-
Linux文件锁内核VFS层源码实现讲解
此文档主要介绍Linux内核FL_FLOCK和FL_POSIX两种类型的文件锁在VFS层的实现。对强制性锁和租约锁**(lease**)不做过多的讨论。基于的内核版本为3.10.0-862.el7.x86_64。VFS层的实现代码主要是在fs/locks.c文件中。
FL_FLOCK和FL_POSIX两个类型文件锁各自检查各自的锁语义,不会互相影响。
当一个锁被删除时,需要唤醒所有因此锁睡眠的进程。解锁就是通过删除锁来实现的。
文件锁设计时,其实主要需要考虑如下几点:
- 文件锁的拥有者怎么区分?
- 文件锁的冲突怎么检查?
- 文件锁的信息是如何在进程间共享的?
- 文件锁是如何跟进程和文件系统关联起来的?
- 文件锁是如何实现进程级别的锁的语义?
- 文件锁的冲突和不冲突时的处理方式是什么?
- 阻塞模式下,什么时候需要唤醒由于获取不到锁而睡眠的进程(waiter)?
- 相同拥有者改变文件锁的类型时,需要做那些操作?
- FL_POSIX类型文件锁,锁区间的合并和拆分如何实现的?
- 文件锁的信息如何展现?
文件锁主要结构体
文件锁主要数据结构为struct file_lock,内容如下:
struct file_lock { struct file_lock *fl_next; /* singly linked list for this inode */ struct hlist_node fl_link; /* node in global lists */ struct list_head fl_block; /* circular list of blocked processes */ fl_owner_t fl_owner; unsigned int fl_flags; unsigned char fl_type; unsigned int fl_pid; int fl_link_cpu; /* what cpu's list is this on? */ struct pid *fl_nspid; wait_queue_head_t fl_wait; struct file *fl_file; loff_t fl_start; loff_t fl_end; struct fasync_struct * fl_fasync; /* for lease break notifications */ /* for lease breaks: */ unsigned long fl_break_time; unsigned long fl_downgrade_time; const struct file_lock_operations *fl_ops; /* Callbacks for filesystems */ const struct lock_manager_operations *fl_lmops; /* Callbacks for lockmanagers */ union { struct nfs_lock_info nfs_fl; struct nfs4_lock_info nfs4_fl; struct { struct list_head link; /* link in AFS vnode's pending_locks list */ int state; /* state of grant or error if -ve */ } afs; } fl_u; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
主要字段描述见下表2-1
类型 字段 字段描述 struct file_lock* fl_next 与索引节点(inode)相关的锁链表中下一个元素 struct hlist_node fl_link 指向活跃或者被阻塞的全局hash链表指针,
hash链file_lock_list是percpu变量struct list_head fl_block 指向阻塞的锁链表指针,双向循环链表 struct files_struct * fl_owner 文件锁拥有者struct files_struct(current->files) unsigned int fl_flags 锁的标识 unsigned char fl_type 锁的类型 unsigned int fl_pid 进程拥有者的pid(current->tgid) int fl_link_cpu hash链表所在的cpu号 struct pid * fl_nspid 暂时没用到 wait_queue_head_t fl_wait 被阻塞进程的等待队列 struct file * fl_file 指向文件对象的指针struct file loff_t fl_start 被锁区间的开始偏移量 loff_t fl_end 被锁区间的结束偏移量 struct fasync_struct * fl_fasync 用于租约锁暂停通知 unsigned long fl_break_time 租约锁的剩余时间 unsigned long fl_downgrade_time 租约锁降级的剩余时间 struct file_lock_operations * fl_ops 指向文件锁操作的指针 struct lock_manager_operations * fl_mops 指向锁管理操作的指针,用于nfsv3的nlm模块 union fl_u 特定文件系统的信息 表2-1 file_lock数据结构字段 -
inode->i_flock 链表保存锁的类型的顺序为: FL_LEASE FL_FLOCK FL_POSIX
-
fl_flags锁的标识定义如下:
#define FL_POSIX 1 #define FL_FLOCK 2 #define FL_DELEG 4 /* NFSv4 delegation */ #define FL_ACCESS 8 /* not trying to lock, just looking */ #define FL_EXISTS 16 /* when unlocking, test for existence */ #define FL_LEASE 32 /* lease held on this file */ #define FL_CLOSE 64 /* unlock on close */ #define FL_SLEEP 128 /* A blocking lock */ #define FL_DOWNGRADE_PENDING 256 /* Lease is being downgraded */ #define FL_UNLOCK_PENDING 512 /* Lease is being broken */ #define FL_OFDLCK 1024 /* lock is "owned" by struct file */ #define FL_LAYOUT 2048 /* outstanding pNFS layout */ #define FL_LM_OPS_EXTEND 65536 /* safe to use lock_manager_operations_extend */ #define FL_CLOSE_POSIX (FL_POSIX | FL_CLOSE)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- fl_type锁的类型定义如下:
/* for posix fcntl() and lockf() */ #ifndef F_RDLCK #define F_RDLCK 0 #define F_WRLCK 1 #define F_UNLCK 2 #endif /* operations for bsd flock(), also used by the kernel implementation */ #define LOCK_SH 1 /* shared lock */ #define LOCK_EX 2 /* exclusive lock */ #define LOCK_NB 4 /* or'd with one of the above to prevent blocking */ #define LOCK_UN 8 /* remove lock */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
