-
【Make YOLO Great Again】YOLOv1-v7全系列大解析(Head篇)(尝鲜版)

Rocky Ding 公众号:WeThinkIn 写在前面
【Make YOLO Great Again】栏目专注于从更实战,更深刻的角度解析YOLOv1-v7这个CV领域举足轻重的算法系列,并给出其在业务侧,竞赛侧以及研究侧的延伸思考。欢迎大家一起交流学习💪,分享宝贵的ideas与思考~
大家好,我是Rocky。
近年来YOLO系列层出不穷,更新不断,已经到v7版本。Rocky认为不能简单用版本高低来评判一个系列的效果好坏,YOLOv1-v7不同版本各有特色,在不同场景,不同上下游环境,不同资源支持的情况下,如何从容选择使用哪个版本,甚至使用哪个特定部分,都需要我们对YOLOv1-v7有一个全面的认识。
故Rocky将YOLO系列每个版本都表示成下图中的五个部分,逐一进行解析,并将每个部分带入业务侧,竞赛侧,研究侧进行延伸思考,探索更多可能性。
【Make YOLO Great Again】YOLOv1-v7全系列大解析(Neck篇)已经发布,大家可按需取用~
而本文将聚焦于Head侧的分享,希望能让江湖中的英雄豪杰获益,也希望大家提出宝贵的建议与观点,让这个栏目更加繁荣。
So,enjoy(与本文的BGM一起食用更佳哦):
干货篇
----【目录先行】---- -
YOLOv1-v7论文&&代码大放送
-
YOLO系列中Head结构的由来以及作用
-
YOLOv1 Head侧解析
-
YOLOv2 Head侧解析
-
YOLOv3 Head侧解析
-
YOLOv4-v7 Head侧解析(未完待续)
【一】YOLOv1-v7论文&&代码大放送
YOLOv1论文名以及论文地址:You Only Look Once:
Unified, Real-Time Object DetectionYOLOv1开源代码:YOLOv1-Darkent
YOLOv2论文名以及论文地址:YOLO9000:
Better, Faster, StrongerYOLOv2开源代码:YOLOv2-Darkent
YOLOv3论文名以及论文地址:YOLOv3: An Incremental Improvement
YOLOv3开源代码:YOLOv3-PyTorch
YOLOv4论文名以及论文地址:YOLOv4: Optimal Speed and Accuracy of Object Detection
YOLOv4开源代码:YOLOv4-Darkent
YOLOv5论文名以及论文地址:无
YOLOv5开源代码:YOLOv5-PyTorch
