-
带你吃透MySQL系列:InnoDB引擎浅析
InnoDB概述
MySQL我们都很熟悉,InnoDB引擎作为MySQL当前最多被使用的存储引擎,收到了很多的关注。该引擎是第一个完整支持事务ACID特性的存储引擎,特点是支持行锁,MVCC,一致性非锁定读等。本文作为解析MySQL的第一篇文章,会为大家详细解读一下内存池的设计细节,以及详解InnoDB的特性。在之后的文章中,会切入MySQL的各个具体的维度,解析MySQL的各个技术细节,请大家持续关注。如有问题,欢迎大家一起讨论。
InnoDB体系架构
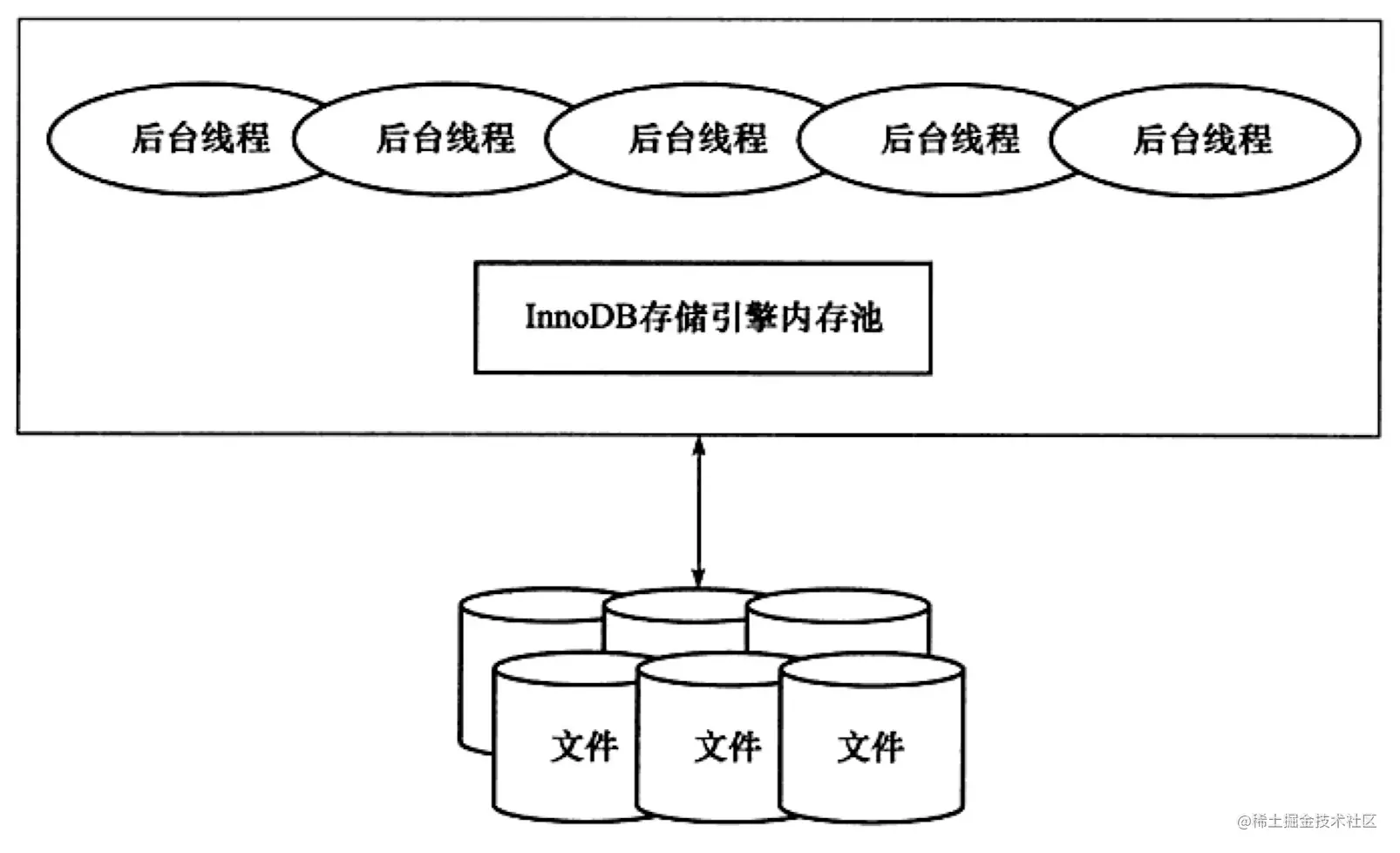
如图,InnoDB体系架构,宏观上即是这样。InnoDB由很多个内存块组成,这些内存块构成了一个大的内存池,内存池的作用是:
- 负责缓存数据,方便快速读取,并且修改过的数据会先在这里缓存,之后再刷到磁盘中。
- 缓冲日志,例如redo log。
- 维护MySQL的多个内部数据结构。
- …… MySQL是一个单进程实例,内部会存在多个后台线程,线程有很多种类,每一类线程具有不同的任务,这些后台线程的主要任务是:保证内存池中会缓存最近的数据,flush脏数据,保证遇到故障可以恢复(日志机制的实现)等。
后台线程有如下分类:
- master thread:主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包含脏页的刷新,合并插入缓冲,undo页的回收等。
- IO thread:InnoDB中大量使用AIO来处理写IO请求,IO thread用来负责这些IO请求的回调处理。
- purge thread:undolog作为事务回滚的必要日志,当事务提交了之后,存储在undo log中的相关数据可能不再需要了。原先回收undo log的任务是交给master线程的,后来为了减轻master线程的压力,便将这个回收任务独立了出来,purge thread会回收这些无用的数据页。
- page cleaner thread:在InnoDB1.2中引入,任务是将内存中的脏页flush到磁盘,也是为了减轻master线程的压力。
InnoDB内存
接下来,为大家介绍一下InnoDB的内存池。内存池中又划分为了缓冲池,重做日志缓冲,额外内存池。
