-
地平线面试总结
1.vector.resize()和vector.reserve()区别
先明确vector中的两个属性:
size: 表示实际容器中保存元素的个数
capacity: 表示在发生重新分配之前允许存放多少元素
vector<int>vc(5); cout << "初始化分配5个元素----------" << endl; cout << &vc[0] << endl; cout << vc.size() << endl; cout << vc.capacity() << endl; cout << "reserve(6)----------" << endl; vc.reserve(6); cout << &vc[0]<<endl; cout << vc.size()<<endl; cout << vc.capacity() << endl; cout << "resize(6)----------" << endl; vc.resize(6); cout << &vc[0] << endl; cout << vc.size() << endl; cout << vc.capacity() << endl; cout << "reserve(4)----------" << endl; vc.reserve(4); cout << &vc[0] << endl; cout << vc.size() << endl; cout << vc.capacity() << endl; cout << "resize(4)----------" << endl; vc.resize(4); cout << &vc[0] << endl; cout << vc.size() << endl; cout << vc.capacity() << endl;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
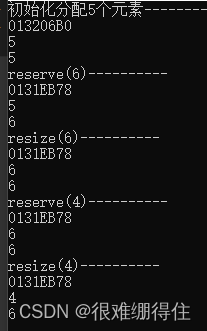
当reverse的大小大于当前容量时,对size不改变,改变capacity
当reverse的大小小于当前容量时,对size不改变,对capacity不改变
由于vector的插入效率低下,reverse主要用于预先分配空间
当resize的大小大于当前容量时,将size与capacity都改为resize的大小
当resize的大小小于当前容量时,只将size改变,而对capacity不改变reserve(size_type)只是改变了capaciy的值,此时这些内存空间可能还是“野”的。如果使用[]操作符进行访问,可能出现数组越界问题,如果使用[]操作符进行访问,可能出现数组越界问题。
2.虚函数原理与实现
3.四种类型转换
4.四种智能指针
5.进程与线程的切换,上下文切换原理,保存在什么地方
简要概述:
进程的上下文即程序计数器(PC)与寄存器保存在PCB中,每个进程的PCB都是存在所有进程共享的内核空间中,操作系统管理进程,也就是在内核空间中管理的,在内核空间中通过链表管理所有进程的PCB。
此外用户进程既有用户空间信息也有内核空间信息,在进程切换过程中,进程的所有信息都要保存,但用户空间的信息(用户堆栈、用户数据等)是保存存在用户空间,传递地址(用户栈指针)给内核,只有内核空间的信息保存在内核态。进程在创建时会创建一个PCB,其中有以下数据:
进程标识符:
内部标识符(系统用的):数字标识符;
外部标识符(创建者):字母、数字
处理机状态:包括所有寄存器状态
通用寄存器(用户可视):存放进程当前暂存信息;
指令计数器(PC):存放要访问的下一条指令的地址信息;
程序状态字(PSW):存放进程的状态信息;
用户栈指针:存放过程和系统要调用的参数及调用地址
进程调度信息(进程调度、对换):
进程状态;
进程优先级;
进程调度所需的其他信息;
事件:e.g.阻塞原因
进程控制信息:
页表数据
程序和数据地址;
进程同步和通讯机制;
资源清单:除CPU以外的全部资源;
链接指针:本CPU所在的队列中下一个PCB的首地址进程切换与系统调用的区别:
进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。 系统调用过程中,并不涉及到虚拟内存等进程用户态的资源,也不会切换进程。进程切换与线程切换的区别:
前后两个线程属于不同进程:此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样的。
前后两个线程属于同一个进程:当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。6.GDB用法
GDB 全称“GNU symbolic debugger”,从名称上不难看出,它诞生于 GNU 计划(同时诞生的还有 GCC、Emacs 等),是 Linux 下常用的程序调试器。发展至今,GDB 已经迭代了诸多个版本,当下的 GDB 支持调试多种编程语言编写的程序,包括 C、C++、Go、Objective-C、OpenCL、Ada 等。实际场景中,GDB 更常用来调试 C 和 C++ 程序。
gdb命令
视频教学
先在linux中写一段简单的代码:
使用gcc -g加入gdb编译,再用gdb打开编译好的a.out:

用list命令可以展示出代码并标识出行号,先用b 4在第四行打上断点,再用r发出运行指令,发现停在了第四行,然后不停输入n可以运行到下一行:

输入c表示continue,一直运行到程序结束

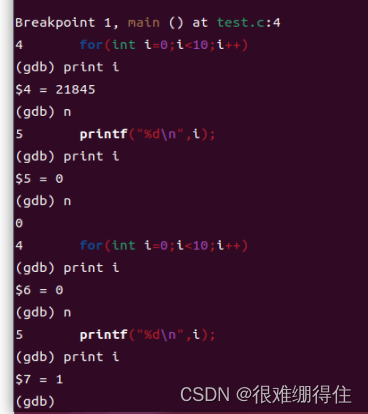
第一个print i结果为21845是因为此时int i=0还未执行,这块内存还没有被初始化
后面可以看到每经过一次for(int i=0;i<10;i++)i的值就会自加1
先在第六行第七行打上断点,再info b展示当前的断点信息,再r开启,然后用s(step)进入最近的函数fun():

用watch观察变量是否变化:先打断点到第8行,再n让i初始化,此时watch i的值,再c,i的值发生变化,用old value与new value展示变化,用info watch可展示观察点,图中放不下