YOLOx论文名以及论文地址:YOLOX: Exceeding YOLO Series in 2021
YOLOx开源代码:YOLOx-PyTorch
YOLOv6官方讲解:YOLOv6:又快又准的目标检测框架开源啦
YOLOv6开源代码:YOLOv6-PyTorch
YOLOv7论文名以及论文地址:YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object
detectorsYOLOv7开源代码:Official YOLOv7-PyTorch
【二】YOLO系列中Head结构的由来以及作用
YOLO系列中的Head侧主要包含了Head检测头,损失函数部分以及Head侧的优化策略。
Head检测头体现了YOLO系列“简洁美”的思想,与two-stage检测算法相比,YOLO取消了RPN模块,设计了特征提取网络+检测头的end-to-end整体逻辑,其对工程的友好特性让工业界顿时开满“YOLO花”。
YOLO系列的损失函数部分可谓是目标检测领域中的“掌上明珠”,其在业务侧,竞赛侧和研究侧都有很强的迁移价值。
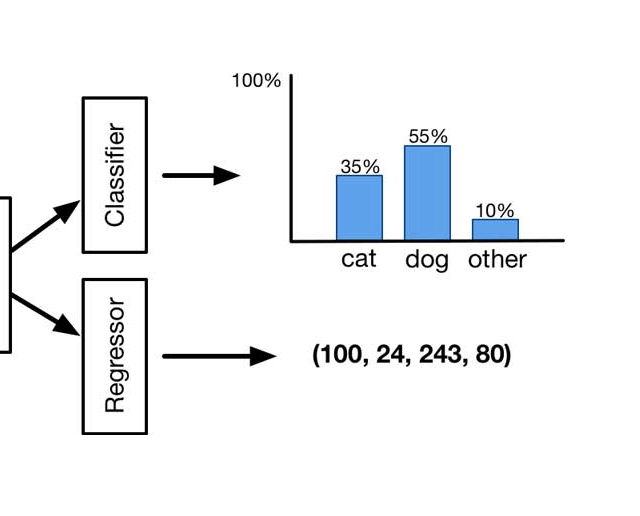
【Rocky的延伸思考】
- 业务侧:YOLO系列的Head侧中,不管是Head检测头,损失函数部分以及Head侧的优化策略,其在业务侧都可以作为baseline进行迁移使用。
- 竞赛侧:YOLO系列的Head侧在目标检测竞赛中可以说时入场必选结构,能极大程度上缩短竞赛初期的熟悉适应成本。
- 研究侧:YOLO系列的Head侧具备作为baseline的价值,不管是进行拓展研究还是单纯学习思想,这个算法都是不错的选择。
【三】YOLOv1 Head侧解析
YOLOv1作为YOLO系列的开山鼻祖,其Head侧整体逻辑比较直观,并且对后续的版本影响深远。
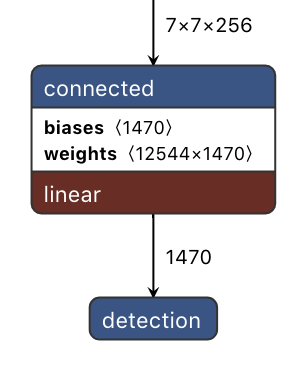

YOLOv1中,图片被划分为 7 × 7 7\times7 7×7的网格(grid cell),每个网络在Head侧进行独立检测。
YOLOv1在Inference过程中并不是把每个单独的网格作为输入,网格只是用于物体ground truth中心点位置的分配,如果一个物体的ground truth中心点坐标在一个grid cell中,那么就认为这个grid cell就是包含这个物体,这个物体的预测就由该grid cell负责。而不是对图片进行切片,并不会让网格的视野受限且只有局部特征。