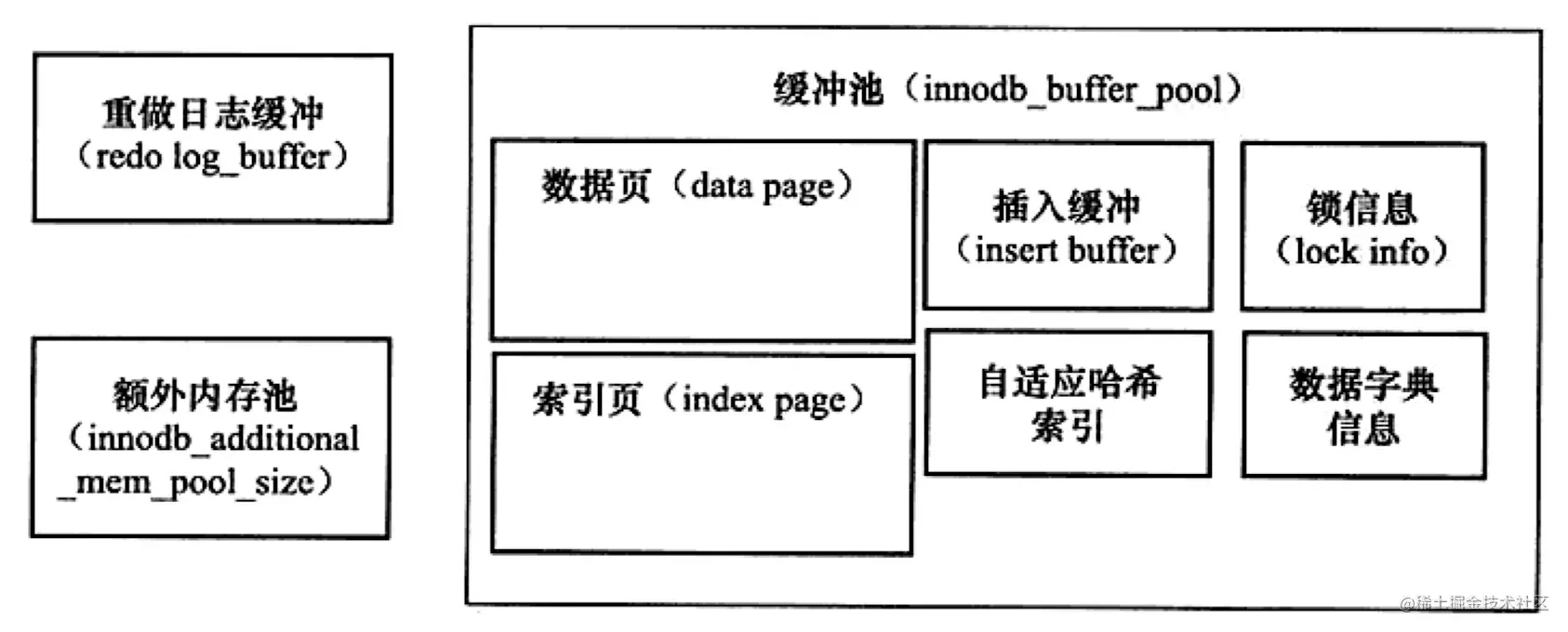
缓冲池
几乎任何可持久化的存储系统,都会设有缓冲池。缓冲池,顾名思义,就是用于缓存数据,用于弥补CPU速度和磁盘速度之间的鸿沟。InnoDB将数据按照页的方式进行管理,当数据库试图读取一页时,首先会判断该页是否存在于缓冲池中,若存在,则直接读取,若不存在,才需要去磁盘中读取该页,并将该页加入到缓冲池中。
当数据库试图修改某页中的数据时,首先会修改在缓冲池中的页,之后再按照一定规则将该页flush回磁盘。这个规则叫做“checkpoint机制”,在后面的文章会讲。
我们可以通过参数innodb_buffer_pool_instances来配置缓冲池实例的个数,默认为1,若有多个实例,每个页会根据哈希映射到不同的实例中。多实例可以减少库内部竞争,增加数据库的并发处理能力。
我们也可以通过参数控制缓冲池的大小,在生产环境下,数据库一般都会部署在64位的操作系统下,因为32位机器最大的内存也仅有3G,相对来说太小了。
如何管理缓冲池中的页
MySQL缓冲池的大小是固定的,随着实例的运行,会有很多页被不断地读入和读出,那么MySQL是如何管理这个缓冲池的呢?
MySQL采用的是改良版的LRU算法来管理缓冲池的页。LRU算法大家都清楚,最常被读到的页放在LRU前端,最不常被读到的页放在尾端。MySQL对LRU算法做了一些更改,每当读取一个新的页到内存时,不会按照常规的LRU算法,将其放到LRU列表的最前端,而是根据innodb_old_blocks_pct参数的配置,放到LRU列表的某个位置,例如上述参数的值为40%,那么,就会放到离尾端40%的位置。这个位置,叫做midpoint。midpoint之前的位置,叫做热端,可以理解为:热端的数据,即是热点数据。
那么,为啥要这么搞呢? 我们可以设想一个场景,如果有几个页是热点数据,经常会被读取。他们理所当然的会放在LRU列表的最前端。然后这时,用户进行了一个全表扫描操作,这个操作会往内存中新增许多磁盘上的页,如果采用常规LRU算法,这些新页会挤掉热点数据页,占据列表头部,甚至直接把热点数据挤出缓冲区。但是用户只是在这一刻偶尔进行了一下table scan,之后依然会读取热点数据,但此时缓冲池中是大量table scan读入的非热点数据,热点数据只能从磁盘重新读取了,无疑增加了许多耗时。
