-
Python 操作 lxml库与Xpath(爬取网页指定内容)
Python 操作 lxml库与Xpath(爬取网页指定内容)
软件测试工作中常用
活动地址:CSDN21天学习挑战赛
1.Python lxml库介绍
lxml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的数据;lxml和正则一样,也是用C语言实现的,是一款高性能的python HTML、XML解析器,也可以利用XPath语法,来定位特定的元素及节点信息
HTML是超文本标记语言,主要用于显示数据,他的焦点是数据的外观
XML是可扩展标记语言,主要用于传输和存储数据,他的焦点是数据的内容1.1 安装lxml模块库
pip install lxml- 1
1.2 lxml 是什么
lxml是以Python语言编写的库,主要用于解析和提取HTML或者XML格式的数据,它不仅功能非常丰富,而且便于使用,可以利用XPath语法快速地定位特定的元素或节点。
lxml库中大部分的功能都位于 lxml.etree模块中,导入lxml.etree模块的常见方式如下:
from lxml import etree- 1
lxml库的一些相关类如吓:
●Element类 :可以理解为XML的节点。
●ElementTree类 :可以理解为一个完整的XML文档树。
●ElementPath类 :可以理解为XPath ,于搜索和定位节点。1.2.1 Element类简介
Element类是XML处理的核心类,可以直观地理解为XML的节点,大部分XML节点的处理都是围绕着该类进行的。要想创建一个节点对象,则可以通过构造函数直接创建,示例如下:
root = etree.Element('root')- 1
上述示例中,参数root表示节点的名称。
关于Element类的相关操作,主要可分为三个部分,分别是节点操作、节点属性的操作、节点内文本的操作,下面进行逐一介绍。
1. 节点操作
若要获取节点的名称,则可以通过tag属性获取,示例如下:
print(root.tag) # 输出结果如下 root- 1
- 2
- 3
2. 节点属性的操作
在创建节点的同时,可以为节点增加属性。节点中的属性是以“key-value”的形式进行存储的,类似于字典的存储方式。通过构造方法创建节点时,可以在该方法中以参数的形式设置属性,其中参数的名称表示属性的名称,参数的值表示为属性的值。创建属性的示例如下:
# 创建root节点,并为其添加属性 root = etree.Element('root', interesting='totally') print(etree.tostring(root)) # 输出结果如下 b'' - 1
- 2
- 3
- 4
- 5
此外,可以通过set()方法给已有的节点添加属性。在调用该方法时可以传入两个参数,其中第一个参数表示属性的名称,第二个参数表示属性的值,示例如下:
# 再次给root节点添加age属性 root.set('age', '30') print(etree.tostring(root)) # 输出结果如下 b'' - 1
- 2
- 3
- 4
- 5
在上述两个示例中,都用到了tostring()函数,该函数可以将元素序列化为其XML树的编码字符串表示形式。
3. 节点内文本的操作
一般情况下,可以通过text、tail属性或者xpath()方法来访问文本内容。通过text属性访问节点的示例如下:
root = etree.Element('root') # 创建root节点 root.text = 'Hello, World!' # 给root节点添加文本 print(root.text) print(etree.tostring(root)) # 输出结果如下 Hello, World! b'Hello, World! '- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.2.2 从字符串或文件中解析XML
为了能够将XML文件解析为树结构,etree模块中提供了如下三个函数:
- fromstring()函数:从字符串中解析XML文档或片段,返回根节点(或解析器目标返回的结果)。
- XML()函数:从字符串常量中解析XML文档或片段,返回根节点(或解析器目标返回的结果)。
- HTML()函数:从字符串常量中解析HTML文档或片段,返回根节点(或解析器目标返回的结果)。
其中,XML()函数的行为类似于fromstring()函数,通常用于将XML字面量直接写入到源代码中,HTML()函数可以自动补全缺少的< html>和< body>标签。关于上述三个函数的示例如下:
xml_data = 'data ' # fromstring方法 root_one = etree.fromstring(xml_data) print(root_one.tag) print(etree.tostring(root_one)) # XML方法,与fromstring方法基本一样 root_two = etree.XML(xml_data) print(root_two.tag) print(etree.tostring(root_two)) # HTML方法,如果没有和标签,会自动补上 root_three = etree.HTML(xml_data) print(root_three.tag)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
上述示例运行的结果如下:
root b'data ' root b'data ' html- 1
- 2
- 3
- 4
- 5
除了上述三个函数之外,还可以调用parse()函数从XML文件中直接解析。在调用函数时,如果没有提供解析器,那么就使用默认的解析器,函数会返回一个ElementTree 类型的对象,示例如下:
html = etree.parse('./hello.html') result = etree.tostring(html, pretty_print=True) print(result)- 1
- 2
- 3
1.2.3 ElementPath类简介
ElementTree类中附带了一个类似于XPath路径语言的ElementPath类。在ElementTree类或Elements类的API文档中,提供了三个常用的方法,可以满足大部分搜索和查询需求,并且这两个方法的参数都是XPath语句,具体如下:
- find()方法:返回匹配到的第一个子元素;
- findall()方法:以列表的形式返回所有匹配的子元素。
- iterfind()方法:返回一个所有匹配元素的迭代器。
从文档树的根节点开始,搜索符合要求的节点,示例如下:
# 从字符串中解析XML,返回根节点 root = etree.XML("aText ") # 从根节点查找,返回匹配到的节点名称 print(root.find("a").tag) # 从根节点开始查找,返回匹配到的第一个节点的名称 print(root.findall(".//a[@x]")[0].tag)- 1
- 2
- 3
- 4
- 5
- 6
示例的结果如下:
a A- 1
- 2
2.XPath 介绍
2.1 什么是XPath
XPath(XML Path Language的简写)即为XML路径语言,用于确定XML树结构中某一部分的位置。XPath技术基于XML的树结构,能够在树结构中遍历节点(元素、属性等)。
那么,XPath 是如何查找信息呢?XPath使用路径表达式选取XML文档中的节点或者节点集,这些路径表达式与常规的电脑文件系统中看到的路径非常相似,代表着从一个节点到另一个或者一组节点的顺序,并以“/”字符进行分隔。接下来,通过一张示意图来描述XPath的路径表达式,如图所示。
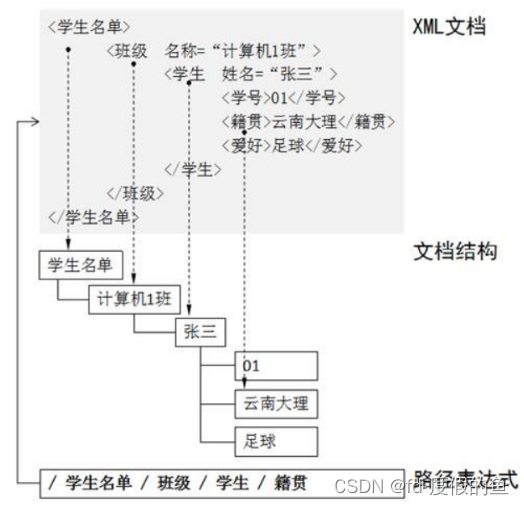
XPath不仅能够查询XML文档,而且能够查询HTML文档。不过,需要先将HTML文档转换成XML文档,之后使用XPath语法查找HTML文档的节点或者元素。
2.2 XPath 语法
在Python中,XPath使用路径表达式在文档中进行导航。这个表达式是从某个节点开始,之后顺着文档树结构的节点进一步查找。由于查询路径的多样性,可以将XPath的语法按照如下情况进行划分:
2.1.1 选取节点
节点是沿着路径选取的,既可以从根节点开始,也可以从任意位置开始。表1列举了XPath中用于选取节点的表达式。
表1 选取节点的表达式
表达式 说明 nodename 选取此节点的所有子节点 / 从根节点选取 // 从匹配选择的当前节点选取文档中的节点,而不用考虑它们的位置 . 选取当前节点 … 选取当前节点的父节点 @ 选取属性 接下来是一些选取节点的示例,具体如下:
- 选取节点bookstore的所有子节点,表达式如下:
bookstore- 1
- 选取根节点bookstore,表达式如下:
/bookstore- 1
需要注意的是,如果路径以“/”开始,那么该路径就代表着到达某个节点的绝对路径。
- 从根节点bookstore开始,向下选取属于它的所有book子节点,表达式如下:
bookstore/book- 1
- 从任意位置开始,选取名称为book的所有节点,表达式如下:
//book- 1
与上一个表达式相比,该表达式不用再说明符合要求的这些节点在文档树中的具体位置。
- 在节点bookstore的后代中,选取所有名称为book的所有节点,而且不用管这些节点位于bookstore之下的什么位置,表达式如下:
bookstore//book- 1
- 使用“@”选取名称为lang的所有属性节点,表达式如下:
//@lang- 1
2.1.2 谓语(补充说明节点)
谓语是对指路径表达式的附加条件,这些条件都写在方括号中,表示对节点进行进一步筛选,用于查找某个特定节点或者包含某个指定值的节点,具体格式如下。
元素[表达式]- 1
接下来,通过一张表来列举一些常用的带有谓语的路径表达式,以及对这些表达式功能的说明,具体如表2所示。
表2 使用谓语的表达式
表达式 说明 /bookstore/book[1] 选取属于 bookstore 子元素的第一个 book 元素。 /bookstore/book[last()] 选取属于 bookstore 子元素的最后一个 book 元素。 /bookstore/book[last()-1] 选取属于 bookstore 子元素的倒数第二个 book 元素。 /bookstore/book[position()❤️] 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 //title[@lang] 选取所有的title元素,且这些元素拥有名称为lang的属性。 //title[@lang=’eng’] 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 /bookstore/book[price>35.00] 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 /bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 2.1.3 选取未知节点
XPath可以使用通配符(*)来选取未知的节点。例如,使用“ *”可以匹配任何元素节点。接下来,通过一张表来列举带有通配符的表达式,具体如表3所示。
表3 带有通配符的表达式
通配符 说明 * 匹配任何元素节点。 @* 匹配任何属性节点。 node() 匹配任何类型的节点。 下面是一些使用通配符的示例,具体如下:
- 选取bookstore元素的所有子元素,表达式如下:
/bookstore/*- 1
- 选取文档中的所有元素,表达式如下:
//*- 1
- 选取所有带有属性的title 元素,表达式如下:
//title[@*]- 1
2.1.4 选取若干路径
在路径表达式中可以使用“|”运算符,以选取若干个路径。下面是一些在路径表达式中使用“|”运算符的示例,具体如下:
- 选取book元素中包含的所有title和price子元素,表达式如下:
//book/title | //book/price- 1
- 选取文档中的所有title和price元素,表达式如下:
//title | //price- 1
- 选取位于/bookstore/book/路径下的所有title元素,以及文档中所有的price元素,表达式如下:
/bookstore/book/title | //price- 1
2.3.如何获取XPath
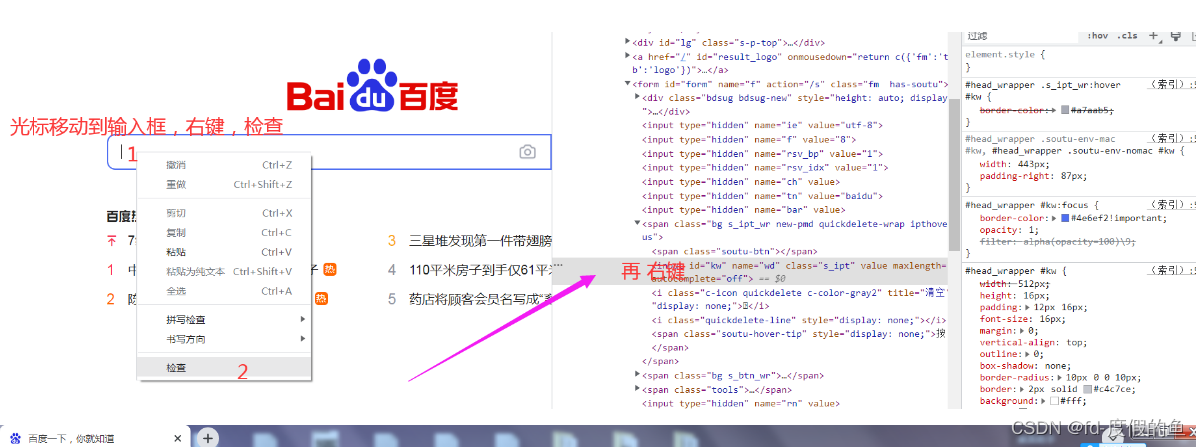
对于没有编码基础的小伙伴来说,可以直接用谷歌浏览器自带的【开发者工具】
来获取网页某个元素的 XPath
//*[@id="kw"]- 1
/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input- 1

3 .实战练习
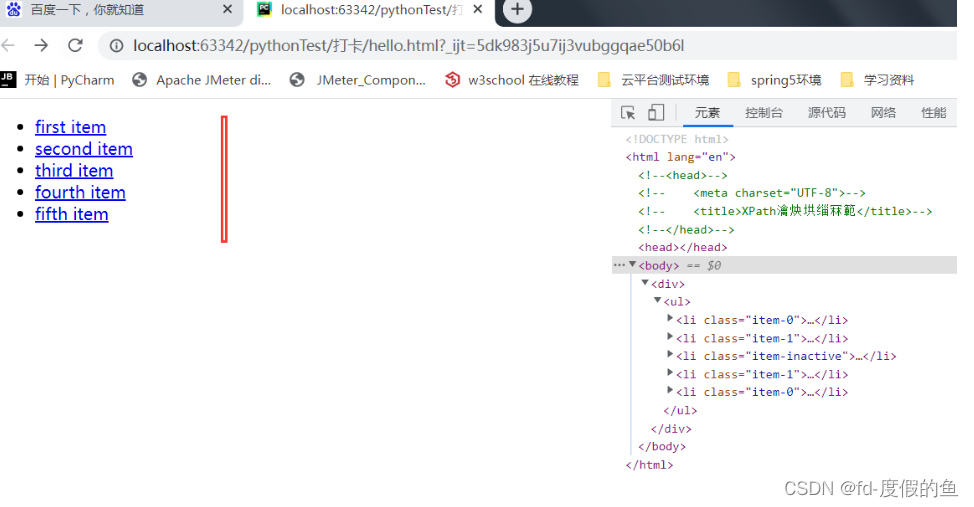
我们使用一个HTML示例文件做为素材来介绍lxml库的基本使用,该文件名为hello.html,内容如下:
DOCTYPE html> <html lang="en"> <body> <div> <ul> <li class="item-0"><a href="link1.html">first itema>li> <li class="item-1"><a href="link2.html">second itema>li> <li class="item-inactive"><a href="link3.html"><span class="bold">third itemspan>a>li> <li class="item-1"><a href="link4.html">fourth itema>li> <li class="item-0"><a href="link5.html">fifth itema>li> ul> div> body> html>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
接下来,我们基于上述HTML文档,使用lxml库中的路径表达式技巧,通过调用xpath()方法匹配选取到的节点,具体如下:
代码
