-
【无标题】
信达雅原则
觉得还是要复现这篇文章,上次复现无果,半路放弃了。但是,还是觉得,这篇文章的价值是可以的,因为,可能要用到,觉得还是要做好复现。。。。
论文题目:A Unified Generative Framework for Various NER Subtasks
论文代码和论文中的描述,有矛盾部分。之前问到的一些问题:
表示上——非常感谢你关注到我们的工作。这里实际代码和论文的编码方式有点出入,有出入的地方在于,在实际代码中,label实际上占据的是[2, n_label+2]的范围,pointer是(n_label+2, n_token + n_label+2]。这里有这种出入的原因是由于,在代码中如果使用pointer在前面,由于每句话长度不一致【但是label个数是一定的】,会导致每一句话处理的时候很繁琐;而在文章中如果直接写label在前面呢,又必须在pointer描述中减去n_label,导致公式看起来更复杂了。这两者本质上是等价的。
实体测评上——我们是直接根据target_span中的数字做的计算【因为这些index数字加最后一位的entity类别已经可以唯一确定一个entity了】,没有将其转换回text entity进行评测。文章建模方法
输入序列:X=[x1,…xn],
输出序列:Y=[s11,e11,s12,e12,…t1,…tk]
输出序列中,Y是由多个实体构成的,每个实体又是由多个span构成的。每个span是由start index和end index。每个实体是由tag 标签的。
在语料集中,假设定义,实体的label set的长度是l,则label的index范围是(n,n+l]
而pointer 的index的范围是[1,n]
建模方式:generative way,即生成任务的形式。模型计算
Encoder和Decoder两部分。
其中,Encoder是对input sentence X 做编码,
Decoder是产生index,即span的index,但在解码时,需要多加一步,index2token,将index转为token。
在最终计算概率时,是将sent部分和entity tag部分,分开的的,将两部分做的concatenation,得到的向量大小为[n+l]*d,做softmax,得到最终的概率。在sent部分,相比于tag部分,多了一步,MLP的过程,有一个对He加权求和得到最终向量表示的过程。
复现
colab平台
代码已跑通(别问为啥用它,穷,没设备。。。。。)
pycharm
包安装:
- torch ==1.7.1
pip install torch==1.7.0+cu101 torchvision==0.8.1+cu101 torchaudio===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html -i https://pypi.douban.com/simple- 1
- 2
- 报错——git安装
ERROR: Error [WinError 2] 系统找不到指定的文件。 while executing command git version ERROR: Cannot find command 'git' - do you have 'git' installed and in your PATH?- 1
- 2
- 3
ERROR: Could not find a version that satisfies the requirement prettytable>=0.7.2 (from fastnlp) (from versions: none)
ERROR: No matching distribution found for prettytable>=0.7.2
镜像地址fatal: unable to access 'https://github.com/fastnlp/fastNLP/': OpenSSL SSL_read: Connection was reset, errno 10054 error: subprocess-exited-with-error- 1
- 2
解决方式:在开启VPN的情形下,在git中下载包,之后,在Pycharm中,安装对应的包。。
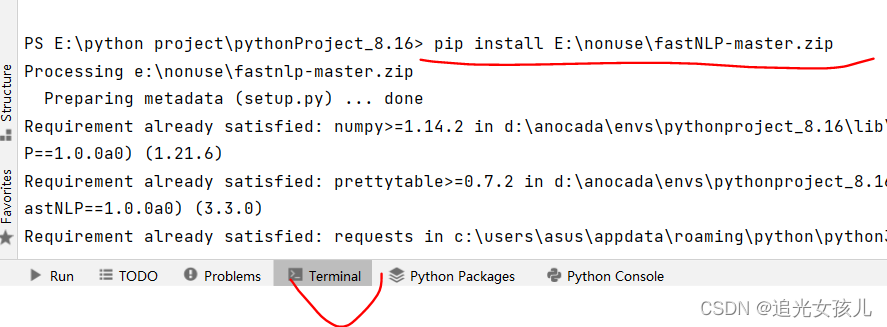
5.查看之后,确定了两个组件的版本,直接pip 安装也可以。
fastNLP0.7.0;fitlog0.9.136.代码调试成功。(但是,由于本机的GPU大小受限,只能作为代码理解的工具,如果真的跑,大概要10h,但在高GPU平台,只用了1h就结束了。)
-
相关阅读:
java实验报告6:异常处理程序设计
容器化 Spring Boot 代码的 9 个技巧
82-Java异常:概述、分类、认识、异常的默认处理流程
最新MySql安装教学,非常详细
【web-解析目标】(1.2.4)解析应用程序:解析受攻击面
使用 lua 运行 fscript
MATLAB算法实战应用案例精讲-【图像处理】图像识别分类
【uiautomation】获取微信好友名单,可指定标签 & 全部
【WP】猿人学13_入门级cookie
ASW3410数据手册|ASW3410设计参数|USB3.0高速数据开关切换IC说明书
- 原文地址:https://blog.csdn.net/Hekena/article/details/126347272