所以,MySQL采用了上述方法。与此同时,MySQL还有一个参数:innodb_old_blocks_time,这个参数的值,意味着当一个数据页被读取到了midpoint位置时,需要经过多久,才会被加入到LRU列表的热端。
通过上述两个参数的配置,我们可以做到,当一个页被读入缓冲池中,并且在缓冲池中需要待够一定时长之后(没有被LRU列表淘汰),才能进入到LRU列表的热端,这样就极大地保证了LRU的前部存放的是真正的热点数据。
注意,LRU列表只管理缓冲池中的数据页和索引页,其他类型的页是不归LRU列表管理的。
LRU列表只管理已被读取的页,当数据库刚启动时,LRU列表是空的,因为此时还没有任何一页被读取到内存中,这时,所有的空闲页存在于free列表中。当需要往缓冲池中新放入一页时,首先判断free列表中是否有空闲页,若有,则将该页从free列表删除,并放入LRU列表;若没有,则在LRU列表中淘汰末尾的页。
InnoDB缓冲池的页默认大小为16KB,但是支持压缩功能,将其压缩为1KB,2Kb,4KB,8KB大小的页。针对非16KB的页,采用unzip_LRU列表进行管理。每种大小的页,分别有一个对应的unzip_LRU列表进行管理,并基于伙伴算法来管理内存的分配。例如要申请一个2KB的页,首先去2KB的列表查,如果有空闲的页,直接分配;如果没有,则首先去4KB的列表查,如果有,则将其拆成两个2KB的页,一个用于分配,一个写入2KB的unzip_LRU表中。以此类推。
当缓冲池中有了脏页,就需要将其刷到内存。flush_list中即是所有的脏页。需要注意,LRU列表管理的是已被读取的页,flush列表存储所有脏页,所以一个脏页可能同时存在于LRU列表和flush列表中。二者互不影响。
重做日志缓冲
几乎所有和磁盘打交道的存储都使用到了WAL(write ahead log)技术,即在写入真正数据之前,都会记录一条日志,日志一般是磁盘顺序写的,速度很快,防止在flush真正数据之前宕机。重做日志缓冲,就是MySQL中WAL的实现。
redo log记录了所有修改的操作,是一种逻辑物理日志,具体来说,就是记录了 某个页 发生了 哪些更改。
