-
融合边界处理机制的学习型麻雀搜索算法
一、理论基础
1、麻雀搜索算法
请参考这里。
2、HSSA搜索算法
2.1 Piecewise map初始化种群
为了改善SSA通过后续寻优方式获得的解的质量,一个优良的初始种群分布是整个算法的基础。本文采用分段映射Piecewise map来对算法的初始化阶段进行混沌变换。Piecewise map作为分段线性映射的一种,和Liebovitch map、伯努利移位映射Bernoulli shift map一样,其对分布在不同位置的初始值设置了不同的变换公式。具体的数学表达式为 x n + 1 = { x n d , 0 ≤ x n < d x n − d 0.5 − d , d ≤ x n < 0.5 1 − d − x n 0.5 − d , 0.5 ≤ x n < 1 − d 1 − x n d , 1 − d ≤ x n < 1 (1) x_{n+1}=
\tag{1} xn+1=⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧dxn,0≤xn<d0.5−dxn−d,d≤xn<0.50.5−d1−d−xn,0.5≤xn<1−dd1−xn,1−d≤xn<1(1)其中, d d d为一个控制参数,用于决定四段式的分段范围使他们之间无重叠的部分。实验证明, d = 0.3 d=0.3 d=0.3时效果最佳,故本文实验中 d d d均取0.3。\begin{dcases}\frac{x_n}{d},\quad\quad\quad\quad\,\,\, 0\leq x_n<d\\[2ex]\frac{x_n-d}{0.5-d},\quad\quad\,\,\, d\leq x_n<0.5\\[2ex]\frac{1-d-x_n}{0.5-d},\quad 0.5\leq x_n<1-d\\[2ex]\frac{1-x_n}{d},\quad\quad\,\,\,\,\, 1-d\leq x_n<1\end{dcases}
图1(a)为随机初始化生成的种群分布图(2维),图1(b)为使用Piecewise map后的种群分布情况。可以看出映射后的初始化分布中群体的分散程度更高,且在边界上的个体和重合的个体数量更少。在初始化阶段分布的广度较大能够保证种群的多样性,且减少局部最优的吸引。

(a) 随机初始化

(b) Piecewise map初始化 图1 初始种群分布 2.2 自适应警戒者策略
固定不变的警戒者数量并不能够最大化其在整个过程中的作用。实际上,在觅食行为的初期,全局搜索的要求更高,需要更多的警戒者去尝试竞争最优位置,迫使领头的个体能够提高自身的勘探能力;而随着迭代的进行,少量的警戒者既能够保留一定的跳出机制,又不会频繁的干扰对于最优解的开发。因此,本文对警戒者的数量占全体数量的比例 S D SD SD进行动态的改变,最大化警戒者的作用,公式如下: S D = { 20 × e a e a + 1 a = T t − 1 (2) SD=
\tag{2} SD=⎩⎪⎪⎨⎪⎪⎧20×ea+1eaa=tT−1(2)通过上述数学公式可以看出, S D SD SD初期占据整个种群的20%,随着迭代的进行,逐渐减小到10%附近,有效增大了警戒者机制在全局的发挥。\begin{dcases}20\times\frac{e^a}{e^a+1}\\[2ex]a=\frac Tt-1\end{dcases} 2.3 多策略学习机制
2.3.1 排序配对学习策略
将最优和最差的学习进行配对学习不能够实现个体之间的最佳辅导效率。而如果将学生的能力进行排序,并分成前半部分和后半部分,再分别由后半部分的学生对应向前面部分的同序号学生进行学习,这样可以实现辅导效率的最大化。在 SSA中,麻雀类比学生,而适应度值就代表成绩。基于上述原则,提出了一种全新的学习策略:排序配对学习(Ranking paired learning, RPL)。