FL_FLOCK锁的类型最后都会转成相应的FL_POSIX类型,转换关系如下:
LOCK_SH->F_RDLCK LOCK_EX->F_WRLCK LOCK_UN->F_UNLCK
-
全局**(struct hlist_head)file_lock_list仅用于显示/proc/locks**,每个CPU上保留一个链表,每个链表通过file_lock_lglock(percpu)由自己的自旋锁保护。注意,对链表的更改还要求持有相关的i_lock。
-
(struct hlist_head)blocked_hash[1<<7]记录FL_POSIX类型的所有文件的阻塞锁,用于死锁检查。
-
fl_pid指向的是tgid,即线程组的ID。一个进程里面的多个线程,此字段是相同的。不同进程,包括父子进程,此字段是不相同的。
-
fl_next插入到指定位置,fl_link是头插法,fl_block是尾插法。fl_block是双向循环链表。
文件锁结构体关联
文件系统和文件锁数据结构
一个 file_lock 结构就对应一个"锁",结构中的 fl_file 就指向目标文件的 file 结构(通过open打开,fd映射的),而 fl_start 和 fl_end 则确定了该文件要加锁的一个区间。
指向磁盘上相同文件的所有 file_lock结构都被收集在一个单向的链表中,其头节点由inode->i_flock字段所指向,fl_next 用于指向该链表中的下一个元素。
其文件系统和文件锁相关的结构体简单关联,如下图2-1所示
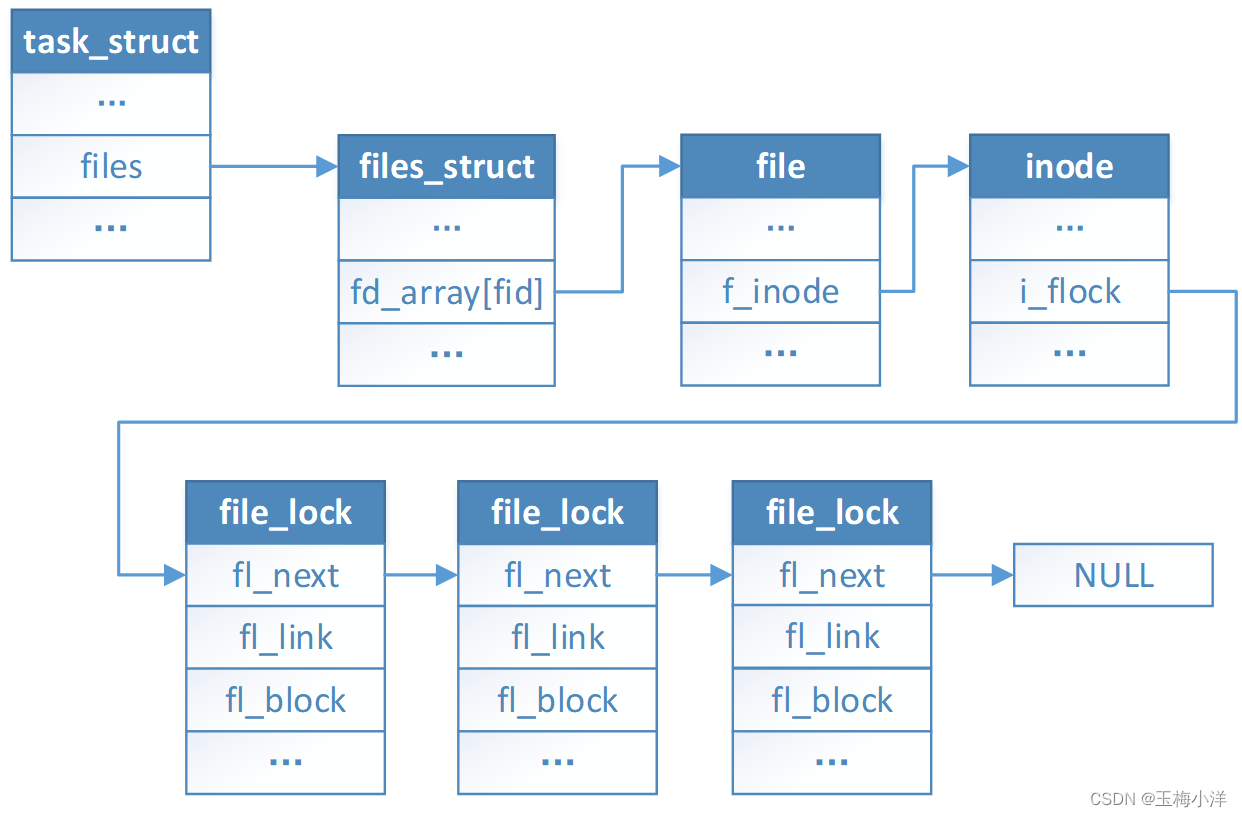
图2-1文件锁相关的数据结构 files记录了进程打开的所有fd,其中每个进程files的地址不一样。每个fd映射到一个file对象,不同的fd可以映射到同一个file对象,例如dup系统调用,不同进程的fd也有可能映射到同一个file对象(大家可以考虑一下这是什么场景?)。然后通过file里面f_inode->i_flock成员,就可以找到这个文件的所有活跃锁和阻塞锁。一个file对象对应一个inode,不同的file对象可以对应相同的inode,例如两次open同一个文件。其对应关系的一个例子如下,
//parentA fd1=open("file1"); file_lock(fd1) if (pid = fork() > 0) { fd2=dup(fd1); fd3=open("file1"); } else { //childB file_lock(fd1); } //processC fd1=open("file1"); file_lock(fd1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
数据结构如图2-2所示
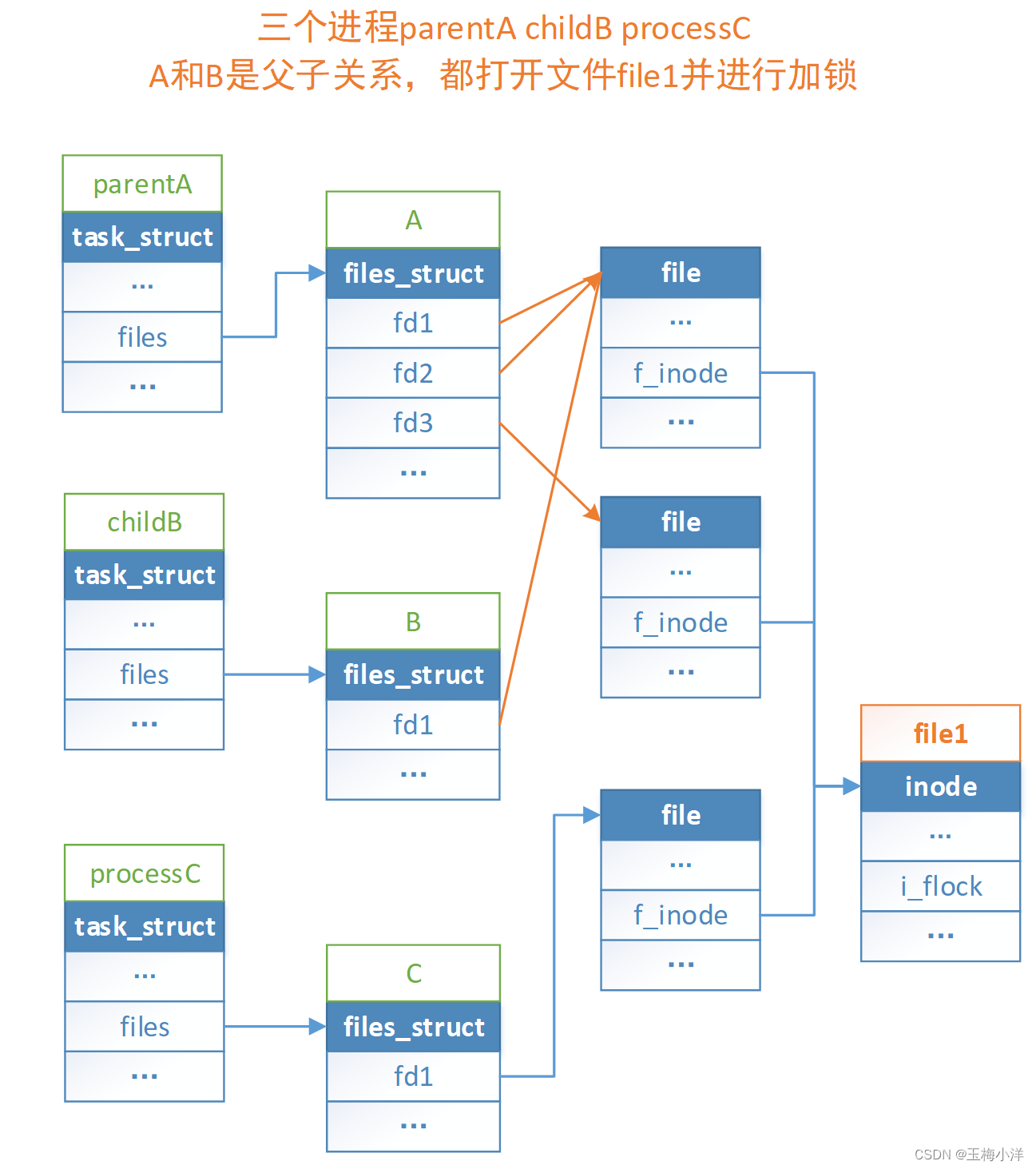
图2-2进程加锁数据结构 活跃锁和阻塞锁数据结构
当进程发出系统调用,来请求对某个文件加排他锁(阻塞方式)时,如果这个文件上已经加上了与其冲突的共享锁,那么排他锁请求不能被立即满足,这个进程必须先要被阻塞。于是这个进程就被放进由阻塞锁file_lock 结构中的 fl_wait字段就指向的等待队列中了。
所有的加锁成功的活跃锁(blocker)串联成一个hash链表,由全局hash链表file_lock_list->first所指向。所有的未加锁成功的FL_POSIX阻塞锁(waiter)也串联成一个hash链表,由全局hash链表blocked_hash[]->first所指向。使用fl_link字段将file_lock插入到上述指定的hash链表中。
由于内核必须跟踪所有与给定的活跃锁(blocker)相关联的阻塞锁(waiter),这就需要blocker通过链表将所有waiter链接在一起。blocker->fl_block字段是链表为首部,waiter->fl_block字段存放了指向链表中相邻元素的指针,waiter->fl_next指向与该锁产生冲突的活跃锁blocker。
FL_FLOCK活跃锁和阻塞锁的相关数据结构如下图2-3所示
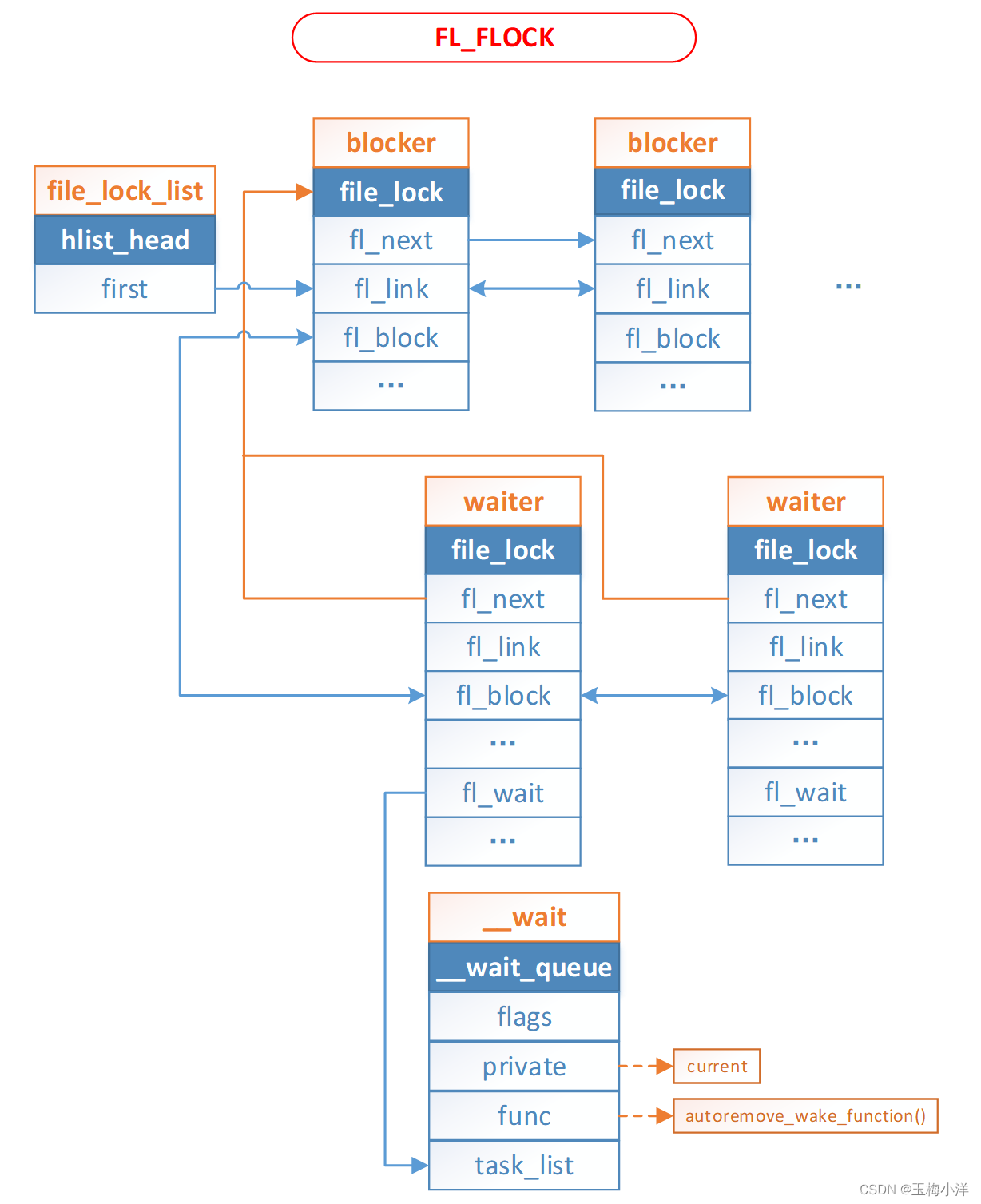
图2-3 FL_FLOCK活跃锁和阻塞锁结构体 阻塞锁waiter的线程会挂起条件为waiter->fl_next != NULL。
FL_POSIX活跃锁和阻塞锁的相关数据构体,如下图2-4所示,只是比FL_FLOCK多一个记录所有阻塞锁的全局hash链表blocked_hash[]
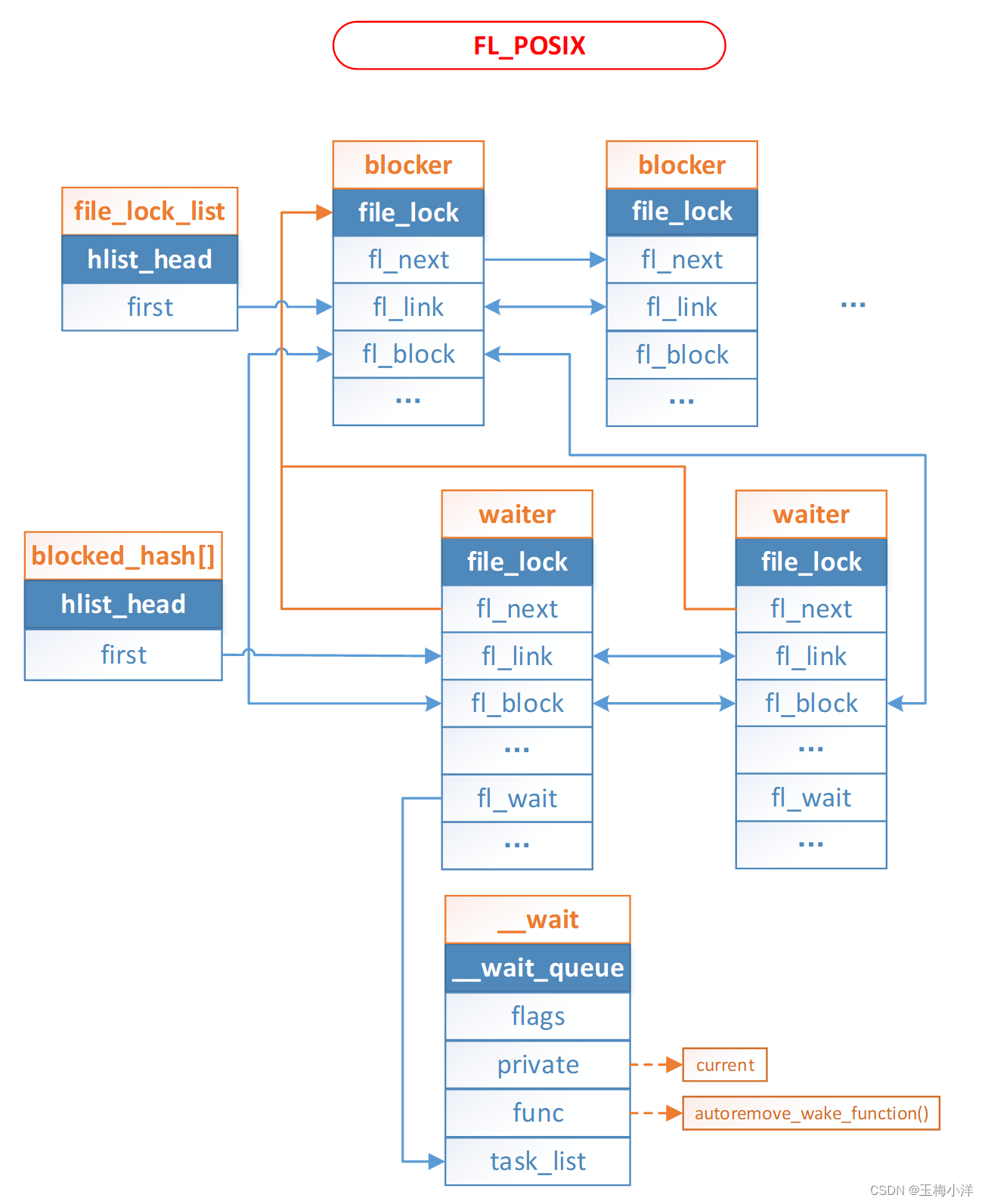
图2-4 FL_POSIX活跃锁和阻塞锁结构体关联图 公共函数介绍
locks_insert_lock()
/* Must be called with the i_lock held! */ static void locks_insert_global_locks(struct file_lock *fl) { lg_local_lock(&file_lock_lglock); fl->fl_link_cpu = smp_processor_id(); hlist_add_head(&fl->fl_link, this_cpu_ptr(&file_lock_list)); lg_local_unlock(&file_lock_lglock); } /* Insert file lock fl into an inode's lock list at the position indicated * by pos. At the same time add the lock to the global file lock list. * * Must be called with the i_lock held! */ static void locks_insert_lock(struct file_lock **pos, struct file_lock *fl) { /* insert into file's list */ fl->fl_next = *pos; *pos = fl; locks_insert_global_locks(fl); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
将新锁加入到pos的位置上,即插入pos的前面,并加入到全局file_lock_list链表中,此函数必须在inode->i_lock锁保护范围内调用。
__locks_insert_block()
/* Insert waiter into blocker's block list. * We use a circular list so that processes can be easily woken up in * the order they blocked. The documentation doesn't require this but * it seems like the reasonable thing to do. * * Must be called with both the i_lock and blocked_lock_lock held. The fl_block * list itself is protected by the file_lock_list, but by ensuring that the * i_lock is also held on insertions we can avoid taking the blocked_lock_lock * in some cases when we see that the fl_block list is empty. */ static void __locks_insert_block(struct file_lock *blocker, struct file_lock *waiter) { BUG_ON(!list_empty(&waiter->fl_block)); waiter->fl_next = blocker; list_add_tail(&waiter->fl_block, &blocker->fl_block); if (IS_POSIX(blocker) && !IS_OFDLCK(blocker)) locks_insert_global_blocked(waiter); } /* Must be called with i_lock held. */ static void locks_insert_block(struct file_lock *blocker, struct file_lock *waiter) { spin_lock(&blocked_lock_lock); __locks_insert_block(blocker, waiter); spin_unlock(&blocked_lock_lock); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
