-
Transformer去阴影!北交大&SCSU&中国移动提出CRFormer,依靠从非阴影到阴影的单向注意力来去除图片中的阴影!...
关注公众号,发现CV技术之美
本篇分享论文『CRFormer: A Cross-Region Transformer for Shadow Removal』,北交大&SCSU&中国移动提出CRFormer模型,依靠从非阴影到阴影的单向注意力来去除图片中的阴影!
详细信息如下:

论文地址:https://arxiv.org/abs/2207.01600
代码地址:未开源
01
摘要
为了恢复图像中阴影区域的原始强度,并使其与剩余的非阴影区域无痕迹兼容的阴影去除任务是一个非常具有挑战性的问题,它有利于许多下游图像/视频相关任务。最近,transformers通过捕获全局像素交互在各种应用中显示出强大的能力,这种能力在阴影消除中非常理想。
然而,出于以下两个原因,应用transformers来促进阴影消除是非常重要的:1) 由于阴影形状不规则,修补操作不适合阴影移除;2) 阴影去除只需要从非阴影区域到阴影区域的单向交互,而不是图像中所有像素之间的常见双向交互。在本文中,作者提出了一种新的跨区域Transformer,即CRFormer,用于阴影去除,它不同于现有的Transformer,CRFormer只考虑从非阴影区域到阴影区域的像素交互,而不将图像分割为patch。
这是通过精心设计的区域感知交叉注意力操作实现的,该操作可以聚合以非阴影区域特征为条件的恢复阴影区域特征。在ISTD、AISTD、SRD和Video Shadow Removal数据集上的大量实验表明,与其他最先进的方法相比,本文的方法具有优越性。
02
Motivation
随着各种摄像机的使用越来越多,数字图像/视频无处不在,用于记录人脸、文档和精彩时刻,其中可能会出现不良阴影并降低视觉质量。阴影还会影响图像的特征表示,并可能不利地影响后续的图像/视频处理任务,例如对象检测和跟踪。为了提高图像质量并有利于下游任务,阴影消除是非常可取的,其目标是恢复物体投射的阴影区域的像素强度。由于复杂的照明条件和不规则的阴影形状,这是一个具有挑战性的问题。
