-
Hadoop分布式集群搭建,以及ssh互通免密登录!
前面给大家讲的是hadoop伪分布式的搭建,今天给大家讲解下3台虚拟机的hadoop搭建.
首先安装好3台虚拟机,命名为hadoop2,hadoop2,hadoop4
都安装好jdk这就不用多说了,这里为了操作方便,3台虚拟机一起下命令;
分别为每台虚拟机设置主机名
hostname hadoop2
hostname hadoop3
hostname hadoop4
首先打开xshell,新建3个会话分别命名为 hadoop2,hadoop2,hadoop4;打开这三个窗口,选择最上端的选项卡,排列中选择水平排列
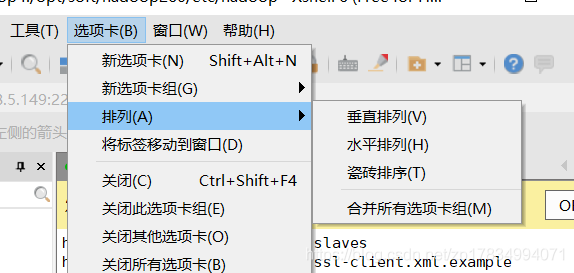
然后选择工具栏,找到第一个:发送键输入到所有会话

这样就可以在一个窗口操作命令,同时控制到3个窗口上了

同时操作之前,分别为每台虚拟机设置静态IP
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3hadoop2 设置:
192.168.5.129 hadoop2
hadoop3 设置:
192.168.5.129 hadoop3
hadoop4 设置:
192.168.5.129 hadoop4
里面其它配置就不多说了同时操作3个窗口添加3台主机映射
vi /etc/hosts192.168.5.129 hadoop2
192.168.5.139 hadoop3
192.168.5.149 hadoop4同时操作配置公私钥,免密登陆
ssh-keygen -t rsa -P ‘’
这样每台机就有各自的公私钥查看是否生成了公私钥
cd ~/.ssh/
ls
当出现id_rsa.pub和 id_rsa两个文件时说明已生成了公私钥把公钥生成新的文件
cat id_rsa.pub >> authorized_keys给新的文件授权
chmod 600 authorized_keys
这时三个窗口就都生成了新的文件每台机都拷贝同样的公钥到另2台机上,这样3台机就可以互相免密登录
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop2
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop3
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop4解析
ssh- copy-id命令可以把本地的ssh公钥文件安装到远程主机对应的主机名下
注意
因为是同时在操作3个窗口,所以当复制本机的ssh公钥时,会提示报错已存在了公钥,但是另外2台会提示输入密码,不用管报错的,直接同时输入密码就好了,这时就会把公钥复制到另外2台机上。输入登录命令
ssh hadoop2就会免密同时登录hadoop2这台机了

退出登录
exit同时操作去修改hadoop集群的配置文件
进入hadoop下去修改配置文件
cd /opt/soft/hadoop260/etc/hadoop修改配置文件hadoop-env.sh 更改jdk环境变量
vi hadoop-env.shexport JAVA_HOME=/opt/soft/jdk180
修改配置core-site.xml,在configuration添加配置信息
vi core-site.xml< !-- 指定HDFS中NameNode的地址是hadoop2 -->
fs.defaultFS hdfs://192.168.5.129:9000 hadoop.tmp.dir /opt/soft/hadoop260/tmp - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
修改配置文件hdfs-site.xml
vi hdfs-site.xmldfs.replication 3 dfs.namenode.secondary.http-address 192.168.5.149:50090 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
配置yarn-env.sh的jdk环境变量,去掉注释
vi yarn-env.sh
export JAVA_HOME=/opt/soft/jdk180配置yarn-site.xml
vi yarn-site.xmlyarn.nodemanager.aux-services mapreduce_shuffle mapreduce.framework.name yarn - 1
- 2
- 3
- 4
- 5
- 6
配置slaves 把3台虚拟机的主机名添加进去,删掉localhost
vi slaves
hadoop2
hadoop3
hadoop4添加hadoop的环境变量,添加在最后面
vi /etc/profileexport HADOOP_HOME=/opt/soft/hadoop260 export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOME- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
激活
source /etc/profile格式化NameNode 目录
hadoop namenode -format直接启动所有
start-all.shjps查看

注意
namenode在hadoop2上启动,
resourceManager在hadoop3上启动,
secondaryNamenode在hadoop4上启动
只有这样才表示集群搭建成功,
当同时启动命令时,因为是第一次启动,会要求输入密码,输入密码后,有一台启动很快,另外2台会启动缓慢,enter键输入3次就好了,并会在这两台机上出现错误提示Authentication Failed,验证失败,不用管,这是因为每一台的启动进程不一样,全部启动的时候会找不到,所以最好分开启动;有namenode的hadoop2这台机用sbin/start-dfs.sh命令启动;
有resourceManager的hadoop3这台机用sbin/start-yarn.sh命令启动;然后输入jps查看
到web页面查看
hadoop2的网址是 192.168.5.129:50070
hadoop3的网址是 192.168.5.139:8088