将新阻塞锁waiter->fl_next指向让其阻塞的活跃锁blocker,并加入到blocker的阻塞链表fl_block中。如果是FL_POSIX类型则还需要加入到全局blocked_hash中,用于后边做死锁检查。
locks_wake_up_blocks()
/* * Wake up processes blocked waiting for blocker. * * Must be called with the inode->i_lock held! */ static void locks_wake_up_blocks(struct file_lock *blocker) { /* * Avoid taking global lock if list is empty. This is safe since new * blocked requests are only added to the list under the i_lock, and * the i_lock is always held here. Note that removal from the fl_block * list does not require the i_lock, so we must recheck list_empty() * after acquiring the blocked_lock_lock. */ if (list_empty(&blocker->fl_block)) return; spin_lock(&blocked_lock_lock); while (!list_empty(&blocker->fl_block)) { struct file_lock *waiter; waiter = list_first_entry(&blocker->fl_block, struct file_lock, fl_block); __locks_delete_block(waiter); if (waiter->fl_lmops && waiter->fl_lmops->lm_notify) waiter->fl_lmops->lm_notify(waiter); else wake_up(&waiter->fl_wait); } spin_unlock(&blocked_lock_lock); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
唤醒活跃锁blocker上阻塞的进程,必须在inode->i_lock锁保护范围内调用。如果链表为空,则直接返回,此处没必要加全局锁了,因为阻塞锁的插入操作,也是受到inode->i_lock锁保护。因为摘除链表操作不受inode->i_lock锁保护,此时需要blocked_lock_lock锁保护,并重新检查链表是否为空。
链表不为空,通过__locks_delete_block()对waiter进行摘除链表操作,包括全局bloked_hash链表和活跃锁的fl_block链表,并设置waiter->fl_next = NULL。并根据注册的方法,调用相应的唤醒函数。lm_notify唤醒函数nfs的nlm模块会注册。
注意:此处waiter只是摘链,其申请的内存资源不在这释放的。
locks_delete_lock()
/** * locks_delete_lock - Delete a lock and then free it. * @thisfl_p: pointer that points to the fl_next field of the previous * inode->i_flock list entry * * Unlink a lock from all lists and free the namespace reference, but don't * free it yet. Wake up processes that are blocked waiting for this lock and * notify the FS that the lock has been cleared. * * Must be called with the i_lock held! */ static void locks_unlink_lock(struct file_lock **thisfl_p) { struct file_lock *fl = *thisfl_p; locks_delete_global_locks(fl); *thisfl_p = fl->fl_next; fl->fl_next = NULL; locks_wake_up_blocks(fl); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
将活跃锁从全局链表file_lock_list和indoe->i_flock链表中摘除。并调用**locks_wake_up_blocks()**唤醒其阻塞的进程。需要受到inode->i_lock的保护,并且内存资源不在这释放。
/* * Unlink a lock from all lists and free it. * * Must be called with i_lock held! */ static void locks_delete_lock(struct file_lock **thisfl_p, struct list_head *dispose) { struct file_lock *fl = *thisfl_p; locks_unlink_lock(thisfl_p); if (dispose) list_add(&fl->fl_block, dispose); else locks_free_lock(fl); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
删除活跃锁,先调用locks_unlink_lock(),进行摘除链表和唤醒操作。dispose不为NULL,则将活跃锁,及其阻塞的所有锁,加入到dispose,后面统一释放。如果为NULL,则直接释放。FL_FLOCK和FL_POSIX类型锁dispose不为NULL,FL_LEASE类型锁为NULL。
locks_remove_file()
在open的文件的最后一个colse的时候,调用此函数此函清理相关的锁资源。通过**__fput()函数进行调用。主要时进行解锁请求、或调用locks_delete_lock()**进行锁删除操作。
FL_FLOCK内核实现
FL_FLOCK锁没有用到fl_owner字段,因为内核判断FL_FLOCK类型锁的拥有者,是通过fl_file字段即打开的文件对象区分的。内核锁的冲突代码实现如下:
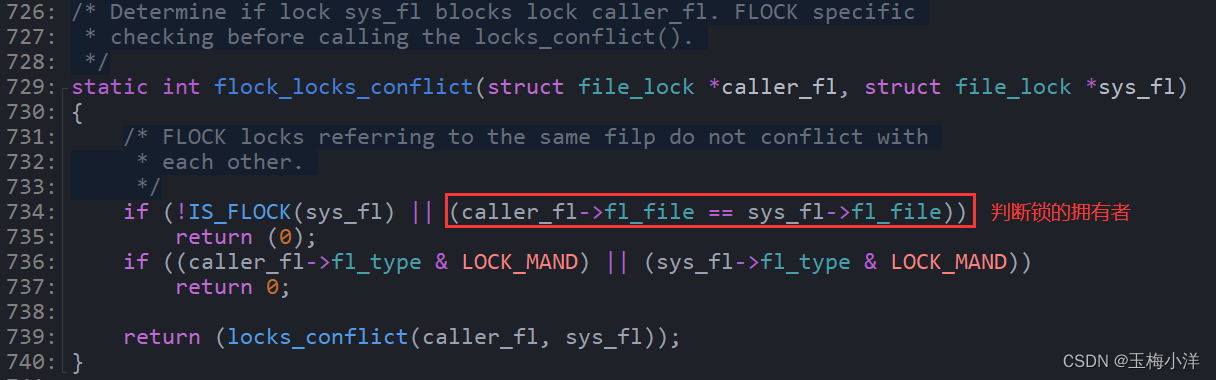
其简单的数据结构如图3-1所示
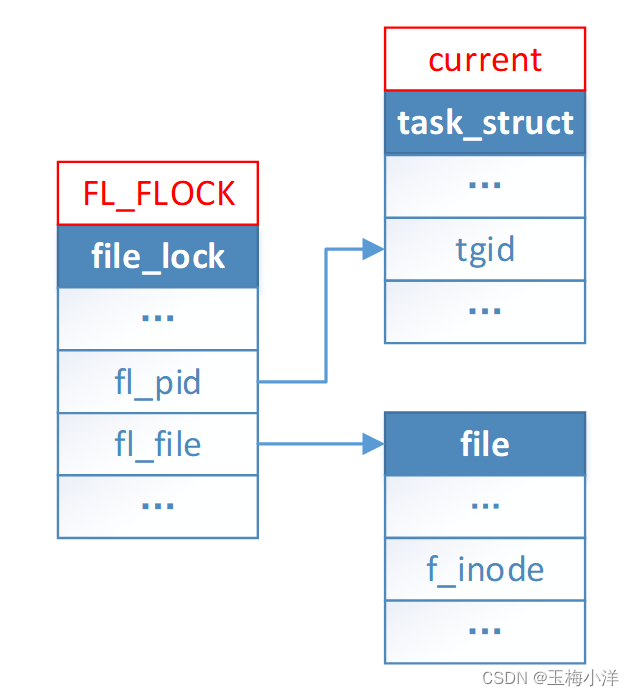