由于深度卷积神经网络 (CNNs) 的进步和提取的代表性深度特征,基于CNN的方法通过表现出优于传统方法的性能而成为阴影去除的主流。来自非阴影区域的图像上下文提示对于阴影去除至关重要。不幸的是,由于卷积运算,大多数现有的基于CNN的方法在模拟大感受野的长距离像素依赖性方面是无效的。
因此,在这些方法中,没有充分利用来自非阴影区域的信息来恢复阴影区域的每个像素。最近,一种基于上下文感知的CNN方法试图通过匹配阴影和非阴影patch之间的特征相似性,然后传输成对patch的上下文信息来执行阴影去除,以帮助缓解这个问题。然而,作为先决条件,它需要一个超大的基于patch的数据集来训练上下文patch匹配模块,这既耗时又费力。从方法论的角度来看,它仅从非阴影区域中选取前3个相似的patch进行上下文信息传输,这仍然不利于利用非阴影区域中的所有像素级信息进行阴影去除。
最近,Transformer在许多计算机视觉任务中取得了成功,在这些任务中,可以有效地对远程上下文信息进行建模。因此,作者考虑利用Transformer来增强从非阴影区域到阴影区域的连接。然而,在使用Transformer去除阴影之前,需要解决两个主要挑战。
首先,Transformer采用图像patch作为输入,由于对象投射的阴影形状不规则,直观上不适合阴影去除。其次,现有Transformer的全局像素交互考虑了所有像素对恢复阴影区域的贡献,由于阴影区域的特征已损坏,因此阴影移除只应考虑从非阴影区域到阴影区域的单向连接。
为了解决上述问题,作者提出了一种新的跨区域Transformer(CRFormer),以混合CNN和Transformer框架的形式用于阴影去除。
首先使用基于CNN的双编码器来提取给定阴影图像及其阴影掩码的两条路径之间的不对称特征。
然后,提出的具有N个跨区域对齐块的Transformer层同时吸收阴影和非阴影区域的特征,建立从非阴影区域到阴影区域的连接,这是通过新设计的区域感知交叉注意来实现的。这样,所提出的CRFormer可以利用来自非阴影区域的足够上下文信息来恢复阴影区域中每个阴影像素的强度。然后,将一系列跨区域对齐块的输出馈送到单个基于CNN的解码器中,以实现去阴影结果。
最后,作者利用轻量级U形网络进行后处理,以重新确定获得的阴影去除结果。作者在ISTD、AISTD、SRD和Video Shadow Removal数据集上评估了本文提出的CRFormer。大量实验证明了该方法的有效性和优越性。