YOLOv1的输出是一个 7 × 7 × 30 7\times7\times30 7×7×30的张量, 7 × 7 7\times7 7×7表示把输入图片划分成 7 × 7 7\times7 7×7的网格,每一个网格的通道维度等于 30 = ( 2 × 5 + 20 ) 30=(2\times5+20) 30=(2×5+20),代表YOLOv1中每个网格能预测2个框,每个框能预测5个参数 ( x , y , w , h , C ) (x,y,w,h,C) (x,y,w,h,C)再加上20个种类。
把上述内容转换成通用公式就是网格一共是 S × S S \times S S×S个,每个网格产生 B B B个检测框,每个检测框会经过网络最终得到相应的bounding box。最终会得到 S × S × B S\times S\times B S×S×B个bounding box,每个bounding box都包含5个预测值,分别是bounding box的中心坐标 x , y x,y x,y,bounding box的宽高 w , h w,h w,h和置信度 C C C。其中 C C C代表网格中box能与物体的取得的最大IOU值。
铺垫了这么多变量表示,到这里终于可以引出对工业界产生深远影响的YOLOv1的损失函数,YOLO系列的后续版本的损失函数都是从这个最初的形式优化而来。
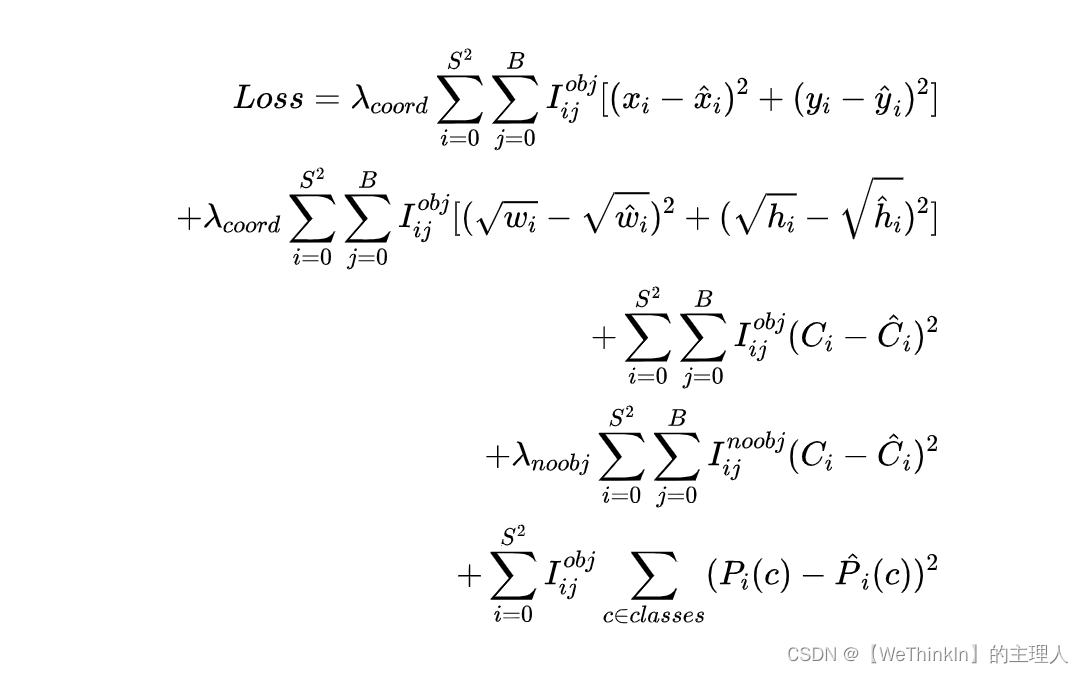
乍一看YOLOv1的损失函数十分复杂,don’t worry,接下来Rocky将进行详细分析。
整体上来看,YOLOv1的损失函数可以分为检测框的回归损失,置信度误差损失以及分类误差损失。
公式中第一行和第二行代表了检测框的中心点和宽高的回归损失,其中 I i j o b j I^{obj}_{ij} Iijobj表示第 i i i个网格的第 j j j个box是否去预测这个物体,即这个box与物体的ground truth box的IOU值和其他box相比是否是最大的。如果是,那么 I i j o b j = 1 I^{obj}_{ij} = 1 Iijobj=1,否则 I i j o b j = 0 I^{obj}_{ij} = 0 Iijobj=0,而YOLOv1中每个网格只有2个box,还是比较简单的。值得注意的是宽高回归损失中使用了开根号的操作,这是考虑到了小目标与大目标对应的检测框会存在差异,并消除这个差异。不开根号时,损失函数往往更倾向于调整尺寸比较大的检测框。例如,12个像素点的偏差,对于 888 × 888 888\times888 888×888的检测框几乎没有影响,因为此时的IOU值还是很大,但是对于 28 × 48 28\times48 28×48的小检测框影响就很大。
