-
Netty(4)NIO 和 BIO
stream & channel
stream 不会自动缓冲数据,channel 会利用系统提供的发送缓冲区、接收缓冲区(更为底层)stream 仅支持阻塞 API;channel 同时支持阻塞、非阻塞 API,网络 channel 可配合 selector 实现多路复用二者均为全双工,即读写可以同时进行
IO模型
同步阻塞、同步非阻塞、同步多路复用、异步阻塞(不存在此情况)、异步非阻塞
一共有五种IO模型《Unix网络编程》
- 阻塞IO
- 非阻塞IO
- 多路复用
- 信号异步
- 异步IO
基础概念
同步:线程自己去获取结果(一个线程)类似亲力亲为
异步:线程自己不去获取结果,而是由其它线程送结果(至少两个线程)类似老板可以让员工去处理其他事情
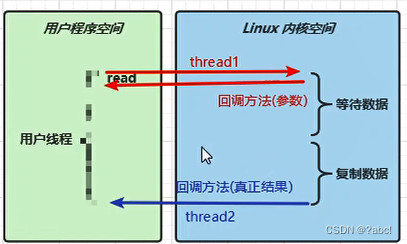
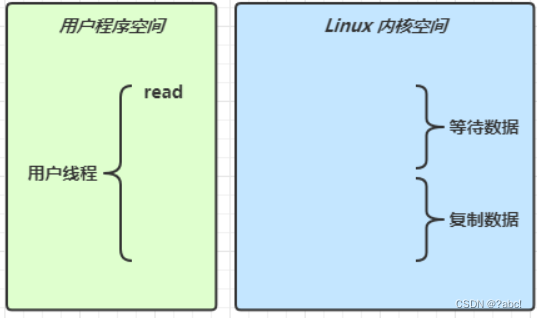
当调用一次 channel.read 或 stream.read 后,会切换至操作系统内核态来完成真正数据读取,而读取又分为两个阶段,分别为:
-
等待数据阶段
-
复制数据阶段
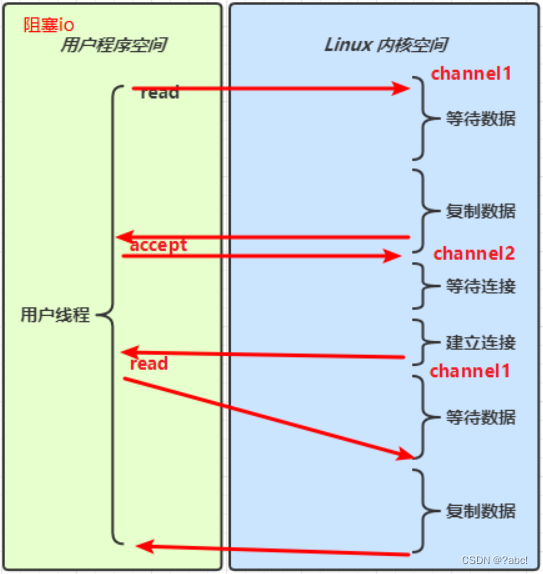
阻塞IO(同步)
情况说明:
-
当用户线程发起一次read,此时便会由用户程序空间切换到Linux内核空间,
-
这时候使用内核空间真正的去读取,
-
这时候网络上可能还没有数据真正的发送过来,这时候read就会被阻塞住(就是线程停止下来,什么都做不了),
-
直到数据到了,这时候进行数据的复制,等数据全部复制完了,值由Linux内核空间,切换回用户程序空间,
-
这时候read方法的调用便告一段落,如下图所示:
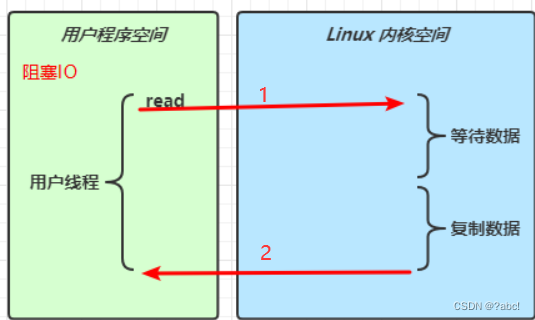
像上面的这种就称为阻塞IO
- 这里的阻塞就是指
用户线程被阻塞了,在读取期间什么都做不了
非阻塞IO(同步)
发起read的线程和接收read的线程是同一种线程
情况说明:
- 用户线程调用read方法,
- 如果这时候数据还没有传输过来,会立刻返回,告诉用户线程读到的为0
- 用户线程这边再次进行read方法的调用,Linux内核空间会立刻返回…
- 在上面的过程中,用户线程一直没有停下来,一直在运行,所以这种情况就被称为非阻塞,
- 当某一次调用read方法时,发现有数据了,这是完成第二个阶段复制数据,
复制数据时,用户线程还是会被阻塞住,等待数据复制完毕,这时候用户线程可以继续运行(数据拿到了)。如下图所示:
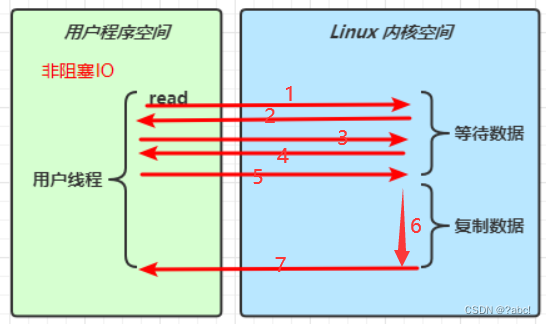
相对于阻塞IO,涉及多次用户程序空间和Linux内核空间的调换,影响系统稳定性
多路复用(同步)
发起read的线程和接收read的线程是同一种线程
情况说明:
- 用户线程调用select方法,切换到Linux内核空间,这时候会阻塞住,等待事件发送
- 当有事件发送后,内核空间会告诉用户线程有新事件read发生
- 这时用户线程,可以根据selectionKey拿到channel,去调用一次read