本文的主要贡献如下:
提出了一种新的混合CNN-Transformer框架,称为跨区域Transformer(CRFormer),用于高质量阴影去除。在CRFormer中,考虑了来自非阴影区域的所有像素来帮助恢复每个阴影像素,这充分利用了来自非阴影区域的潜在上下文线索来去除阴影。这是第一个为阴影消除量身定制的基于transformer的框架。
提出了一种新的区域感知交叉注意力(RCA),该交叉注意力通过仅建立从非阴影区域到阴影区域的单向连接,将非阴影区域的像素级特征聚合为恢复的阴影区域特征。
大量实验表明,该方法在ISTD、AISTD、SRD和Video Shadow Removal等四个数据集上优于最先进的方法。
03
方法
3.1. Overview

跨区域Transformer(CRFormer)的整体pipeline如上图所示,这是一个混合CNN-Transformer框架。通过输入阴影图像及其阴影掩码,在CRFormer中,一种双编码器架构设计用于提取涉及不同感兴趣区域特征的不对称特征。非阴影路径的输入是三通道输入图像,其中包含来自非阴影区域的上下文信息,阴影路径是输入图像及其阴影掩码的四通道concat图像。注意,两个编码器的网络设计不同。
为了减少阴影像素和非阴影像素之间由于更深卷积而产生的干扰,即提取每个区域内的纯特征以准确提供感兴趣的非阴影区域特征,顶部编码器(非阴影路径)构建在仅使用三个卷积的浅子网上,其中包括两个3×3平均池化卷积,用于对特征映射进行降采样,以及一个1×1卷积,用于调整特征映射的维度,以匹配底部编码器输出的维度。阴影路径的底部编码器是一个更深的编码器,由几个卷积和残差块组成,其中两个卷积的步长设置为2,以对特征图进行降采样。鉴于图像的阴影和非阴影区域通常都是同一和谐场景的一部分,非阴影区域的上下文信息可以帮助恢复阴影区域的无阴影像素强度。为了实现这个目标,作者设计了一个新的具有区域感知交叉注意力的Transformer层。然后,其输出被发送到解码器以重建去阴影图像。
最后,作者执行结果精炼以提高去阴影结果的质量。首先获得合成图像:,代表哈达玛积。通过将和作为输入,执行重新定义以生成最终的阴影去除图像。作者使用U形网络作为神经网络的主干,去掉一半的滤波器以降低计算复杂度。
