-
金融业信贷风控算法7-分类场景之决策树和随机森林
一. 决策树的基本概念
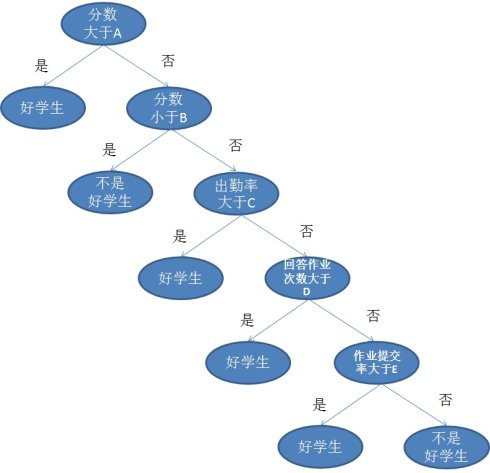
1.1 树模型
树的特点:
- 1个根节点
- 若干个叶子结点
- 若干个非叶子结点
- 具有层次性:根节点只有子节点,没有父节点;叶子结点只有父节点,没有子节点;非叶结点同时具有父、子节点
- 除根节点外,每个节点有且仅有一个父节点

1.2 决策树的定义
以X1<= t1为例,左边是满足条件的,右边是不满足条件的,下同。
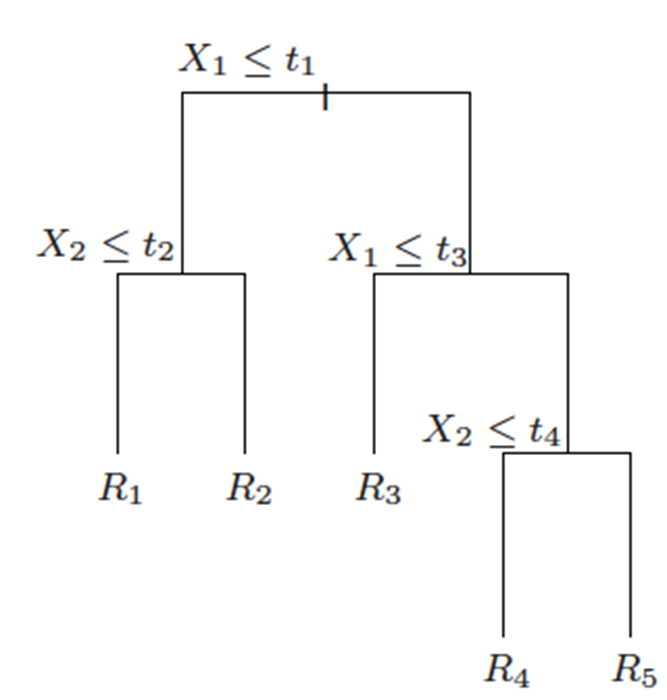
一个树结构(二叉树或非二叉树)的分类器,其每个非叶节点表示一个特征属性上的判断,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。
使用决策树进行决策的过程就是从根节点开始,判断待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
1.3 决策树的结构
**根节点:**第一个被分裂的特征。一个决策树中只有一个根节点
**叶节点:**输出决策的结果
**内部节点:**除了根节点和叶节点之外的其他节点
**路径:**从根节点到某个叶节点的唯一的联通道路,且路径上的节点(除叶节点外)是不能有重复的离散特征的。每一个可能的样本都能找到对应的并且是唯一的路径。1.4 决策树的几种常见实例
- ID3决策树
- C4.5决策树
- CART分类(回归)树

1.4 决策树的优缺点
决策树的优点:
- 能够处理数值和非数值属性
- 对数值属性的极端值不敏感
- 对属性的线性相关性不敏感
- 可以自动处理缺失值
- 很高的可解释性
- 可以用于多分类场景
决策树的缺点:
- 结构过于简单,分类精度不是很高
- 不支持增量训练
- 在属性选择、属性分裂时,无法纳入属性间的交互性
二. 决策树的构造
2.1 决策树的构造:分而治之(divide and conquer)
决策树是典型的局部与整体存在相似性的模型,即任意一条路径中,任意一个内部节点都形成以它为根节点的“子决策树”。对于这样形态的模型,高效、可行的构造方法就是分而治之。步骤如下:
输入:数据集 𝐷 = ( 𝑥 1 , 𝑦 1 ) , ( 𝑥 2 , 𝑦 2 ) , . . , ( 𝑥 𝑚 , 𝑦 𝑚 ) 𝐷={(𝑥_1,𝑦_1 ),(𝑥_2,𝑦_2 ),..,(𝑥_𝑚,𝑦_𝑚)} D=(x1,y1),(x2,y2),..,(xm,ym)及其特征空间 𝐴 = 𝑎 1 , 𝑎 2 , … , 𝑎 𝑑 𝐴={𝑎_1,𝑎_2,…,𝑎_𝑑 } A=a1,a2,…,ad
函数TreeGenerate(D,A)- 生成节点Node
- 如果数据集D全部属于某类别C,则将1中的节点Node划分为属性C,返回
- 如果A为空集,或者D在A上的取值完全一致,则1中的节点Node标记为叶节点,所属类别为D中占大多数的类别,返回
- 选择最优分裂节点a,
For each value 𝑎 𝑉 𝑎^𝑉 aV in a:
从节点Node生成一个分支,令数据集𝐷_𝑉是D在a中取值为 𝑎 𝑉 𝑎^𝑉 aV的子集
if 𝐷_𝑉是空集,则该分支作为叶节点,所属类别是D中大多数的类别,返回;else 生成分支 TreeGenerate(𝐷_𝑉, A{a})
End for
这是一个典型的递归过程,返回条件是:
- 当前节点包含的样本属于同一类别
- 当前属性为空
- 所有属性取值相同
- 当前节点包含的样本集为空
叶节点的输出:
叶子节点输出占比最大的类别,也就是输出概率最大的类别。如果改造成输出每个类别对应的概率,则可以用在随机森林中输出概率的计算。两个问题:如何选择最优属性?如何分裂节点?
