-
MYSQL
Mysql
1. 数据库介绍
- 数据库:DataBase -->按照一定格式存储数据的文件的组合,专门存放数据的仓库
- 数据库管理系统:专门用来管理数据库中的数据的,可以对数据库中的数据进行操作:增删改查
- 常见的数据库管理系统:MySQL、Oracle、Sqlserver
- SQL:结构化的查询语句–>
2. 数据库命令
常用命令:
注意:每一个命令后面都要加上分号结尾,这就代表一句命令结束- 关闭服务:net stop mysql;
- 开启服务:net start mysql;
注意:开启和关闭,只能在数据库位登录之前 - 登录:
- 显示密码:mysql -uroot -p+密码(p之间没有空格)
- 不显示密码:mysql -uroot -p+换行+密码(换行后在Enter password:这里输入密码)
-
退出:exit
-
查看数据库: show databases; 分号结尾
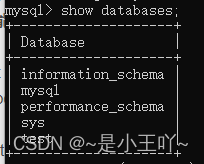
-
使用数据库: use + 具体数据库名
-
创建数据库库:create database + 库名
-
查看有哪些表(也就是查所有表名):show tables
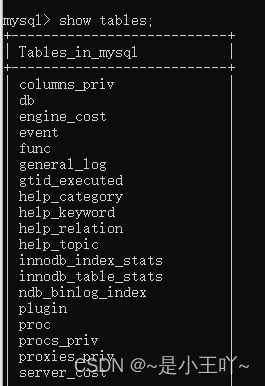
-
查看数据库版本号:select version();
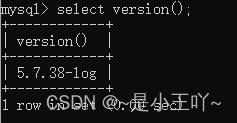
-
查看当前使用的数据库:select database();
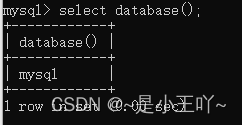
3 数据库基本单元
table表
- 行(row):每一行就是一条数据
- 列(column):字段
- 字段:字段名+数据类型+约束(约束一般都是能不能为null)
4 SQL分类
4.1 DQL(数据查询)
数据查询语言,也就是只要是select的都是
4.1.1 建表查询
- 查看表结构: desc 表名 ;
- desc student;

- 查看表中所有数据
- select * from student;
- select sid,sname,ssex,sdept,sage,saddress from student;
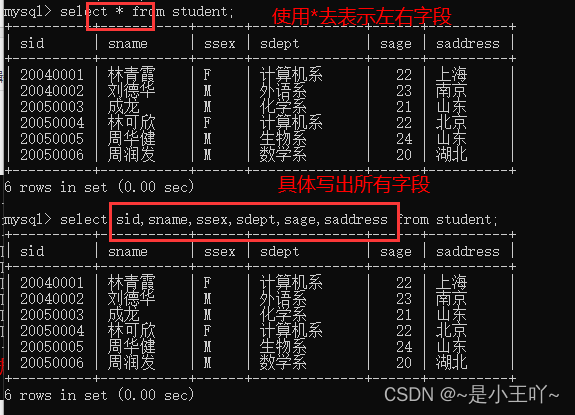
注意:建议使用写出全部字段,因为使用 “ * ”, 效率比较低 因为会把*转化为字段所以效率比较低,在实际开发中不建议
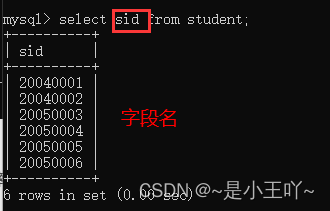
- 查看表的某字段
- select sid from student;
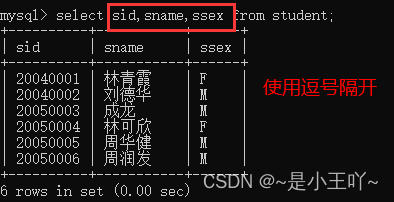
- 查询多个字段
- select sid,sname,ssex from student;
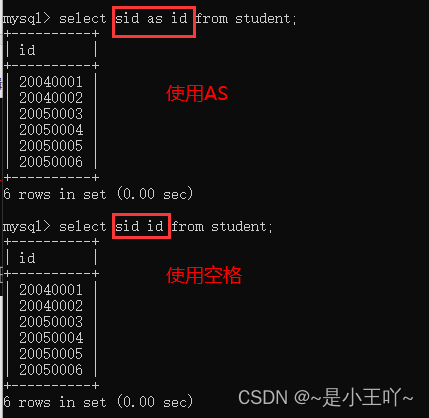
- 给字段取别名
- select sid as id from student;
- select sid id from student;
- 字段数据的计算
- select sage*12 from student;

注意:只要在数据库中有null出现,最后结果都是null
4.1.2 条件查询
语法:
select 字段名 from 表名 where 条件
条件:
=:等于
<> !=:不等于
<小于
大于>
<=:小于等于
: >=大于等于
between … and…:两个值之间,等价于>= and <=:注意:前面的值一定是小的,后面的是大的
is null :为空
is not null:不为空
and:并且
or:或
in:包含
like:模糊查询,一般跟 % 或者下划线;%匹配任意字符;下划线:一个下划线匹配一个字符4.1.3 排序
4.1.3.1 单字段排序
order by :默认是升序,
-
select sname,sage from student order by sage;

-
升序(ASC):
-
select sname,sage from student order by sage asc;
-
降序(DESC):
-
select sname,sage from student order by sage desc;