其基本思想描述如下:将种群中的全部的 M M M个个体按照适应度大小进行排序,平均分成两个自然组,组内个体位置占优的组称为范例组(Group of exemplars, GE),个体记为 x i E x_i^E xiE;个体位置差的组称为学习组(Group of learners, GL),个体称为 x i L x_i^L xiL,两组均有 M / 2 M/2 M/2个个体。图2展示了RPL的核心思想。通过上述描述可知,RPL应满足: G E ∩ G L = ∅ (3) GE\cap GL=\varnothing\tag{3} GE∩GL=∅(3) ∀ x i E ∈ G E a n d ∀ x i L ∈ G L , f ( x i E ) < f ( x i L ) (4) \forall x_i^E\in GE\,\,and\,\,\forall x_i^L\in GL,\,\,f(x_i^E)

图2 排序配对学习示意图 定义参数 D D D表示学习者 x i L x_i^L xiL与被学习者 x i E x_i^E xiE的差值,改进后的 D D D满足: D = { f ( x i E ) − f ( x i L ) f ( x i L ) , D ≠ 0 cos ( π ( T − t ) 2 T ) , D = 0 (7) D=
\tag{7} D=⎩⎪⎪⎨⎪⎪⎧f(xiL)f(xiE)−f(xiL),D=0cos(2Tπ(T−t)),D=0(7)当 D D D的值不为0,满足括号内的上面式子;反之, D D D按照下面的式子得到一个 ( 0 , 1 ) (0,1) (0,1)的随机值。 x i L x_i^L xiL的学习公式满足: x i ′ L = ( D + 1 ) ⋯ x i L (8) x_i'^L=(D+1)\cdots x_i^L\tag{8} xi′L=(D+1)⋯xiL(8)在跟随者阶段将学习后得到的解和之前的解进行比较,通过贪婪原则保留更优的位置。贪婪选择的数学表达式如下: x i = { x i ′ L , f ( x i ′ L ) ≤ f ( x i L ) x i L , f ( x i ′ L ) > f ( x i L ) (9) x_i=\begin{dcases}\frac{f(x_i^E)-f(x_i^L)}{f(x_i^L)},\quad\,\,\,\, D\neq0\\[2ex]\cos\left(\frac{\pi(T-t)}{2T}\right),\quad D=0\end{dcases} \tag{9} xi=⎩⎨⎧xi′L,f(xi′L)≤f(xiL)xiL,f(xi′L)>f(xiL)(9)\begin{dcases}x_i'^L,\quad f(x_i'^L)\leq f(x_i^L)\\[2ex]x_i^L,\quad\, f(x_i'^L)> f(x_i^L)\end{dcases} 2.3.2 竞争学习策略
为了在进入下一次循环之前能够对解的质量有所保证,保持较优解的存在以及将给予较差的解学习机会可以很好地解决较优解丢失的问题,同时保证下一次输入的精度。在该思想的基础上提出了一种竞争学习的策略,其思想可描述为:在每一次迭代中,将该阶段种群中的所有个体都进行两两组队。本文设置个体数目为 M M M,则拥有 M / 2 M/2 M/2个小组。对于每个小组中的两个个体,都进行适应度的比较。将适应度好的直接保存并进入下一次迭代,而对于适应度差的个体,则要采取相应的学习机制(式(10))来更新自己的位置: x i , j ′ t = x i , j ′ t + λ ( x b ′ − x i , j ′ t ) (10) x_{i,j}'^t=x_{i,j}'^t+\lambda(x_b'-x_{i,j}'^t)\tag{10} xi,j′t=xi,j′t+λ(xb′−xi,j′t)(10)其中, λ \lambda λ为服从正态分布的随机数; x b ′ x_b' xb′为当前迭代中竞争学习策略开始前排序时的最优解。每一次竞争学习之后,半数的个体位置会得到更新并以新值传递至下一次迭代中。图 3展示了竞争学习的主要思想。
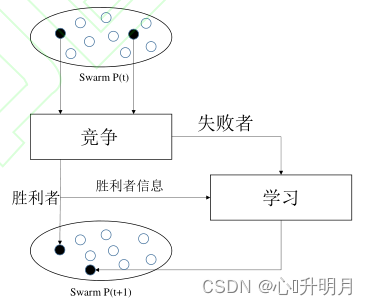