from lxml import etree html = etree.parse('hello.html') ''' 1.获取任意位置的li节点-----//li 直接使用“//”从任意位置选取节点li;通过lxml.etree模块的xpath方法,将hello.html文件中与该路径表达式匹配到的列表进行返回,并打印输出,具体代码如下。 ''' # 查找所有的li节点 result = html.xpath('//li') # 1.打印- 标签的元素集合
print("1.- 标签的元素集合:"
, result) # 2.打印- 标签的个数
print("2.- 标签的个数:"
, len(result)) # 3.打印返回结果的类型 print("3.返回结果的类型:", type(result)) # 4.打印第一个元素的类型 print("4.第一个元素的类型:", type(result[0])) ''' 2.继续获取< li>标签的class属性-----//li/@class 在上个表达式的末尾,使用“/”向下选取节点,并使用“@”选取class属性节点,表达式如下: ''' # 5.查找位于li标签的class属性 result1 = html.xpath('//li/@class') print("5.查找位于li标签的class属性:", result1) ''' 3.获取倒数第二个元素的内容------ //li[last()-1]/a 或者 /li[last()-1]/a]/text() 从任意位置开始选取倒数第二个< li>标签,再向下选取标签< a>。如果要获取该标签中的文本,可以使用如下表达式: ''' # 6.获取倒数第二个元素的内容 result = html.xpath('//li[last()-1]/a') print("6.获取倒数第二个元素的内容", result[0].text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
输出结果
"D:\Program Files1\Python\python.exe" D:/Pycharm-work/pythonTest/打卡/0816.py 1.<li>标签的元素集合: [<Element li at 0x2b9d908>, <Element li at 0x2b9da08>, <Element li at 0x2b9da48>, <Element li at 0x2b9da88>, <Element li at 0x2b9dac8>] 2.<li>标签的个数: 5 3.返回结果的类型: <class 'list'> 4.第一个元素的类型: <class 'lxml.etree._Element'> 5.查找位于li标签的class属性: ['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0'] 6.获取倒数第二个元素的内容 fourth item Process finished with exit code 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4. 一个UI自动化的简单例子
import time import selenium from selenium import webdriver # 1、创建Chrome实例 。 driver = webdriver.Chrome() # 2、driver.get方法将定位在给定的URL的网页 。 driver.get("https://www.baidu.com/") # get接受url可以是如何网址,此处以百度为例 # 3、定位元素 # 3.1、用id定位输入框对象, driver.find_element_by_id("kw").send_keys("python") # 3.2、用id定位点击对象,用click()触发点击事件 driver.find_element_by_id('su').click() # 延迟3秒 time.sleep(3) # 4、退出访问的实例网站。 driver.quit()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
-
相关阅读:
每日三题 8.25
中国运动服行业并购重组机会及投融资战略研究咨询报告
批量更改文件名 - 大师汇总
验证k8s中HPA功能及测试
Git-快速笔记(持续更新)
计算机是如何启动的
TypeError: res.data.map is not a function微信小程序报错
list的模拟实现
Linux桌面环境中应用程序无法启动图形交互界面
Docker 快速入门体验
- 原文地址:https://blog.csdn.net/u014096024/article/details/126367883