重做日志缓冲(redo log buffer)大小默认为8M,可以通过参数Innodb_log_buffer_size控制。在MySQL事务开始时,就会不断地将redo log记录到redo log buffer中,之后,会按照一定规则刷到redo log file中。
redo log buffer的刷盘时机是:
- master thread每秒会将buffer中的日志刷入磁盘。
- 当buffer剩余空间的大小不足一半时,刷入磁盘。
- innodb_flush_log_at_trx_commit参数的配置决定。该参数的值可以为0,1,2。不同的值决定了每次事务提交时的刷盘策略。 设置为0:每次事务提交不刷盘。 设置为1:每次事务提交,都刷盘。 设置为2:每次事务提交,仅写入操作系统的页缓存,之后由操作系统的flush策略决定什么时候刷盘。可以看到,当设置这个参数为0或2时,MySQL的事务就失去了“D”的特性。并且当设置为2时,如果写入页缓存时,MySQL宕机了,但是操作系统没挂,那么数据是不会丢失的。 此参数默认为1。
可见,redo log buffer的大小不需要太大,因为至少每秒会flush一次,只要保证一秒内产生的日志量足够存储就行。
InnoDB特性
InnoDB有很多关键的特性,这些特性的存在,使得InnoDB可以具有更高的可靠性以及性能。
这些特性分别有:
- 插入缓冲(insert buffer)
- 两次写(double write)
- 自适应哈希索引
- 异步IO
- 刷新邻接页
插入缓冲
我们都知道MySQL表的组织结构在磁盘中是按照主键ID排序的B+树,并且写入顺序一般情况下主键ID是auto-increment的,所以针对一条数据的写入,聚簇索引的写入一般是顺序写入的(当然总是会写满一个页之后需要写新一个页,但毕竟是极少数的情况嘛,同时需要注意,很多文档里写到b+树是按照顺序存储磁盘上的数据的,这里要明确,这里的顺序存储,指的是逻辑上的顺序,而不是物理上的顺序,很好理解,物理上的顺序也太难维护了吧!逻辑上的顺序,指的是叶节点之间会用双向链表连接起来,同时每一页中的每一行数据也会用双向链表连接起来),不需要随机IO。但是,这时候,针对表上非聚簇索引的写入,大概率就是随机IO了;所以维护非聚簇索引就是一个相对较耗时的问题。