最优属性的选择- 信息增益和信息增益率
- 基尼指数
分裂节点 - 离散型,取值种类少
- 离散型,取值种类多
- 连续型
2.2 信息增益(Information Gain)
衡量类别纯度的信息熵:
假设样本D中第k类样本占比为𝑝_𝐾,则D的信息熵定义为
𝐸 𝑛 𝑡 𝑟 𝑜 𝑝 𝑦 ( 𝐷 ) = − ∑ 𝑘 𝑝 𝑘 l o g 2 𝑝 𝑘 𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝐷)=−∑_𝑘𝑝_𝑘 log_2𝑝_𝑘 Entropy(D)=−k∑pklog2pk
Entropy越小,纯度越高信息熵:entropy 它表示了信息的不确定度 换句话说就是数据的混沌程度,以贷款举例,2人逾期,2人未逾期那么混沌程度最高,不确定性最高,信息熵就最大。纯度就最低。
信息增益:
若D被属性a划分成 𝐷 = ⋃ 𝑣 𝐷 𝑣 , 𝐷 𝑣 ∩ 𝐷 𝑤 = ∅ 𝐷=⋃_𝑣𝐷_𝑣 , 𝐷_𝑣∩𝐷_𝑤=∅ D=⋃vDv,Dv∩Dw=∅,定义信息增益为:
𝐺 𝑎 𝑖 𝑛 ( 𝐷 , 𝑎 ) = 𝐸 𝑛 𝑡 𝑟 𝑜 𝑝 𝑦 ( 𝐷 ) − ∑ 𝑣 ∣ 𝐷 𝑣 ∣ ∣ 𝐷 ∣ 𝐸 𝑛 𝑡 𝑟 𝑜 𝑝 𝑦 ( 𝐷 𝑣 ) 𝐺𝑎𝑖𝑛(𝐷,𝑎)=𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝐷)−∑_𝑣\frac{|𝐷_𝑣 |}{|𝐷|} 𝐸𝑛𝑡 𝑟𝑜𝑝𝑦(𝐷_𝑣) Gain(D,a)=Entropy(D)−v∑∣D∣∣Dv∣Entropy(Dv)现在我们有一份数据集D(例如贷款信息登记表)和特征A(例如年龄),则A的信息增益就是D本身的熵与特征A给定条件下D的条件熵之差,即:
g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A) = H(D) - H(D|A) g(D,A)=H(D)−H(D∣A)
数据集D的熵是一个常量。信息增益越大,表示条件熵 越小,A消除D的不确定性的功劳越大。所以要优先选择信息增益大的特征,它们具有更强的分类能力。由此生成决策树,称为ID3算法。
信息增益的作用和特点:
- 衡量从无序到有序的变化程度(常用于ID3决策树)
- 选择具有最大信息增益的属性进行分裂
- 不具有泛化能力,对取值较多的属性有偏好
为了控制属性取值数目的影响,先定义IV:
𝐼 𝑉 ( 𝑎 ) = − ∑ 𝑣 ∣ 𝐷 𝑣 ∣ ∣ 𝐷 ∣ l o g 2 ∣ 𝐷 𝑣 ∣ ∣ 𝐷 ∣ 𝐼𝑉(𝑎)=−∑_𝑣 \frac{|𝐷_𝑣 |}{|𝐷|} log_2 \frac{|𝐷_𝑣 |}{|𝐷|} IV(a)=−v∑∣D∣∣Dv∣log2∣D∣∣Dv∣
2.3 信息增益率
当某个特征具有多种候选值时,信息增益容易偏大,造成误差。引入信息增益率可以校正这一问题。
信息增益率为信息增益与数据集D的熵之比:
𝐺 𝑎 𝑖 𝑛 𝑅 𝑎 𝑡 𝑖 𝑜 = 𝐺 𝑎 𝑖 𝑛 ( 𝐷 , 𝑎 ) 𝐼 𝑉 ( 𝑎 ) 𝐺𝑎𝑖𝑛 𝑅𝑎𝑡𝑖𝑜=\frac{𝐺𝑎𝑖𝑛(𝐷,𝑎)}{𝐼𝑉(𝑎)} GainRatio=IV(a)Gain(D,a)特性:
容易倾向取值较少的属性
可以选择具有最大增益率的属性进行分裂
可以选择大于平均增益率的属性集,再选择增益率最小的属性2.4 基尼指数
另一种衡量纯度的指标
𝐺 𝑖 𝑛 𝑖 ( 𝐷 ) = 1 − ∑ 𝑘 𝑝 𝑘 2 𝐺𝑖𝑛𝑖(𝐷)=1−∑_𝑘𝑝_𝑘^2 Gini(D)=1−k∑pk2
Gini越小,纯度越高
属性a在数据集D中的基尼指数是
