xpath('/body/div[price>35.00]') 选取body下price元素值大于35的div节点 通配符
通配符来选取未知的XML元素
表达式 结果 xpath('/div/*') 选取div下的所有子节点 xpath('/div[@*]') 选取所有带属性的div节点 取多个路径
使用“|”运算符可以选取多个路径
表达式 结果 xpath('//div|//table') 选取所有的div和table节点 功能函数
使用功能函数能够更好的进行模糊搜索
函数 用法 解释 starts-with xpath('//div[starts-with(@id,"ma")]') 选取id值以ma开头的div节点 contains xpath('//div[contains(@id,"ma")]') 选取id值包含ma的div节点 and xpath('//div[contains(@id,"ma") and contains(@id,"in")]') 选取id值包含ma和in的div节点 text() xpath('//div[contains(text(),"ma")]') 选取节点文本包含ma的div节点 语法熟悉
下面举一段HTML文本进行语法热身,代码如下
#!/usr/bin/env python # -*- coding: utf-8 -*- # time: 2022/8/8 0:05 # author: gangtie # email: 648403020@qq.com from lxml import etree text = ''' ''' # 调用HTML类进行初始化,这样就成功构造了一个XPath解析对象。 # 利用etree.HTML解析字符串 page = etree.HTML(text) print(type(page))
可以看到打印结果已经变成XML元素:
字符串转换HTML
字符串利用etree.HTML解析成html格式:
print(etree.tostring(page,encoding='utf-8').decode('utf-8')) ``` Process finished with exit code 0 ```经过处理可以看到缺失的
也自动补全了,还自动添加html、body节点。查找绝对路径
通过绝对路径获取a标签的所有内容
a = page.xpath("/html/body/div/ul/li/a") for i in a: print(i.text) ``` first item second item third item None fifth item ```查找相对路径(常用)
查找所有li标签下的a标签内容
html = etree.HTML(text) a = html.xpath("//a/text()") print(a) ``` ['first item', 'second item', 'third item', 'fifth item'] ```当前标签节点
.表示选取当前标签的节点。我们先定位 ul 元素节点得到一个列表,打印当前节点列表得到第一个 ul,
接着打印 ul 节点的子节点 li,text()输出。
page = etree.HTML(text) ul = page.xpath("//ul") print(ul) print(ul[0].xpath(".")) print(ul[0].xpath("./li")) print(ul[0].xpath("./li/a/text()")) ``` [] [ ] [ , , , , ] ['first item', 'second item', 'third item', 'fifth item'] ``` 父节点
..表示选取当前标签的父节点。可以看到得到ul的上一级div
page = etree.HTML(text) ul = page.xpath("//ul") print(ul[0].xpath(".")) print(ul[0].xpath("..")) ``` [] [ ] ``` 属性匹配
匹配时可以用@符号进行属性过滤
查找a标签下属性href值为link2.html的内容
html = etree.HTML(text) a = html.xpath("//a[@href='link2.html']/text()") print(a) ``` ['second item'] ```函数
last():查找最后一个li标签里的a标签的href属性
html = etree.HTML(text) a = html.xpath("//li[last()]/a/text()") print(a) ``` ['fifth item'] ```contains:查找a标签中属性href包含link的节点,并文本输出
html = etree.HTML(text) a = html.xpath("//a[contains(@href, 'link')]/text()") print(a) ``` ['first item', 'second item', 'third item', 'fifth item'] ```实战案例
上面说完基本用法,接下来做几个实战案例练练手。
案例一:豆瓣读书
# -*-coding:utf8 -*- # 1.请求并提取需要的字段 # 2.保存需要的数据 import requests from lxml import etree class DoubanBook(): def __init__(self): self.base_url = 'https://book.douban.com/chart?subcat=all&icn=index-topchart-popular' self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/104.0.0.0 Safari/537.36' } # 请求并提取需要的字段 def crawl(self): res = requests.get(self.base_url, headers=self.headers) lis = etree.HTML(res.text).xpath('//*[@id="content"]/div/div[1]/ul/li') # print(type(lis)) books = [] for li in lis: # print(etree.tostring(li,encoding='utf-8').decode('utf-8')) # print("==================================================") title = "".join(li.xpath(".//a[@class='fleft']/text()")) score = "".join(li.xpath(".//p[@class='clearfix w250']/span[2]/text()")) # list输出带有['\n 刘瑜 / 2022-4 / 广西师范大学出版社 / 82.00元 / 精装\n '] publishing = "".join(li.xpath(".