4.1.3.2 多字段排序:
- select sid,sname,sage from student order by sage desc,sid asc;

注意:多个字段同时排序的时候,先按照前面的排序,如果前面排序中的数据有i相同的,就按照后面的方式排序。如果没有就只管前面的了。
所以:越靠前的字段能起到主导作用,只有前面字段不能够排了后,才会按照后面的去排序
4.1.3.3 字段为数字
- mysql> select sid,sname,sage from student order by 3;
- select * from student order by 3;
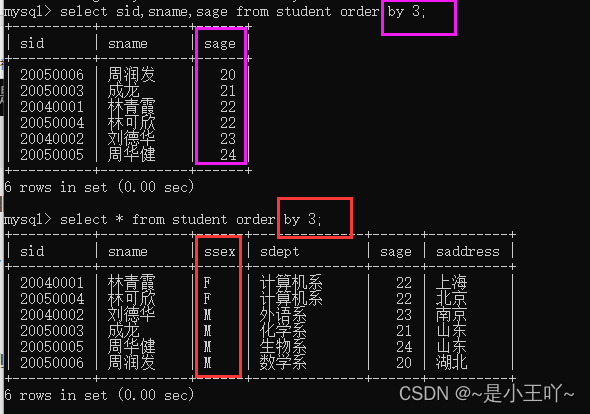
注意:如果order by 后面没有字段,是数字,那就是按照数字所对应的列来排的,这个数字所对应的列,是你所要查询的所有字段的,也就是select后面的。
4.1.3.4 执行顺序

4.1.4 单行处理函数
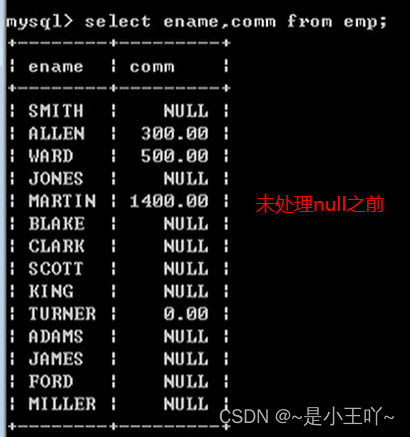
- 也就是输入一行,输出一行
- 一般在字段进行计算的时候,只要有null出现,那么运算结果一定为null
-
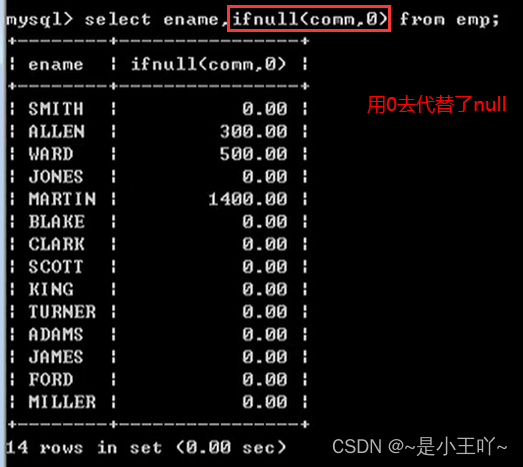
处理空处理函数:
ifnull(可能为null的数据,被当作什么来处理) -
select ename,ifnull(comm,0) as comm from emp;
-
单行处理函数:ifnull();
-
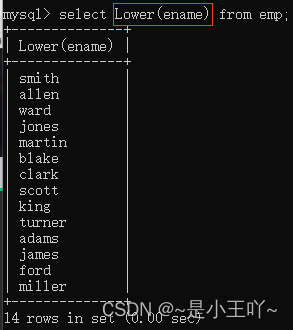
Lower:转换成小写
select Lower(ename) from emp;
-
Upper:转换成大写
-
substr:截取字符串(被截取字符串,起始下标,截取长度)
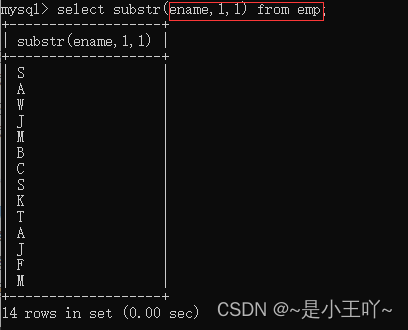

注意:mysql中起始下标为1.
-
trim:去空格
-
round:四舍五入(x,d):x是要四舍五入的数据,d是保留的小数位,默认是0也就是没有小数
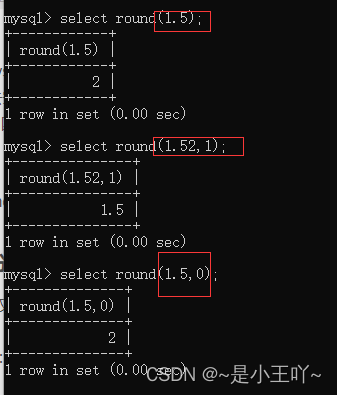