3.2. Review of Transformer
初始Transformer由N个编码器块组成。每个块由多头注意力(MHA)、多层感知器(MLP)和层归一化(LN)组成。此外,在每个块的末端利用残差连接来防止网络退化。
通常,MHA并行执行多个注意力模块,并投影concat的输出。最重要的是,在每个注意力模块中,通过将点积相似性应用于一组查询向量和关键向量,并使用结果重新校准一组值向量来计算注意力图,以实现聚合输出。所有这些操作可以公式化为:
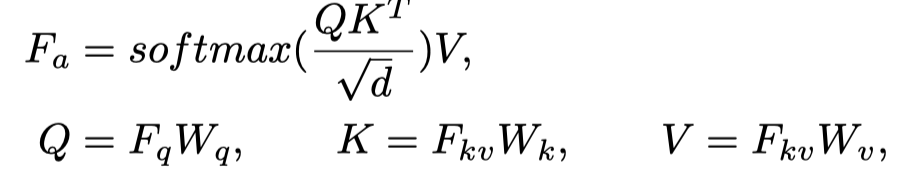
其中,和分别表示查询和键/值的特征描述符,是线性可学习矩阵,C是token嵌入的维数,d是Q、K和V的维数。当时,它相当于自注意力机制。
3.3. Transformer attention with Region-aware Cross-Attention
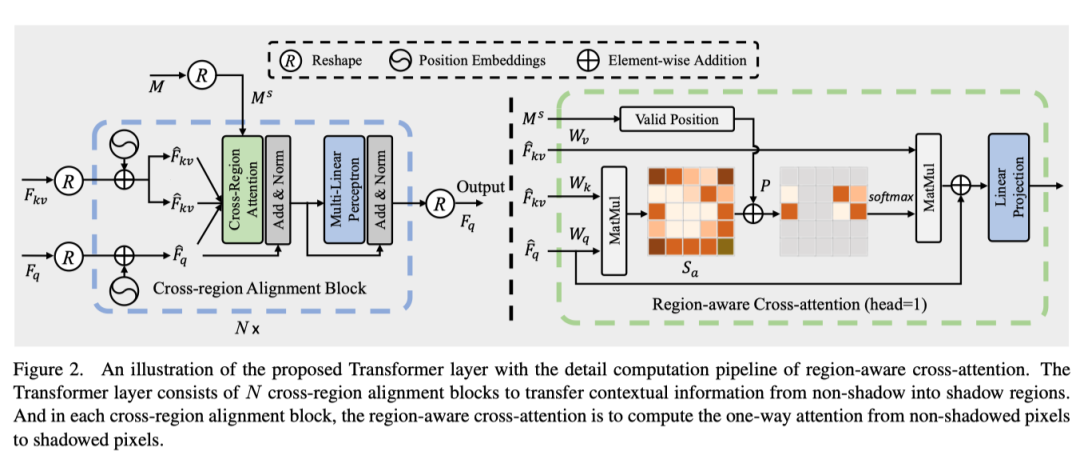
为了恢复阴影像素,充分探索和利用非阴影区域的潜在上下文线索至关重要。因此,作者提出了一种具有区域感知交叉注意(RAC)的新型Transformer层,以将足够的上下文信息从非阴影区域转移到阴影区域。在Transformer层内,有N个跨区域对齐块。跨区域对齐块的详细pipeline和RAC计算如上图所示。
具体来说,考虑到紧凑的阴影特征和无阴影特征,作者首先将其分解为1D向量(形状为),作为跨区域对齐块的输入,其中H、W和C是特征图的高度、宽度和通道。在这里设计为和的特征形状相等。此外,作者将像素作为Transformer层的输入token,并将每个像素的通道作为token嵌入。然后,对每个token执行位置编码,这些token可以表示为:
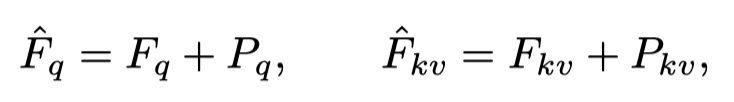
其中为位置编码嵌入。
然后,作者使用区域感知交叉注意力执行从非阴影像素到阴影像素的单向注意,以将相关的非阴影区域特征聚合为恢复的阴影区域特征。注意,作者没有通过跨区域对齐块将全局特征(即阴影和非阴影区域特征)集成到去阴影区域特征,因为阴影区域特征可能会被阴影损坏,并对最终的去阴影特征聚合产生负面影响。最后,由区域感知交叉注意力聚合的特征通过MLP和LN层来生成跨区域对齐块的输出。当堆叠N个块时,前一个块的输出被馈送到下一个块。