- read期间还是需要去复制数据,这期间还是阻塞住了,等待数据复制完毕 。如下图所示
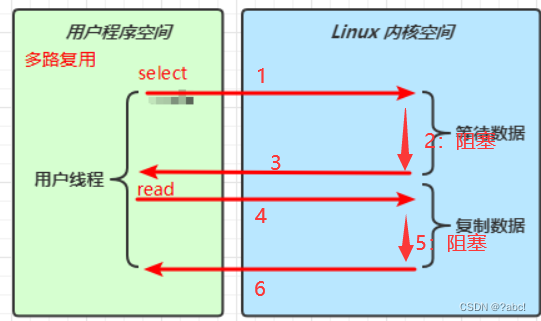
通过分析可以发现,这个过程中有两个地方阻塞:select在等待数据时,read在复制数据时
与阻塞IO相比-
阻塞IO:当channel发送数据时,无法去处理第二次发送数据的处理(需要等待第一次处理完成)
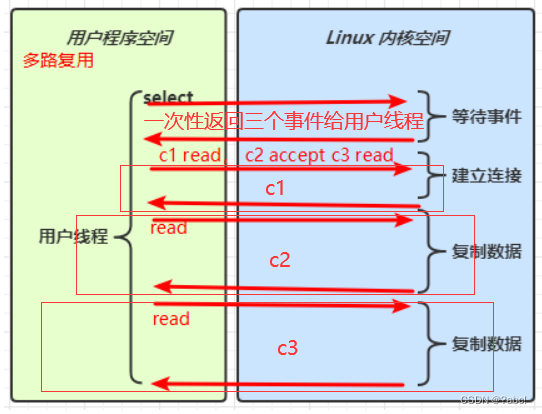
-
多路复用:一个selector可以去监视多个channel上的事件(一次性处理多个channel的事件,等待事件的时间都在第一回合等完了),不管是什么事件都可以触发selector去处理,如下图:
信号异步
异步IO(AIO)
AIO 用来解决数据复制阶段的阻塞问题
- 同步意味着,在进行读写操作时,线程需要等待结果,还是相当于闲置
- 异步意味着,在进行读写操作时,线程不必等待结果,而是将来由操作系统来通过回调方式由另外的线程来获得结果
异步模型需要底层操作系统(Kernel)提供支持
- Windows 系统通过 IOCP 实现了真正的异步 IO
- Linux 系统异步 IO 在 2.6 版本引入,但其底层实现还是用多路复用模拟了异步 IO,性能没有优势
文件 AIO
try (AsynchronousFileChannel channel = AsynchronousFileChannel.open(Paths.get("data.txt"), StandardOpenOption.READ)) { // 参数1 ByteBuffer // 参数2 读取的起始位置 // 参数3 附件 // 参数4 回调对象 CompletionHandler ByteBuffer buffer = ByteBuffer.allocate(16); log.debug("read begin..."); channel.read(buffer, 0, buffer, new CompletionHandler<Integer, ByteBuffer>() { @Override // read 成功 public void completed(Integer result, ByteBuffer attachment) { log.debug("read completed...: "+ result); //切换到读模式 attachment.flip(); debugAll(attachment); } @Override // read 失败 public void failed(Throwable exc, ByteBuffer attachment) { exc.printStackTrace(); } }); log.debug("read end..."); } catch (IOException e) { e.printStackTrace(); } //使主线程先不结束,completed这个重写方法是守护线程(如果其他线程运行完了,守护线程也会结束) System.in.read();- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