公式中第三行和第四行代表了置信度误差损失,分别是含物体的置信度误差损失和不含物体的置信度误差损失。当网格中含有物体时, I i j o b j = 1 , I i j n o o b j = 0 I^{obj}_{ij} = 1, I^{noobj}_{ij} = 0 Iijobj=1,Iijnoobj=0,并且置信度ground truth值 C ^ i = 1 \hat{C}_i = 1 C^i=1;当网格中不含物体时, I i j o b j = 0 , I i j n o o b j = 1 I^{obj}_{ij} = 0, I^{noobj}_{ij} = 1 Iijobj=0,Iijnoobj=1,并且置信度ground truth值 C ^ i = 0 \hat{C}_i = 0 C^i=0。包含物体的预测置信度 C i C_i Ci为网格中box与物体ground truth box能取到的最大的IOU值,这很好理解,计算逻辑也直接明了。但是不包含物体的置信度误差损失究竟是怎么回事?don’t worry,不包含物体的置信度误差损失包含两部分,一部分是包含物体的网格中的两个box中不负责预测的那个box,另外一部分是不包含物体的网格中的box,让他们都往0回归吧!
目标检测中存在一个常见问题,那就是类别不均衡问题,YOLOv1中也不例外。在一张图像中物体往往只占一小部分,大部分还是背景为主。故在置信度误差损失中设置了 λ c o o r d = 5 \lambda_{coord} = 5 λcoord=5和 λ n o o b j = 0.5 \lambda_{noobj} = 0.5 λnoobj=0.5来平衡含物体的置信度误差损失和不含物体的置信度误差损失两者的权重,让模型更加重视含物体的置信度误差损失。
公式中第五行代表了分类误差损失,只有当 I i j o b j = 1 I^{obj}_{ij} = 1 Iijobj=1时才会进行计算。
到这里,YOLOv1损失函数的解析就告一段落了。接下来我们看一下YOLOv1Head侧的优化策略:
- 使用NMS算法,过滤掉一些重叠的检测框。
- 同一网格中的不同检测框有不同作用,也就是置信度误差损失的设计逻辑,这样可以增加召回率
- Inference时使用 P × C P\times C P×C作为输出置信度。使用物体的类别预测最大值 P P P乘以最合适的预测框 C C C,这样也可以过滤掉一些大部分重叠的检测框,同时考虑了检测框与类别让输出更加可信。
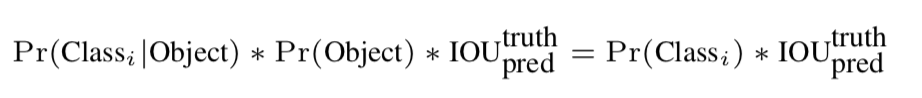
YOLOv1的缺陷:
- 由于YOLOv1每个网格的检测框只有2个,对于密集型目标检测和小物体检测都不能很好适用。
- Inference时,当同一类物体出现的不常见的长宽比时泛化能力偏弱。
- 由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。
【Rocky的延伸思考】
- 业务侧:YOLOv1 Head侧经过时间的考验与沉淀,非常适合作为简单业务的入场baseline部分模块进行搭建。
- 竞赛侧:YOLOv1 Head架构坦率来说在竞赛中已不具备竞争力,但作为baseline入场模型也未尝不可。
- 研究侧:YOLOv1 Head架构可谓是YOLO系列的开山鼻祖,给后续系列搭建了baseline,不管是入门学习还是进行扩展研究,都是非常有价值的。
【四】YOLOv2 Head侧解析
YOLOv2的Head侧在YOLOv1的基础上进行了网络结构和损失函数的改进,并且大名鼎鼎的anchor box也在此引入。
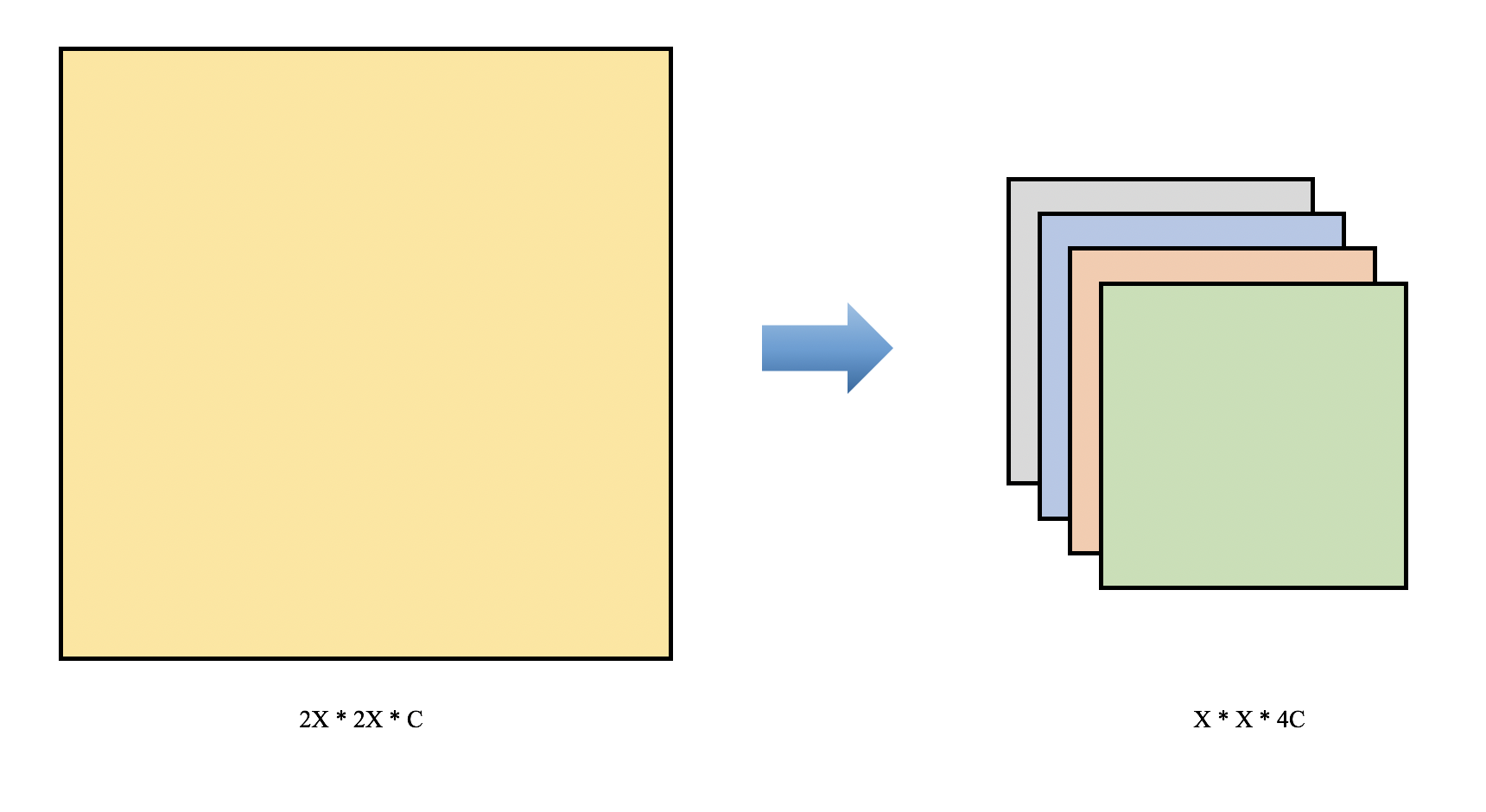
YOLOv2在YOLOv1的基础上去掉了最后的全连接层,采用了卷积和anchor boxes来预测检测框。由于使用卷积对特征图进行下采样会使很多细粒度特征(Fine-Grained Features)的损失,导致小物体的识别效果不佳。故在YOLOv2Head侧中引入了passthrough layer结构,将特征图一分为四,并进行concat操作,保存了珍贵的细粒度特征。
刚才提到了YOLOv2使用卷积和anchor box来输出检测框,那么到底anchor box机制是怎么样的呢?
YOLOv1中每个网格预测两个检测框,并让最合适的检测框向ground truth框进行回归修正。在YOLOv2中,Head侧不对检测框的宽高进行直接硬回归,而是将检测框与Anchor框的偏差(offset)进行回归,并且每个网格指定 n n n个anchor box。在训练时,只有最接近ground truth的检测框进行损失的计算。在引入anchor box后,mAP由69.5下降至69.2,原因在于每个网格预测的物体变多之后,召回率大幅上升,准确率有所下降,总体mAP略有下降。
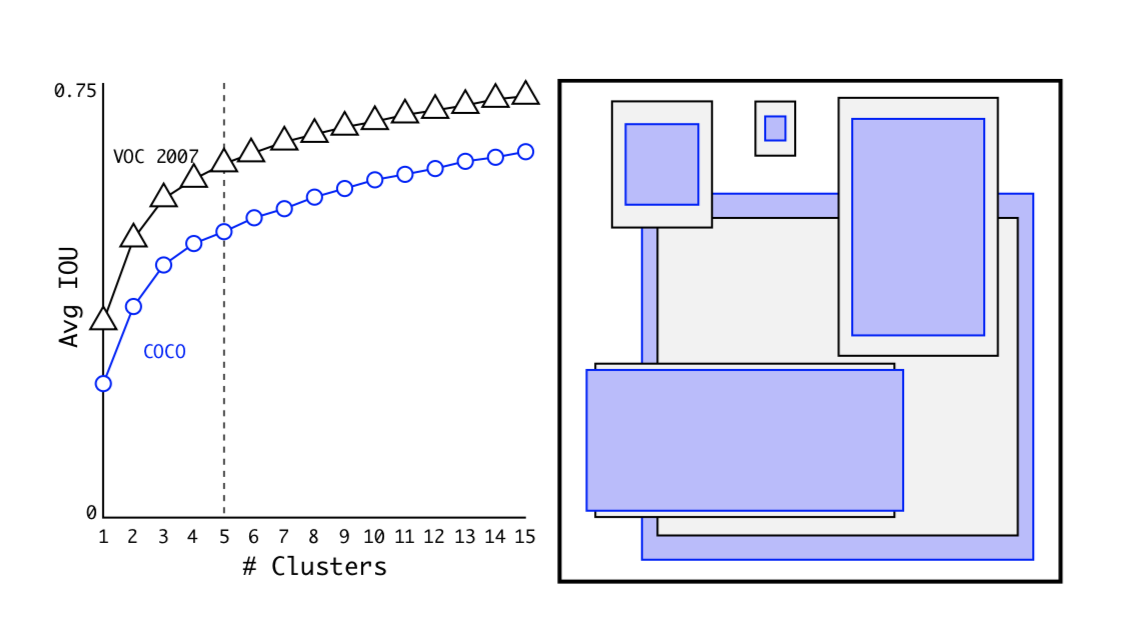