𝐺 𝑖 𝑛 𝑖 ( 𝐷 , 𝑎 ) = ∑ 𝑣 ∣ 𝐷 𝑣 ∣ ∣ 𝐷 ∣ 𝐺 𝑖 𝑛 𝑖 ( 𝐷 𝑣 ) 𝐺𝑖𝑛𝑖(𝐷,𝑎)=∑_𝑣\frac{|𝐷_𝑣 |}{|𝐷|} 𝐺𝑖𝑛𝑖(𝐷_𝑣) Gini(D,a)=v∑∣D∣∣Dv∣Gini(Dv)
选择具有最小基尼指数的属性,即 𝑎 ∗ = 𝑎 𝑟 𝑔 𝑚 𝑖 𝑛 𝐺 𝑖 𝑛 𝑖 ( 𝐷 , 𝑎 ) 𝑎_∗=𝑎𝑟𝑔𝑚𝑖𝑛 𝐺𝑖𝑛𝑖(𝐷,𝑎) a∗=argminGini(D,a)2.5 示例
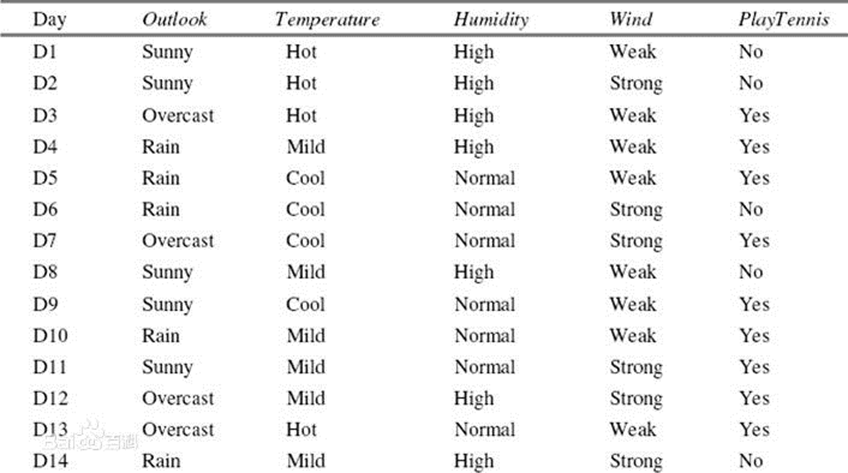
一个简单的例子:用变量outlook,temperature,humidity,wind来对playtennis进行分类。
对于outlook,它的信息增益率的计算方式为:
(1)总体的熵的计算:
P(PlayTennis=Yes) = 9/14, P(PlayTennis=No) = 5/14
Entropy = -9/14log2(9/14) – 5/14log2(5/14) =0.9403
(2)将数据集D按照Outlook进行划分,结果为:
D1: Outlook=Sunny有5个样本,其中PlayTennis=Yes有2个样本,PlayTennis=No有3个样本
Entropy1 = -2/5log2(2/5)-3/5log2(3/5) =0.9710
D2: Outlook=Overcast有4个样本,其中PlayTennis=Yes有4个样本,PlayTennis=No有0个样本
Entropy2 = -0/4log2(0/4)-4/4log2(4/4) =0 (定义0log2(0)=0)
D3: Outlook=Rain有5个样本,其中PlayTennis=Yes有3个样本,PlayTennis=No有2个样本
Entropy3 = -3/5log2(3/5)-2/5log2(2/5) = 0.9710
(3)计算IV: IV=-5/14log2(5/14)-4/14log2(4/14)-5/14log2(5/14)= 1.5774
(4)计算信息增益:Gain = 0.9403-5/14* 0.9710-4/140-5/14 0.9710= 0.2467
(5)计算信息增益率:Gain Ratio= 0.2467/ 1.5774= 0.1564计算Outlook的Gini:
(1)计算D1,D2和D3的Gini:
Gini1 = 1-(2/5)2-(3/5)2=0.4800,Gini2 = 1-(4/4)2-(0/4)2=0
Gini3 = 1-(2/5)2-(3/5)2=0.4800
(2)计算总体的Gini:
Gini(D)=5/140.4800 + 4/140 + 5/15* 2=0.4800= 0.30862.6 连续变量的处理
连续变量通过二分法离散化,然后当成离散变量来处理。

三. 防止拟合:剪枝的艺术
有很大的概率,所有属性都拿来分裂,易造成过拟合
避免过拟合,需要剪枝(pruning)。剪枝的两种方法
- 预剪枝
在决策树生成过程中,对每个节点在划分前先进行估计,若当前节点的划分不能带来决策树泛化性能的提升,则停止划分并将当前节点标记为叶节点 - 后剪枝
先从训练集中生成一颗完成的决策树,然后自底向上地对非叶节点进行考察,若将该节点对应的子树替换成叶节点能提升决策树泛化性能,则将该子树替换成叶节点
**泛化能力:**算法对新鲜样本的适应能力。可以用留出法,即在训练集中再次抽选出一部分不参与决策树构造,而用于评估某一次对某节点划分或者子树合并的测试。
四. 随机森林的基本概念
4.1 随机森林的基本概念
随机森林属于集成模型的一种。它由若干棵决策树构成,最终的判断结果由每一棵决策树的结果进行简单投票决定。
