-
打造千万级流量秒杀第十二课 高性能缓存:多级缓存是如何提升服务性能的?
上一讲,我给你介绍了如何为不同的业务场景优化系统参数,从而提升网络性能。但是在实际当中,仅靠这种方式并不能解决所有性能问题。比如当并发高的时候,数据库的响应时间可能达到一秒以上,这个时候,想要通过优化系统参数就很难做到。那怎么办呢?我们可以使用缓存来提升并发访问数据的性能。
什么是缓存?缓存是一种存储器,它位于访问速度、容量和成本相差较大的计算单元和目标存储器之间,主要用于存储热点数据的中间状态,为计算单元处理热点数据时提供良好的访问性能。
打个比方,不知道你平时买东西的时候有没有这样一种体会:一些日常生活用品、水果蔬菜,在小区门口小超市可能就能买到,但类似按摩椅这种商品,就需要你到市区专卖店里买。
很显然,在小区超市买东西要比去市区快很多,原因就是小超市离你比较近。假如把消费者比喻成处理数据的计算单元,商品比喻成数据,那么这里的小超市就相当于缓存,而日常生活用品则是热点数据。
在秒杀系统中,活动信息数据请求量很大,属于热点数据。如果热点数据每次都从 DB 中读取,会给 DB 带来庞大的压力,导致性能大幅下降。所以,我们需要用缓存来提升热点数据的访问性能,比如将活动信息数据在浏览器的缓存中保存一段时间。
但缓存中的热点数据通常具有时效性,比如当后端活动数据有更新的时候,浏览器缓存中的原活动信息就会失效,进而导致缓存穿透问题。为此,我们通常会采用多级缓存来避免单级缓存穿透,提升服务性能。
什么是多级缓存
多级缓存通常是由多种不同容量、不同性能的存储器按顺序组成,最有名的是存储器金字塔。

在存储器金字塔中,从上往下看,各层存储器离计算单元越来越远,性能和成本从高到低,容量从小到大。 其中的每一层存储器,都是其下一层存储器的缓存,如 L3 缓存是内存的缓存,内存是硬盘的缓存。
那么,这个多级缓存各层存储器的性能如何呢?
上层的寄存器、L1 缓存、L2 缓存是位于 CPU 核内的高速缓存,访问延迟通常在 10 纳秒以下。L3 缓存是位于 CPU 核外部但在芯片内部的共享高速缓存,访问延迟通常在十纳秒左右。高速缓存具有成本高、容量小的特点,容量最大的 L3 缓存通常也只有几十MB。
本地内存是计算机内的主存储器,相比 CPU 芯片内部的高速缓存,内存的成本要低很多,容量通常是 GB 级别,访问延迟通常在几十到几百纳秒。
内存和高速缓存都属于掉电易失的存储器,如果机器断电了,这类存储器中的数据就丢失了。

本地磁盘是计算机内的辅助存储,负责存储一些希望掉电不丢失的数据,主要有机械磁盘和固态硬盘。它的容量通常在几百 GB ,大的达到了 TB。固态硬盘访问延迟通常在几十到几百微秒,而机械硬盘通常在十几到几十毫秒。
网络内存和网络磁盘属于外部存储,通常用于多个计算机之间共享数据。比如 Redis 属于网络内存存储, NAS 文件系统和 MySQL 之类的关系型数据库属于网络磁盘存储。网络内存和本地磁盘通常用来当作网络磁盘存储的缓存。
为什么会有存储器金字塔结构呢?
主要还是因为存储器的发展速度远无法匹配 CPU 而形成的。具体来说,CPU 的发展基本上符合摩尔定律,而存储器特别是硬盘读写速度的提升却比较漫长,大幅提升主要还是在固态硬盘出现后。如果没有缓存,硬盘访问速度太慢会导致 CPU 性能下降。特别是随着计算机对数据访问的性能要求越来越高,存储器与CPU 的性能差距越来越大,为了满足需求,缓存的级数越来越多,也就形成了现在的存储器金字塔模型。
那么,秒杀系统的多级缓存是如何设计的呢?
秒杀系统多级缓存设计
秒杀系统包含动态数据和静态数据,它的多级缓存包括浏览器端缓存和服务器端缓存。其中浏览器端缓存分为本地内存缓存和本地磁盘缓存,服务器端缓存有本地内存缓存、网络内存缓存。
下面我给你介绍下各部分缓存的原理,以及这么设计的原因。
浏览器本地内存缓存
为什么浏览器端需要有内存缓存呢?
