-
【SQL刷题】Day5----SQL分组查询专项练习
博主昵称:跳楼梯企鹅
博主主页面链接:博主主页传送门博主专栏页面连接:专栏传送门--网路安全技术
创作初心:本博客的初心为与技术朋友们相互交流,每个人的技术都存在短板,博主也是一样,虚心求教,希望各位技术友给予指导。
博主座右铭:发现光,追随光,成为光,散发光;
博主研究方向:渗透测试、机器学习 ;
博主寄语:感谢各位技术友的支持,您的支持就是我前进的动力 ;学习网站跳转链接:牛客刷题网

一、分组查询语句
刷题网站牛客网,点击右边连接跳转 牛客在线刷题
1.初步了解
group by 关键字可以根据一个或多个字段对查询结果进行分组
group by 一般都会结合Mysql聚合函数来使用
如果需要指定条件来过滤分组后的结果集,需要结合 having 关键字;原因:where不能与聚合函数联合使用 并且 where 是在 group by 之前执行的2. 语法格式
GROUP BY <字段名>[,,]代码举例:
- SELECT 字段名1(要求出现在group by后面),分组函数(),……
- FROM 表名
- WHERE 条件
- GROUP BY 字段名1,字段名2
- ORDER BY 字段
- HAVING 过滤条件;
二、刷题
1.练习一
(1)题目
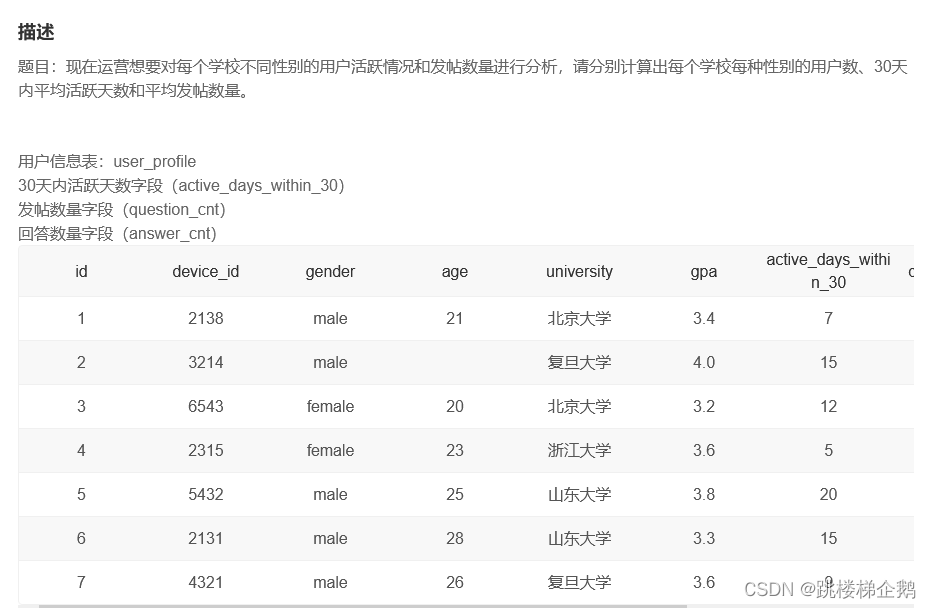
现在运营想要对每个学校不同性别的用户活跃情况和发帖数量进行分析,请分别计算出每个学校每种性别的用户数、30天内平均活跃天数和平均发帖数量。
(2)分析
我们拿到数据之后,我们可以看到字段有9个,题目中又说请分别计算出每个学校每种性别的用户数、30天内平均活跃天数和平均发帖数量,那么我们是不是可以用上次所学的计算函数进行计算,那么我们怎么将有用的数据拿出来进行计算呢?这时候就需要用到我们的分组函数进行指定字段的取出。
示例
- 输入:
- drop table if exists user_profile;
- CREATE TABLE `user_profile` (
- `id` int NOT NULL,
- `device_id` int NOT NULL,
- `gender` varchar(14) NOT NULL,
- `age` int ,
- `university` varchar(32) NOT NULL,
- `gpa` float,
- `active_days_within_30` float,