在引入anchor box之后,又使用了Dimension Clusters操作,使得anchor box的宽高由聚类算法产生。没错,就是K-means算法~~(K-NN算法)~~。使用K-means算法获得anchor box的具体细节可以在我之前的文章【三年面试五年模拟】算法工程师的独孤九剑秘籍(第七式)中取用。YOLOv2Head侧输出的feature map大小为 13 × 13 13\times13 13×13,每个grid cell设置了 5 5 5个anchor box预测得到 5 5 5个检测框,一共有 13 × 13 × 5 = 845 13\times13\times5=845 13×13×5=845个检测框,与YOLOv1相比大大提高目标的定位准确率。
优化了anchor box预设置后,YOLOv2设计了Direct location prediction操作来支持检测框与Anchor框的偏差(offset)回归逻辑。与YOLOv1相比,YOLOv2中每个检测框输出5个偏差参数 ( t x , t y , t w , t h , t o ) (t_x,t_y,t_w,t_h,t_o) (tx,ty,tw,th,to),为了将预测框的中心点约束在当前grid cell中,使用sigmoid函数 σ ( ⋅ ) \sigma(·) σ(⋅)将 t x 和 t y t_x和t_y tx和ty归一化处理,将值约束在 [ 0 , 1 ] [0,1] [0,1]之间,这使得模型训练更稳定。
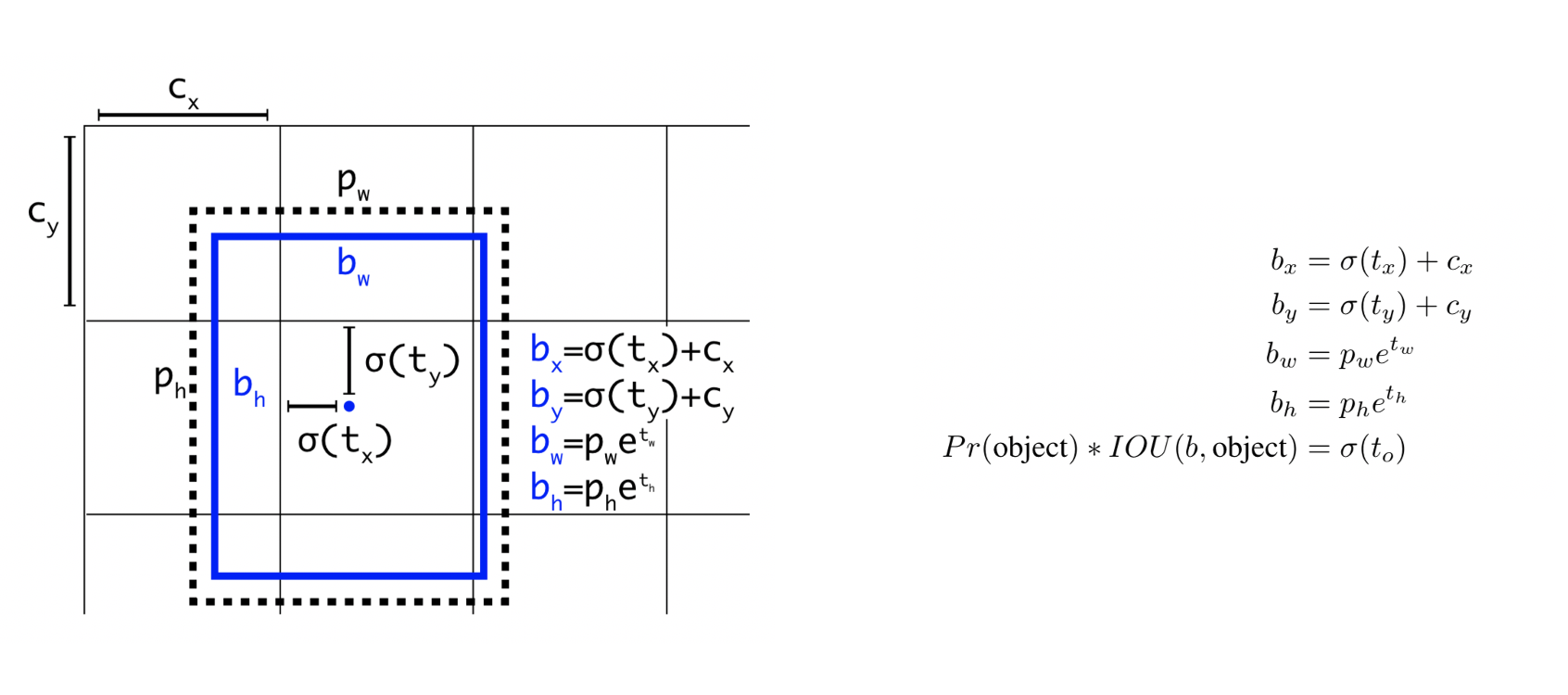
其中 P w P_w Pw和 P h P_h Ph代表anchor box的宽高, c x c_x cx和 c y c_y cy代表grid cell左上角相对于feature map左上角的距离。
讲完了网络结构的改进和anchor box,接下来就是损失函数的改进了:
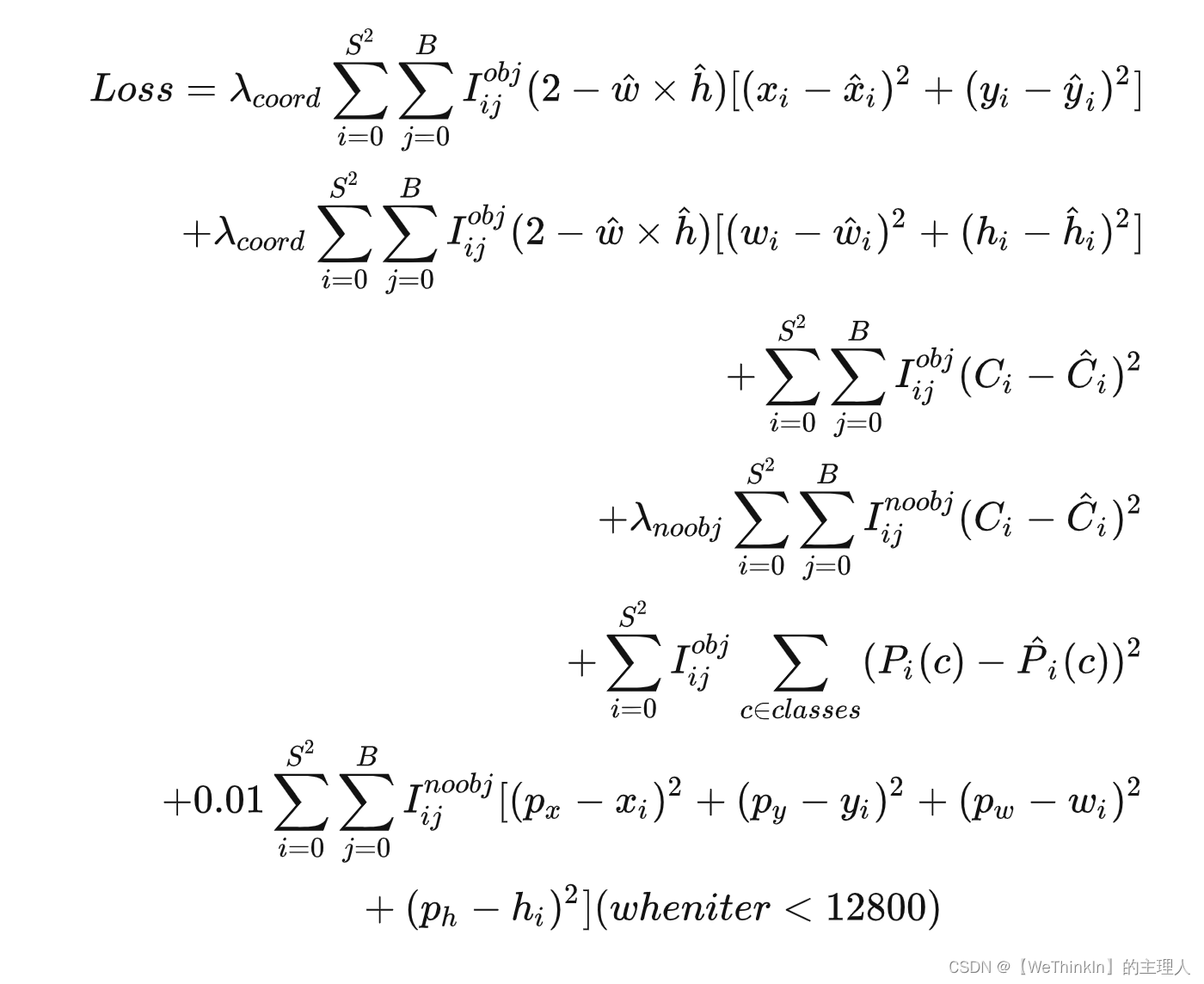
可以看出,在计算检测框的回归损失时,YOLOv2去掉了开根号操作,进行直接计算。但是根据ground truth的大小对权重系数进行修正: ( 2 − w ^ × h ^ ) (2 - \hat{w}\times \hat{h}) (2−w^×h^)(这里 w ^ \hat{w} w^和 h ^ \hat{h} h^都归一化到 [ 0 , 1 ] [0,1] [0,1]),这样对于尺度较小的预测框其权重系数会更大一些,可以放大误差,起到和YOLOv1计算平方根相似的效果。
在训练前期(iter < 12800),YOLOv2还会进行 0.01 ∑ i = 0 S 2 ∑ j = 0 B I i j n o o b j [ ( p x − x i ) 2 + ( p y − y i ) 2 + ( p w − w i ) 2 + ( p h − h i ) 2 ] 0.01 \sum^{S^2}_{i=0}\sum^{B}_{j=0}I^{noobj}_{ij}[(p_x - x_i)^2 + (p_y - y_i)^2 + (p_w - w_i)^2 + (p_h - h_i)^2] 0.01∑i=0S2∑j=0BIijnoobj[(px−xi)2+(py−yi)2+(pw−wi)2+(ph−hi)2] 的计算,表示对anchor boxes和检测框进行坐标回归,促进网络学习到anchor的形状。
【Rocky的延伸思考】
- 业务侧:YOLOv2 Head侧完全可以作为baseline模型的一部分进行业务开展。
- 竞赛侧:YOLOv2 Head侧中的anchor box机制,Dimension Clusters以及Direct location prediction优化方法可以作为竞赛侧的提分策略。
- 研究侧:YOLOv2 Head侧网络架构以及损失函数具备作为baseline的价值,不管是进行拓展研究还是单纯学习思想。
【五】YOLOv3 Head侧解析
YOLOv3Head侧在YOLOv2的基础上引入了多尺度检测逻辑和多标签分类思想,优化了损失函数。
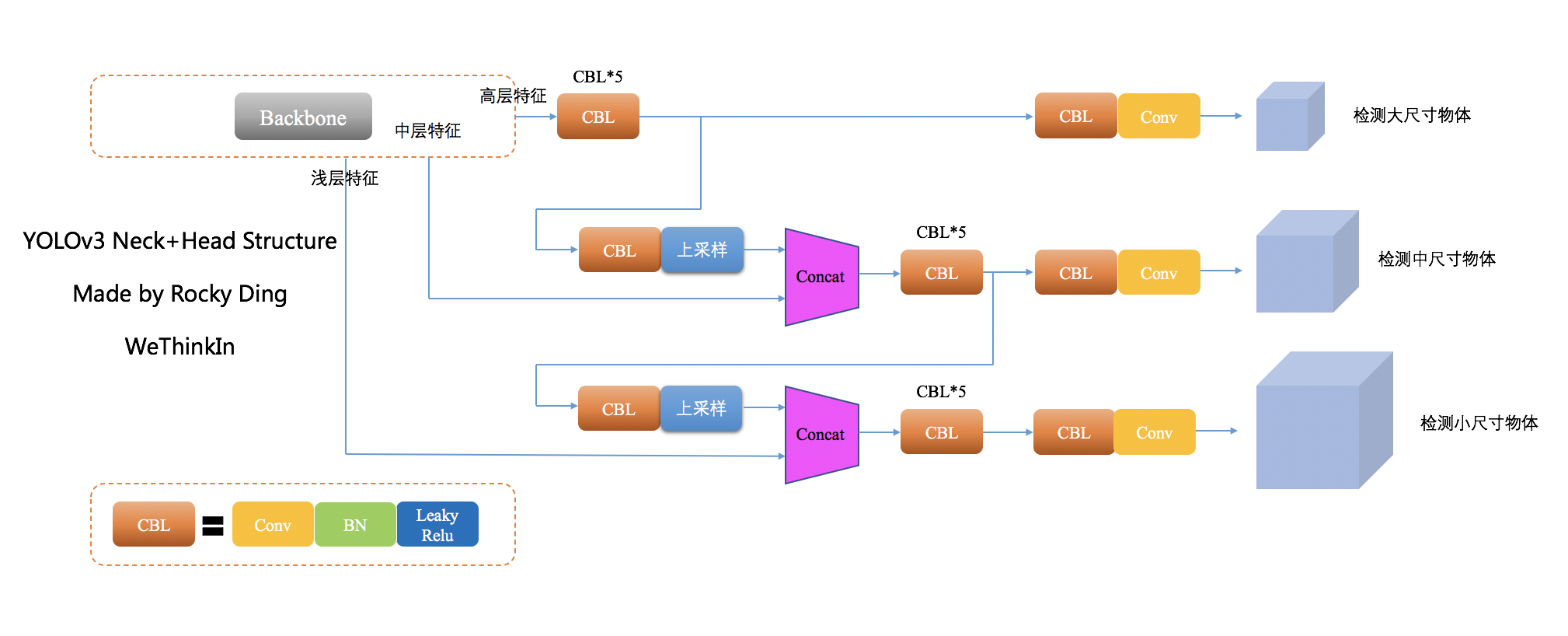
YOLOv3在Neck侧的基础上顺势而为融合了3个尺度,在多个尺度的融合特征图上分别独立做检测。再将Anchor Box由5个增加至9个,每个尺度下分配3个Anchor Box,最终对于小目标的检测效果提升明显。并且多尺度+9anchor box让YOLOv3的整体检测性能达到了一个比较从容的level。
再说多标签分类思想,我大受震撼。首先什么是多标签分类呢?我们先对几种常见的分类逻辑做一个对比:
- 二分类(Two-Class Classification)问题,是最简单的分类问题,比如一个任务中只有猫和狗,每个样本中也只有其中的一类。
- 单标签多分类(Multi-Class Classification)问题,指一个样本(一个图片或者一个检测框)有一个标签,但总共的类别数是大于两类的。目标检测中针对每个检测框的分类是多分类问题。在深度学习中,使用softmax是最常用的解决方案。
- 多标签多分类(Multi-Label Classification)问题,指一个样本(一个图片或者一个检测框)中含有多个物体或者多个label。在深度学习中,使用多个Logistic输出是一种性价比很高的做法。