回想下,浏览器端是如何获取秒杀活动信息的呢?当进入秒杀活动页的时候,浏览器通过 JavaScript 发起 HTTP 请求,从秒杀接口服务获取活动信息。一个专题活动,一旦上线,在活动期间是不会随意变更的。所以,活动信息是可以在内存里缓存一段时间的。
在浏览器端,活动信息可以缓存多久?建议缓存到当前场次活动结束之前。 也就是说,当活动场次因为某场活动结束而切换时,应该从后端获取新的活动数据并更新内存缓存。为什么呢?因为如果运营发现后面某场活动配错了,可以在活动开始前修改该活动信息,在场次切换的时候,浏览器将更新到最新的活动信息。
另外,浏览器的内存缓存还用于缓存页面渲染的结果,比如从后端获取到商品图片后,将其渲染到页面上展现给用户。
总的来说,浏览器的内存缓存是有时效性的,浏览器内存中缓存的数据会随着页面渲染、关闭而更新、丢弃。
浏览器本地磁盘缓存
那什么情况下需要用到浏览器的本地磁盘缓存呢?前面提到的商品图片的渲染结果是缓存在内存中的,假如用户将活动页面关闭再打开,如果重新从服务端下载所有图片并渲染出来,图片的渲染速度会非常慢。怎么办呢?
已经生成的商品图片文件数据是不会随意变动的,所以浏览器端没必要每次都从后端下载图片。但是,也不能将所有图片都缓存到内存里。因为缓存所有的商品图片将会占用大量系统内存,导致系统变慢,影响用户体验。
内存通常适合缓存一些比较小的图片,比如图标、缩略图之类的。由于每张商品图片大小在几百 KB 以上,前端通常会采用一种叫作 “懒加载” 的技术——只加载页面可见区内的图片,这么做既可以提高页面首屏渲染速度,还能有效减少浏览器内存的占用。
那浏览器应当如何缓存商品图片呢?当后端给浏览器端返回图片的时候,可以通过一些参数,告诉浏览器端将图片在本地磁盘上缓存一段时间。具体我们可以在后端返回的 HTTP 头中加上浏览器缓存相关参数,如下图所示:
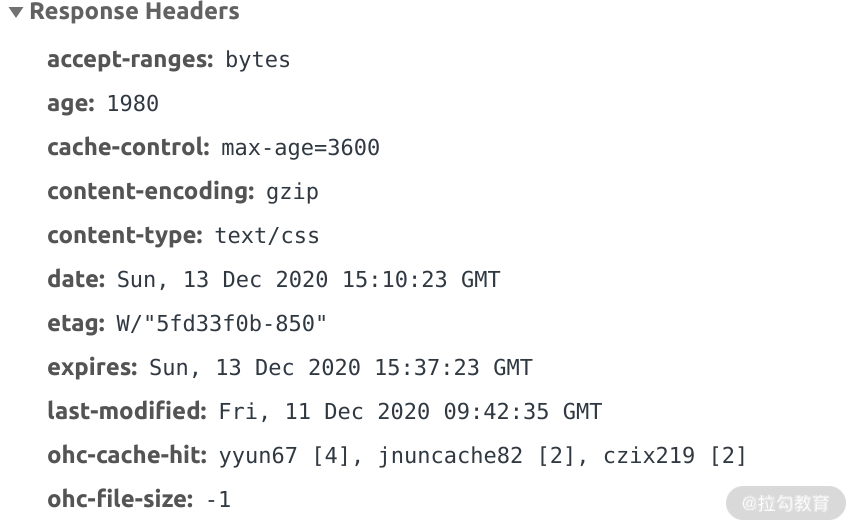
浏览器缓存参数
上图 HTTP 返回头中的 age、cache-control、etag、expires、last-modified 便是用来告诉浏览器应该如何缓存该文件。这些参数中,age、cache-control、expires、last-modified 是用来告诉浏览器该文件已经缓存多久了、最多缓存多久、什么时候过期、上一次修改的时间。
etag 是怎么用的呢?etag 是由服务端生成的一个唯一标识,当文件的本地缓存到期后,浏览器会将该文件的 etag 发给服务端。服务端如果校验自己本地的 etag 与浏览器发过来的 etag 不一致,则会将最新的文件数据返回给浏览器并告诉它缓存该数据;如果一致,服务端只会返回 HTTP 头,告诉浏览器端继续用浏览器本地缓存,而不会返回实际的数据。
由于 HTTP 头通常要比文件数据小很多,在文件没有变更的情况下,通过 etag 能节省很多网络流量,有效提升访问性能。
除了商品图片,为了减少服务端压力,提升服务端性能,秒杀页面用到的 css、js 等静态资源文件,也是通过上述方法缓存在浏览器本地的。
服务端本地内存缓存
前面提到了秒杀活动信息是从秒杀接口服务获取的,那秒杀接口服务又是如何存储活动信息的呢?