图3-1 FL_FLOCK简单数据结构 FL_FLOCK锁,总是与一个文件对象相关联,因此由一个打开该文件的进程(或共享同一个文件描述符的子进程)来维护。只要fd映射的file对象不一样,就认为是不同的拥有者,而不关心进程是否相同。对于相同的文件,只要调用open,就会生成一个新的file对象。这也就能解释FL_FLOCK如下语义了。
fork产生的子进程可以继承父进程所设置的锁。
通过dup或者fork产生的两个fd,都可以加锁而不会产生死锁,这两个fd都可以操作这把锁(例如通过一个fd加锁,通过另一个fd可以释放锁),但是上锁过程中关闭其中一个fd,并不会释放锁(因为file对象并没有释放),只有关闭所有复制出的fd,锁才会释放。
使用open两次打开同一个文件,得到的两个fd是独立的(因为底层对应两个file对象),通过其中一个加锁,通过另一个无法解锁,并且在前一个解锁前也无法将冲突的锁。
其函数的调用关系如下:
flock()–>sys_flock()–>locks_lock_file_wait()–>locks_lock_inode_wait()–>flock_lock_inode_wait()–>flock_lock_inode()
sys_flock()
位置:kernel.function(“SyS_flock@fs/locks.c:1876”)
函数声明:long sys_flock(unsigned int fd, unsigned int cmd);
fd:要加锁文件的文件描述符
cmd:指定锁的操作类型,包括LOCK_SH共享读锁,LOCK_EX独占写锁,LOCK_UN解锁。LOCK_NB非阻塞模式与LOCK_SH或LOCK_EX一起使用。
用户态进程通过**flock()**系统调用,调用内核的sys_flock()函数,实现FL_FLOCK类型锁的相关操作。
此函数的流程如图3-2所示,

图3-2 sys_flock流程 其中locks_lock_file_wait()最终会调用flock_lock_inode_wait()
其代码实现如下:
/** * sys_flock: - flock() system call. * @fd: the file descriptor to lock. * @cmd: the type of lock to apply. * * Apply a %FL_FLOCK style lock to an open file descriptor. * The @cmd can be one of * * %LOCK_SH -- a shared lock. * * %LOCK_EX -- an exclusive lock. * * %LOCK_UN -- remove an existing lock. * * %LOCK_MAND -- a `mandatory' flock. This exists to emulate Windows Share Modes. * * %LOCK_MAND can be combined with %LOCK_READ or %LOCK_WRITE to allow other * processes read and write access respectively. */ 1876: SYSCALL_DEFINE2(flock, unsigned int, fd, unsigned int, cmd) { struct fd f = fdget(fd); struct file_lock *lock; int can_sleep, unlock; int error; error = -EBADF; if (!f.file) goto out; can_sleep = !(cmd & LOCK_NB); cmd &= ~LOCK_NB; unlock = (cmd == LOCK_UN); if (!unlock && !(cmd & LOCK_MAND) && !(f.file->f_mode & (FMODE_READ|FMODE_WRITE))) goto out_putf; error = flock_make_lock(f.file, &lock, cmd); if (error) goto out_putf; if (can_sleep) lock->fl_flags |= FL_SLEEP; error = security_file_lock(f.file, lock->fl_type); if (error) goto out_free; if (f.file->f_op && f.file->f_op->flock && is_remote_lock(f.file)) error = f.file->f_op->flock(f.file, (can_sleep) ? F_SETLKW : F_SETLK, lock); else error = locks_lock_file_wait(f.file, lock); out_free: locks_free_lock(lock); out_putf: fdput(f); out: return error; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
flock_lock_inode_wait()
位置在kernel.function(“flock_lock_inode_wait@fs/locks.c:1814”),
函数声明为int flock_lock_inode_wait(struct inode *inode, struct file_lock *fl)
其代码实现如下:
/** * flock_lock_inode_wait - Apply a FLOCK-style lock to a file * @inode: inode of the file to apply to * @fl: The lock to be applied * * Apply a FLOCK style lock request to an inode. */ int flock_lock_inode_wait(struct inode *inode, struct file_lock *fl) { int error; might_sleep(); for (;;) { error = flock_lock_inode(inode, fl); if (error != FILE_LOCK_DEFERRED) break; error = wait_event_interruptible(fl->fl_wait, !fl->fl_next); if (!error) continue; locks_delete_block(fl); break; } return error; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
-
调用**flock_lock_inode()**函数进行加锁操作。
-
如果error != FILE_LOCK_DEFERRED则退出循环,直接返回。其中返回值,主要分为:0(锁请求成功,包括加锁和解锁)-EAGAIN(非阻塞模式,锁请求冲突)。
-
阻塞模式,锁请求冲突时返回FILE_LOCK_DEFERRED(用于异步锁定的posix_lock_file()和vfs_lock_file()的特殊返回值)。此时调用wait_event_interruptible(),把当前进程插入到fl->fl_wait等待队列中,并挂起等待唤醒。
-
当进程被唤醒(唤醒前,此阻塞锁blocker的相关资源先摘链,然后统一释放),重新从1开始执行。
flock_lock_inode()
位置:kernel.function(“flock_lock_inode@fs/locks.c:840”),
函数声明:static int flock_lock_inode(struct inode *inode, struct file_lock *request)
这个函数就是FL_FLOCK加锁操作的核心函数。
flock()–>sys_flock()–>locks_lock_file_wait()–>locks_lock_inode_wait()–>flock_lock_inode_wait()->flock_lock_inode()
此函数的流程如图3-3所示