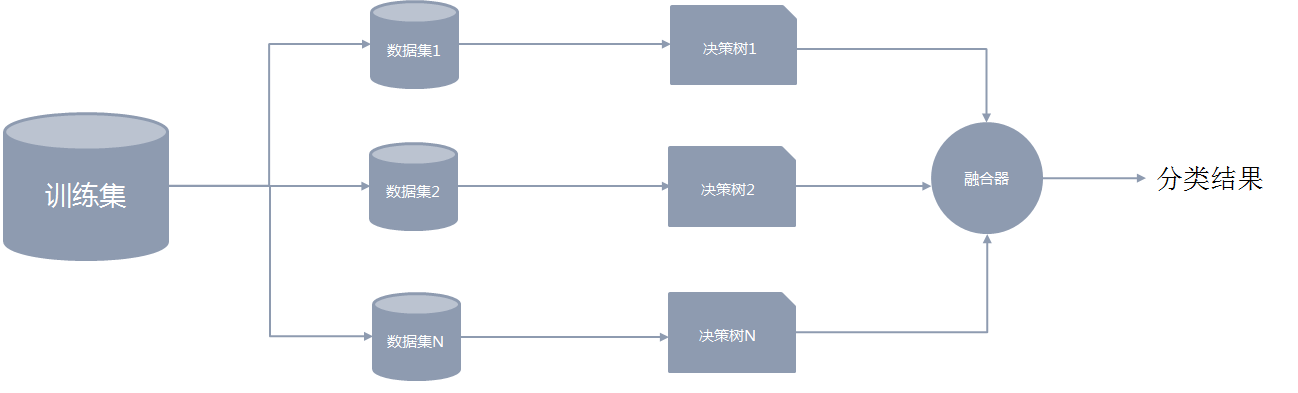
4.2 数据集的抽取
在构建随机森林模型的过程中,关键的一步是要从原数据集中多次有放回地抽取一部分样本组成新的训练集,且样本量保持不变。后续每一个决策树模型的构建都是分别基于对应的抽样训练集。
“随机森林”中的“随机”二字主要体现在2方面:- 从整体的训练集中抽取数据时,样本是有放回地抽取。
- 组成新的训练集后,再从属性集中无放回地抽取一部分属性进行决策树模型的开发
这些随机操作能很好地增强模型的泛化能力,有效避免了过拟合的问题。也别其他一些模型所借鉴(例如极大梯度提升树)。
在1中,每次有放回地生成同等样本量的数据集时,大约有1/3的样本没有被选中,留作“袋外数据”
在2中,假设原有m个属性,在第2步中一般选择log_2𝑚个属性进行决策树开发。4.3 决策树结果的融合
得到若干棵决策树后,会对模型的结果进行融合。在随机森林中,融合的方法通常是简单投票法。假设K棵决策树的投票分别是𝑡_1, 𝑡_2,…,𝑡_𝐾, 𝑡_𝑖∈{0,1},最终的分类结果是
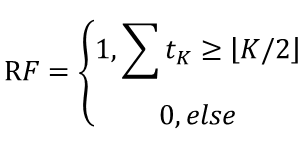
随机森林的输出概率
同时随机森林也支持以概率的形式输出结果:
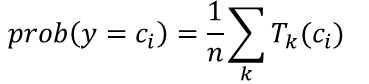
五. 特征重要性的评估
5.1 特征重要性评估
除了用于分类场景外,随机森林的重要用途之一就是给出特征的重要性的评估。在特征选择和降维中,特征的重要性是常用的依据。在随机森林中,判断变量重要性的方法就是评估每个变量在所有树上的“作用”的平均值。
对于作用的衡量,可以从两点来考虑:
- 特征的基尼指数,即特征在某节点上分列前后类别纯度的提升度。平均提升度越高,则变量的重要性越高。
- 特征在袋外数据上的分类准确性,即打乱某特征在袋外数据上的次序,看打乱前后在袋外数据上的预测错误率的上升程度。上升程度越高,说明该变量越重要。
5.2 混淆矩阵
当我们有了决策树、随机森林等分类工具后,如何衡量模型分类的准确性呢?
考虑分类模型的精度:
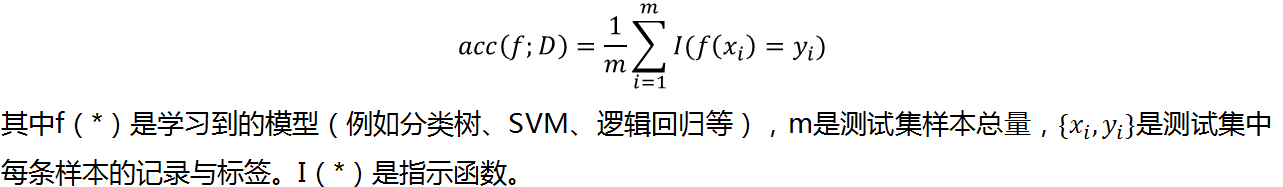
对于一般的分类场景,精度指标可能比较有效。但是在某些特定场景,例如反欺诈工作中,这类指标是不合适的。原因在于:
(1)欺诈场景中,欺诈样本的占比很少
(2)误判的损失是不一样的!在二分类场景中,混淆矩阵及其衍生指标可以较好地衡量欺诈场景中的分类模型的性能。
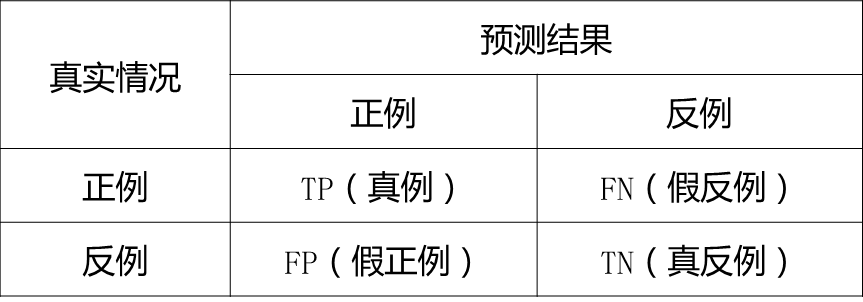
矩阵中的元素的含义:
TP: 表示真实为正、预测也为正的样本(真正例)的个数
FN: 表示真实为正、预测为反的样本(假反例)的个数
FP: 表示真实为反、预测为正的样本(假正例)的个数
TN: 表示真实为反、预测也为反的样本(真反例)的个数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hxftvAuK-1660617221783)(https://upload-images.jianshu.io/upload_images/2638478-4a361047aff3571d.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)]5.3 ROC与AUC
在诸如逻辑回归或者神经网络的分类器中,模型给出的结果并不是直接的分类结果,而是对样本属于某类的概率。此时可以选择某一个概率阈值,当预测概率超过此阈值时,认为样本属于欺诈,否则属于正常样本,进而形成混淆矩阵。由于阈值有很多种可能,于是我们有很多个混淆矩阵。如何综合判断多个混淆矩阵的结果呢?