- `question_cnt` float,
- `answer_cnt` float
- );
- INSERT INTO user_profile VALUES(1,2138,'male',21,'北京大学',3.4,7,2,12);
- INSERT INTO user_profile VALUES(2,3214,'male',null,'复旦大学',4.0,15,5,25);
- INSERT INTO user_profile VALUES(3,6543,'female',20,'北京大学',3.2,12,3,30);
- INSERT INTO user_profile VALUES(4,2315,'female',23,'浙江大学',3.6,5,1,2);
- INSERT INTO user_profile VALUES(5,5432,'male',25,'山东大学',3.8,20,15,70);
- INSERT INTO user_profile VALUES(6,2131,'male',28,'山东大学',3.3,15,7,13);
- INSERT INTO user_profile VALUES(7,4321,'male',28,'复旦大学',3.6,9,6,52);
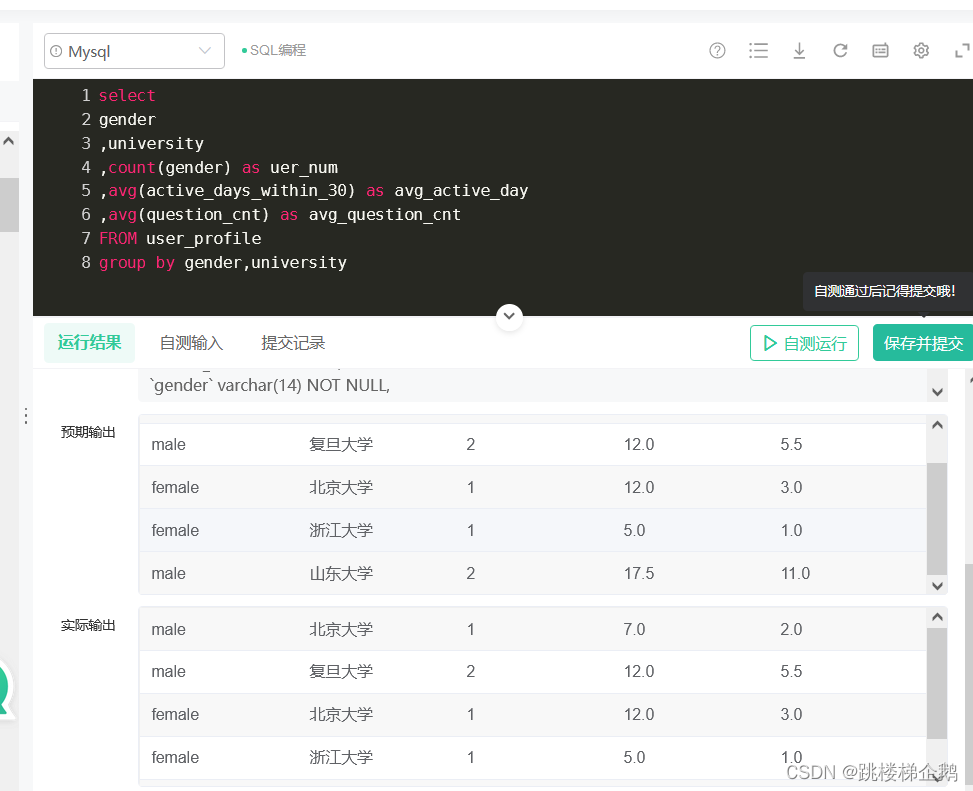
- 输出:
- male|北京大学|1|7.0|2.0
- male|复旦大学|2|12.0|5.5
- female|北京大学|1|12.0|3.0
- female|浙江大学|1|5.0|1.0
- male|山东大学|2|17.5|11.0
(3)代码
- select
- gender
- ,university
- ,count(gender) as uer_num
- ,avg(active_days_within_30) as avg_active_day
- ,avg(question_cnt) as avg_question_cnt
- FROM user_profile
- group by gender,university
(4)运行
成功的完成这道题目
2.练习二
(1)题目
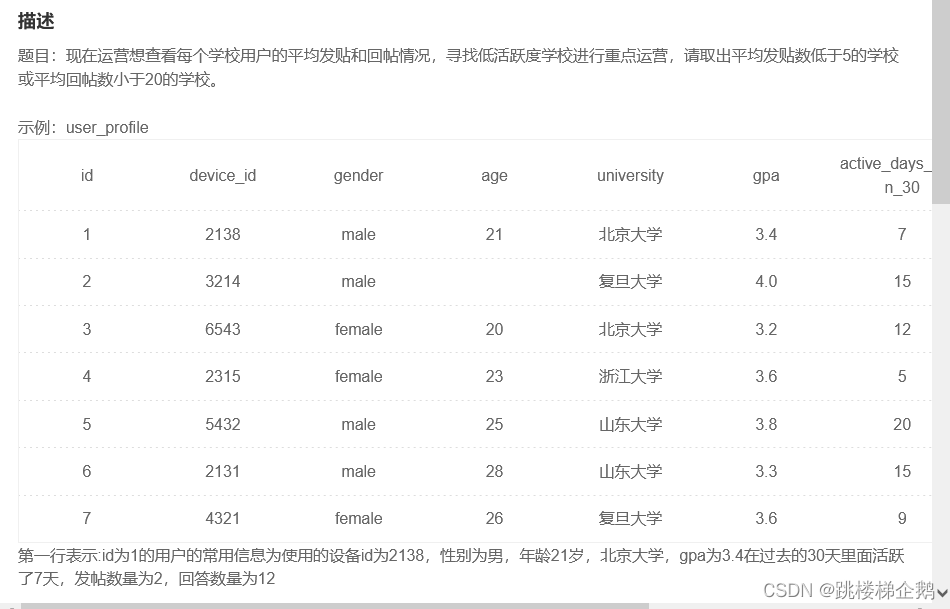
现在运营想查看每个学校用户的平均发贴和回帖情况,寻找低活跃度学校进行重点运营,请取出平均发贴数低于5的学校或平均回帖数小于20的学校。