//p[@class='subject-abstract color-gray']/text()")).strip() book = { 'title': title, 'score': score, 'publishing': publishing, } books.append(book) self.save_data(books) def save_data(self, datas): with open('books.txt', 'w', encoding='utf-8') as f: f.write(str(datas)) def run(self): self.crawl() if __name__ == '__main__': DoubanBook().run()案例二:彼岸图片下载
#!/usr/bin/env python # -*- coding: utf-8 -*- # author: 钢铁知识库 # email: 648403020@qq.com import os import requests from lxml import etree # 彼岸图片下载 class BiAn(): def __init__(self): self.url = 'https://pic.netbian.com' self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/104.0.0.0 Safari/537.36', 'cookie': '__yjs_duid=1_cb922eedbda97280755010e53b2caca41659183144320; Hm_lvt_c59f2e992a863c2744e1ba985abaea6c=1649863747,1660203266; zkhanecookieclassrecord=%2C23%2C54%2C55%2C66%2C60%2C; Hm_lpvt_c59f2e992a863c2744e1ba985abaea6c=1660207771; yjs_js_security_passport=1225f36e8501b4d95592e5e7d5202f4081149e51_1630209607_js' } # 如果目录不存在会报错 if not os.path.exists('BianPicture'): os.mkdir('BianPicture') # 请求拿到ul列表 def crawl(self): res = requests.get(self.url, headers=self.headers) res.encoding = 'gbk' uls = etree.HTML(res.text).xpath('//div[@class="slist"]/ul[@class="clearfix"]/li') # print(etree.tostring(uls,encoding='gbk').decode('gbk')) # 循环拿到图片名、图片地址,拼接请求再次下载到图片 for ul in uls: img_name = ul.xpath('.//a/b/text()')[0] img_src = ul.xpath('.//a/span/img/@src')[0] # print(img_name + img_src) img_url = self.url + img_src # 拼接后下载图片,转义Bytes img_res = requests.get(img_url, headers=self.headers).content img_path = "BianPicture/" + img_name + ".jpg" data = { 'img_res': img_res, 'img_path': img_path } self.save_data(data) # 数据保存逻辑 def save_data(self, data): with open(data['img_path'], 'wb') as f: f.write(data['img_res']) # print(data) def run(self): self.crawl() if __name__ == '__main__': BiAn().run()
案例三:全国城市名称爬取
#!/usr/bin/env python # -*- coding: utf-8 -*- # author: 钢铁知识库 # email: 648403020@qq.com import os import requests from lxml import etree class CityName(): def __init__(self): self.url = 'https://www.aqistudy.cn/historydata/' self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36' } # 判断目录是否存在 if not os.path.exists('city_project'): os.mkdir('city_project') def crawl(self): res = requests.get(url=self.url, headers=self.headers).text uls = etree.HTML(res).xpath('//div[@class="all"]/div[2]/ul/div[2]/li') all_city_name = list() for ul in uls: city_name = ul.xpath('.//a/text()')[0] # print(type(city_name)) all_city_name.append(city_name) self.save_data(all_city_name) def save_data(self, data): with open('./city_project/city.txt', 'w') as f: f.write(str(data)) def run(self): self.crawl() if __name__ == '__main__': CityName().run()xpath使用工具
chrome生成XPath表达式
经常使用chome的朋友都应该知道这功能,在
审查状态下(快捷键ctrl+shift+i,F12),定位到元素(快捷键ctrl+shift+c) ,在Elements选项卡中,右键元素 Copy->Copy xpath,就能得到该元素的xpath了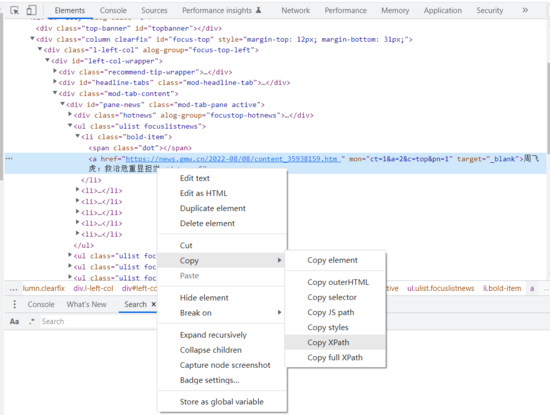
Xpath Helper插件
为chome装上XPath Helper就可以很轻松的检验自己的xpath是否正确了。安装插件需要特别上网,安装好插件后,在chrome右上角点插件的图标,调出插件的黑色界面,编辑好xpath表达式,表达式选中的元素被标记为黄色
结语:
以上就是利用XPath的所有用法,从常用语法,到案例练习都走了一遍。觉得有用点赞加关注,后续更多学习知识点。
-
相关阅读:
走进SpringBoot源码吃透Spring扩展点「扩展点实战系列」- 第450篇
R语言深度学习-4-识别异常数据(无监督学习/自动编码器)
白杨SEO对话老姜:聊聊第三方平台站内SEO,第三方平台的引流的逻辑是什么?
【SV 基础】queue 的一些用法
1024 向所有的程序员们致以崇高的敬意和感谢
【2023考研】数据结构常考应用典型例题(含真题)
Spark SQL底层执行流程详解
nodejs篇 内置模块events 常用api
神经网络原理及代码实现
仅用Python三行代码,实现数据库和Excel之间的导入导出
- 原文地址:https://blog.csdn.net/m0_72557783/article/details/126364498