因此,InnoDB中设置了插入缓冲(insert-buffer),对于非聚簇索引的插入或更新,不是直接写入磁盘,而是先判断该非聚簇索引所在的页是否在插入缓冲当中,如果在,则修改缓冲中的索引,如果不在,则先放入一个insert buffer对象中; 最后,再以一定的频率和规则,将insert buffer中的数据和磁盘对应数据进行merge。 这样做的好处就是,在缓冲中积累的多次修改,可能有很多修改会作用在同一页中,便可以将他们合并成一次插入,大大提高了性能。
insert buffer的使用需要满足两个条件:
- 索引是非聚簇索引。
- 索引不是唯一索引。
很好理解,如果是唯一索引的话,每次插入,都需要从磁盘中读取全量数据进行唯一性比对,就失去了buffer存在的意义。
与此同时,如果使用了插入缓冲,假如MySQL某一刻宕机了,势必会有很多非聚簇索引未合并到磁盘,这会大大影响数据库恢复的速度。
change buffer
change buffer是MySQL在InnoDB 1.0.x版本引入的,可以理解为是insert buffer的升级版,适用对象依然是非唯一的辅助索引,insert buffer仅针对插入操作;change buffer,顾名思义,可以针对所有DML操作,即增删改都可以利用到change buffer。
两次写
两次写(double write)为MySQL带来了数据页的可靠性。传统机械磁盘原子写的单位为一个扇区,即512字节,文件系统一页大小为4kb,MySQL默认一页大小为16kb,所以MySQL一页显然不可能做到原子写入磁盘。假设某一个数据页正在刷盘,刷了4kb,MySQL就宕机了,这种情况叫做部分写失效(partial page write)。
对MySQL有些了解的人会想,我们可以通过redo log进行恢复啊。真的可以吗?答案是不行。
那么为什么不行呢? 接下来所讲的,将是重中之重。
在解答为什么不行之前,需要为大家普及几个概念.
物理日志,逻辑日志,物理逻辑日志
物理日志
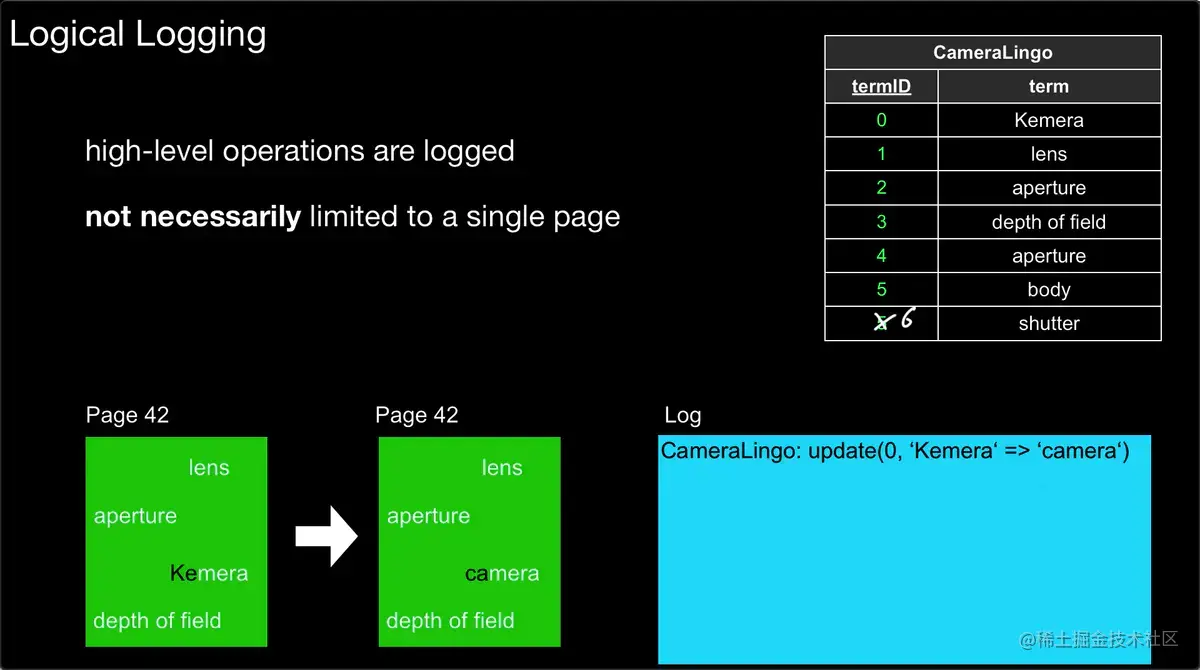
物理日志,以页为单位,记录了某一页中,发生变更的字段的 更新前 和 更新后 的具体值.