3.3.1 Region-aware Cross-attention
为了将非阴影区域的像素级特征聚合为阴影区域的恢复特征,并避免不相关图像特征(即被阴影破坏的特征)的混淆,作者提出了一种区域感知交叉注意操作,以从非阴影区域到阴影区域进行单向像素交互。
详细的计算步骤如上图(右)所示。注意力是使用以及调整大小和形状的阴影掩模计算的。注意,由于多头注意操作的计算复杂度很高,本文将头数设置为1以执行区域感知交叉注意。
形式上,查询向量、键向量和值向量最初是通过将和与三个线性可学习矩阵()相乘获得的。然后,计算相似性分数映射
测量所有查询和键像素/token之间的相关性。之后,为了更好地探索用于恢复阴影像素的非阴影区域特征,作者只关注阴影区域中位于i的查询像素和非阴影区域中j处的键像素。
给定reshape后的二值阴影掩码,如果且,则从j到i应用区域感知交叉注意操作。因此,通过遍历查询和键的所有token,可以获得一个映射表示中非阴影像素和阴影像素之间的位置对应。这个操作这可表示为:
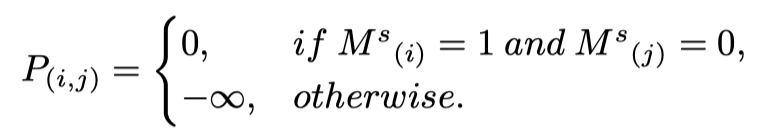
之后,对于阴影区域中的所有查询像素/token,通过以下公式计算由非阴影区域中的所有关键像素/token重新校准的聚合特征:
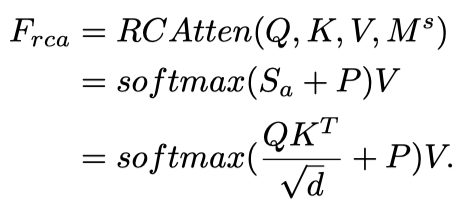
最后,将添加到以防止非阴影区域信息的退化,然后将其发送到线性投影层以转发传播以获得最终输出。通过这种方式,Transformer层可以有效避免被阴影破坏的无关特征引起的注意力偏移,并将适当的上下文信息从非阴影区域转移到阴影区域,以重建高质量的去阴影结果。
3.4. Loss Function
提出的CRFormer以端到端的方式进行训练。总损失包括重建损失和空间损失,定义为:
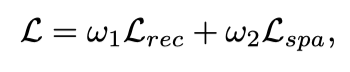
其中ω1和ω2是不同损失项的权重,在实验中根据经验将其分别设置为1和10。具体而言,采用像素级L1距离来确保去阴影结果和的像素强度与相应的ground truth图像一致,其计算如下:
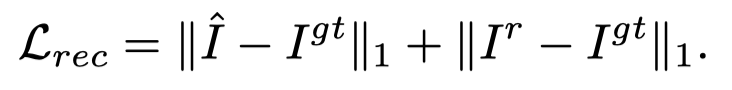
此外,受轻量级图像增强任务的启发,作者引入了空间一致性损失,通过保留去阴影图像及其相应无阴影版本的相邻区域之间的差异来增强图像的空间一致性,其表示为:
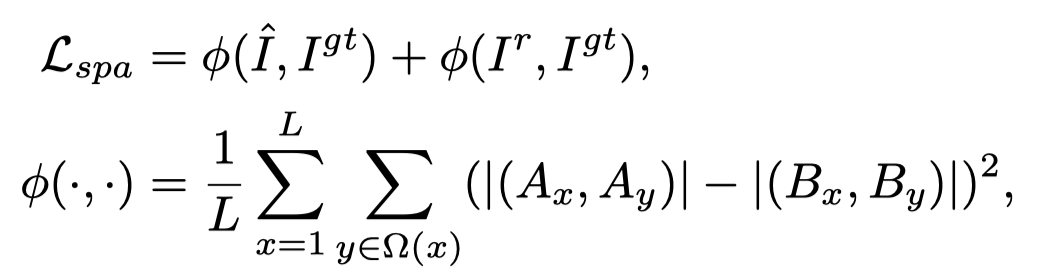
其中L表示局部区域的数量,Ω(x) 表示局部区域x附近的四个区域(上、下、左和右),A和B分别是去阴影图像及其相应的ground truth图像局部区域的平均值。
04
实验
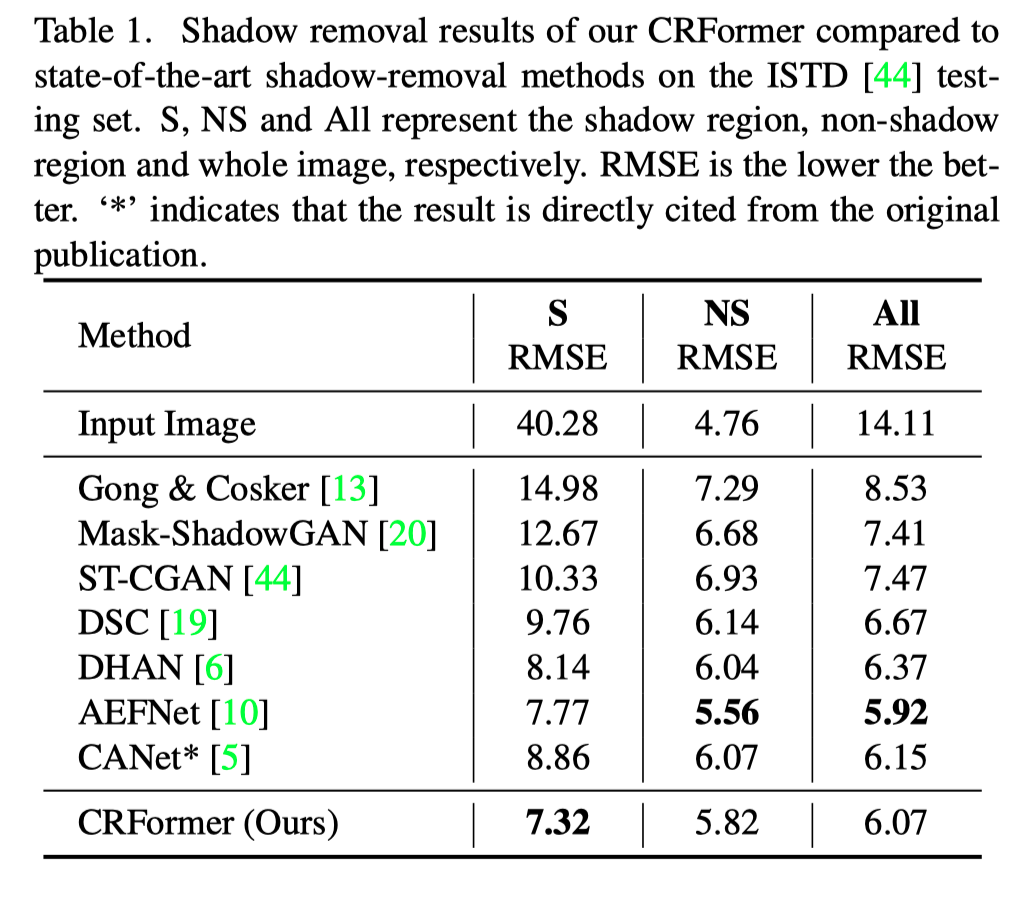
对于ISTD,作者比较了最先进的方法,包括Gong&Cosker、Mask ShadowGAN、ST-CGAN、DSC、DHAN、AEFNet和CANet。上表显示了本文的方法和其他竞争方法的定量结果。
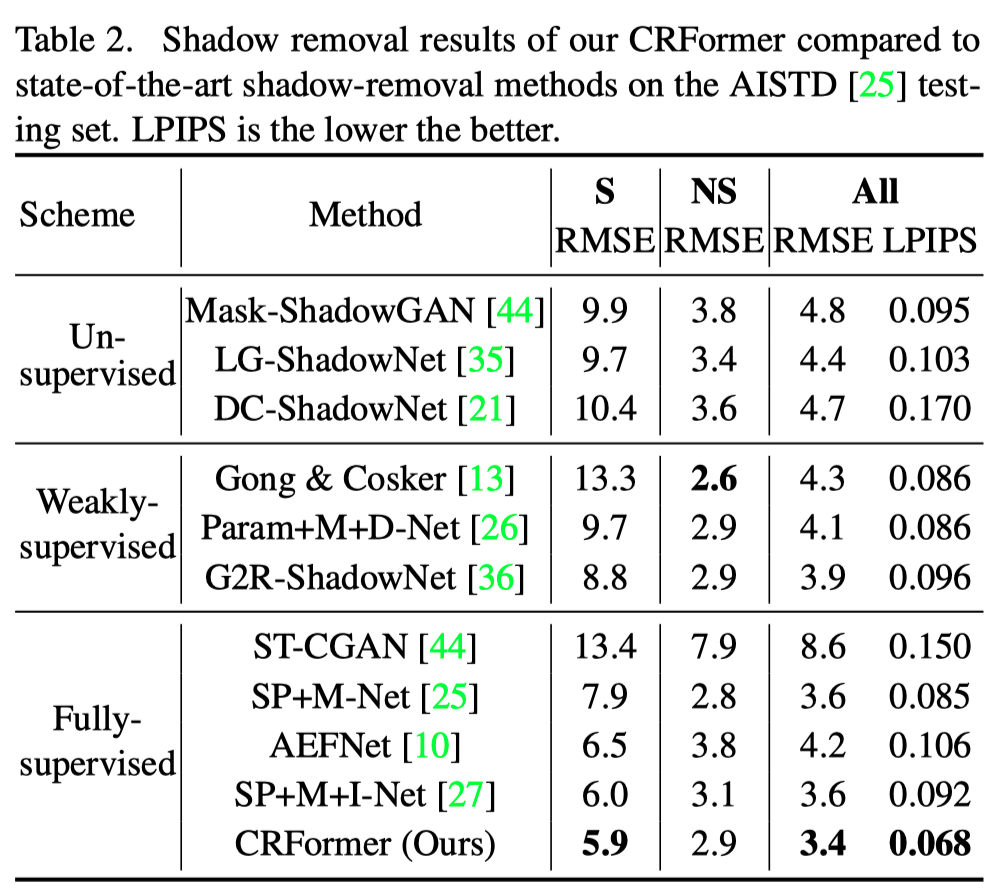
对于AISTD,作者将本文的模型与无监督方法(包括Mask ShadowGAN、LG ShadowNet和DC ShadowNet)、弱监督方法(包括Gong&Cosker、Param+M+D-Net和G2R ShadowNet)以及监督方法(包括ST-CGAN、SP+MNet、AEFNet和SP+M+I-Net)进行了比较。如上表所示,本文的方法在阴影区域和整个图像中都优于所有最先进的方法。

上图展示了不同方法进行阴影去除的定性结果。
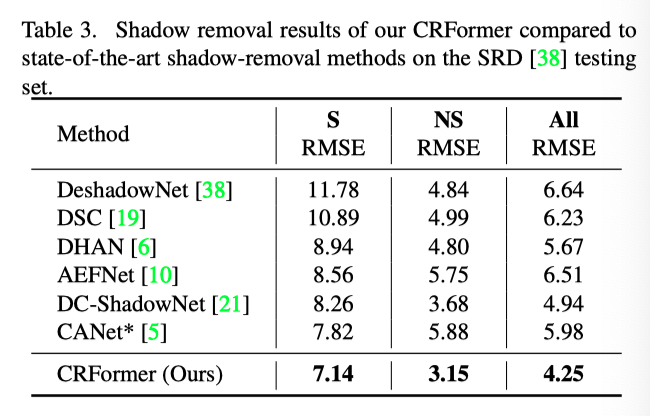
作者使用由DHAN生成的阴影掩码进行评估,并与当前最先进的方法进行比较,可以看出本文方法具有明显的性能优势。
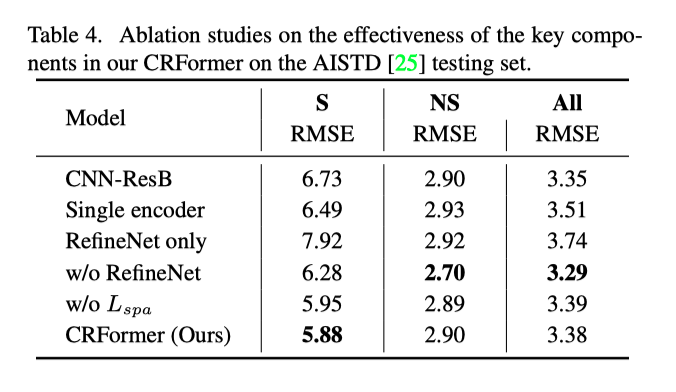
上表展示了本文方法中的关键模块的消融实验结果,可以看出这些模块对于性能提升的积极作用。
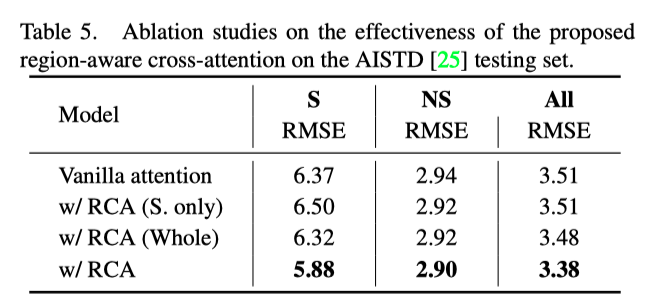
上表展示了本文提出的区域感知注意力机制的消融实验结果,可以看出通过非阴影区域和阴影区域的单向交互,有利于提升去除阴影的效果。