-
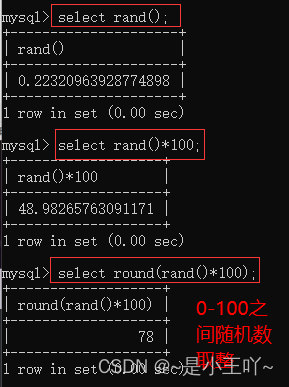
rand():随机数:0-1之间
-
concat:字符串拼接(字段1,字段2,…)
-
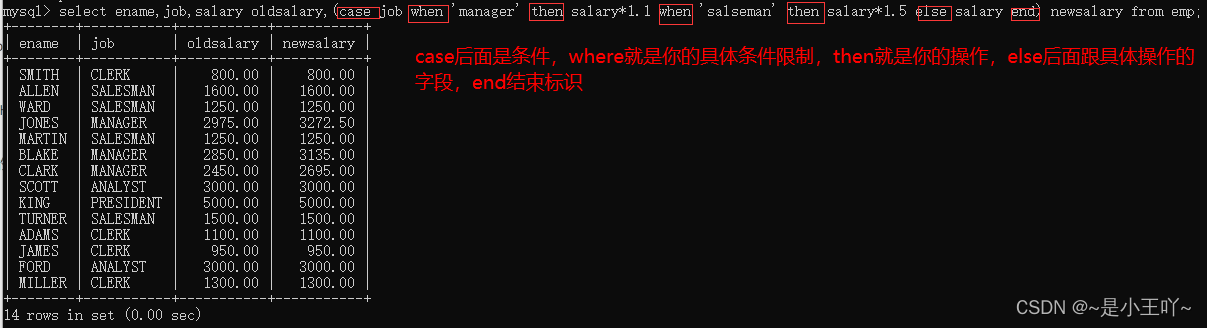
case when then when then else end :当…时候…就…
4.1.5 分组函数
分组函数又叫多行处理函数,也就是输入多行,输出一行
一共五个:
- count:计数
- sum:求和
- avg:求平均值
- max:求最大值
- min:求最小值
注意:
- 所有的分组函数都是对“某一组"数据进行操作的
- 输入多行,输出一行
- 分组函数自动忽略null,所以对含有null的字段进行运算的时候,不影响
- sql语句中,分组函数,不可以直接使用在where子句中

为什么分组函数不能出现在where子句中?
答:因为一般分组函数都是搭配group by使用的,但是呢group by的执行顺序在where的后面,所以分组函数的数据都还没有进行分组,就更不可能在where子句中使用了。

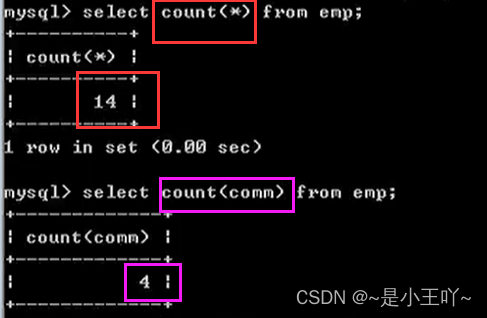
重点:count(*) 和 count(具体字段)的区别
0count(*):统计同数据条数,和字段无关
count(具体字段):统计这个字段中不为null的总记录
多行处理函数可以组合:

4.1.6 group by 和 having
- group by :按照某个字段或者某些字段进行分组
- having :是对分组后的数据进行再次过滤
注意:having是搭配group by使用的,有group by才能有having,能先使用where过滤的先使用where过滤。
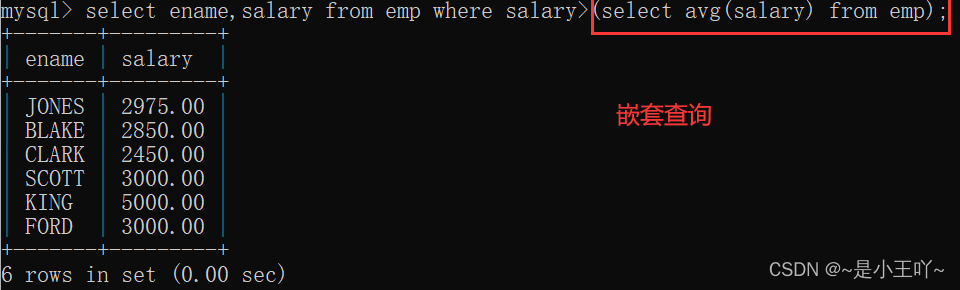
案例1:查询工资大于平均工资的员工信息
注意:考察的是where后面不能跟分组函数- select ename,sal from where sal>(select avg(sal) from emp);
注意: - 分组函数一般都会跟group by联合使用,并且任何一个分组函数(count、sum、avg、max、min)都在group by语句执行完结束过后才会执行的。
- 当一条sql语句没有group by的话,整张表的数据会自成一组
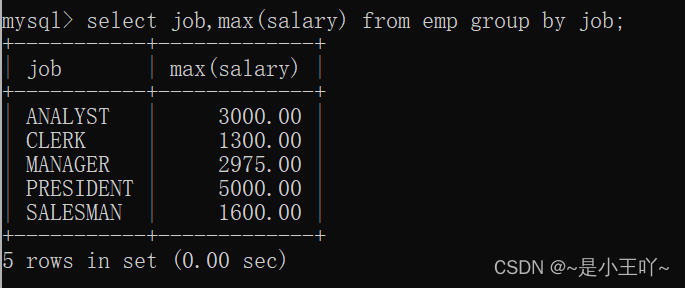
案例2:找出每个工作岗位的最高薪资
分析:根据岗位来分组,相同岗位分在一起,然后求出最大值即可- select job,max(salary) from emp group by job;
案例3:这条语句有没有问题:
select ename,max(salary) ,job from emp group by job;
验证:
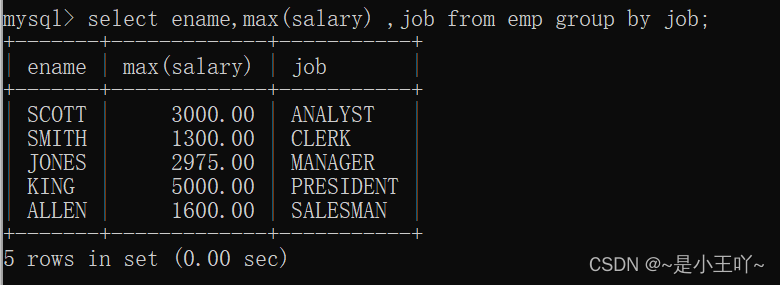
注意: - 这条语句在,在mysql语句中是有查询结果的,但是查询的结果并没有意义,在oracle中就会报语法错误。
- 当一条语句中有group by的话,select后面只能跟分组函数和参与分组的字段
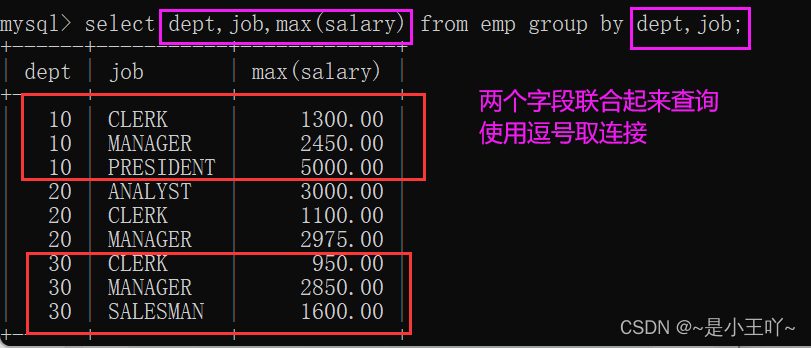
案例4:找出每个部门不同岗位的最高薪资
分析:-
先通过排序查一下不同部门的岗位薪资,便于观察
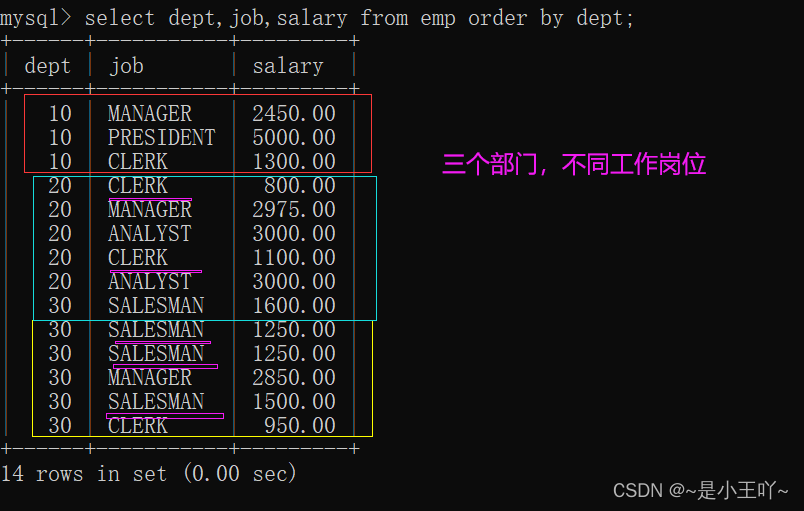
-
两个字段联合分组(dept,job)
select dept,job,max(salary) from emp group by dept,job;
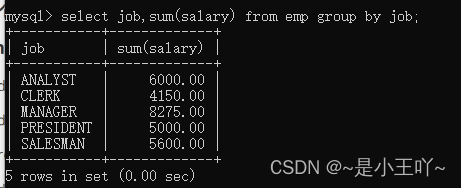
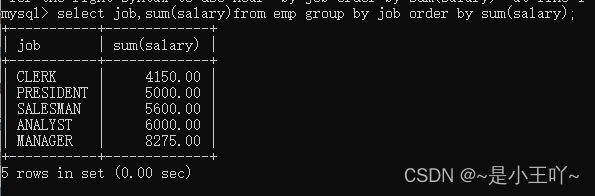
案例5:计算出那个岗位的工资最高 -
select job,sum(salary) from emp group by job;
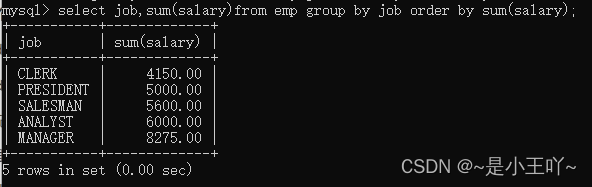
-
select job,sum(salary)from emp group by job order by sum(salary);

