-
eclipse配置hadoop插件
首先下载eclipse的插件,下载链接有
https://github.com/HuangDongdong666/Hadoop-eclipse-plugin-2.8.3
https://github.com/winghc/hadoop2x-eclipse-plugin/tree/master/release
下载完之后,根据eclipse版本的不同,旧版本放在plugins这个文件夹下,新版本的,我的就是重装之后的eclipse就是放在dropins这个文件夹下。然后重开eclipse。
开启eclipse之后,点击help->install->add,输入hadoop-plungin,确定,之后可以在manager看到如下图所示的。(ok后勾选确定,可能会会有警告,忽略,重启eclipse即可)

打开Window->Preferences->HadoopMap/Reduce,,然后在dircetory输入你从虚拟机拉过来的已经解压的Hadoop文件夹!


接着,window->show view->others,弹出的窗口中选择Map/Reduce Locations,即可看到Map/Reduce的控制界面。在该页面右键new一个Hadoop Location,这是我的配置。

下载文件 inutils.exe 和 winutils.exe
https://github.com/steveloughran/winutils(下载和自己hadoop版本一样的,或者接近的(<=自己的版本))
下载了winutils.exe文件和hadoop.dll之后放入hadoop-2.7.5in文件夹中

另外还要把hadoop.dll放在C:WindowsSystem32文件夹下
接着,先测试下你的虚拟机和你的windows能不能连接上,如果用户对hadoop目录并没有写入权限,会导致异常的发生,命令如下 :hdfs dfs -chmod -R 777 /,在左边Project Explorer能看的你的hdfs结构,然后就开始编代码吧。
(操作如下)


在主函数编写job时,要注意自己的端口号是多少。
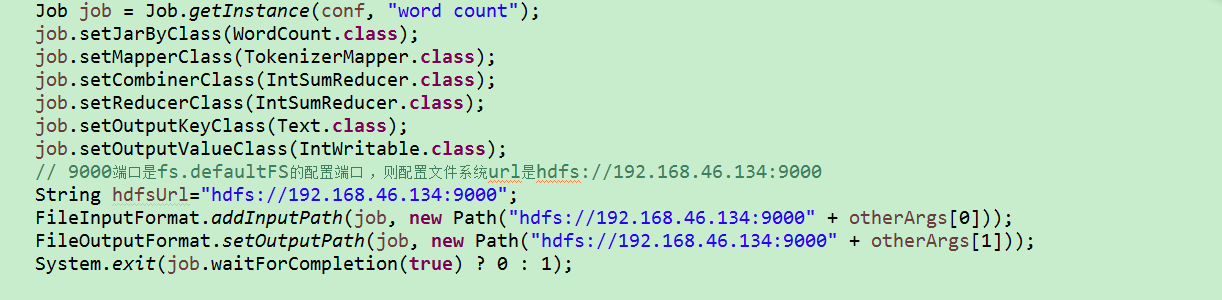
问题总结:
(1)Could not locate Hadoop executable: D:Program Fileshadoop-3.0.0inwinutils.exe
下载文件inutils.exe 和 winutils.exe
https://github.com/steveloughran/winutils
下载了winutils.exe文件和hadoop.dll之后放入hadoop-2.7.5in文件夹中。
(2)如果用户对hadoop目录并没有写入权限,会导致异常的发生,命令如下 :hdfs dfs -chmod -R 777 /
(3)异常Exception in thread “main” java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
https://blog.csdn.net/congcong68/article/details/42043093
(4)hadoop关于org.apache.hadoop.security.AccessControlException: Permission denied: user=Administrator, ac
https://blog.csdn.net/lunhuishizhe/article/details/50489849
(5)Hadoop Hdfs常用命令
(6)https://blog.csdn.net/sunshingheavy/article/details/53227581
hadoop测试样例
http://younglibin.iteye.com/blog/1925008
最后贴上本人的测试代码
package com.cby.test; import java.io.File; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper extends Mappervalues, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } // static { // try { // System.load("D:/Program Files/hadoop-3.0.0/bin/hadoop.dll"); // } catch (UnsatisfiedLinkError e) { // System.err.println("Native code library failed to load. " + e); // System.exit(1); // } // } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); // conf.set("mapred.job.tracker", "192.168.247.130:9001"); System.setProperty("hadoop.home.dir", "D:/Program Files/hadoop-3.0.0"); args = new String[] { "/user/root/input", "/user/root/output1" }; String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); System.out.println(otherArgs.length); if (otherArgs.length != 2) { System.err.println("Usage: wordcount "); System.out.println("测试结束"); System.exit(2); } // conf.set("fs.defaultFS", "hdfs://192.168.6.77:9000"); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 8020端口是fs.defaultFS的配置端口,一般默认为9000 FileInputFormat.addInputPath(job, new Path("hdfs://192.168.247.130:8020" + otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.247.130:8020" + otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
-
相关阅读:
云原生题目整理(待更新)
热更新:Chrome 插件开发提效
OJ第三篇
JWT 实现登录认证 + Token 自动续期方案
朋友圈怎么发?托育人看过来
FFmpeg入门详解之114:DirectShow读取摄像头数据
餐厅预订APP多少钱一套?餐厅预订APP如何收费?
GUI自动化 - 操控键盘
优秀的 Verilog/FPGA开源项目介绍(三十二)-RISC-V(新增俩)
多御安全浏览器更新了这些设置,还是你熟悉的吗?
- 原文地址:https://blog.csdn.net/m0_67403188/article/details/126358321