图3 竞争学习示意图 结合竞争学习的策略提出了将随机匹配的两个个体进行比较之后再更新较差的个体,胜出者直接晋级下一次迭代的方法。这样不仅不会使得较优的个体位置丢失,最大程度地运用了优秀个体的信息。同时,随机选择竞争个体的机制也保留了群智能算法的随机性这一特点,便于验证算法的鲁棒性。
2.4 多策略边界处理
在发现者阶段,整个种群应当致力于寻找新的食物,当前最优即是潜在的最合适觅食点。但是觅食的初期伴随着最优位置的不确定性,故个体的边界处理应当保留一定的随机性。同理,在警戒者更新之后,紧接着就会是下一次迭代的开始,初始化的种群越分散,相应阶段的策略开展获取最优解的可能性就越大。随机性较强的处理方法赋予了种群的一定几率的跳出局部最优的能力。下面给出该阶段处理方法: x i ′ = u b − ( u b − l b ) ⋅ r a n d , x > u b o r x < l b (11) x_i'=ub-(ub-lb)\cdot rand,\,\,x>ub\,\,or\,\,x
考虑到原来的SSA中,跟随者阶段的更新操作会产生两种情况,其一维示意图如图4所示。图(a)的情况是个体更新之后的位置超出上边界,图(b)则是更新后的位置超出下边界。为了使处理后的麻雀个体重回既定边界内,又能够充分运用到几个重要位置(当前全局最优 x b x_b xb、更新前的位置 x i x_i xi、更新后的跟随者位置 x i x_i xi、函数的上下界 l b lb lb和 u b ub ub)的信息。同时,为了和原始跟随者的更新方向保持一致(如图4中箭头所示),按照超出边界的两种不同情况提出如下公式。
超出上边界: x i ′ ′ = x b + ∣ u b − x b ∣ ⋅ ∣ x i − u b ∣ ∣ x i ′ − x i ∣ (12) x_i''=x_b+|ub-x_b|\cdot\frac{|x_i-ub|}{|x_i'-x_i|}\tag{12} xi′′=xb+∣ub−xb∣⋅∣xi′−xi∣∣xi−ub∣(12)超出下边界: x i ′ ′ = x b − ∣ l b − x b ∣ ⋅ ∣ x i − l b ∣ ∣ x i ′ − x i ∣ (13) x_i''=x_b-|lb-x_b|\cdot\frac{|x_i-lb|}{|x_i'-x_i|}\tag{13} xi′′=xb−∣lb−xb∣⋅∣xi′−xi∣∣xi−lb∣(13)不难看出, ∣ l b − x b ∣ |lb-x_b| ∣lb−xb∣和 ∣ u b − x b ∣ |ub-x_b| ∣ub−xb∣控制了步长的单位距离,而后面的分式控制了单位数。两者的结合实现了对于位置更新的步长控制,能够保证处理后的位置在预设的范围内。

(a) 超出上边界

(b) 超出下边界 图4 跟随者阶段边界处理示意图 2.5 HSSA算法流程
HSSA算法利用Piecewise map初始化种群,在跟随者和警戒者的位置更新完成后分别加入排序配对学习和竞争学习,最大化每一次迭代中较优的部分解的信息以此来更新差解,并保证将最优解群传递至下一代中。此外,自适应警戒者的处理使得警戒者群体的重要性被强调。同时,根据不同阶段的更新意义制定多策略边界处理机制,使得种群分布更合理,并保证了种群的多样性。具体实现步骤如下:
步骤1:设置初始化种群及各参数,包括种群规模 N N N,发现者比例 P D PD PD、警戒者比例 S D SD SD,目标函
数的维度设置为 D D D、初始值的上下界分别设定为 l b lb lb、 u b ub ub,最大迭代次数 T T T,报警阈值 S T ST ST,求解精度 ε \varepsilon ε。
步骤2:使用式(1)中的Piecewise map初始化种群。
步骤3:计算每只麻雀的适应度 f i f_i fi,选出当前最优适应度 f b f_b fb和其所对应的位置 x b x_b xb,以及当前最劣适应度 f w f_w fw和其对应的位置 x w x_w xw。
步骤4:根据设置的比例 P D PD PD随机选取适应度最优的 p N u m pNum pNum个麻雀作为发现者,剩下的作为加入者,并更新发现者的位置。按照式(11)进行边界处理。