如果觉得同时操作三个窗口麻烦或者不熟练,可以正常按照上面的方法先安装在一台机上;
然后把hadoop目录远程拷贝到另外两台机上也是可以的。单台虚拟机操作步骤:
把配好的hadoop2拷贝到hadoop3和hadoop4
scp -r /opt/soft/hadoop260 root@hadoop3:$PWDscp -r /opt/soft/hadoop260 root@hadoop4:$PWD
拷贝好后
格式化HDFS 在安装有namnode这台机上,下这个命令也就是hadoop2这台机,切记
hadoop namenode -format启动HDFS 在hadoop2 上
sbin/start-dfs.sh启动yarn在hadoop3 上
sbin/start-yarn.sh如果namenode在hadoop2上启动成功,
resourceManager在hadoop3上启动成功,
secondaryNamenode在hadoop4上启动成功,
这样的话也就表示集群搭建成功。个人建议还是同步操作比较好,因为远程拷贝的时候,文件太多,有时会出现拷贝不完整的情况,导致启动会报错,很麻烦。
最后说下时间同步,如果时间不同步的话,会导致拷贝的进程速度不一样,是拷贝两个的文件出现断裂,断档,也就是说当同时拷贝某文件时,每台虚拟机时间时不一样的,一台时间快,一台时间慢,时间不对等会得不到响应,慢的那台会觉得时间没到响应的时间,所以为了不让这种情况发生,必须让集群的时间同步。
时间同步 操作步骤:
在hadoop2这台机上操作,因为有NameNode下载安装ntp
rpm -qa|grep ntp
yum -y install ntp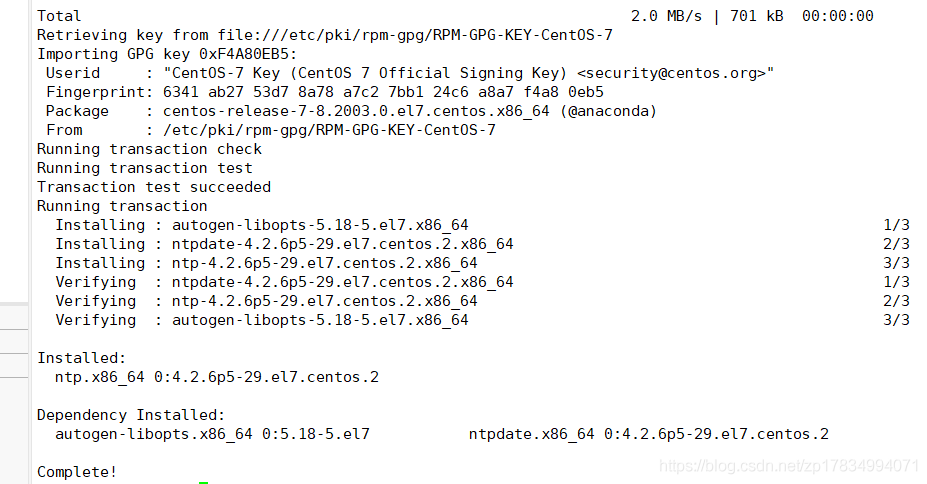
如图所示,说明已经安装成功!修改ntp的配置文件
vi /etc/ntp.conf修改1(设置本地网络上的主机不受限制。)
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
去掉这行的注释如下图所示!

修改2(设置为不采用公共的服务器)
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
四行都注释掉,如下图所示

添加3(添加默认的一个内部时钟数据,使用它为局域网用户提供服务。)
server 127.127.1.0
fudge 127.127.1.0 stratum 10修改/etc/sysconfig/ntpd配置
vi /etc/sysconfig/ntpd增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes重新启动ntpd
systemctl restart ntpd每台机安装ntpdate
yum -y install ntpdate在另外2台机上同步hadoop2的时间
ntpdate hadoop2
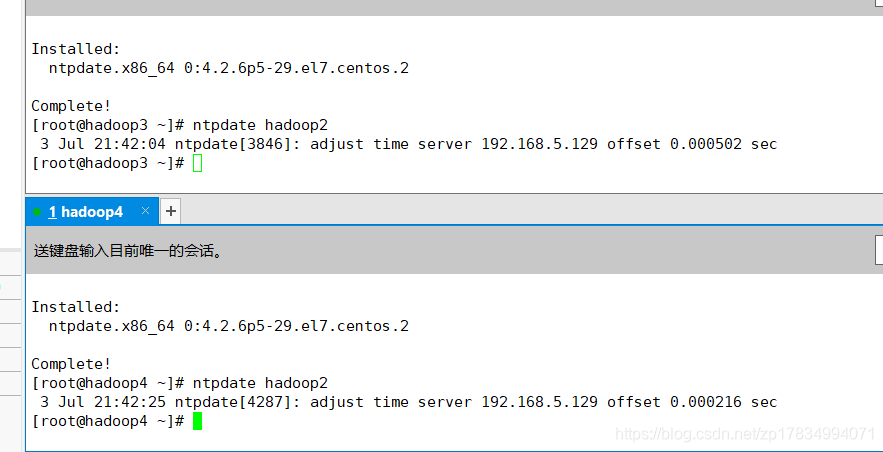 如图所示,已同步hadoop2的时间!
如图所示,已同步hadoop2的时间!hadoop3和hadoop4配置同步时间的间隔
crontab -e添加配置
*/10 * * * * /usr/sbin/ntpdate hadoop2 每隔10分钟同步时间,根据Hadoop2的时间- 1
- 2

到这里时间也就同步了! -
相关阅读:
从数据库中读取文件导出为Excel
java垃圾回收-三色标记法
MATLAB实现相关性分析
深度学习 opencv python 公式识别(图像识别 机器视觉) 计算机竞赛
Blazor前后端框架Known-V1.2.14
idea常用的一些配置信息
2023第十七届中国品牌节 | 每日互动刘宇分享大模型创新应用AITA智选人群工具
jsPlumb导航器
史上最全的NLP中的数据增强方法!
Java前后端分离项目生成二维码链接带中文参数遇到的问题及解决办法
- 原文地址:https://blog.csdn.net/m0_67392661/article/details/126367938