7.CPU的三级缓存,作用,谁来管理,怎么管理
为什么cpu需要用到缓存 简单的说,因为CPU太快,内存太慢,需要有缓存来减少CPU的等待时间,变相地提高CPU性能。
先看CPU执行程序的过程:
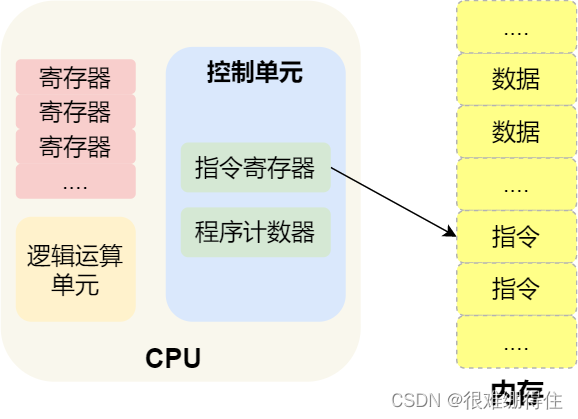
那 CPU 执行程序的过程如下:第一步,CPU 读取「程序计数器」的值,这个值是指令的内存地址,然后 CPU 的「控制单元」操作「地址总线」指定需要访问的内存地址,接着通知内存设备准备数据,数据准备好后通过「数据总线」将指令数据传给 CPU,CPU 收到内存传来的数据后,将这个指令数据存入到「指令寄存器」。
第二步,CPU 分析「指令寄存器」中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给「逻辑运算单元」运算;如果是存储类型的指令,则交由「控制单元」执行;
第三步,CPU 执行完指令后,「程序计数器」的值自增,表示指向下一条指令。这个自增的大小,由 CPU 的位宽决定,比如 32 位的 CPU,指令是 4 个字节,需要 4 个内存地址存放,因此「程序计数器」的值会自增 4;
简单总结一下就是,一个程序执行的时候,CPU 会根据程序计数器里的内存地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。CPU 从程序计数器读取指令、到执行、再到下一条指令,这个过程会不断循环,直到程序执行结束,这个不断循环的过程被称为 CPU 的指令周期。
来源:https://blog.csdn.net/qq_34827674/article/details/109006026
再来看CPU缓存,我们先来举个例子,比如CPU做一个加法运算,需要1-2个时钟周期,那从内存中读取数据需要100-300个周期,这中间差距太大了,CPU不可能等待那么长时间,不然高速的CPU也变成了龟速,于是就想出了缓存Cache这个东西。
现在主流的CPU中,通常有三级缓存,分为L1、L2和L3,它们间的速度呈递减,容量呈递增,读取L1中的信息大概就3个周期,和CPU处理运算的速度无限接近了,读L2的周期大概10-15个周期,读L3的就更慢了,大概40-60个周期左右。

如图所示,L1与L2缓存在CPU核中,多个核共用一个L3缓存
L1L2L3的速度越来越慢,价格越来越低(这里的速度是指CPU从中读写数据或指令的速度)cpu缓存的作用:
CPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。CPU高速缓存的出现主要是为了解决CPU运算速度与内存读写速度不匹配的矛盾。
当CPU需要读取数据并进行计算时,首先需要将CPU缓存中查到所需的数据,并在最短的时间下交付给CPU。如果没有查到所需的数据,CPU就会提出“要求”经过缓存从内存中读取,再原路返回至CPU进行计算。而同时,把这个数据所在的数据也调入缓存,可以使得以后对整块数据的读取都从缓存中进行,不必再调用内存,加快访问速度,这是基于时间局部性原理(如果某个数据被访问,那么在不久的将来它很可能再次被访问)和空间局部性原理(如果某个数据被访问,那么与它相邻的数据很快也可能被访问)因此,如果我们查看内存中的某个字节,我们可能很快就会访问其邻居。一旦高速缓存行出现在L1D中,装入指令就可以继续执行并执行其内存读取。(2)
缓存一致性:
有个程序举例子,有一个数据结构其中有个long型数据,假设缓存行为64B,有两个线程都会对这个数据结构中的int型数据进行修改,循环100次,耗时100秒。
改进:将这个数据结构的int型数据前后都加上64B的数据,此时耗时将远小于100秒,这是因为在修改之前一个缓存行中有8个修改的数据,一个线程对缓存行修改时要通知其他线程对缓存行修改。现在的计算机几乎都是多个核心的,多个线程运行在不同的核心中,每个核心都有自己的缓存。这时就会出现多个cpu同时修改了同一个数据的问题,这就是著名的缓存一致性问题。
8.判断链表有环
哈希表,快慢指针,略
9.Map和unorderedmap区别
实现一个数据结构,可以用O(1)的时间复杂度来随机访问map中的元素,获取其迭代器 -
相关阅读:
vlookup函数踩坑(wps)
华为数通方向HCIP-DataCom H12-831题库(多选题:121-140)
CentOS7 —— yum安装mysql
jsp人力资源管理系统Myeclipse开发mysql数据库servlet开发java编程计算机网页项目
【Swift 60秒】59 - Closures: Summary
【调试笔记-20240602-Linux-在 OpenWRT-23.05 上配置 frps 与 frpc 之间使用 TLS 进行传输】
ALP300智能型低压马达保护器
上周热点回顾(5.13-5.19)
深入理解React中fiber
springcloud总结篇
- 原文地址:https://blog.csdn.net/qq_42567607/article/details/126322705