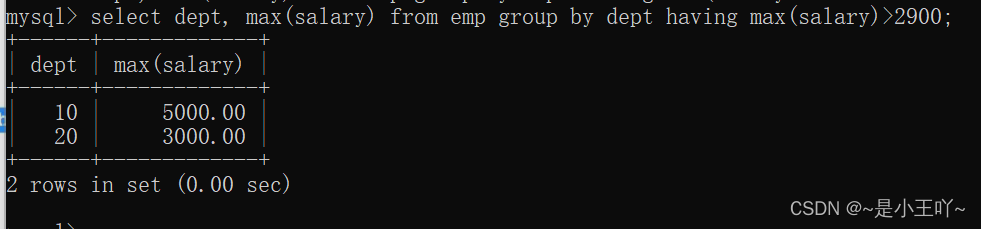
案例5:找出每个部门的最高薪资,要求薪资数据大于2900
- select dept,max(salary) from emp group by dept having max(salary)>2900;
- 效率低,不介意使用
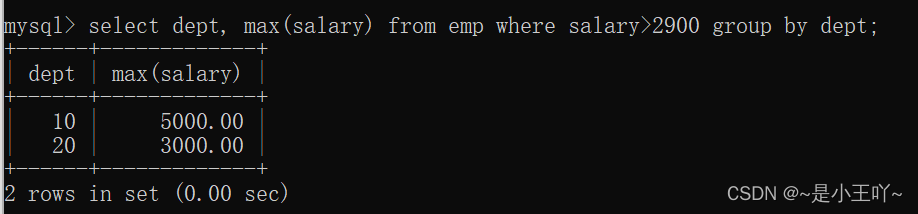
- select dept, max(salary) from emp where salary>2900 group by dept;
- 介意使用where过滤,效率高,因为where的执行顺序在group by的前面,语句意思是:先将所有大于2900的数据先找出来,再去排序
案例6:找出每个部门的平均薪资,要求显示平均薪资高于2500
- select dept,avg(salary) from emp group by dept having avg(salary)>2500;
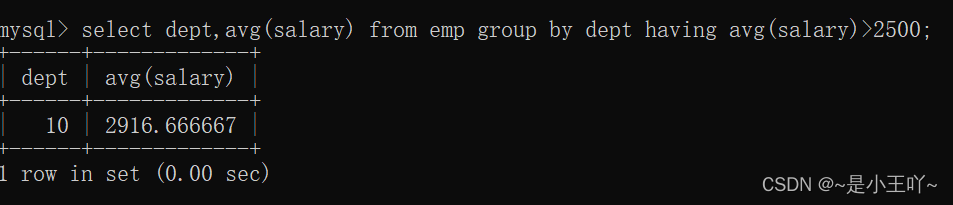
注意:这时候不能使用where,因为where后面不能跟分组函数
DQL完整语法:

4.1.7 distincet 关键字
作用:去重
只会显示的去重了,数据库实际没有去重案例:去重工作的重复字段
- select distinct job from emp;
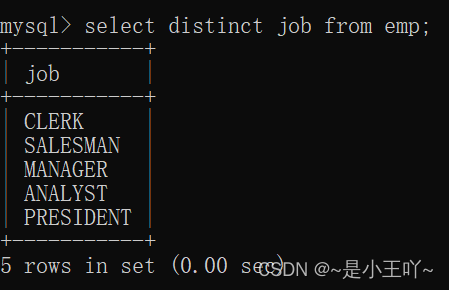
在distinct前面加字段?
错误的,会报错,因为distinct有限制条数,前面再加字段,显示条数就会有问题,不知道显示前面字段的条数还是去重后的