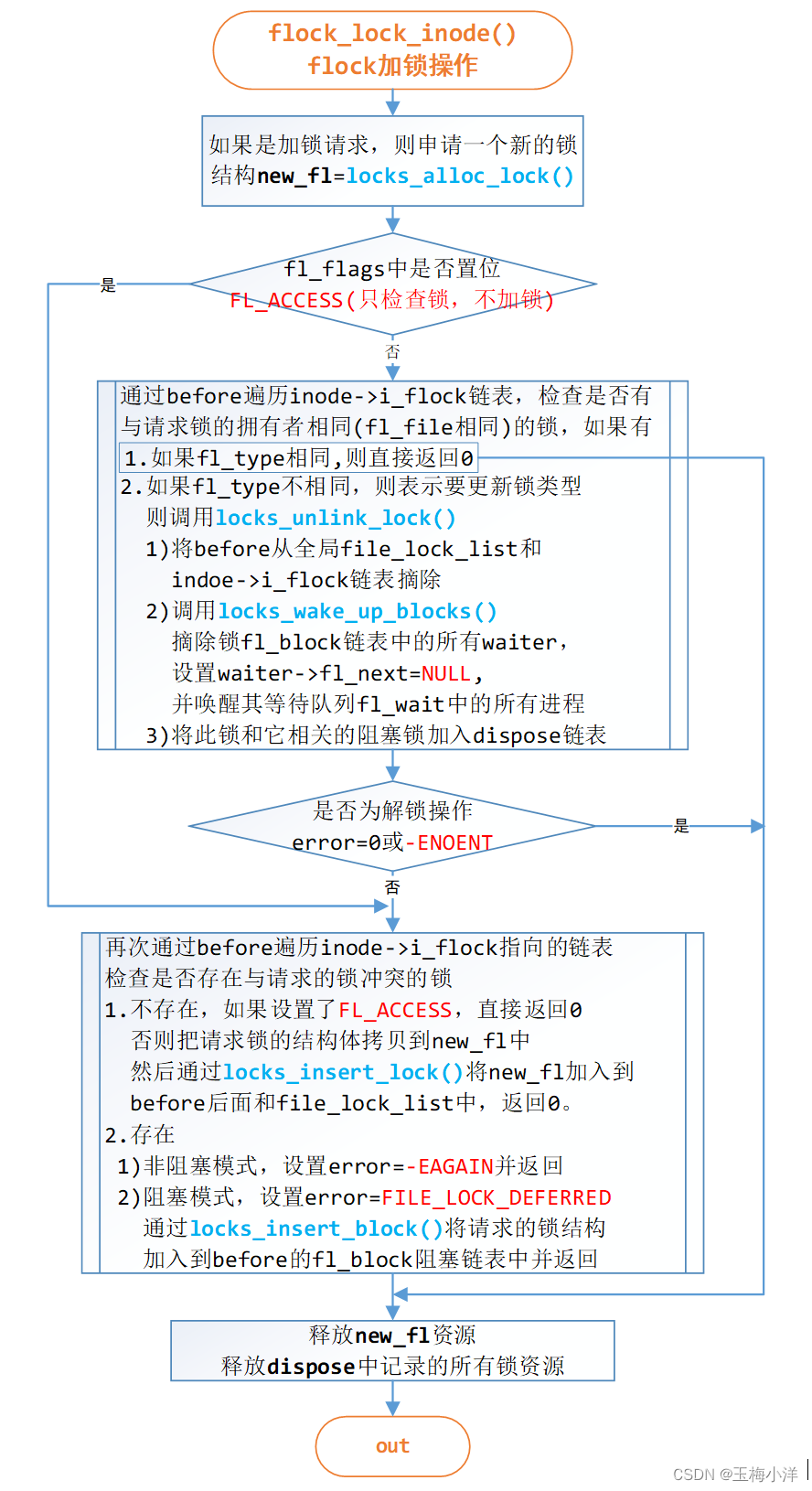
图3-3 flock_lock_inode函数流程 其代码实现如下:
840 static int flock_lock_inode(struct inode *inode, struct file_lock *request) 841 { 842 struct file_lock *new_fl = NULL; 843 struct file_lock **before; 844 int error = 0; 845 int found = 0; 846 LIST_HEAD(dispose); 847 848 if (!(request->fl_flags & FL_ACCESS) && (request->fl_type != F_UNLCK)) { 849 new_fl = locks_alloc_lock(); 850 if (!new_fl) 851 return -ENOMEM; 852 } 853 854 spin_lock(&inode->i_lock); 855 if (request->fl_flags & FL_ACCESS) 856 goto find_conflict; 857 858 for_each_lock(inode, before) { 859 struct file_lock *fl = *before; 860 if (IS_POSIX(fl)) 861 break; 862 if (IS_LEASE(fl)) 863 continue; 864 if (request->fl_file != fl->fl_file) 865 continue; 866 if (request->fl_type == fl->fl_type) 867 goto out; 868 found = 1; 869 locks_delete_lock(before, &dispose); 870 break; 871 } 872 873 if (request->fl_type == F_UNLCK) { 874 if ((request->fl_flags & FL_EXISTS) && !found) 875 error = -ENOENT; 876 goto out; 877 } 878 879 find_conflict: 880 for_each_lock(inode, before) { 881 struct file_lock *fl = *before; 882 if (IS_POSIX(fl)) 883 break; 884 if (IS_LEASE(fl)) 885 continue; 886 if (!flock_locks_conflict(request, fl)) 887 continue; 888 error = -EAGAIN; 889 if (!(request->fl_flags & FL_SLEEP)) 890 goto out; 891 error = FILE_LOCK_DEFERRED; 892 locks_insert_block(fl, request); 893 goto out; 894 } 895 if (request->fl_flags & FL_ACCESS) 896 goto out; 897 locks_copy_lock(new_fl, request); 898 locks_insert_lock(before, new_fl); 899 new_fl = NULL; 900 error = 0; 901 902 out: 903 spin_unlock(&inode->i_lock); 904 if (new_fl) 905 locks_free_lock(new_fl); 906 locks_dispose_list(&dispose); 907 return error; 908 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
new_fl是加锁请求的时候,用于复制加锁请求的file_lock对象。
before在锁遍历和插入时用于定位插入的位置,插入到before前面。
dispose记录所有摘除链表的锁(包括活跃锁和阻塞锁),在i_lock锁释放后,函数返回前统一释放这些锁资源。
FL_ACCESS此标识在加锁请求时,检查是否存在冲突锁。不存在时直接返回,不进行实际加锁,后续步骤再加锁。锁冲突处理方式不变。
FL_EXISTS此标识用来在解锁的时候,判断锁是否存在,不存在返回-ENOENT。
848~852 根据需要,申请新锁的资源new_fl。
854 加inode->i_lock锁,后续文件锁的操作都受此锁保护。
858~871 用来处理解锁和锁的类型变更的请求。在此处会有删除旧锁,唤醒进程操作。遍历到FL_POSIX类型锁就结束遍历。
880~894 检查锁是否存在冲突,存在时进行锁冲突处理。
897~898 将新锁插入到系统中。
FL_POSIX内核实现
FL_POSIX锁,会用到fl_owner字段,其指向的是current->files,这个对象不同的进程(包括父子进程)地址是不一样的,通过copy_process->copy_files创建出来的。FL_POSIX类型锁的拥有者,是通过fl_owner字段区分的。内核锁拥有者检查代码实现如下:

其简单的数据结构如图4-1所示
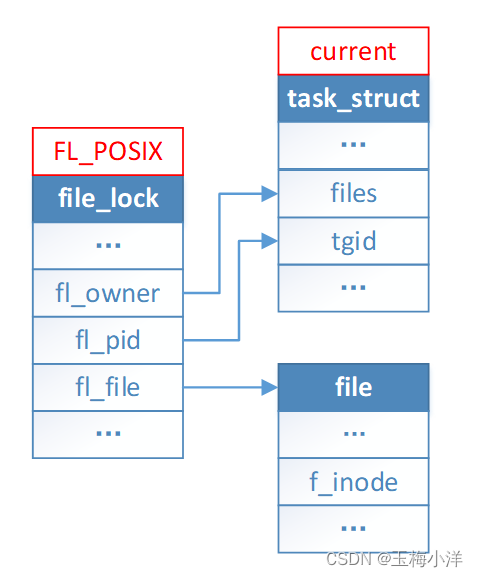
图4-1 FL_POSIX简单数据结构 FL_POSIX锁,总是与一个进程和inode相关。只关心进程是否相同,因为files不同进程是不一样的,不关心其关联的file对象。只要进程不同,就认为是不同的拥有者。这也就能解释FL_POSIX如下语义:
fork产生的子进程不继承父进程所设置的锁。
任何时候关闭一个描述符时,则该进程通过这一描述符引用的文件上的任何一个锁都被释放。
open两次打开同一个文件或dup,得到的两个fd都可以进行加锁请求,只要关闭其中一个fd,这个文件上的所有文件锁就都被释放了。
锁区间排列方式
FL_POSIX锁,活跃锁的区间排列是按照不同owner独自排列。其区间在链表中是按照从左到右,从小到达的方的顺序串联起来的。例如processA和processB加锁区间有交错,但他们的活跃锁也不会出现交错的情况,如图4-2所示
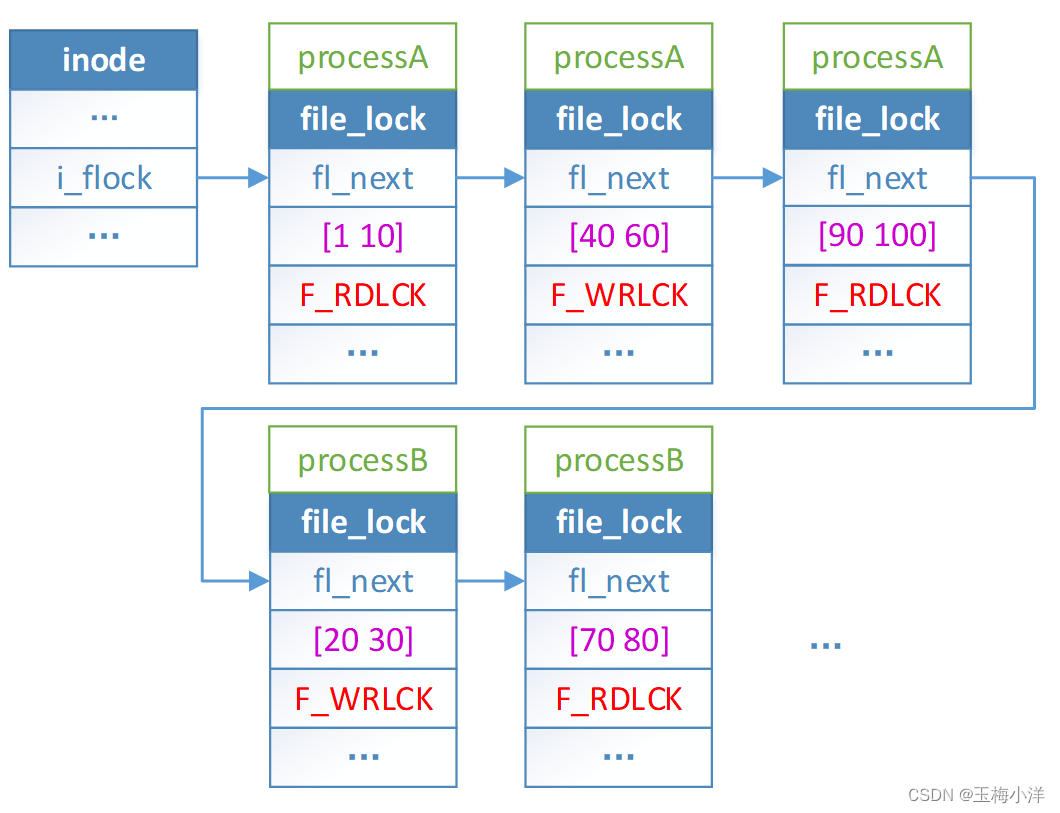
图4-2 FL_POSIX锁区间排列 锁区间合并拆分
同一个owner对文件的不同区间加锁,就有可能出现新锁与旧锁的区间重叠或相邻的情况,此时就需要进行锁区间的合并、拆分、删除旧锁、唤醒进程等操作。这里涉及到新锁和旧锁类型相同和不同两种情况。大家可以先思考一下有多少种情况,以及每种情况需要做些操作。接下来列举各种情况。
- 无重叠或相邻区间,不需要合并或拆分,直接添加新锁即可。

-
新锁和旧锁类型相同,主要是合并操作,也有删除旧锁的操作。
- req_lock->start在一个old_lock1区间内或与其end相邻,req_lock->end没有和其他锁区间相交,此时只需要扩展old_lock1区间即可,涉及合并操作。
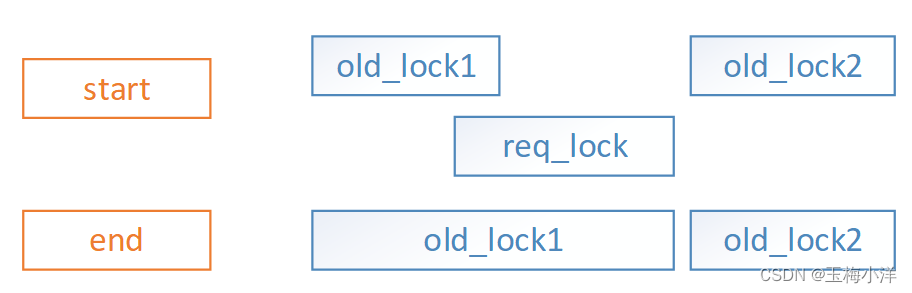
- req_lock->end在一个old_lock2区间内或与其start相邻,req_lock->start没有和其他锁区间相交,此时只需要扩展old_lock2区间即可,涉及合并操作。

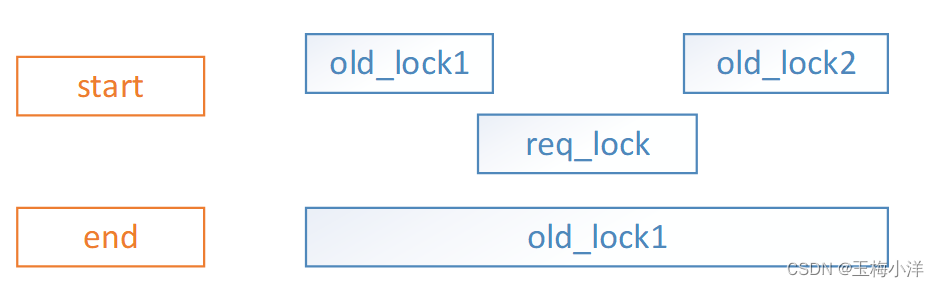
- req_lock->start在old_lock1区间内或与其start相邻,req_lock->end在一个old_lock2区间内或与其start相邻,此时只需要扩展old_lock1区间,删除old_lock2即可,涉及合并和删除旧锁操作。
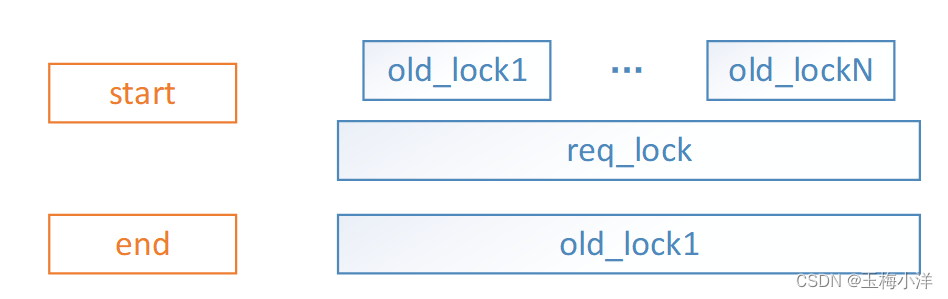
- req_lock区间包含一个或多个old_locks区间,此时只需扩展old_lock1,删除其他old_locks,涉及合并和删除旧锁操作。
- req_lock区间被一个old_lock1区间包含,此时直接返回成功。