ROC曲线(Receiver operating characteristic curve)是多个混淆矩阵的结果组合,如果在上述模型中我们没有定好阈值,而是将模型预测概率从高到低排序,将每个概率值依次作为阈值,那么就有多个混淆矩阵。
对于每个混淆矩阵,我们计算两个指标
TPR(True positive rate)= TPR=TP/(TP+FN)=Recall
FPR(False positive rate)=FP/(FP+TN)TPR就是召回率,FPR即为实际为正常样本中,预测为欺诈占比。我们以FPR为x轴,TPR为y轴画图,就得到了ROC曲线。
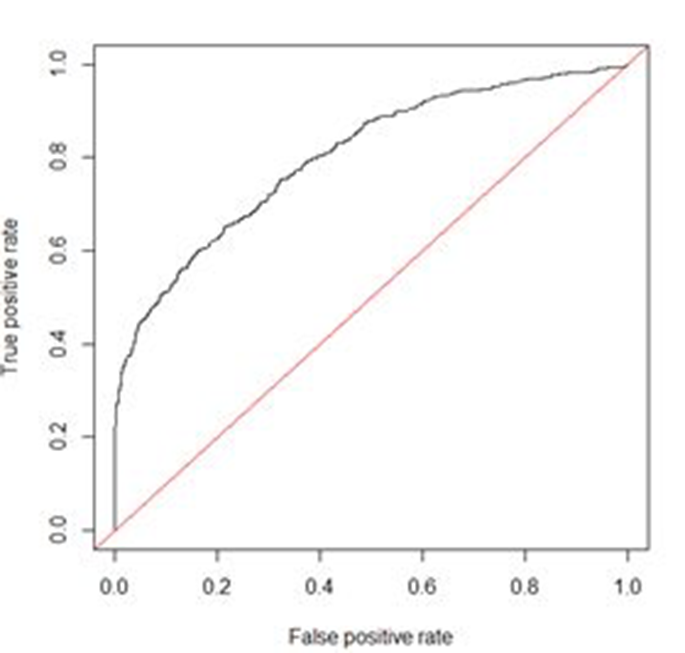
AUC(Area Under Curve)的值为ROC曲线下面的面积,若如上所述模型十分准确,则AUC为1。但现实工作中不会有如此完美的模型,一般AUC均在0.5到1之间,AUC越高,模型的区分能力越好,上图AUC为0.81。若AUC=0.5,即与上图中红线重合,表示模型的区分能力与随机猜测没有差别。若AUC真的小于0.5,表明模型很差。
KS(Kolmogorov-Smirnov)值:KS=max(TPR-FPR),即为TPR与FPR的差的最大值,KS可以反映模型的最优区分效果。KS也是评分卡模型的常用度量指标。
特别地,反欺诈领域的欺诈预测模型,由于模型结果会对识别的坏人进行一定的处置措施,FPR过高会对好人有一定干扰,造成误杀,影响客户体验,因此模型需保证在低于一定FPR的基础上尽量增加TPR。5.4 模型的调参
随机森林中有很多参数需要调优。调参工作是NP问题,当参数空间很大时,在有限时间内无法得到最优解。此时可以使用启发式搜索法,对单个参数进行调优。
随机森林模型的重要参数有:- 决策树的个数:n_estimators
- 控制复杂度的参数:max_depth,min_samples_split和min_samples_leaf
- 用于构建树模型的特征数:max_features
sklearn中的GridSearchCV可进行调参
5.4.1 模型构建——n_estimators调参
n_estimators是随机森林模型中决策树的个数,用来控制该集成模型的复杂度。 n_estimators太小会影响模型精度, n_estimators太大会造成过拟合同时增加训练时间开销。
先从大范围内进行大尺度调参:从10~100中按照步长=10寻找最优的参数,得到的结果是80
再从71~89中寻找最优的参数,步长为1,得到的结果是84.