在distinct后面加字段?
这代表着联合去重,也就是将后面的所有字段联合起来,去除联合后还相同的
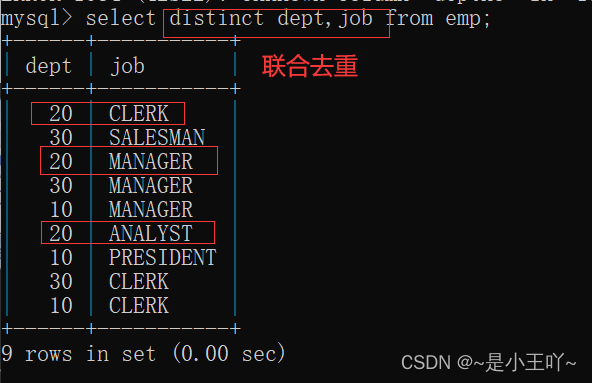
注意:
- 只能出现在所有字段的最前面:因为distinct有限制条数,前面再加字段,显示条数就会有问题
- distinct后面有多个字段,并且用逗号隔开,表示联合去重
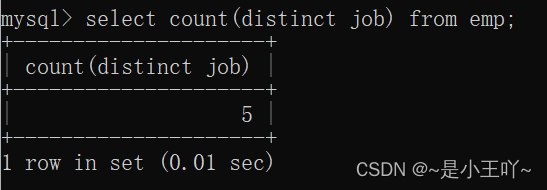
案例:统计岗位的数量:
- select count(distinct job) from emp;
4.1.8连接查询
连接查询就是多表查询
笛卡尔积现象:
当两张表进行连接查询的时候,没有任何条件限制,最终的查询结构条数是两张表记录条数的乘积连接分类:
- 按照年份分类:
SQL99:用join(比较新 )
SQL92:用where - 按照连接方法分类:
- 内连接:
- 等值连接:
特点:条件是等量关系,inner join on,inner可以省略
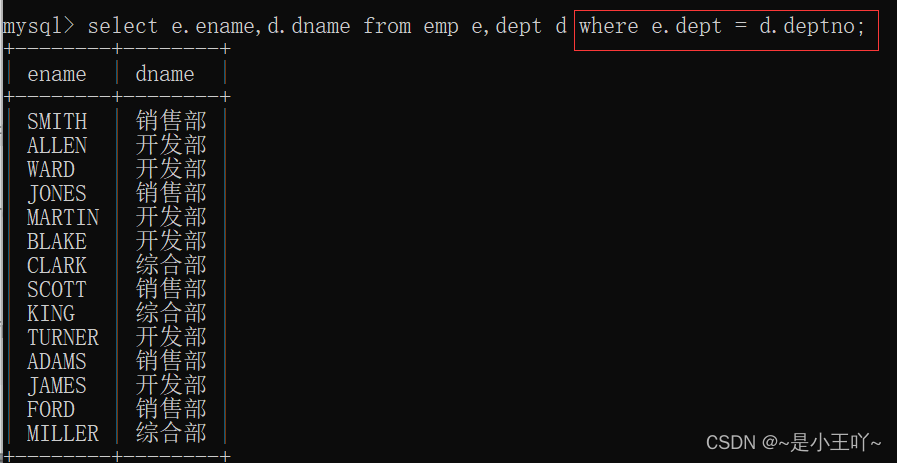
- 案例:查询每个员工的部门名称,要求显示员工名和部门名
SQL92查询方法:
select e.ename,d.dname from emp e,dept d where e.dept = d.deptno;
//使用where
SQL99查询方法:
select e.ename,d.dname from emp e join dept d on e.dept = d.deptno;
使用inner(省略了) join on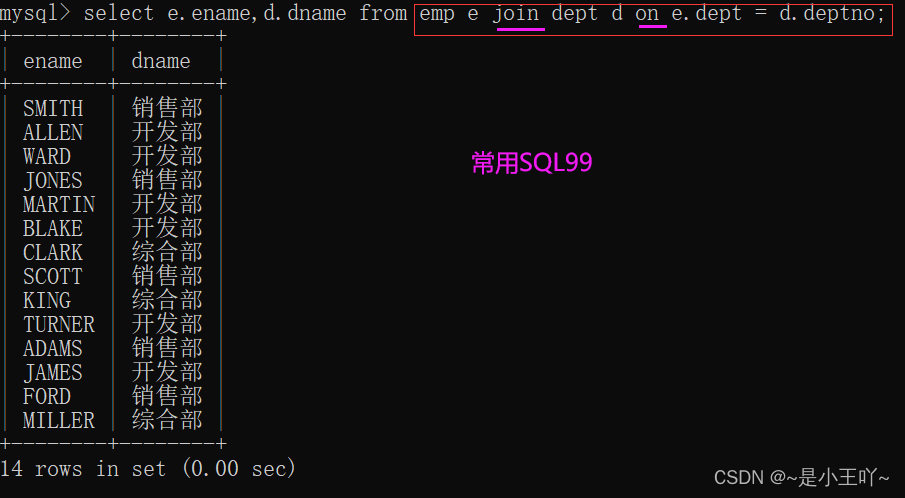 mg-blog.csdnimg.cn/6199d86aa3f84fd68416fb68551e14b5.png)