-
新锁和旧锁类型不相同
- req_lock->start在left区间内,req_lock->end没有和其他锁区间相交,此时需要添加新锁new_fl,插入到left后面,调整left区间(left->end=req_lock->start-1)并唤醒left上挂起的进程。涉及合并和唤醒操作。

- req_lock->end在right区间内,req_lock->start没有和其他锁区间相交,此时需要添加新锁new_fl,插入到old_lock1后面,调整right区间(right->start=req_lock->end+1),并唤醒right上挂起的进程。涉及合并和唤醒操作。
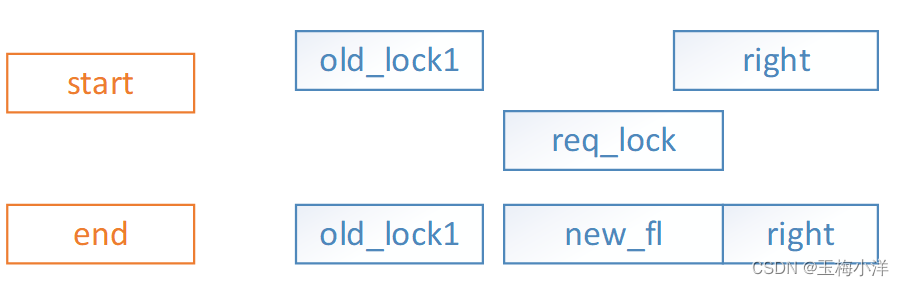
- req_lock->start在left区间内,req_lock->end在right区间内,此时需要添加新锁new_fl,插入到left后面。分别调整right和left区间,并唤醒其上挂起的进程。涉及合并和唤醒操作。
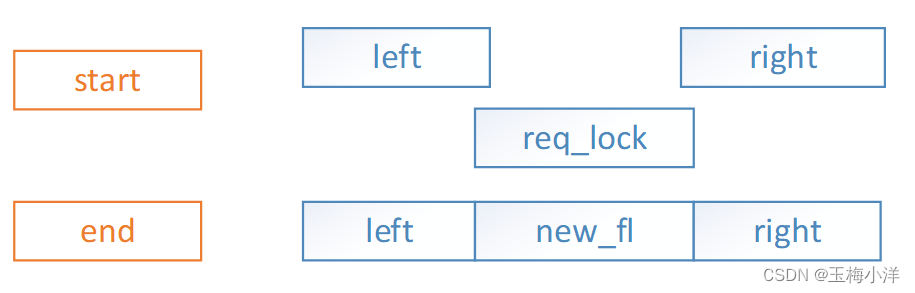
- req_lock区间包含一个或多个old_locks区间,此时需要添加新锁new_fl,替换old_lock1位置上的锁,并删除这些old_locks。涉及删除旧锁操作。
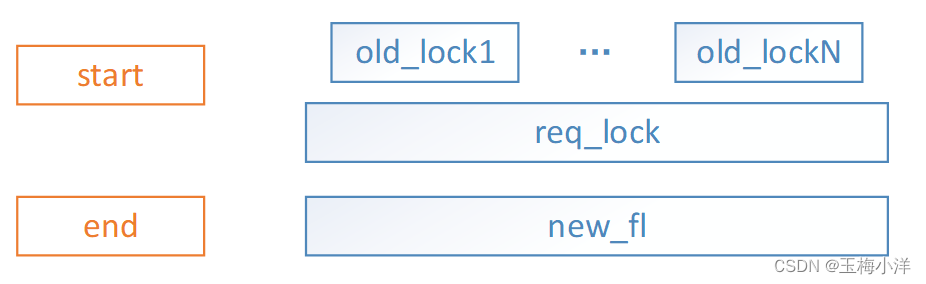
- req_lock区间被一个old_lock(left==right左区间和右区间是一个锁)区间包含。此时需要添加新锁new_fl,插入到right前面, old_lock拆分成两个锁left=new_fl2,right=old_lock,left插入到new_fl前面,分别调整right和left区间,并唤醒其上挂起的进程。

fcntl_setlk()
位置: kernel.function(“fcntl_setlk@fs/locks.c:2124”)
函数声明: int fcntl_setlk(unsigned int fd, struct file *filp, unsigned int cmd, truct flock *flock)
用户态的进程通过fcntl()系统调用,调用内核的sys_fcntl(),sys_fcntl()先通过fd获取对应的文件对象struct file *filp,然后通过do_fcntl()函数,根据用户态传入的操作类型调用fcntl_getlk()(F_GETLK)或fcntl_setlk()(F_SETLK或F_SETLKW)。这里我们先讨论fcntl_setlk()。
函数流程如图5-1所示

图5-1 fcntl_setlk函数流程 其代码实现如下:
2124 int fcntl_setlk(unsigned int fd, struct file *filp, unsigned int cmd, 2125 struct flock *flock) 2126 { 2127 struct file_lock *file_lock = locks_alloc_lock(); 2128 struct inode *inode = locks_inode(filp); 2129 struct file *f; 2130 int error; 2131 2132 if (file_lock == NULL) 2133 return -ENOLCK; 2134 2135 /* Don't allow mandatory locks on files that may be memory mapped 2136 * and shared. 2137 */ 2138 if (mandatory_lock(inode) && mapping_writably_mapped(filp->f_mapping)) { 2139 error = -EAGAIN; 2140 goto out; 2141 } 2142 2143 error = flock_to_posix_lock(filp, file_lock, flock); 2144 if (error) 2145 goto out; 2146 2147 error = check_fmode_for_setlk(file_lock); 2148 if (error) 2149 goto out; 2150 2151 /* 2152 * If the cmd is requesting file-private locks, then set the 2153 * FL_OFDLCK flag and override the owner. 2154 */ 2155 switch (cmd) { ...... 2174 case F_SETLKW: 2175 file_lock->fl_flags |= FL_SLEEP; 2176 } 2177 2178 error = do_lock_file_wait(filp, cmd, file_lock); ...... 2202 out: 2203 locks_free_lock(file_lock); 2204 return error; 2205 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
do_lock_file_wait()
位置: kernel.function(“do_lock_file_wait@fs/locks.c:2081”)
函数声明: static int do_lock_file_wait(struct file *filp, unsigned int cmd, struct file_lock *fl)
其代码实现如下:
static int do_lock_file_wait(struct file *filp, unsigned int cmd, struct file_lock *fl) { int error; error = security_file_lock(filp, fl->fl_type); if (error) return error; for (;;) { error = vfs_lock_file(filp, cmd, fl, NULL); if (error != FILE_LOCK_DEFERRED) break; error = wait_event_interruptible(fl->fl_wait, !fl->fl_next); if (!error) continue; locks_delete_block(fl); break; } return error; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
-
调用vfs_lock_file()函数进行加锁操作。如果定义了文件操作的lock方法,并且是is_remote_lock(filp)则调用它,否则调用**__posix_lock_file()**。
-
如果error != FILE_LOCK_DEFERRED则退出循环,直接返回。返回值主要分为:0(锁请求成功,包括加锁和解锁),-EAGAIN(非阻塞模式,锁请求冲突)。
-
阻塞模式,锁请求冲突时返回FILE_LOCK_DEFERRED。此时调用wait_event_interruptible(),把当前进程插入到fl->fl_wait等待队列中,并挂起等待唤醒。
-
当进程被唤醒(唤醒前,此阻塞锁blocker的相关资源先摘链,然后统一释放),重新从1开始执行。
__posix_lock_file()
位置: kernel.function(“__posix_lock_file@fs/locks.c:910”)
函数声明: static int __posix_lock_file(struct inode *inode, struct file_lock *request, struct file_lock *conflock)
这个函数就是FL_POSIX加锁操作的核心函数。
其函数调用关系如下:
fcntl(F_SETLK)–>sys_fcntl()–>do_fcntl()–>fcntl_setlk()–>do_lock_file_wait()–>vfs_lock_file()–>posix_lock_file()–>__posix_lock_file()
