-
06.位置匹配 (Python)
第 6 章节 位置匹配
位置匹配: 对文本中特定位置进行匹配.
6.1 边界
位置匹配用于指定应该在文本中什么地方进行匹配操作.
直接来看代码吧!
import re # 测试文本 text = """ The cat scattered his food all over the room. """ # 正则表达式 REGEXP = r'cat' # 编译 pattern = re.compile(REGEXP) # 匹配所有, 返回值是匹配结果的数组 rs = pattern.findall(text) if rs: print(rs) else: print("No match!") # 匹配所有, 返回值是匹配对象的迭代器 ms = pattern.finditer(text) if ms: for m in ms: print(m)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
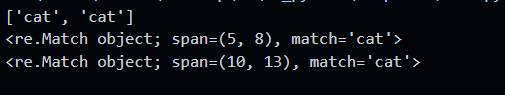
分析: 模式
cat可以匹配文本中所有的 cat, 上面结果截图中的 span 即是匹配到的字符的起始位置和结束位置. 所以它其实匹配到了单词cat和scattered中的cat. 所以为了能够正确的进行匹配, 我们需要用到边界的概念.6.2 单词边界
第一种边界 (也是最常用的) 是由
\b指定的单词边界. 所以,\b是用来匹配一个单词的开头或结尾. 我们来演示一下它的使用方法.注意: b 是英文 boundary (边界) 的首字母.
模式改为了:
\bcat\bimport re # 测试文本 text = """ The cat scattered his food all over the room. """ # 正则表达式 REGEXP = r'\bcat\b' # 编译 pattern = re.compile(REGEXP) # 匹配所有, 返回值是匹配结果的数组 rs = pattern.findall(text) if rs: print(rs) else: print("No match!") # 匹配所有, 返回值是匹配对象的迭代器 ms = pattern.finditer(text) if ms: for m in ms: print(m)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25

分析: 单词
cat的前后都有一个空格, 所以匹配模式\bcat\b(空格是用来分隔单词的字符之一). 该模式并不匹配单词scattered中的字符序列cat, 因为它的前一个字符s, 后一个字符t(这两个字符都不能与\b相匹配).注意:
\b到底匹配什么呢?\b匹配的是字符之间的一个位置: 一边是单词 (能够被\w匹配的字母数字数字字符和下划线), 另一边是其他内容 (能够被\w匹配的字符.).所以, 如果你想要匹配一个完整的单词, 就必须在要匹配的文本的前后都加上
\b. 下面再来看一个例子:模式:
\bcapimport re # 测试文本 text = """ The captain wore his cap and cape proudly as be sat listening to the recap of how his crew saved the men from a capsized vessel. """ # 正则表达式 REGEXP = r'\bcap' # 编译 pattern = re.compile(REGEXP) # 匹配 rs = pattern.findall(text) if rs: print(rs) else: print("No match!")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21

模式
\bcap匹配任何以字符序列cap开头的单词. 这里总共找到了 4 个匹配, 其中有 3 个都不是独立的单词cap.然后将模式改为:
cap\b, 则运行结果如下:

它匹配以字符序列
cap结束的任意单词. 这里总共找到了 2 个匹配, 其中有一个不是独立的单词cap. 如果你想要匹配单词 cap 本身, 那么正确的模式应该是\bcap\b.注意:
\b匹配的是一个位置, 而不是任何实际的字符. 用\bcap\b匹配到的字符串的长度是 3 个字符 (c,a,p), 不是 5 个字符.如果你不想匹配单词边界, 那么可以使用
\B.注意: 同一个元字符的大写形式与它的小写形式在功能上往往刚好相反.
在下面例子中, 我们将使用
\B来查找前后都有多余空格 的连字符:模式:
\B-\Bimport re # 测试文本 text = """ Please enter the nine-digit id as it appears on your color - coded pass-key. """ # 正则表达式 REGEXP = r'\B-\B' # 编译 pattern = re.compile(REGEXP) # 匹配 rs = pattern.findall(text) if rs: print(rs) else: print("No match!") ms = pattern.finditer(text) if ms: for m in ms: print(m)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25

分析:
\B-\B将匹配一个前后都不是单词边界的连字符.nine-digit和pass-key中的连字符都不能与之匹配, 但color - coded中的连字符可以与之匹配 (因为空格和连字符都不属于\w).这个东西感觉理解起来不是那么直观了,
\B匹配的不是单词的边界, 也就是\W的内容了. 我尝试把模式换成了\W-\W, 这样也是可以匹配到的, 但是它匹配的是三个字符了, 前后的空格+中间的连字符了.6.2 字符串边界
单词边界可以对单词位置进行匹配 (单词的开头, 单词的结尾, 整个单词等). PS: 感觉可以用来查找单词的 词根和词缀.
字符串边界用于在字符串首尾进行模式匹配, 字符串边界元字符有两个:
^代表字符串开头,$代表字符串结尾.注意 在之前的学习中, 我们学习了
^用来排除某个字符集合. 如果它不是出现在字符集合的开头, 并且出现在模式的开头, 它将匹配字符串的起始位置.下面是一个例子用来演示字符串边界的用法. 有效的 XML 文档都必须以
标签开头, 另外可能还包含一些其他属性 (比如版本号), 下面的这个简单的测试可以检查一段文本是否位 XML 文档.import re # 测试文本 text = """- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

分析: 该模式似乎管用.
<\?xml匹配,.*匹配随后的任意文本,\?>匹配结尾的?>.但是, 这个测试非常不准确. 例如下面这个例子, 在 xml 的开头添加了一行文字, 这样就是一个非法的 xml 文档了:
import re # 测试文本 text = """ This is bad, real bad!- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23

分析: 这样上面的模式匹配到的是第 2 行文本. 因为 XML 文档的起始标签出现在了第 2 行, 所以这肯定不是有效的 XML 文档 (将其作为 XML 文档来处理会导致各种问题).
这里需要的测试是能够确保 XML 文档的起始标签
出现在字符串最开始处, 而这正是^字符大显身手的地方, 如下所示:import re # 测试文本 text = """- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

这里多匹配了一个
\n, 这是 Python 的字符串语法造成的, 不过它也并不影响 XML 文档的功能.分析:
^匹配一个字符串的开头位置, 所以^\s*匹配字符串开头和随后的零个或多个空白字符 (这解决了标签前允许出现的空格, 制表符, 换行符的问题). 作为一个整体, 模式^\s*<\?xml.*\?>不仅能匹配带有任意属性的 XML 起始标签, 还可以正确处理空白字符.注意 虽然模式
^\s*<\?xml.*\?>解决了上面的问题, 但是这只是以为上面的 XML 文档是不完整的, 因为匹配 中间任意字符使用的是贪婪量词, 所以实际使用时, 需要分清楚情况使用贪婪量词还是它的懒惰型.*?.$的用法也差不多, 它可以用来检查 web 页面结尾的