(2)分析
第一行表示:id为1的用户的常用信息为使用的设备id为2138,性别为男,年龄21岁,北京大学,gpa为3.4在过去的30天里面活跃了7天,发帖数量为2,回答数量为12。
最后一行表示:id为7的用户的常用信息为使用的设备id为4321,性别为男,年龄26岁,复旦大学,gpa为3.6在过去的30天里面活跃了9天,发帖数量为6,回答数量为52。根据示例,你的查询应返回以下结果,请你保留3位小数(系统后台也会自动校正),3位之后四舍五入:

平均发贴数低于5的学校或平均回帖数小于20的学校有2个,属于北京大学的用户的平均发帖量为2.500,平均回答数量为21.000,属于浙江大学的用户的平均发帖量为1.000,平均回答数量为2.000
示例:
- 输入:
- drop table if exists user_profile;
- CREATE TABLE `user_profile` (
- `id` int NOT NULL,
- `device_id` int NOT NULL,
- `gender` varchar(14) NOT NULL,
- `age` int ,
- `university` varchar(32) NOT NULL,
- `gpa` float,
- `active_days_within_30` int ,
- `question_cnt` float,
- `answer_cnt` float
- );
- INSERT INTO user_profile VALUES(1,2138,'male',21,'北京大学',3.4,7,2,12);
- INSERT INTO user_profile VALUES(2,3214,'male',null,'复旦大学',4.0,15,5,25);
- INSERT INTO user_profile VALUES(3,6543,'female',20,'北京大学',3.2,12,3,30);
- INSERT INTO user_profile VALUES(4,2315,'female',23,'浙江大学',3.6,5,1,2);
- INSERT INTO user_profile VALUES(5,5432,'male',25,'山东大学',3.8,20,15,70);
- INSERT INTO user_profile VALUES(6,2131,'male',28,'山东大学',3.3,15,7,13);