在做需求分析和总体架构设计的时候我提到过,秒杀活动信息是由秒杀管理后台配置并存储到数据库中的,而数据库最终会将数据存储到磁盘上。假如活动期间每秒一千万次请求都直接从数据库中取数据,你觉得数据库能扛住吗?也许,当数据库资源足够的时候能扛住,但这意味着要投入很大的成本来建设一个能扛住千万并发的数据库。
那么,有没有办法用相对较小的成本来提升服务端数据访问性能呢?有,那就是利用服务端本地内存缓存。
对于 Golang、java、C/C++ 等静态类型语言来说,最大的好处就是能将热点数据缓存在程序内存中,以便充分利用本地内存的高速读写能力,大幅提升数据访问的性能。
这个性能提升多少?打个比方,如果从数据库加载活动信息数据,即使在并发压力不大的情况下,网络延迟加上数据库处理延迟,整个延迟可能达到 10 毫秒以上。如果用本地内存缓存,整个加载过程能降到 100 纳秒以下,也就是低于 10 毫秒的 1/100000,性能提升 100000 倍以上!
当然,本地内存缓存是需要设置有效时间的。当有效时间过期,会有部分请求发生缓存穿透。流量小的时候问题不大,一旦并发量达到千万,哪怕是 1/100 的流量穿透到了数据库,数据库也可能被压垮。
怎么解决呢?配置类的数据格式比较固定,数据量比较小,我们可以在程序内部使用定时器,定时从下游数据库中获取最新数据,更新到本地内存缓存中。
如果说缓存穿透在软件正常运行时有可能发生,那么有一种情况,缓存穿透必定会发生,那就是在服务启动或重启的时候。 你可以想象一下,程序刚启动的时候,本地内存缓存为空,此时突然有大量请求涌进来,数据库一定能扛住吗?

那该怎么办呢?我们可以在本地内存缓存与数据库之间加一层网络内存缓存,为秒杀接口服务各节点提供共享缓存。我上面提到的定时任务,就可以从网络内存缓存中获取最新的数据,并更新到本地内存缓存中,避免本地内存缓存穿透。
服务端网络内存缓存
还记得第 9 讲里我提到的 Memcached 和 Redis 吗?它们常用来当作网络内存缓存来提供服务,其性能至少是关系型数据库的几十倍。在这里,我们还是用 Redis 来介绍下 。
前面提到了,在秒杀接口服务正常运行时,可以通过程序内部定时任务,来定时更新本地内存缓存。但 Redis 是个通用的开源软件,它内部没有从其他存储同步数据的逻辑,那我们要如何将数据同步到 Redis 里呢?答案是利用秒杀系统的管理后台服务。
具体来说,我们可以先在管理后台系统发布修改后的活动信息,然后将最新的活动信息写入到 Redis 中。另外,为了防止 Redis 挂掉重启后缓存数据丢失,管理后台服务中可以实现一个定时器,定时将已发布的活动配置从数据库中取出,并写入到 Redis 中。
由于管理后台是实时将最新数据写入到 Redis 中的,并且有定时任务作兜底方案,这也保障了在 Redis 正常运行的过程中不会有缓存穿透的问题。
以上便是秒杀系统多级缓存中各缓存的原理。多种缓存配合使用,最终落到数据库上的请求可能每秒只有几十次,而系统性能和稳定性都可以得到大幅提升。

小结
这一讲主要和你介绍了多级缓存的实现原理。通过多级缓存,我们既能提升浏览器端的加载速度,又能提升服务端整体性能和稳定性。其中,最值得注意的是,如何解决缓存穿透问题和数据同步问题。你学会了吗?
思考题:
前面提到了网络内存和本地磁盘可以当作网络磁盘的缓存使用,那为何我们在设计方案中使用的是网络内存,而不是本地磁盘呢?
你可以把答案写在留言区。我很期待你的回答哦。
这一讲就到这里了,下一讲我将为你介绍如何提升日志性能避免 IO 瓶颈。到时见!
精选评论
**贝:
用缓存就一定会有机会带来数据不一致,关键是不一致带来的影响是否能被业务场景接受
**毅:
分布式环境,本地无状态,状态保存在网络内存中。
*铁:
网络磁盘后端可以实现高可用,本地只有一个。网络磁盘也比较方便扩容
XX:
本地缓存不利于弹性扩缩容;相同的服务端程序都是用自己本地的缓存数据,可能出现数据不一致的问题。
**用户0528:
本地磁盘慢,而且存储在本地不够集中,不同的机器刷新数据可能不一致。
-
相关阅读:
DTO概念的了解和使用
QDir(目录)
RHCSA-VM-Linux安装虚拟机后的基础命令
vue3.0 实现图片延迟加载 自定义属性
缓存怎么测试?
SpringCloud基础5——elasticsearch
算法题笔记 6-10 (青蛙跳台阶)
寒武纪实现高维向量的softmax进阶优化和库函数对比
如何应对软件可变性?这4种常用的方法肯定要知道
windows11配置电脑IP
- 原文地址:https://blog.csdn.net/fegus/article/details/126342601