如图,可以看到,物理日志记录了 某一页(42页)具体发生变更的offset:发生变更的长度(367:2) 的 更新前("Ke") 和 更新后("ca")的值. 物理日志以字节编码落盘,是幂等的.
逻辑日志
逻辑日志,站在更高的抽象维度表述变更,而不关心这个抽象维度具体作用于哪些物理页。 具体到mysql上,逻辑日志有三种类型:
- statement格式:即原始DML SQL语句。
- row格式:记录了表中每行的修改。
- mix格式:上述两种的结合。
可以看到,无论哪种格式,都不care具体作用于哪个物理页,都是作用于逻辑上的某个单位。
逻辑日志相对物理日志而言:
- 逻辑日志日志量更小。
- 重放速度更慢,因为需要解析类SQL语句,找到具体的page,再更新数据。
- 逻辑日志是非幂等的。
逻辑物理日志

Physiological Logging 折中了上述两种日志的优缺点,特点是:
- 与物理日志相同点:更新操作相对于 page 进行,每一条日志仅仅涉及一个 page 的修改;
- 与逻辑日志相同点:日志内容为逻辑语句,而不是记录某些字段更新前后的内容。 MySQL的redo log实际上是逻辑物理日志。截止MySQL5.6版本,共有51种类型的redo log。其拥有共同的日志头部格式:

可以看到,space和page-no决定了更新哪一页。无论哪种类型的redo log,其不会像物理日志那样记录页中某个偏移量的更新前和更新后的值,所以其并不是幂等的。
InnoDB数据页结构
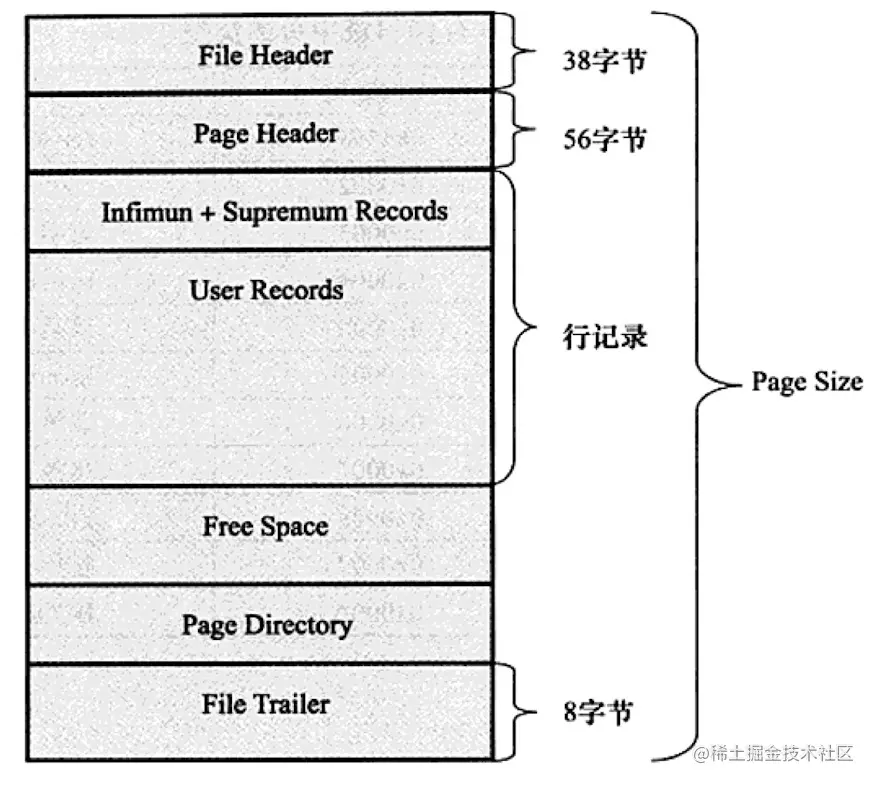
这里大家可以先看一下,InnoDB数据页的存储结构,在这里,大家主要需要关注的是File Header和File Trailer。我们需要知道,File Trailer当中存在一个“checksum”字段,代表该页的checksum值,InnoDB通过将该字段和File Header中的FIL_PAGE_SPACE_OR_CHECKSUM 值进行比较,来保证这一页的完整性,注意这里的比较不是简单的等值比较,而是通过InnoDB的checksum函数进行比较。InnoDB每从磁盘读取一页时,默认都会进行上述校验来保证该页的完整性。
-----------------------------------------