步骤5:确定跟随者群体,并更新加入者的位置。
步骤6:对当前种群按照适应度值再次排序,并根据式(7)~式(9)再次更新种群。按式(12)和式(13)进行边界处理。
步骤7:从种群中按照比例 S D SD SD随机生成 s N u m sNum sNum个警戒者,并根据式(2)对 S D SD SD进行更新。同时,根
据原始更新公式和式(10)进行警戒者位置更新操作,按照式(11)进行边界处理。
步骤8:根据麻雀种群当前的状态,更新整个种群在整个觅食过程中的最优位置 x b x_b xb,最佳适应度值 f b f_b fb,以及最差位置 x w x_w xw和最坏适应度值 f w f_w fw。
步骤9:判断迭代是否结束。若算法达到最大迭代次数或者求解精度达到设定值,则判定循环结束,并输出寻优结果;否则返回步骤3继续下一次迭代操作,且当前迭代次数 t = t + 1 t=t+1 t=t+1。二、仿真实验和结果分析
将HSSA与PSO、WOA、GWO、BOA、TLBO和SSA进行对比,以常用23个测试函数中的F3、F4(单峰函数/30维)、F9、F10(多峰函数/30维)、F17、F21(固定维度多峰函数/2维、4维)为例,实验设置种群规模为100,最大迭代次数为500,每种算法独立运算30次,结果显示如下:





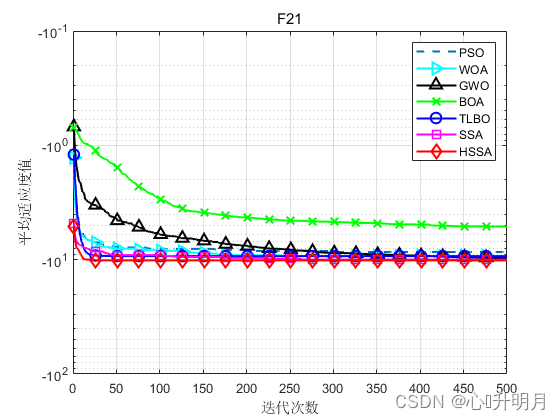
函数:F3 PSO:最差值: 33.9207, 最优值: 8.7797, 平均值: 16.7741, 标准差: 5.2392 WOA:最差值: 31922.8302, 最优值: 2508.57, 平均值: 15799.5452, 标准差: 7058.7466 GWO:最差值: 1.169e-10, 最优值: 6.8858e-15, 平均值: 9.7034e-12, 标准差: 2.2982e-11 BOA:最差值: 6.5804e-11, 最优值: 4.1646e-11, 平均值: 5.1567e-11, 标准差: 5.6942e-12 TLBO:最差值: 3.1395e-106, 最优值: 7.4825e-109, 平均值: 2.3791e-107, 标准差: 5.6521e-107 SSA:最差值: 1.7252e-200, 最优值: 0, 平均值: 5.7507e-202, 标准差: 0 HSSA:最差值: 0, 最优值: 0, 平均值: 0, 标准差: 0 函数:F4 PSO:最差值: 4.9114, 最优值: 0.61414, 平均值: 1.2679, 标准差: 0.8108 WOA:最差值: 88.4229, 最优值: 0.0004186, 平均值: 19.7548, 标准差: 25.3745 GWO:最差值: 4.8926e-10, 最优值: 1.892e-11, 平均值: 1.4902e-10, 标准差: 1.1752e-10 BOA:最差值: 3.5817e-08, 最优值: 2.5204e-08, 平均值: 3.0567e-08, 标准差: 2.9036e-09 TLBO:最差值: 1.2704e-50, 最优值: 1.5968e-52, 平均值: 1.4124e-51, 标准差: 2.3148e-51 SSA:最差值: 1.6516e-174, 最优值: 0, 平均值: 5.5052e-176, 标准差: 0 HSSA:最差值: 0, 最优值: 0, 平均值: 0, 标准差: 0 函数:F9 PSO:最差值: 120.4211, 最优值: 54.2795, 平均值: 80.4849, 标准差: 17.7901 WOA:最差值: 0, 最优值: 0, 平均值: 0, 标准差: 0 GWO:最差值: 10.6532, 最优值: 0, 平均值: 0.81471, 标准差: 2.3041 BOA:最差值: 3.626e-08, 最优值: 0, 平均值: 1.274e-09, 标准差: 6.617e-09 TLBO:最差值: 0, 最优值: 0, 平均值: 0, 标准差: 0 SSA:最差值: 0, 最优值: 0, 平均值: 0, 标准差: 0 HSSA:最差值: 0, 