流程图
此函数的流程如图5-2所示

图5-2 __posix_lock_file函数流程 源代码
其代码实现如下:
910 static int __posix_lock_file() 911 { 912 struct file_lock *fl; 913 struct file_lock *new_fl = NULL; 914 struct file_lock *new_fl2 = NULL; 915 struct file_lock *left = NULL; 916 struct file_lock *right = NULL; 917 struct file_lock **before; 918 int error; 919 bool added = false; 920 LIST_HEAD(dispose); 921 922 /* 923 * We may need two file_lock structures for this operation, 924 * so we get them in advance to avoid races. 925 * 926 * In some cases we can be sure, that no new locks will be needed 927 */ 928 if (!(request->fl_flags & FL_ACCESS) && 929 (request->fl_type != F_UNLCK || 930 request->fl_start != 0 || request->fl_end != OFFSET_MAX)) { 931 new_fl = locks_alloc_lock(); 932 new_fl2 = locks_alloc_lock(); 933 } 934 935 spin_lock(&inode->i_lock); 936 /* 937 * New lock request. Walk all POSIX locks and look for conflicts. If 938 * there are any, either return error or put the request on the 939 * blocker's list of waiters and the global blocked_hash. 940 */ 941 if (request->fl_type != F_UNLCK) { 942 for_each_lock(inode, before) { 943 fl = *before; 944 if (!IS_POSIX(fl)) 945 continue; 946 if (!posix_locks_conflict(request, fl)) 947 continue; 948 if (conflock) 949 locks_copy_conflock(conflock, fl); 950 error = -EAGAIN; 951 if (!(request->fl_flags & FL_SLEEP)) 952 goto out; 953 /* 954 * Deadlock detection and insertion into the blocked 955 * locks list must be done while holding the same lock! 956 */ 957 error = -EDEADLK; 958 spin_lock(&blocked_lock_lock); 959 if (likely(!posix_locks_deadlock(request, fl))) { 960 error = FILE_LOCK_DEFERRED; 961 __locks_insert_block(fl, request); 962 } 963 spin_unlock(&blocked_lock_lock); 964 goto out; 965 } 966 } 967 968 /* If we're just looking for a conflict, we're done. */ 969 error = 0; 970 if (request->fl_flags & FL_ACCESS) 971 goto out; 972 973 /* 974 * Find the first old lock with the same owner as the new lock. 975 */ 976 977 before = &inode->i_flock; 978 979 /* First skip locks owned by other processes. */ 980 while ((fl = *before) && (!IS_POSIX(fl) || 981 !posix_same_owner(request, fl))) { 982 before = &fl->fl_next; 983 } 984 985 /* Process locks with this owner. */ 986 while ((fl = *before) && posix_same_owner(request, fl)) { 987 /* Detect adjacent or overlapping regions (if same lock type) 988 */ 989 if (request->fl_type == fl->fl_type) { 990 /* In all comparisons of start vs end, use 991 * "start - 1" rather than "end + 1". If end 992 * is OFFSET_MAX, end + 1 will become negative. 993 */ 994 if (fl->fl_end < request->fl_start - 1) 995 goto next_lock; 996 /* If the next lock in the list has entirely bigger 997 * addresses than the new one, insert the lock here. 998 */ 999 if (fl->fl_start - 1 > request->fl_end) 1000 break; 1001 1002 /* If we come here, the new and old lock are of the 1003 * same type and adjacent or overlapping. Make one 1004 * lock yielding from the lower start address of both 1005 * locks to the higher end address. 1006 */ 1007 if (fl->fl_start > request->fl_start) { 1008 gmb(); 1009 fl->fl_start = request->fl_start; 1010 } else { 1011 gmb(); 1012 request->fl_start = fl->fl_start; 1013 } 1014 if (fl->fl_end < request->fl_end) { 1015 gmb(); 1016 fl->fl_end = request->fl_end; 1017 } else { 1018 gmb(); 1019 request->fl_end = fl->fl_end; 1020 } 1021 if (added) { 1022 locks_delete_lock(before, &dispose); 1023 continue; 1024 } 1025 request = fl; 1026 added = true; 1027 } 1028 else { 1029 /* Processing for different lock types is a bit 1030 * more complex. 