回到两次写,之前提到不能用redo log进行重做的原因是,MySQL在重做每一页时,首先会检验该页的完整性,通过checksum校验的方式进行校验,如果校验不通过,即表明该页是“已损坏”的,那么MySQL就会拒绝对其进行重做,因为此时的重做是没有意义的。
我们刨根问底的想一下,为什么这样的重做是没有意义的呢?
上面讲到,redo log是逻辑物理日志,既然逻辑物理日志是非幂等的,那如果将其强行作用于某个因为部分写失效而已损坏的页,数据库并不知道,这个页中哪些数据已经被写入了,哪些还未被写入,所以重放可能会导致数据的不一致。因此,数据库需要一个没有被部分写失效污染的,干净的数据页来进行redo log的重做。
于是,MySQL实现了两次写(double write)来解决上述问题。
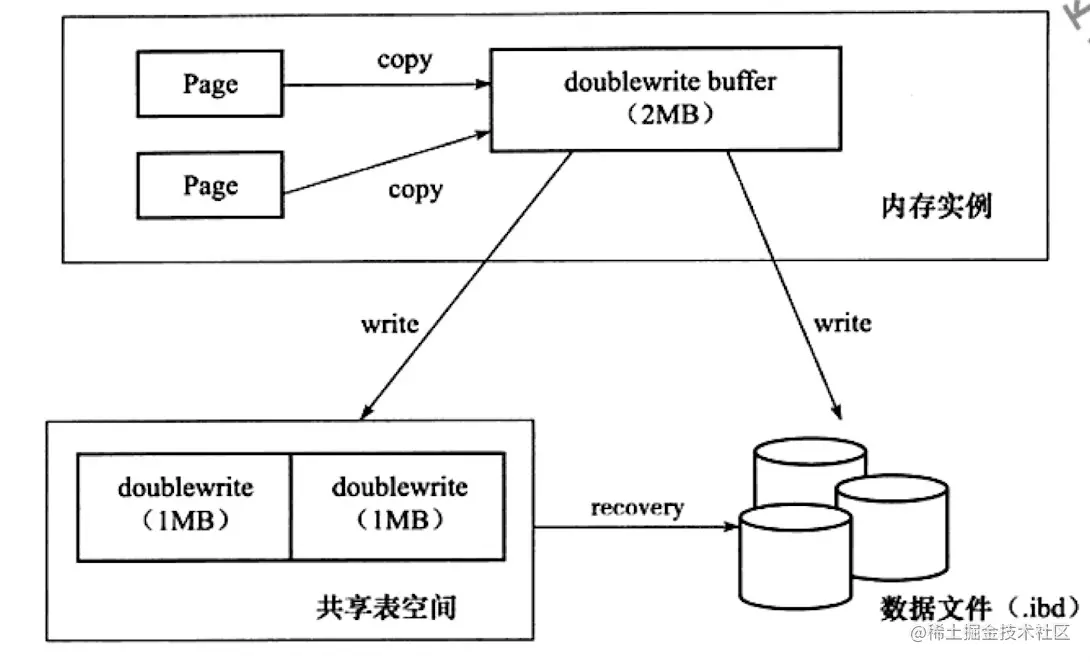
其实现由两部分组成,内存中的doublewrite buffer,以及磁盘中共享表空间的连续128个页,即2MB,当对内存中的脏页刷盘时,并不直接刷盘,而是:
- 首先copy到内存中的doublewrite buffer
- 之后每次1MB的顺序写入到共享表空间的doublewrite中
- 然后立马同步数据文件。 如果在同步数据文件时宕机了,那么此时共享表空间中已经有了该页的一个干净的副本,可以通过这个干净的副本页进行redo重做。
自适应哈希索引
InnoDB表采用B+树的格式组织存储,在生产环境下,一般B+树的树高为3-4层,所以针对数据的读取一般需要3-4次IO。而哈希是一种快速定位所需数据的方法,只需O(1)的时间复杂度即可查找到数据。
所以,InnoDB引擎会监控针对索引页的查询操作,如果观察到建立哈希索引可以带来速度的提升的话,会自动创建哈希索引,无需人工的介入,称之为“自适应哈希索引”。自适应哈希索引是根据缓冲池中的索引页建立的,无需访问磁盘,所以建立速度较快。
自适应哈希索引只能进行等值查询,如 select from xxx where col = xxx;这样的操作。
异步IO
异步IO相对应的是同步IO,同步IO每次发出一条IO请求时,需要等待这次请求返回,才可以进行下一次IO。而异步IO无需等待上一次IO请求的返回,即可发出新的IO请求,然后等待所有发出的IO返回。
