-
什么是mvcc,mysql中的mvcc是怎么实现的
MVCC的原则
一个事务能看到的数据版本:
- 第一次查询之前已经提交的事务的修改
- 本事务的修改
一个事务不能看见的数据版本:
- 在本事务第一次查询之后创建的事务(事务ID比我的事务ID大)
- 活跃的(未提交的)事务的修改
MVCC的效果
我可以查到在我这个事务开始之前已经存在的数据,即使它在后面被修改或者删除了。而在我这个事务之后新增的数据,我是查不到的。
原理
- innodb的事务都是有编号的
- innodb每行记录都有两个隐藏字段,DB_TRX_ID和DB_ROLL_PTR
- DB_TRX_ID,6字节:事务ID,数据是在哪个事务插入或者修改为新数据的就记录为当前事务ID。
- DB_ROLL_PTR,7字节:回滚指针(我们把它理解为删除版本号,数据被删除或记录为旧数据的时候,记录当前事务ID,没有修改或者删除的时候是空)。
案例
新建t_user表
CREATE TABLE `t_user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(64) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;- 1
- 2
- 3
- 4
- 5
初始化数据
-- 第一个事务,事务1 begin; insert into t_user values(null,"二哈"); insert into t_user values(null,"旺财"); commit;- 1
- 2
- 3
- 4
- 5
此时表数据如下图所示,DB_TRX_ID记录了插入时的事务1,DB_ROLL_PTR没有操作删除的数据,所以为undefined
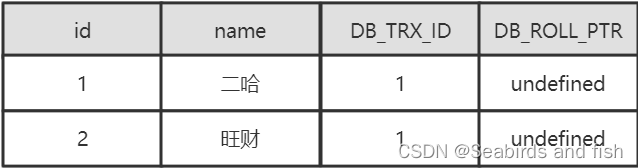
开启第二个事务,事务ID为2,执行第一次查询
-- 事务2,查询t_user,不commit; begin; select * from t_user;- 1
- 2
- 3
此时查询的数据有如下图所示,因为没有操作数据,所以表中的DB_TRX_ID和DB_ROLL_PTR并没有改变,读取到原始的两条记录
开启第三个事务,事务ID为3
-- 插入一条数据,提交 begin; insert into t_user values(null,"柯基"); commit;- 1
- 2
- 3
- 4
此时表数据如下图所示,多了一条柯基的记录,版本号为3

第二个事务继续查询t_user
-- 事务2,第2次查询t_user select * from t_user;- 1
- 2
MVCC的查找规则:只能查找创建时间小于等于当前事务ID的数据,和删除时间大于当前事务ID的行(或未删除)。
结果还是只能查到两条数据,因为事务3的创建时间比事务2的创建时间大,而事务2只能查询创建时间比事务2小的记录,所以查不到柯基这条
开启第四个事务,删除旺财这条记录
-- 事务4, 删除旺财这条数据,提交 begin; delete from t_user where id = 2; commit;- 1
- 2
- 3
- 4
此时旺财这条数据的DB_ROLL_PTR为4
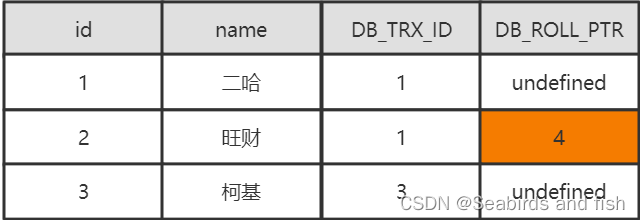
第二个事务继续查询t_user
-- 事务2,第3次查询t_user select * from t_user;- 1
- 2
MVCC的查找规则:只能查找创建时间小于等于当前事务ID的数据,和删除时间大于当前事务ID的行(或未删除)。
结果还是只能查到两条数据,因为事务4的删除时间大于事务2,所以旺财还是可以查出来
开启第五个事务,更新数据
-- 事务5,更新二哈的名字为德牧 begin; update t_user set name = '德牧' where id=1; commit;- 1
- 2
- 3
- 4
此时表中的数据为,更新数据会把旧的数据的DB_ROLL_PTR标记,然后再插入一条新的数据

第二个事务继续查询t_user
-- 事务2,第4次查询t_user select * from t_user;- 1
- 2
MVCC的查找规则:只能查找创建时间小于等于当前事务ID的数据,和删除时间大于当前事务ID的行(或未删除)。
结果还是只能查到两条数据,因为事务5的删除时间大于事务2和创建时间大于2,所以还是只能查出二哈这条记录,不能查出德牧