YOLOv3将YOLOv2的单标签分类改进为多标签分类,Head侧将用于单标签分类的Softmax分类器改成多个独立的用于多标签分类的Logistic分类器,取消了类别之间的互斥,可以使网络更加灵活。YOLOv2使用Softmax分类器,认为一个检测框只属于一个类别,每个检测框分配到概率最大的类别。但实际场景中一个检测框可能含有多个物体或者有重叠的类别标签。Logistic分类器主要用到Sigmoid函数,可以将输入约束在0到1的范围内,当一张图像经过特征提取后的某一检测框类别置信度经过sigmoid函数约束后如果大于设定的阈值,就表示该检测框负责的物体属于该类别。
YOLOv3的损失函数在YOLOv2的基础上进行了改进:
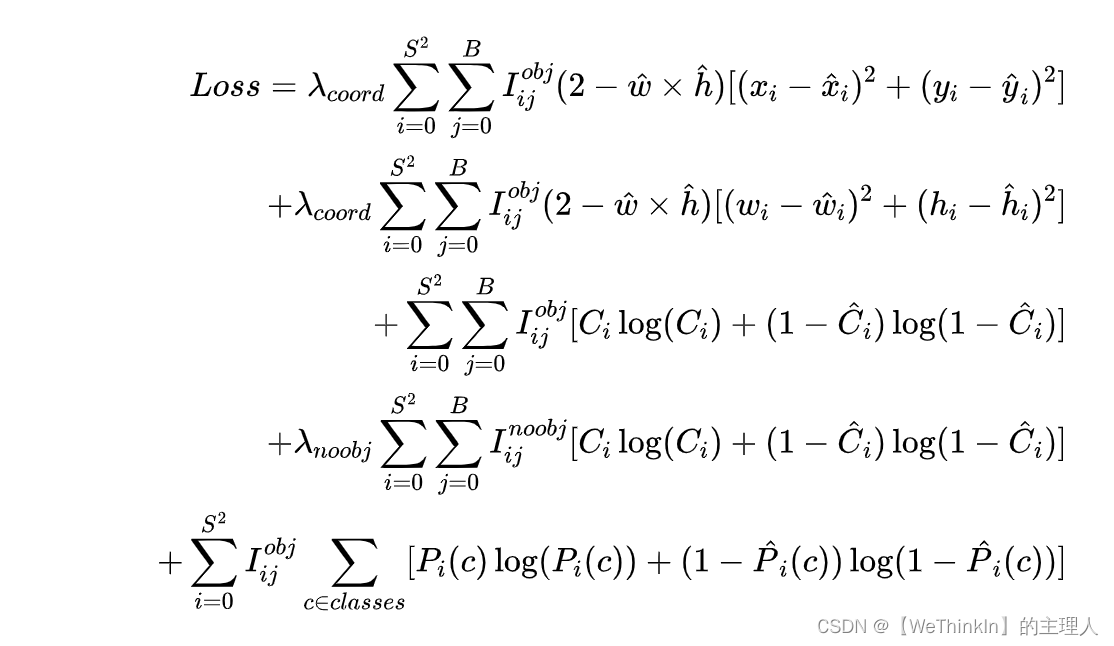
YOLOv3中置信度误差损失和分类误差损失都使用交叉熵来表示。
【Rocky的延伸思考】
- 业务侧:YOLOv3 Head侧在工程中非常稳定,且究竟工程与时间的考验,可以作为业务baseline模型的首选。
- 竞赛侧:YOLOv3 Head侧在竞赛中的地位和业务侧同理。
- 研究侧:YOLOv3 Head侧作为穿越v1和v2的周期优化而来的结构,值得进行学习和研究。
【六】YOLOv4-v7 Head侧解析
由于时间原因未能呈现,希望大家能够谅解~在本系列的下一篇中将完成呈现YOLO全系列的Head侧解析,大家敬请期待!
精致的结尾
Rocky将算法高价值面试知识点即“三年面试五年模拟”之独孤九剑秘籍前六式进行汇总梳理成汇总篇,并制作成pdf版本,大家可在公众号后台 【精华干货】菜单或者回复关键词“三年面试五年模拟” 进行取用。由于“三年面试五年模拟”之独孤九剑秘籍pdf版本是Rocky在工作之余进行整理总结,难免有疏漏与错误之处,欢迎大家对可优化的部分进行指正,Rocky将在后续的优化迭代版本中及时更正。
Rocky也一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于CV算法,算法,开发,IT技术以及工作经验等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请加小助手微信Jarvis8866,拉你进群~)
-
-
相关阅读:
【LeetCode】LeetCode 106.从中序与后序遍历序列构造二叉树
目标检测YOLO实战应用案例100讲-基于改进的YOLOV5算法的垃圾分类模型
git拉代码 使用SSH克隆,配置代理
死锁详细解读
经典sql例子
Editors(Vim)
SpringBoot3快速入门
基于PHP+MySQL仓库管理系统的设计与实现
22下半年软考集成广东卷(中项)真题在线估分
Spring Security 自定义资源服务器实践
- 原文地址:https://blog.csdn.net/Rocky6688/article/details/126336668