mg-blog.csdnimg.cn/6199d86aa3f84fd68416fb68551e14b5.png)
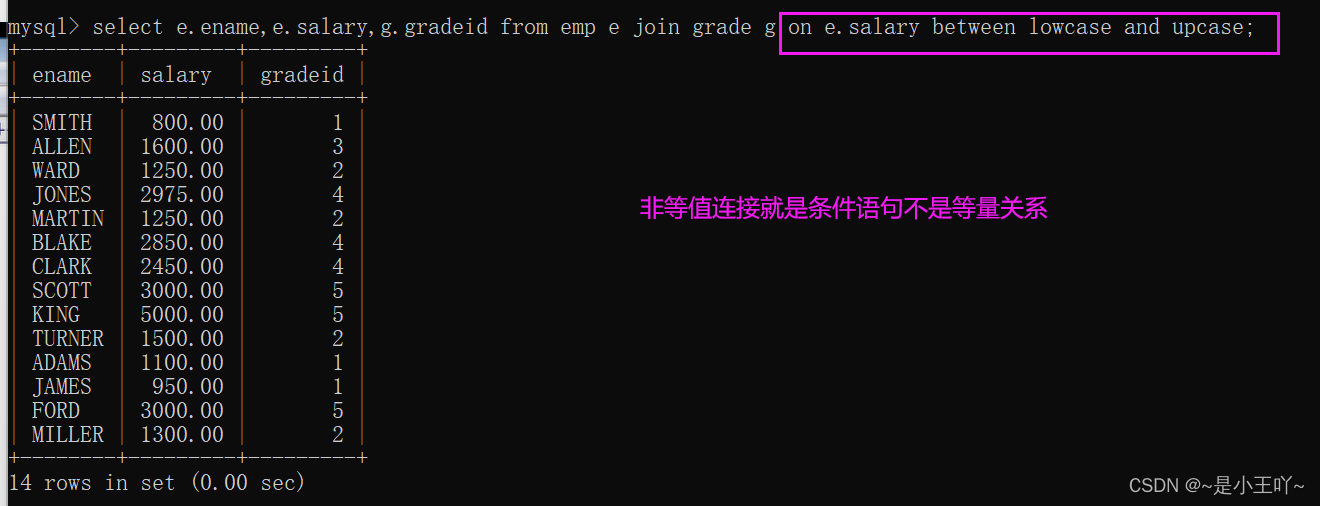
- 非等值连接:不是等量关系
特点:连接台哦见中的关系是非等量的关系
*案例:找出每个员工的工资等级,要求显示员工名、工资、工资等级
select e.ename,e.salary,g.gradeid from emp e join grade g on e.salary between lowcase and upcase;
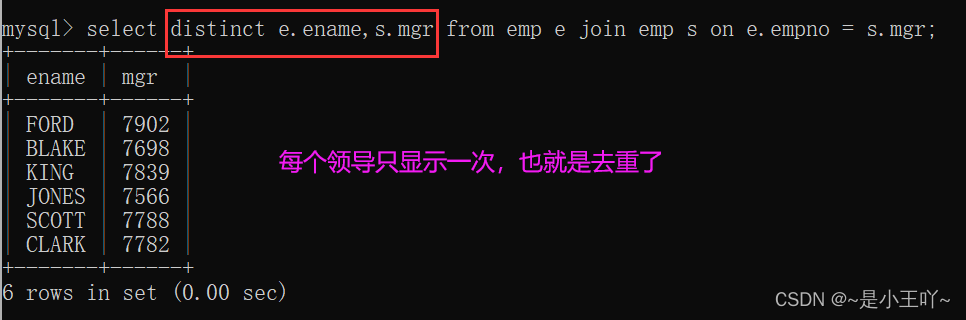
- 自链接:自己连接自己
特点:一张表看作两张表,自己连接自己
- 案例:找出每个员工的上级领导,要求显示员工名和对应的领导名
select e.ename,s.mgr from emp e join emp s on e.empno = s.mgr;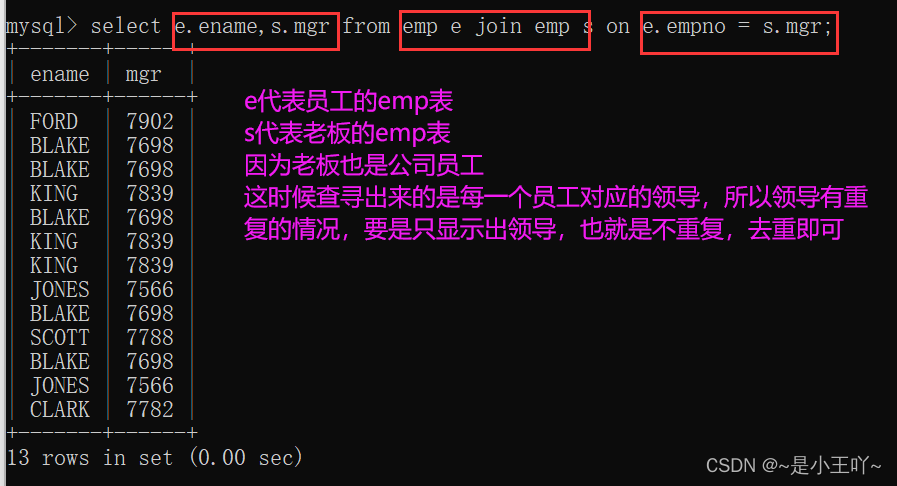
- 外连接:
语法: 表一 lift / right outer(可省略)表二
-
左外连接(左连接)
表示左边的表是主表 -
右外连接(右链接)
表示右边的表是主表
案例:查询所有员工的领导(意思是每一个员工的领导都要查询出来,包括最大boss,虽然他没有领导)
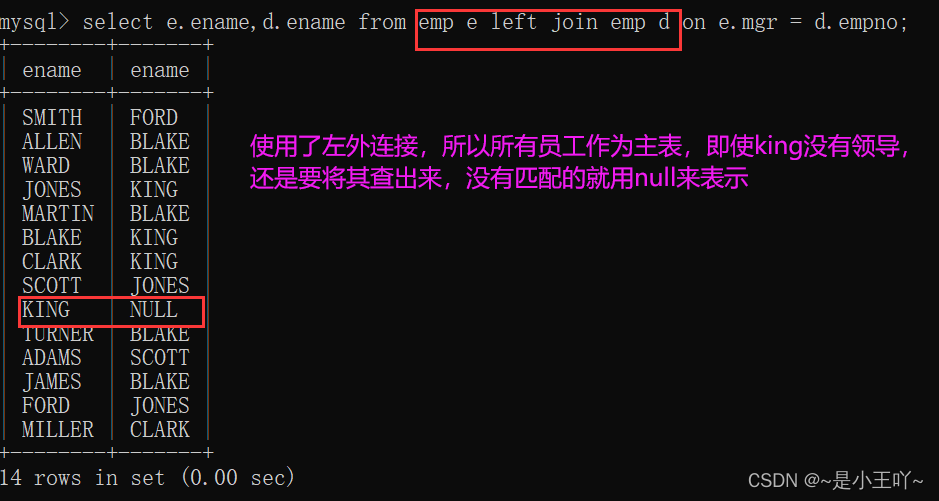
注意:左连接有右连接写法,右连接有左连接的写法-
全连接:不那么重要
-
内连接和外连接区别

