-
ESANet语义分割与realsense D455的结合
paper:Efficient RGB-D Semantic Segmentation for Indoor Scene Analysis
网络结构如下,相比于基于RGB图像的语义分割,该网络用了RGB与深度图结合。
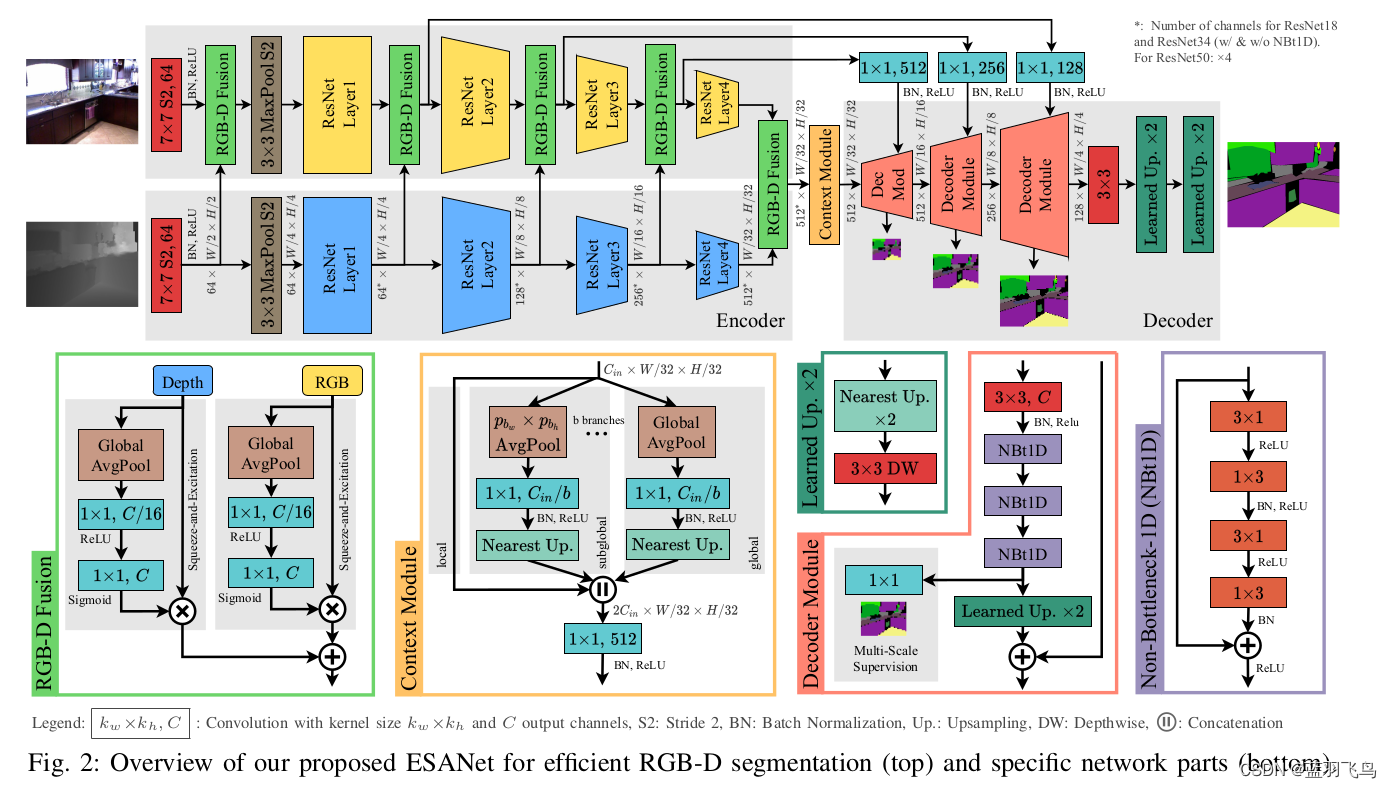
既然是RGBD,就可以用RGBD相机来测试了,选择realsense d455相机。用ROS接口读入RGB图像与深度图。
这里要注意图像需要经过预处理,通过ESANet的源码,得知在validate阶段需要做以下预处理。
transform_list = [Rescale(height=height, width=width)] transform_list.extend([ ToTensor(), Normalize(depth_mean=depth_mean, depth_std=depth_std, depth_mode=depth_mode) ])- 1
- 2
- 3
- 4
- 5
- 6
- 7
包含了Rescale, toTensor和normalize,
Rescale如下:image = cv2.resize(image, (self.width, self.height), interpolation=cv2.INTER_LINEAR) depth = cv2.resize(depth, (self.width, self.height), interpolation=cv2.INTER_NEAREST)- 1
- 2
- 3
- 4
toTensor就是把RGB和深度图变为torch.tensor
image = image.transpose((2, 0, 1)) depth = np.expand_dims(depth, 0).astype('float32') image = torch.from_numpy(image).float() depth = torch.from_numpy(depth).float()- 1
- 2
- 3
- 4
- 5
然后是Normalize,RGB图要做归一化处理,均值方差可能是根据训练集图像来的,可以根据自己的数据进行修改,
深度图的mean, std要根据自己的数据计算,直接用代码里面的效果不好。
有时候深度图会有nan值的情况,需要用到np.nan_to_num函数,d455相机没有nan值。
normalize之后一定要把之前0处的值置为0。image = image / 255 image = torchvision.transforms.Normalize( mean=根据数据, std=根据数据)(image) if self._depth_mode == 'raw': depth_0 = depth == 0 depth = torchvision.transforms.Normalize( mean=根据数据, std=根据数据)(depth) # set invalid values back to zero again depth[depth_0] = 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
剩下就是过模型,input size可以选的,这里选的是(640, 480)
# Do inference outputs = self.model(img, depth) #N,C,W,H- 1
- 2
对于不复杂的场景,效果还是不错的,尤其是轮廓比较整齐,
下图场景中墙上的画,椅子,台灯轮廓都很清楚

但是对于复杂的场景(ex.桌子上乱七八糟的小零碎),移动的相机效果不是很好。
一来跟训练数据集有关,这里用的是sun-rgbd数据集训练的权重。
移动中的相机分割不是很稳,类别频繁变动,可能跟场景比较复杂有关,或者参数还需要进一步调整。
下面这个场景就有点乱了

这是对一个房间的分割建图
-
相关阅读:
对 typescript 的理解
接口测试用例设计
拉普拉斯Laplace算子(高斯二阶导核)
SpringCloud 集成Sentinel
【软件分析第17讲-学习笔记】程序综合 Program Synthesis
如何重装Windows Mirosoft Store
关于处理第三方jar包的maven攻略
【python】eval函数
爬虫爬取mp3文件例子
n皇后问题,不用递归
- 原文地址:https://blog.csdn.net/level_code/article/details/126362232