注意:
如果某次的最优参数的选择位于边界,则意味着需要扩大选择范围。例如,如果在10100中得到的最优的参数是100,则需要将范围改为100200.5.4.2 模型构建——max_depth,min_samples_split和min_samples_leaf调参
这三个参数都是决定决策树复杂度的参数。当max_depth很大、min_samples_split或min_samples_leaf很小时,单棵决策树会生长地比较大,容易造成过拟合
这三个参数需要同时调参。设置max_depth 的范围为range(3,14,2), min_samples_split的范围为range(50,201,20), min_samples_leaf的范围是range(10,41,5)。三个参数的每一种可能的取值配对都会带入模型中进行性能评估
注意:
在寻找最优的max_depth和min_samples_split是,随机森林的n_estimators为上一步得到的最优的n_estimators。5.4.3 模型构建——max_features
max_features用来决定在构建树模型时有多少特征被抽取。适当的特征数目可以增强模型的泛化能力同时降低计算量。
除了用户自己选择的特征个数外,常用的经验值有√𝑛和log(𝑛)等选择。六. 案例: 信贷违约事件的识别
6.1 数据预处理与特征工程—缺失值
本案例中,我们继续使用Kaggle中的某违约预测数据集。我们从数据集中抽取一部分变量来构建随机森林模型进行违约预测,再将数据集按7:3划分为训练集与测试集两部分。注意到,数据集中存在缺失值,下面是变量的缺失率

其中, OWN_CAR_AGE的缺失率最高,达到66%。注意到,这个变量反映的是与车相关的信息(具体含义未知),而另一个变量FLAG_OWN_CAR则反映了借款人是否有车,因此这种缺失机制属于随机缺失。由于缺失率 价高,且OWN_CAR_AGE有一部分信息反映在FLAG_OWN_CAR中,我们将该变量删除。
OCCUPATION_TYPE、 NAME_TYPE_SUITE和AMT_ANNUITY属于完全随机缺失,理论上讲可以直接带入随机森林中,将缺失看成一种特殊的取值。然而, Python中的RandomForestClassifier不支持带入有缺失值的训练数据,需要进行缺失处理。处理方式为:
由于类别型变量如OCCUPATION_TYPE,需要做独热编码,对于其中的缺失值,独热编码全部为0
对于数值型变量如NAME_TYPE_SUITE和AMT_ANNUITY ,可以进行填充,也可以进行删除。在本案例中,上述变量缺失率很低,因此将有缺失值的样本进行删除。6.2 数据预处理与特征工程—独热编码
虽然决策树可以处理类别型变量,但是Python的RandomForestClassifier不支持直接带入非数值型变量,因此要做编码处理。我们采用独热编码的形式。需要注意的是,在测试集上进行编码,需要与在训练集上的编码方式保持一致。并且当某变量在测试集上的取值种类与训练集上的取值种类不一致时,多出来的取值对应的独热编码全部为0.
例如,在训练集中,属性“设备”的取值为{SDK,Android,PC},该属性会形成3列独热编码,假设命名为device_SDK, device_Android, device_PC。然而在测试集上,某样本的“设备”为WAP,此时对该取值的独热编码为:


6.3 数据预处理与特征工程——特征衍生
与回归模型一样,我们也需要从基础字段中衍生有业务含义的变量。例如,我们发现AMT_CREDIT、 AMT_ANNUITY和AMT_GOODS_PRICE可能与收入相关,因此我们衍生出新的变量,表示前三种变量与后一种变量的比例:

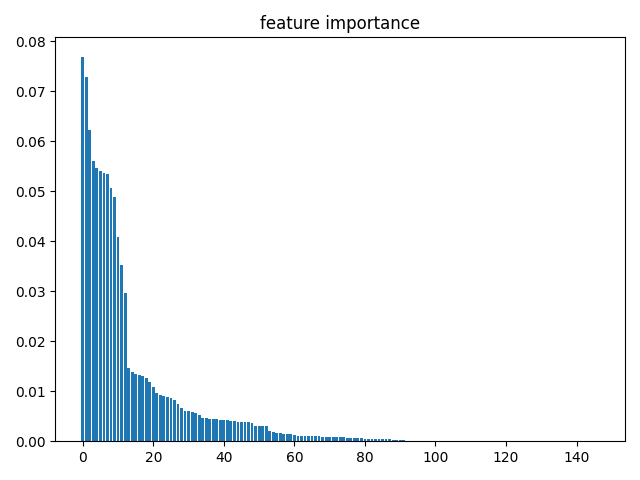
6.4 特征重要性
完成变量衍生后,我们进行调参,评估参数性能以AUC为基准,即选取出使得AUC最大的一组参数。利用优化后的随机森林模型,我们可以评估出特征的重要性。
变量的重要性不仅可以反映出该变量对于模型的影响,还可以用来进行变量挑选。例如,如果我们想要构建回归模型,当变量很多时可以利用随机森林判断出变量的重要性,再从中挑选最为重要的若干个变量进行建模。
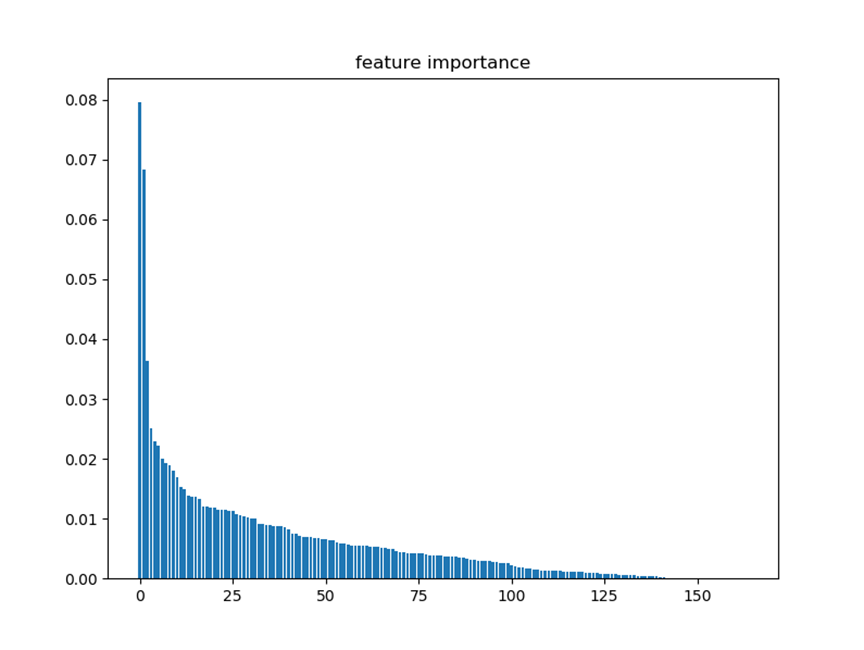
6.5 代码
代码:
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split,GridSearchCV from sklearn.ensemble import RandomForestClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.preprocessing import OneHotEncoder from sklearn.model_selection import GridSearchCV,cross_val_predict from sklearn import metrics from matplotlib import pyplot as plt def Missingrate_Column(df, col): ''' :param df: 数据集 :param col:需要判断缺失率的特征 :return:缺失率 ''' missing_records = df[col].map(lambda x: int(x!=x)) return missing_records.mean() ####################### #### 1,读取数据 ##### ####################### data = pd.read_csv('E:/file/application_train_small.csv', header=0) cash_loan_data = data[data['NAME_CONTRACT_TYPE'] == 'Cash loans'] selected_features = ['CODE_GENDER','FLAG_OWN_CAR','LIVE_CITY_NOT_WORK_CITY', 'ORGANIZATION_TYPE', 'FLAG_OWN_REALTY','CNT_CHILDREN','AMT_INCOME_TOTAL','AMT_CREDIT','WEEKDAY_APPR_PROCESS_START', 'AMT_ANNUITY','AMT_GOODS_PRICE','NAME_TYPE_SUITE','NAME_INCOME_TYPE','OCCUPATION_TYPE', 