- INSERT INTO user_profile VALUES(7,4321,'male',28,'复旦大学',3.6,9,6,52);
- 输出:
- university|avg_question_cnt|avg_answer_cnt
- 北京大学|2.500|21.000
- 浙江大学|1.000|2.000
(3)代码
- SELECT
- university,
- avg( question_cnt ) AS avg_question_cnt,
- avg( answer_cnt ) AS avg_answer_cnt
- FROM
- user_profile GROUP BY university
- HAVING
- avg_question_cnt < 5 OR avg_answer_cnt < 20
(4)运行
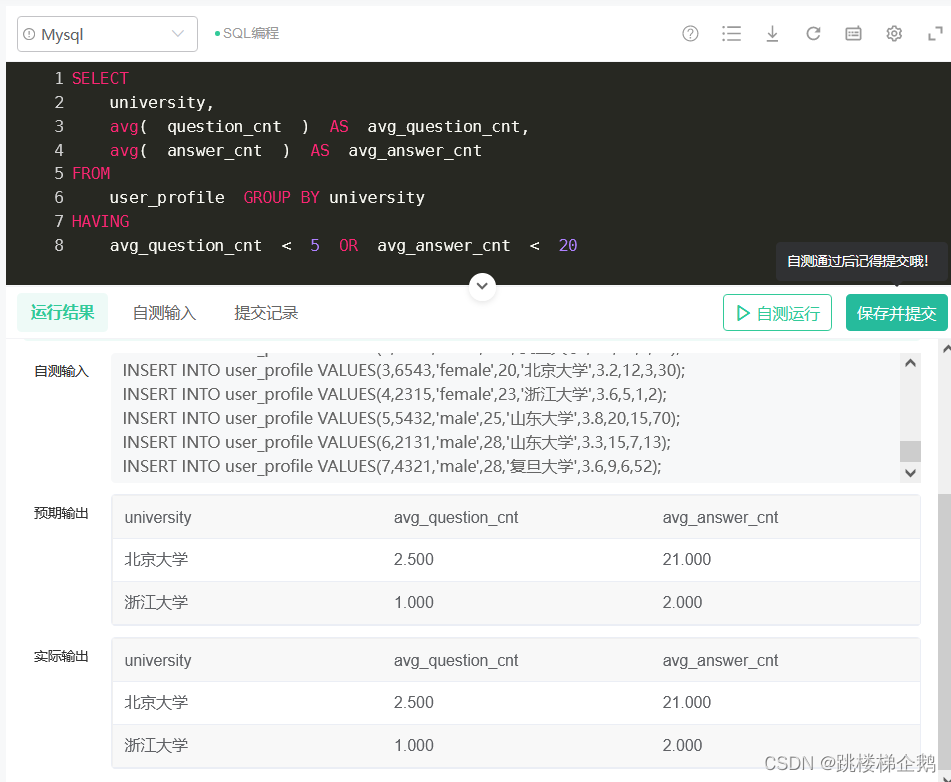
成功的完成这道题目
3.练习三
(1)题目
现在运营想要查看不同大学的用户平均发帖情况,并期望结果按照平均发帖情况进行升序排列,请你取出相应数据。
(2)分析
我们拿到数据之后,我们可以看到字段有9个,题目中又说请分别计算出每个学校每种性别的用户数、30天内平均活跃天数和平均发帖数量,那么我们是不是可以用上次所学的计算函数进行计算,那么我们怎么将有用的数据拿出来进行计算呢?这时候就需要用到我们的分组函数进行指定字段的取出,按照题目要求对数据进行升序排列
示例
- 输入:
- drop table if exists user_profile;
- CREATE TABLE `user_profile` (
- `id` int NOT NULL,
- `device_id` int NOT NULL,
- `gender` varchar(14) NOT NULL,
- `age` int ,
- `university` varchar(32) NOT NULL,
- `gpa` float,
- `active_days_within_30` int ,
- `question_cnt` int ,
- `answer_cnt` int
- );
- INSERT INTO user_profile VALUES(1,2138,'male',21,'北京大学',3.4,7,2,12);
- INSERT INTO user_profile VALUES(2,3214,'male',null,'复旦大学',4.0,15,5,25);