最优值: 0, 平均值: 0, 标准差: 0 函数:F10 PSO:最差值: 3.6955, 最优值: 1.3211, 平均值: 2.5288, 标准差: 0.58737 WOA:最差值: 7.9936e-15, 最优值: 8.8818e-16, 平均值: 4.0856e-15, 标准差: 2.5294e-15 GWO:最差值: 3.2863e-14, 最优值: 2.2204e-14, 平均值: 2.7297e-14, 标准差: 3.4512e-15 BOA:最差值: 2.9301e-08, 最优值: 1.3931e-08, 平均值: 2.1611e-08, 标准差: 3.1866e-09 TLBO:最差值: 4.4409e-15, 最优值: 4.4409e-15, 平均值: 4.4409e-15, 标准差: 0 SSA:最差值: 8.8818e-16, 最优值: 8.8818e-16, 平均值: 8.8818e-16, 标准差: 0 HSSA:最差值: 8.8818e-16, 最优值: 8.8818e-16, 平均值: 8.8818e-16, 标准差: 0 函数:F17 PSO:最差值: 0.39796, 最优值: 0.39789, 平均值: 0.3979, 标准差: 2.1312e-05 WOA:最差值: 0.39789, 最优值: 0.39789, 平均值: 0.39789, 标准差: 3.2544e-07 GWO:最差值: 0.39789, 最优值: 0.39789, 平均值: 0.39789, 标准差: 6.6983e-07 BOA:最差值: 0.39851, 最优值: 0.39789, 平均值: 0.39803, 标准差: 0.00014701 TLBO:最差值: 0.39789, 最优值: 0.39789, 平均值: 0.39789, 标准差: 0 SSA:最差值: 0.39789, 最优值: 0.39789, 平均值: 0.39789, 标准差: 0 HSSA:最差值: 0.39789, 最优值: 0.39789, 平均值: 0.39789, 标准差: 0 函数:F21 PSO:最差值: -2.6303, 最优值: -10.1532, 平均值: -8.562, 标准差: 2.9831 WOA:最差值: -2.6305, 最优值: -10.1532, 平均值: -9.311, 标准差: 2.2275 GWO:最差值: -5.0552, 最优值: -10.1531, 平均值: -9.644, 标准差: 1.5507 BOA:最差值: -4.5488, 最优值: -7.0364, 平均值: -5.1356, 标准差: 0.68189 TLBO:最差值: -5.0552, 最优值: -10.1532, 平均值: -9.3035, 标准差: 1.9324 SSA:最差值: -5.0552, 最优值: -10.1532, 平均值: -9.9833, 标准差: 0.93076 HSSA:最差值: -10.1532, 最优值: -10.1532, 平均值: -10.1532, 标准差: 6.4471e-15- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
实验结果证明了HSSA在收敛速度上的稳定性和寻优的高效性。
三、参考文献
[1] 王子恺, 黄学雨, 朱东林, 等. 融合边界处理机制的学习型麻雀搜索算法[J/OL]. 北京航空航天大学学报: 1-16 [2022-08-16].
-
相关阅读:
leetcode 14天算法入门 C语言实现
完美三元组(normal version)
生命周期详解
Pandas Excel数据处理指南
1333:【例2-2】Blah数集
使用Java的方式配置Spring
‘vue‘ 不是内部或外部命令,也不是可运行的程序或批处理文件
hash模式和history模式
SSL数字证书服务
【2022感恩节活动营销理念】跨境电商卖家必知 !
- 原文地址:https://blog.csdn.net/weixin_43821559/article/details/126364008