'NAME_EDUCATION_TYPE','NAME_FAMILY_STATUS','NAME_HOUSING_TYPE','REGION_POPULATION_RELATIVE', 'DAYS_BIRTH','DAYS_EMPLOYED','DAYS_REGISTRATION','DAYS_ID_PUBLISH','OWN_CAR_AGE','FLAG_MOBIL', 'FLAG_EMP_PHONE','FLAG_WORK_PHONE','FLAG_CONT_MOBILE','FLAG_PHONE','FLAG_EMAIL', 'CNT_FAM_MEMBERS','REGION_RATING_CLIENT','REGION_RATING_CLIENT_W_CITY', 'HOUR_APPR_PROCESS_START','REG_REGION_NOT_LIVE_REGION','REG_REGION_NOT_WORK_REGION', 'LIVE_REGION_NOT_WORK_REGION','REG_CITY_NOT_LIVE_CITY','REG_CITY_NOT_WORK_CITY'] all_data = cash_loan_data[['TARGET']+selected_features] train_data, test_data = train_test_split(all_data, test_size=0.3) ######################### #### 2,数据预处理 ##### ######################### all_columns = list(train_data.columns) all_columns.remove('TARGET') #查看每个字段的缺失率 column_missingrate = {col: Missingrate_Column(train_data, col) for col in all_columns} column_MR_df = pd.DataFrame.from_dict(column_missingrate, orient='index') column_MR_df.columns = ['missing_rate'] column_MR_df_sorted = column_MR_df.sort_values(by='missing_rate', ascending=False) columns_with_missing = column_MR_df_sorted[column_MR_df_sorted['missing_rate']>0] ''' missing_rate OWN_CAR_AGE 0.662521 OCCUPATION_TYPE 0.318319 NAME_TYPE_SUITE 0.003441 AMT_ANNUITY 0.000032 ''' #注意到,变量OWN_CAR_AGE和FLAG_OWN_CAR有对应关系:当FLAG_OWN_CAR='Y'时,OWN_CAR_AGE无缺失,否则OWN_CAR_AGE为有缺失 #这种缺失机制属于随机缺失。 #此外,对于非缺失的OWN_CAR_AGE,我们发现有异常值,例如0, 1,2等,无法判断该变量的含义,建议将其删除 selected_features.remove('OWN_CAR_AGE') del train_data['OWN_CAR_AGE'] #变量OCCUPATION_TYPE和NAME_TYPE_SUITE属于类别型变量,可用哑变量进行编码 categorical_features = ['CODE_GENDER','FLAG_OWN_CAR','FLAG_OWN_REALTY','NAME_TYPE_SUITE','NAME_INCOME_TYPE','NAME_EDUCATION_TYPE', 'NAME_FAMILY_STATUS','NAME_HOUSING_TYPE','OCCUPATION_TYPE','WEEKDAY_APPR_PROCESS_START','ORGANIZATION_TYPE'] train_data_2 = pd.get_dummies(data=train_data, columns=categorical_features) #删除AMT_ANNUITY缺失的样本 train_data_2 = train_data_2[~train_data_2['AMT_ANNUITY'].isna()] ####################### #### 3,特征衍生 ##### ####################### train_data_2['credit_to_income'] = train_data_2.apply(lambda x: x['AMT_CREDIT']/x['AMT_INCOME_TOTAL'],axis=1) train_data_2['annuity_to_income'] = train_data_2.apply(lambda x: x['AMT_ANNUITY']/x['AMT_INCOME_TOTAL'],axis=1) train_data_2['price_to_income'] = train_data_2.apply(lambda x: x['AMT_GOODS_PRICE']/x['AMT_INCOME_TOTAL'],axis=1) #有四个与时长相关的变量DAYS_BIRTH,DAYS_EMPLOYED,DAYS_REGISTRATION ,DAYS_ID_PUBLISH中带有负号,不清楚具体的含义。 #我们在案例中仍然保留4个变量,但是建议在真实场景中获得字段的真实含义 ########################## #### 4,构建随机森林 ##### ########################## #使用默认参数进行建模 all_features = list(train_data_2.columns) all_features.remove('TARGET') X, y = train_data_2[all_features], train_data_2['TARGET'] RFC = RandomForestClassifier(oob_score=True) RFC.fit(X,y) print(RFC.oob_score_) y_predprob = RFC.predict_proba(X)[:,1] result = pd.DataFrame({'real':y,'pred':y_predprob}) print("AUC Score (Train): %f" % metrics.roc_auc_score(y, y_predprob)) #ROC_AUC(result, 