异步IO的优势就是IO合并,用于提升IOPS的性能。例如我需要读取(space,page-no)为(8,6)(8,7)(8,8)的三个数据页,同步IO需要三次IO,而异步IO可以发出从(8,6)开始,连续读取48KB的请求,将三次IO合并为一次。 在InnoDB中,脏页的刷新均是通过异步IO来完成。
在InnoDB1.1.x之前,InnoDB的异步IO是通过引擎代码模拟实现,而在这之后,内核提供了AIO的支持。 值得一提的是,Windows,Linux操作系统都提供了内核AIO的支持,但MACOS却没有提供,如果选用MACOS为MySQL的载体操作系统,依然只能使用引擎模拟AIO的方式。
可以通过参数innodb_use_native_aio来控制是否启用AIO,Linux下默认为on。
刷新邻接页
当InnoDB刷新一个脏页时,会检测该页所在区中的所有页是否有脏页,如果有,则一并flush了。关于区,你只需要知道这是MySQL逻辑结构中的一个连续存储单位,大小为1M。
这个方法结合刚讲的AIO,可以有效提升脏页刷新效率。
但是我们也需要考虑一些问题:
- 会不会将不怎么脏的页刷新了,之后很快又变成了脏页?
- 固态硬盘IOPS很高,还需要这个特性吗?
所以,在InnoDB1.2版本开始,提供了参数innodb_flush_neighbors来控制该特性的开关。
总结
本文详细的解读了InnoDB的内存池结构,以及诸多InnoDB的特性。非常欢迎大家阅读文章后,提出宝贵的意见,每条评论我都会看,你们的支持将是我更新的动力!
-
相关阅读:
C动态内存分配和管理函数malloc,calloc,free与realloc
平衡二叉树(AVL) 的认识与实现
python数据处理—pandas相关函数的使用(持续更新)
java生成excel,uniapp微信小程序接收excel并打开
何为链表、链表示例以及翻转链表
数仓工具—Hive进阶之表设计最佳实践(21)
如何在表格里面添加表单,并且进行表单验证
【应用】布隆过滤器
verilog——移位寄存器
28岁转行软件测试真的很难吗?按照我整理出的这份3000字学习指南就没问题...
- 原文地址:https://blog.csdn.net/Trouvailless/article/details/126345961