-
Elasticsearch压测工具esrally详解
rally 工具是 Elastic 官方开源的针对性性能压测工具。目前 Elasticsearch 的 nightly performance report 就是由 rally 产生的。对自己在做 ES 源码修改,或者ES 应用调优的人来说
,通过 rally 验证自己的修改效果,是一件很需要且容易的事情。
环境:python3.4+ ;pip3;JDK8;git 1.9+;gradle 2.1+
安装:
pip3 install esrally
安装部署请参照本博客其他文档。由于elasticsearch的运行必须非root账户。esrally建议用非root账户执行。“race”表示Rally一次压测过程。你可以使用不同的数据集(称之为tracks)来进行压测。
配置:
esrally configure
按照提示输入java环境变量:/export/servers/jdk1.8.0_60加强版配置:(一般不需要)
esrally configure --advanced-config运行第一个案例:
esrally --distribution-version=5.0.0可用tracks列表
esrally list tracks离线测试数据
拷贝 .rally.zip --> /home/admin/.rally.zip
unzip .rally.zip
vim /home/admin/.rally/rally.ini修改为
root.dir = /home/admin/.rally/benchmarks
default.url = /home/admin/.rally/benchmarks/tracks/default理解:
data:压测数据
distributions:ES安装包
races:测试报告
tracks:测试用例离线方式运行
esrally --offline --pipeline=from-distribution --distribution-version=5.2.0 --track=tiny --challenge=append-fast-no-conflicts默认情况下压测采用的数据集叫 geonames,是一个 2.8GB 大的 JSON 数据。ES 也提供了一系列其他类型的压测数据集。如果要切换数据集采用 --track 参数:
esrally --pipeline=from-distribution --distribution-version=5.2.0 --track=geonames重复运行的时候可以修改 ~/.rally/rally.ini 里的 tracks[default.url] 为第一次运行时下载的地址: ~/.rally/benchmarks/tracks/default 。
然后离线运行:
esrally --offline --pipeline=from-distribution --distribution-version=5.2.0 --track=geonames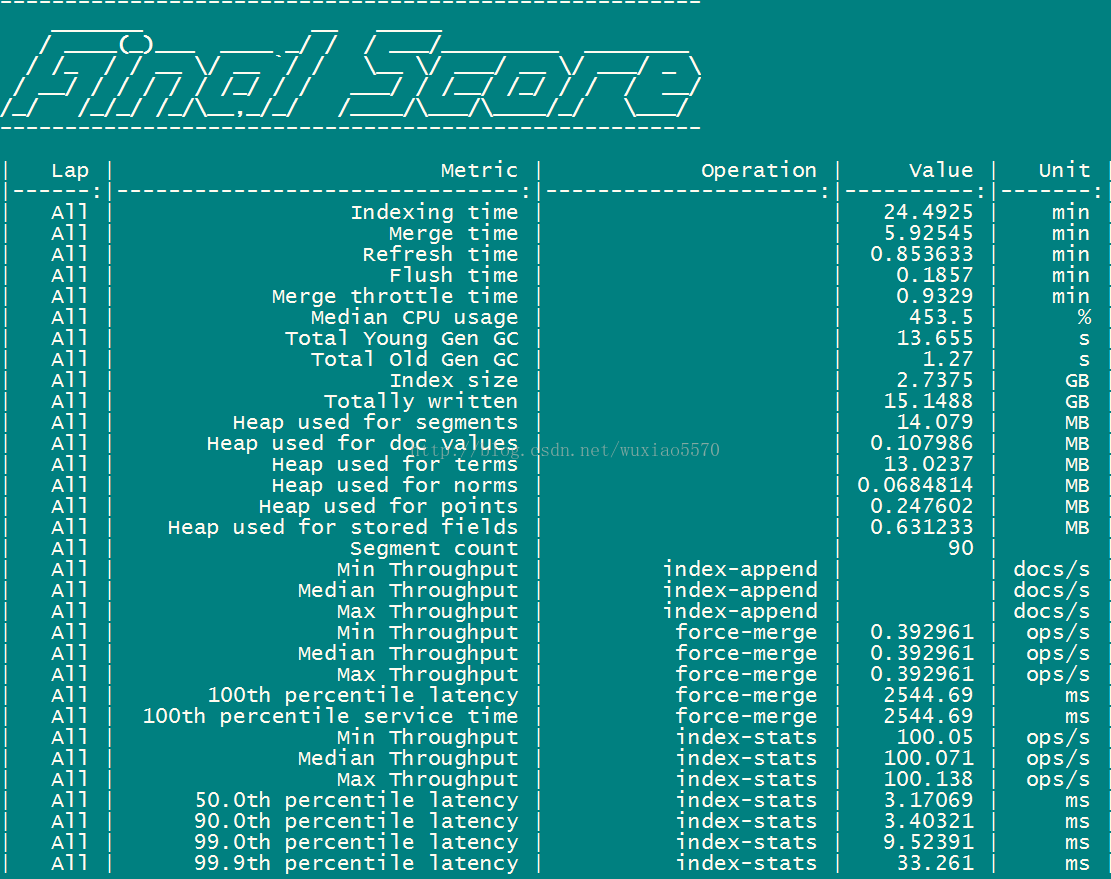
参数理解:
Pipelines管道–基准
A pipeline is a series of steps that are performed to get benchmark results. This is not intended to customize the actual benchmark but rather what happens beforeand after a benchmark.