'pred', 'real') feature_importance = pd.DataFrame({'feature':all_features,'importance':RFC.feature_importances_}) feature_importance = feature_importance.sort_values(by='importance', ascending=False) #参数调整 #1,调整n_estimators #param_test1 = {'n_estimators':range(10,151,10)} #gsearch1 = GridSearchCV(estimator = RandomForestClassifier(),param_grid = param_test1, scoring='roc_auc',cv=5) #gsearch1.fit(X,y) #best_n_estimators_1 = gsearch1.best_params_['n_estimators'] #140 param_test1 = {'n_estimators':range(131,150)} gsearch1 = GridSearchCV(estimator = RandomForestClassifier(),param_grid = param_test1, scoring='roc_auc',cv=5) gsearch1.fit(X,y) best_n_estimators = gsearch1.best_params_['n_estimators'] #134 #2,对决策树最大深度max_depth,内部节点再划分所需最小样本数min_samples_split和叶子节点最少样本数min_samples_leaf进行网格搜索 param_test2 = {'max_depth':range(5,21), 'min_samples_split':range(20,81,10), 'min_samples_leaf':range(5,21,5)} gsearch2 = GridSearchCV(estimator = RandomForestClassifier(n_estimators= best_n_estimators),param_grid = param_test2, scoring='roc_auc',cv=5) gsearch2.fit(X,y) best_max_depth, best_min_sample_split, best_min_samples_leaf = gsearch2.best_params_['max_depth'],gsearch2.best_params_['min_samples_split'],gsearch2.best_params_['min_samples_leaf'] #3,对max_features进行调优 param_test3 ={'max_features':['sqrt','log2']} gsearch3 = GridSearchCV(estimator = RandomForestClassifier(n_estimators= best_n_estimators, max_depth = best_max_depth, min_samples_split = best_min_sample_split, min_samples_leaf = best_min_samples_leaf), param_grid = param_test3, scoring='roc_auc',cv=5) gsearch3.fit(X,y) best_max_features = gsearch3.best_params_['max_features'] RFC_2 = RandomForestClassifier(oob_score=True, n_estimators= best_n_estimators, max_depth = best_max_depth,min_samples_split = best_min_sample_split, min_samples_leaf = best_min_samples_leaf,max_features = best_max_features) RFC_2.fit(X,y) print(RFC_2.oob_score_) y_predprob = RFC_2.predict_proba(X)[:,1] result = pd.DataFrame({'real':y,'pred':y_predprob}) #print("AUC Score (Train): %f" % metrics.roc_auc_score(y, y_predprob)) #ROC_AUC(result, 'pred', 'real') #特征重要性评估 fi = RFC_2.feature_importances_ fi = sorted(fi, reverse=True) plt.bar(list(range(len(fi))), fi) plt.title('feature importance') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
测试记录:
0.9169639193156349 AUC Score (Train): 1.000000 0.9169797026421288- 1
- 2
- 3
参考:
- http://www.dataguru.cn/mycourse.php?mod=intro&lessonid=1701
- https://zhuanlan.zhihu.com/p/76590801
-
相关阅读:
#安装lnmp1.5到最后出现Error: MySQL install failed的解决方法#
MyLife - Docker安装Redis
吹缆机的原理与应用——TFN 吹缆机 T700C系列
Codeforces Round #790 (Div. 4) G. White-Black Balanced Subtrees 感觉很好的树形dp的板子题
C++ | 简单线程池的实现
vue3+vite使用viewerjs实现图片预览
【Linux】VirtualBox安装Centos7
探索未来,开启无限可能:打造智慧应用,亚马逊云科技大语言模型助您一臂之力
计算机网络-传输层
C# 通过Dynamic访问System.Text.Json对象
- 原文地址:https://blog.csdn.net/u010520724/article/details/126360934