- INSERT INTO user_profile VALUES(3,6543,'female',20,'北京大学',3.2,12,3,30);
- INSERT INTO user_profile VALUES(4,2315,'female',23,'浙江大学',3.6,5,1,2);
- INSERT INTO user_profile VALUES(5,5432,'male',25,'山东大学',3.8,20,15,70);
- INSERT INTO user_profile VALUES(6,2131,'male',28,'山东大学',3.3,15,7,13);
- INSERT INTO user_profile VALUES(7,4321,'male',28,'复旦大学',3.6,9,6,52);
- 输出:
- 浙江大学|1.0000
- 北京大学|2.5000
- 复旦大学|5.5000
- 山东大学|11.0000
(3)代码
- select university,avg(question_cnt) AS avg_question_cnt from user_profile
- group by university
- order by avg_question_cnt
(4)运行
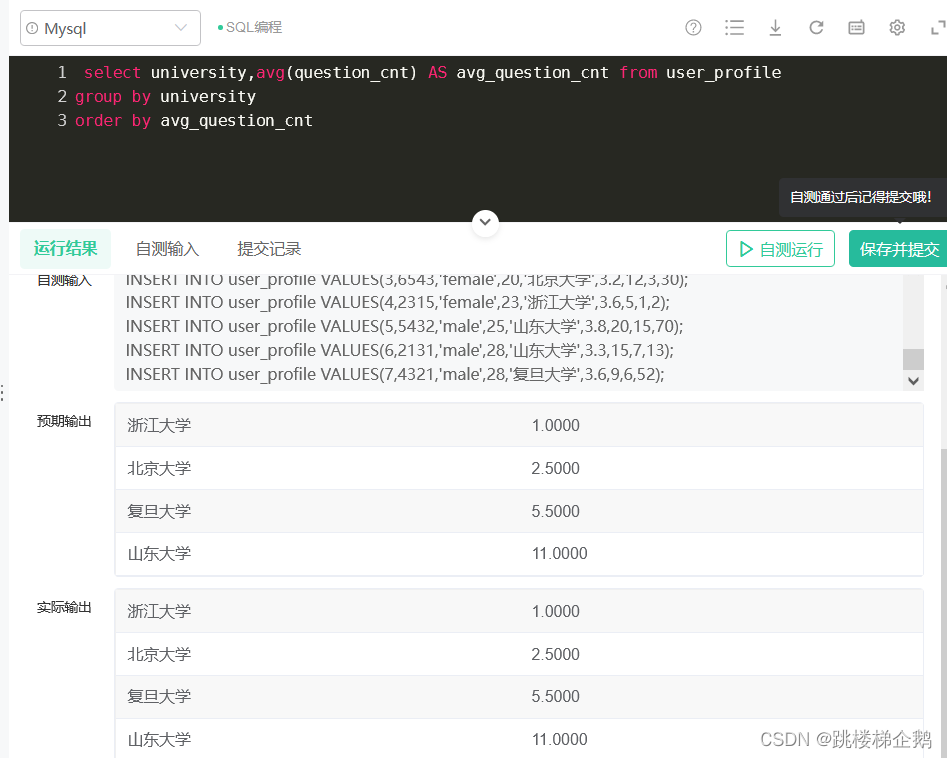
成功的完成这道题目
三、小结
本次刷题第五天,对数据库的了解上升了一个维度,尤其是刚开始对怎么查询计算是有点混乱的,现在坐骑题来越来越得心应手,是很舒服的一件事情。希望可以继续坚持下去,刷题50天,数据库知识点不多,但是后期会分享很多数据库面试的问题和扩展思维
点击右边链接和博主一起刷题吧
-
相关阅读:
Codeforces Round 910 (Div. 2) --- B-E 补题记录
腾讯面试真题 | 没在我八股文列表里。。。
防火墙命令大全
Linux内核之workqueue机制
spring bean生命周期源码分析
Java语言基础第五天
决策树算法在计算机视觉中的应用附matlab代码
迅为i.MX8mm小尺寸商业级/工业级核心板
php操作xml字符串
案例分享 | 基于ETest平台开发某型DCS测试系统
- 原文地址:https://blog.csdn.net/weixin_50481708/article/details/126357178