from-distribution 由rally启动一个ES集群,进行测试
benchmark-only 测试外部ES集群Track
A track is the description of one ore more benchmarking scenarios with a specific document corpus. It defines for example the involved indices, data files and whichoperations are invoked.
调用特定文档语料库(测试数据源)Challenge
The challenges section contains a list of challenges which describe the benchmark scenarios for this data set. It can reference all operations that are defined inthe operations section.
挑战部分包含一个列表描述基准场景数据集。数据源:
/home/admin/.rally/benchmarks/data/geonames/documents.json测试方式:
测试一个本地ES集群:
esrally --offline --pipeline=benchmark-only --target-hosts=127.0.0.1:9200 --track=tiny --challenge=append-fast-no-conflicts
esrally --pipeline=benchmark-only --target-hosts=127.0.0.1:9200压测远端ES集群:
esrally --pipeline=benchmark-only --target-hosts=192.168.1.1:9200,192.168.1.2:9200调整压测任务:
如果你其实只关心部分的性能,比如只关心写入,不关心搜索。其实可以自己去修改一下 track 的任务定义。
track 的定义文件在 ~/.rally/benchmarks/tracks/default/geonames/track.json。
建议直接新建一个 track 目录,比如叫 mytest/track.json。
对照 geonames 里的定义,一个 track 包括以下部分:
meta:定义数据来源 URL。
indices:定义索引名称、索引 mapping 的文件位置、数据的存放位置和校验信息。
operations:定义一个个操作的名称、类型、索引和请求参数。如果操作类型是 index,可用的索引参数有:client 并发量、bulk 大小、是否强制 merge 等;如果操作类型是 search,可用的请求参数就是一个 queries 数组,按序放好一个个 queryDSL。
challenges:定义好名称和调用哪些 operation,调用顺序如何。自定义数据集
{
“meta”: {
“data-url”: “/Users/raochenlin/.rally/benchmarks/data/splunklog/1468766825_10.json.bz2”
},
“indices”: [
{
“name”: “splunklog”,
“types”: [
{
“name”: “type”,
“mapping”: “mappings.json”,
“documents”: “1468766825_10.json.bz2”,
“document-count”:924645,
“compressed-bytes”: 19149532,
“uncompressed-bytes”: 938012996
}
]
}
]自定义测试源准备:
数据源下载http://download.geonames.org/export/dump/allCountries.ziptoJSON.py
import json
import csvcols = ((‘geonameid’, ‘int’),
(‘name’, ‘string’),
(‘asciiname’, ‘string’),
(‘alternatenames’, ‘string’),
(‘latitude’, ‘double’),
(‘longitude’, ‘double’),
(‘feature_class’, ‘string’),
(‘feature_code’, ‘string’),
(‘country_code’, ‘string’),
(‘cc2’, ‘string’),
(‘admin1_code’, ‘string’),
(‘admin2_code’, ‘string’),
(‘admin3_code’, ‘string’),
(‘admin4_code’, ‘string’),
(‘population’, ‘long’),
(‘elevation’, ‘int’),
(‘dem’, ‘string’),
(‘timezone’, ‘string’))with open(‘allCountries.txt’) as f:
while True:
line = f.readline()
if line == ‘’:
break
tup = line.strip().split(’ ')
d = {}
for i in range(len(cols)):
name, type = cols[i]
if tup[i] != ‘’:
if type in (‘int’, ‘long’):
d[name] = int(tup[i])
elif type == ‘double’:
d[name] = float(tup[i])
else:
d[name] = tup[i]print(json.dumps(d))
python3 toJSON.py > documents.json.
bzip2 -9 -c documents.json > documents.json.bz2参考文献:
rally官网:http://esrally.readthedocs.io/en/latest/index.html -
相关阅读:
2022.8.8-8.14 AI行业周刊(第110期):值钱比赚钱更重要
分析SSH登录日志
8月一次阿里云的Java面试凉经(止步三面)
面试题 16.20. T9键盘-力扣双百代码
【STL编程】【竞赛常用】【part 2】
Presentation Prompter 5.4.2(mac屏幕提词器)
合并github未合并的PR
贝叶斯优化分步指南:基于 Python 的方法
8086 汇编笔记(六):更灵活的定位内存地址的方法
odoo 开发入门教程系列-准备一些操作(Action)?
- 原文地址:https://blog.csdn.net/web13618542420/article/details/126361259