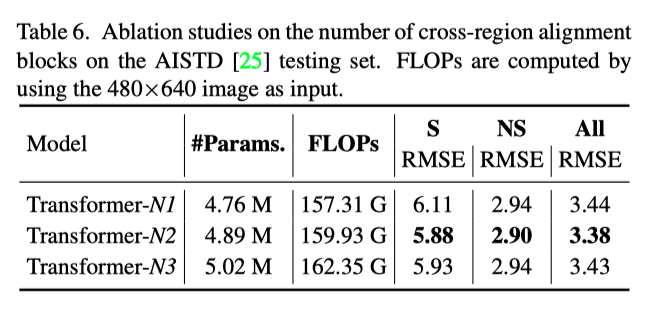
CRFormer的性能还受到跨区域对齐块(表示为N)数量的影响。通过在Transformer层中堆叠更多的块,将在CRFormer中计算更多的跨区域对齐次数。如上表所示,可以发现当使用两个块时,CRFormer实现了最佳性能。
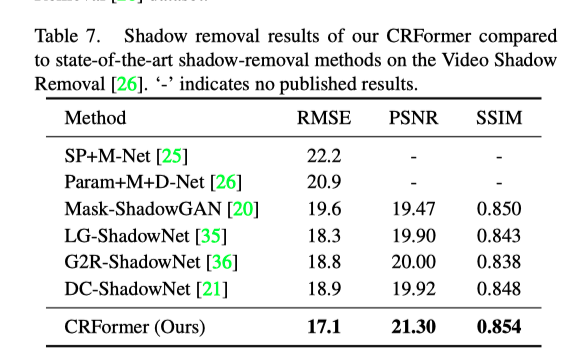
上表展示了本文方法在Video Shadow Removal上的实验结果。

从上图中的定性结果还可以看出,通过利用来自非阴影区域的足够上下文信息来恢复阴影像素,本文的方法产生的去阴影结果具有更少的伪影,比其他方法更有利和真实。
05
总结
在本文中,作者提出了CRFormer,一种新颖的混合CNN-transformer框架,用于高质量的阴影去除。由于新设计的区域感知交叉注意操作,它能够从非阴影区域捕获足够的上下文信息,以帮助恢复阴影区域的无阴影像素强度。
与transformer中现有的注意力计算不同,区域感知的交叉注意力是仅从非阴影区域到阴影区域计算的单向注意力,用于去阴影特征聚合。实验结果表明,与ISTD,AISTD,SRD和Video Shadow Removal数据集的最新技术相比,本文的CRFormer产生了更好的结果。
参考资料
[1]https://arxiv.org/abs/2207.01600
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
欢迎加入「去阴影」交流群👇备注:去阴影

-
相关阅读:
翻译:网站整站翻译 / 网站国际化 / 极简实现
React-hooks有哪些用法?
基于vue和node.js的志愿者招募网站设计
Redis缓存相关问题
助力燃气安全运行:智慧燃气管网背景延展
【论文阅读|深读】Role2Vec:Role-Based Graph Embeddings
centos安装mysql8
[附源码]Python计算机毕业设计Django毕业生就业管理系统
C++之《连连看》
【算法训练-回溯算法 一】【经典模版】全排列
- 原文地址:https://blog.csdn.net/moxibingdao/article/details/126339135