通过以上演示我们能看到,通过版本号的控制,无论其他事务是插入、修改、删除,第二个事务查询到的数据都没有变化。
undo log
如上案例所示,如果一条记录经过多次修改,不同时间段的事务去查询的结果是不一样的
假设一条数据修改了3次,两次提交了一次未提交。每次修改之后都有开启一个事务去查询,那么事务2、4、6查到的数据会有不一样。
-- 事务1 begin; update t_user set name = '英短' where id=1; commit;- 1
- 2
- 3
- 4
-- 事务2,不提交 begin; select * from t_user where id=1;- 1
- 2
- 3
-- 事务3 begin; update t_user set name = '布偶' where id=1; commit;- 1
- 2
- 3
- 4
-- 事务4,不提交 begin; select * from t_user where id=1;- 1
- 2
- 3
-- 事务5 begin; update t_user set name = '橘猫' where id=1; commit;- 1
- 2
- 3
- 4
-- 事务6,不提交 begin; select * from t_user where id=1;- 1
- 2
- 3
最后把事务2,4,6再执行一次的结果是不一样的
那么InnoDB中,一条数据的旧版本,是存放在哪里的呢? undo log。因为修改了多次,这些undo log 会形成一个链条,叫做undo log 链,现在undo log里面有英短、布偶、橘猫。
所以前面我们说的DB_ROLL_PTR,它其实就是指向undo log链的指针。
第二个问题,事务2、4、6最后再查一次,它们去undo log链找数据的时候,拿到的数据是不一样的。在这个undo log链里面,一个事务怎么判断哪个版本的数据是它应该读取的呢?
所以,我们必须要有一个数据结构,把本事务ID、活跃事务ID、当前系统最大事务ID存起来,这样才能实现判断。这个数据结构就叫Read View(可见性视图),每个事务都维护一个自己的 Read View。
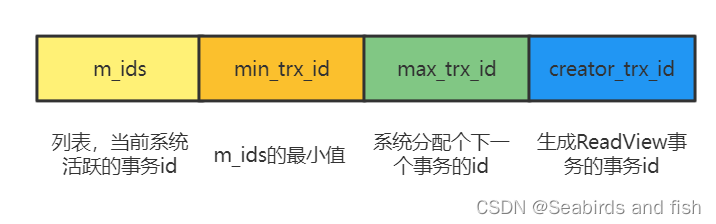
属性 描述 m_ids 表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。 min_trx_id 表示在生成ReadView时当前系统中活跃的读写事务中最小的事务id,也就是m_ids 中的最小值。 max_trx_id 表示生成ReadView时系统中应该分配给下一个事务的id值。 creator_trx_id 表示生成该ReadView的事务的事务id。 有了这个数据结构以后,事务判断可见性的规则是这样的:
- 从数据的最早版本开始判断(undo log)
- 数据版本的trx_id = creator_trx_id,本事务修改,可以访问
- 数据版本的trx_id < min_trx_id(未提交事务的最小ID),说明这个版本在生成 ReadView已经提交,可以访问
- 数据版本的trx_id > max_trx_id(下一个事务ID),这个版本是生成ReadView之后才开启的事务建立的,不能访问
- 数据版本的trx_id 在min_trx_id和max_trx_id之间,看看是否在m_ids中。如果在,不可以。如果不在,可以。
- 如果当前版本不可见,就找undo log链中的下一个版本。
ps:RR(可重复读)中Read View是事务第一次查询的时候建立的。RC(已提交读)的Read View是事务每次查询的时候建立的。
-
相关阅读:
nginx使用详解--反向代理
流媒体集群应用与配置:如何在一台服务器部署多个EasyCVR?
Linux下库的入门与制作
Emgu CV4图像处理之打开Tensorflow训练模型17(C#)
【细度经典】阅读spring security 官方文档Architecture部分
嘉为蓝鲸携手东风集团、上汽零束再获信通院四项大奖
BMS中的绝缘电阻测量方法
C/C++中递归的定义和调用(如何使用递归)
MySQL开窗函数
GCC 参数详解
- 原文地址:https://blog.csdn.net/qq_26751319/article/details/126342915