注意: -
外连接语法:表一 lift / right outer(可省略)表二
-
其实看是内连接还是外连接,看有没有lift或者right就可以知道了
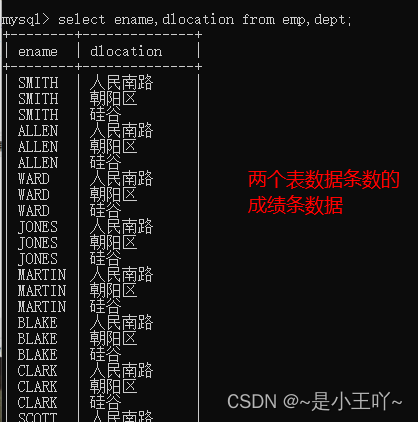
笛卡尔积现象:

-
select ename,dlocation from emp,dept;
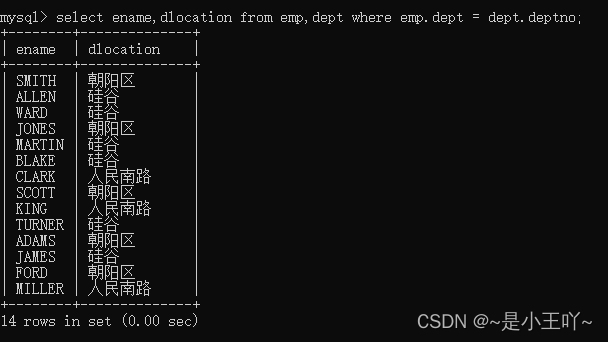
-
select ename,dlocation from emp,dept where emp.dept = dept.deptno;
-
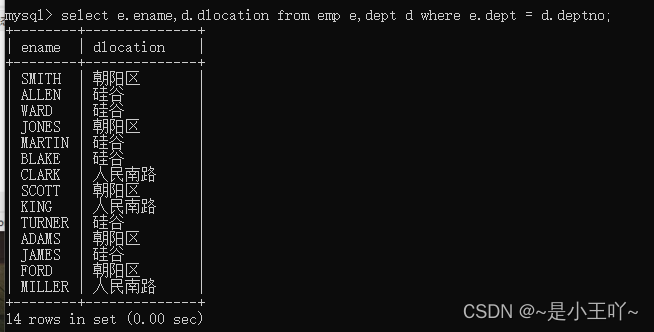
select emp.ename,dept.dlocation from emp,dept where emp.dept = dept.deptno;

-
select e.ename,d.dlocation from emp e,dept d where e.dept = d.deptno;

三张表的连接查询
语法:

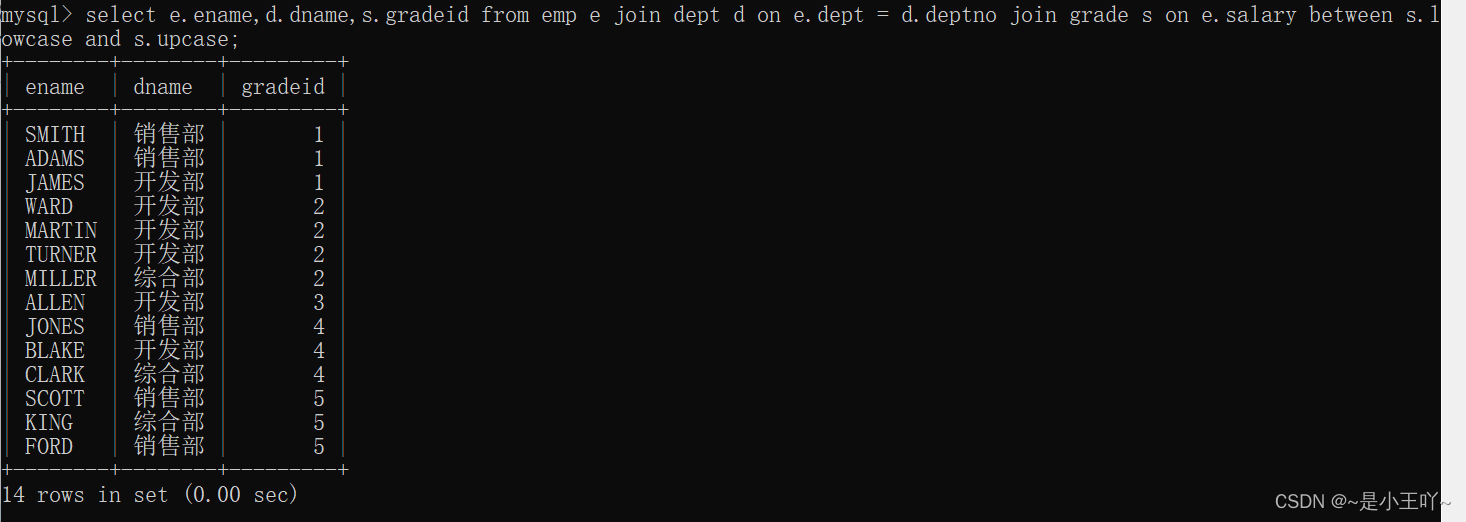
案例:找出每一个员工的部门名称以及工资等级
分析:先连接两张表进行部分数据查询,再将查询到的结果看作是一张表,再与剩下的表进行查询操作- select e.ename,d.dname,s.gradeid from emp e join dept d on e.dept = d.deptno join grade s on e.salary between s.lowcase and s.upcase;
4.2 DML
数据操作语言,也就是数据的增删改等操作
4.3 DDL
数据定义语言,主要是表结构,并不是数据
- creat:新建
- drop:删除
- alter:修改
-
相关阅读:
搜索与图论:染色法判别二分图
Linux 中的 chage 命令及示例
vscode 根据 ESLint 规范自动格式化代码
leetcode周赛---找出中枢整数
ABS10-ASEMI开关电源整流桥ABS10
MyCat应用实战
ReactNative入门(二)——导航和路由
git查看历史记录及修改内容
驾校管理系统的设计与实现/驾校信息管理系统
【Spring IoC容器的加载过程】
- 原文地址:https://blog.csdn.net/Sunblogy/article/details/126361971