可以看到(直接贴其他的截图了…)

- 响应文件读取成功的是另一个线程 Thread-5
- 主线程并没有 IO 操作阻塞
零拷贝
传统方法
传统的 IO 将一个文件通过 socket 写出
File f = new File("helloword/data.txt"); RandomAccessFile file = new RandomAccessFile(file, "r"); byte[] buf = new byte[(int)f.length()]; file.read(buf); Socket socket = ...; socket.getOutputStream().write(buf);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
内部工作流程:
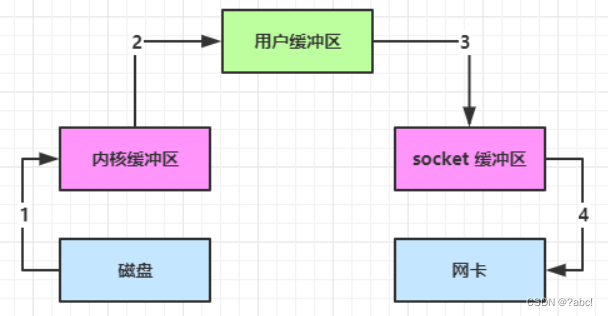
12是read方法的内部工作流程,34是write方法的内部工作流程:-
java 本身并不具备 IO 读写能力,因此 read 方法调用后,要从 java 程序的用户态切换至内核态,去调用操作系统(Kernel)的读能力,将数据读入内核缓冲区。这期间用户线程阻塞,操作系统使用 DMA(Direct Memory Access)来实现文件读,其间也不会使用 cpu
DMA 也可以理解为硬件单元,用来解放 cpu 完成文件 IO
-
从内核态切换回用户态,将数据从内核缓冲区读入用户缓冲区(即 byte[] buf),这期间 cpu 会参与拷贝,无法利用 DMA
-
调用 write 方法,这时将数据从用户缓冲区(byte[] buf)写入 socket 缓冲区,cpu 会参与拷贝
-
接下来要向网卡写数据,这项能力 java 又不具备,因此又得从用户态切换至内核态,调用操作系统的写能力,使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 cpu
java 的 IO 实际不是物理设备级别的读写,而是缓存的复制,底层的真正读写是操作系统来完成的
- 用户态与内核态的切换发生了 3 次,这个操作比较重量级
- 第一次是调用read()方法时,从java变成操作系统
- 第二次是read()方法结束,从操作系统变为java
- 第三次是write()方法的调用,从java变成操作系统
- 数据拷贝了共 4 次
- 上图所示的1234
使用NIO优化
减少一次数据拷贝
通过 DirectByteBuffer ,减少一次数据的拷贝
- ByteBuffer.allocate(10) HeapByteBuffer 使用的还是 java 内存
- ByteBuffer.allocateDirect(10) DirectByteBuffer 使用的是操作系统内存
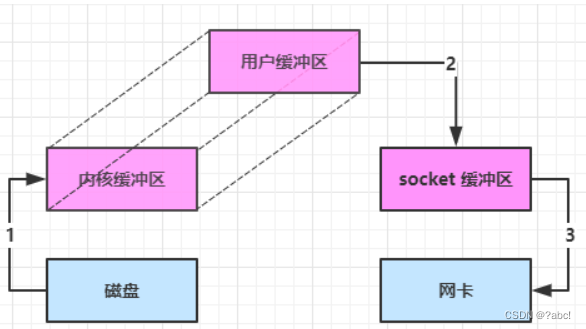
大部分步骤与优化前相同,不再赘述。唯有一点:java 可以使用 DirectByteBuf 将堆外内存映射到 jvm 内存中来直接访问使用- 这块内存不受 jvm 垃圾回收的影响,因此内存地址固定,有助于 IO 读写
- java 中的 DirectByteBuf 对象仅维护了此内存的虚引用,内存回收分成两步
- DirectByteBuf 对象被垃圾回收,将虚引用加入引用队列
- 通过专门线程访问引用队列,根据虚引用释放堆外内存
- 减少了一次数据拷贝,用户态与内核态的切换次数没有减少
进一步优化:一次切换,拷贝三次(linux 2.1)
底层采用了 linux 2.1 后提供的 sendFile 方法,java 中对应着两个 channel 调用 transferTo/transferFrom 方法拷贝数据
transferTo/transferFrom 方法可以直接将数据发送到socket缓冲区(通过sendFile方法),不经过java

- java 调用 transferTo 方法后,要从 java 程序的用户态切换至内核态,使用 DMA将数据读入内核缓冲区,不会使用 cpu
- 数据从内核缓冲区传输到 socket 缓冲区,cpu 会参与拷贝
- 最后使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 cpu
可以看到
只发生了一次用户态与内核态的切换数据拷贝了 3 次
进一步优化:一次切换,拷贝两次(linux 2.4)
有一种实现,可以直接将内核缓冲区的数据发送到网卡(网络设备),只是中间有一些少量的数据会写入socket缓冲区中
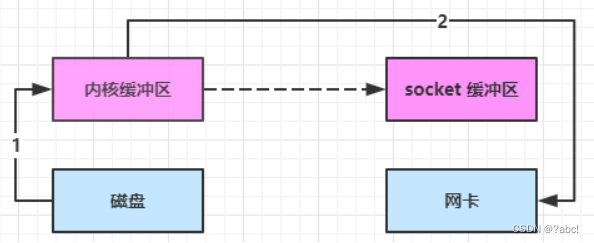
- java 调用 transferTo 方法后,要从 java 程序的用户态切换至内核态,使用 DMA将数据读入内核缓冲区,不会使用 cpu
- 只会将一些 offset 和 length 信息拷入 socket 缓冲区,几乎无消耗
- 使用 DMA 将 内核缓冲区的数据写入网卡,不会使用 cpu
整个过程仅
只发生了一次用户态与内核态的切换,数据拷贝了 2 次。实现零拷贝(从文件传输的角度)
java中对应的transferTo方法,Linux中的sendFile方法都可以叫做零拷贝
零:指的是不用在java中间进行拷贝了所谓的
【零拷贝】,并不是真正无拷贝,而是在不会拷贝重复数据到 jvm 内存中,零拷贝的优点有更少的用户态与内核态的切换不利用 cpu 计算,减少 cpu 缓存伪共享零拷贝适合小文件传输
-
相关阅读:
微服务主流框架概览
【洛谷 P1029】[NOIP2001 普及组] 最大公约数和最小公倍数问题 题解(辗转相除法)
淘宝/天猫API:item_list_weight-批量获取商品信息
java毕业设计大学生入学审核系统mybatis+源码+调试部署+系统+数据库+lw
Android 12.0 SystemUI下拉状态栏定制化之隐藏下拉通知栏布局功能实现(一)
剑指offer-数据结构二
【ccf-csp题解】第四次csp认证-第四题-网络延时-树的直径
KubeCon热点报告:AIStation调度平台实现RoCE网络下大模型的高效稳定训练
java计算机毕业设计ssm信息科技知识交流学习平台
Python中文分词及词频统计
- 原文地址:https://blog.csdn.net/yyuggjggg/article/details/126338312