1031 */ 1032 if (fl->fl_end < request->fl_start) 1033 goto next_lock; 1034 if (fl->fl_start > request->fl_end) 1035 break; 1036 if (request->fl_type == F_UNLCK) 1037 added = true; 1038 if (fl->fl_start < request->fl_start) 1039 left = fl; 1040 /* If the next lock in the list has a higher end 1041 * address than the new one, insert the new one here. 1042 */ 1043 if (fl->fl_end > request->fl_end) { 1044 right = fl; 1045 break; 1046 } 1047 if (fl->fl_start >= request->fl_start) { 1048 /* The new lock completely replaces an old 1049 * one (This may happen several times). 1050 */ 1051 if (added) { 1052 locks_delete_lock(before, &dispose); 1053 continue; 1054 } 1055 /* 1056 * Replace the old lock with new_fl, and 1057 * remove the old one. It's safe to do the 1058 * insert here since we know that we won't be 1059 * using new_fl later, and that the lock is 1060 * just replacing an existing lock. 1061 */ 1062 error = -ENOLCK; 1063 if (!new_fl) 1064 goto out; 1065 locks_copy_lock(new_fl, request); 1066 request = new_fl; 1067 new_fl = NULL; 1068 locks_delete_lock(before, &dispose); 1069 locks_insert_lock(before, request); 1070 added = true; 1071 } 1072 } 1073 /* Go on to next lock. 1074 */ 1075 next_lock: 1076 before = &fl->fl_next; 1077 } 1078 1079 /* 1080 * The above code only modifies existing locks in case of merging or 1081 * replacing. If new lock(s) need to be inserted all modifications are 1082 * done below this, so it's safe yet to bail out. 1083 */ 1084 error = -ENOLCK; /* "no luck" */ 1085 if (right && left == right && !new_fl2) 1086 goto out; 1087 1088 error = 0; 1089 if (!added) { 1090 if (request->fl_type == F_UNLCK) { 1091 if (request->fl_flags & FL_EXISTS) 1092 error = -ENOENT; 1093 goto out; 1094 } 1095 1096 if (!new_fl) { 1097 error = -ENOLCK; 1098 goto out; 1099 } 1100 locks_copy_lock(new_fl, request); 1101 locks_insert_lock(before, new_fl); 1102 new_fl = NULL; 1103 } 1104 if (right) { 1105 if (left == right) { 1106 /* The new lock breaks the old one in two pieces, 1107 * so we have to use the second new lock. 1108 */ 1109 left = new_fl2; 1110 new_fl2 = NULL; 1111 locks_copy_lock(left, right); 1112 locks_insert_lock(before, left); 1113 } 1114 right->fl_start = request->fl_end + 1; 1115 locks_wake_up_blocks(right); 1116 } 1117 if (left) { 1118 left->fl_end = request->fl_start - 1; 1119 locks_wake_up_blocks(left); 1120 } 1121 out: 1122 spin_unlock(&inode->i_lock); 1123 /* 1124 * Free any unused locks. 1125 */ 1126 if (new_fl) 1127 locks_free_lock(new_fl); 1128 if (new_fl2) 1129 locks_free_lock(new_fl2); 1130 locks_dispose_list(&dispose); 1131 return error; 1132 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
代码解读
new_fl和new_fl2是加锁或解锁请求的时候,加锁区间合并或拆分时会用保存新锁,new_fl2在拆分时会用到。
left和right由于定位与请求锁owner相同但类型不同的活跃锁在链表中的位置。
before在锁遍历和插入时用于定位插入的位置,插入到before前面。
added 用来标识新锁是否已经添加或解锁。
dispose记录所有从链表摘除的锁(包括活跃锁和阻塞锁),在i_lock锁释放后,函数返回前统一释放这些锁资源。
982~933 根据情况申请新锁资源。
935 加inode->i_lock锁,后续文件锁的操作都受此锁保护。
941~966 检查锁冲突,存在返回相应错误码。阻塞模式还会检查是否存在死锁的情况,如果存在,此时加锁的进程会收到-EDEADLK错误码,无死锁则将请求的新锁加入到blocker->fl_block和全局blocked_hash的链表中。
977~983 重新遍历,定位到第一个与请求锁owner相同的活跃锁位置。
986~1077 接下来就是重头戏了,这部分是处理锁区间的合并和拆分。接下来讲解这部分的处理流程,分为锁的类型相同和不同两种情况,其中fl表示遍历到的每个活跃锁,request表示请求的锁。
锁的类型相同(989~1026):
遍历方法:
if (fl->fl_end < request->fl_start - 1) goto next_lock;// 略过当前活跃锁,request区间左边不重叠或相邻 if (fl->fl_start - 1 > request->fl_end) break; //结束循环遍历,新锁插入到此活跃锁前面- 1
- 2
- 3
- 4
这里不是end+1,代码注释已经描述了,防止end+1变为负数,所以start-1。但是为什么start要减1?因为相同类型锁,区间相邻(即end=start-1,start+1=end)也是需要进行合并操作的。
锁区间有重叠如何判断?如果正向不好理解,其实可以反向思考,即锁的区间不重叠如何判断?(fl->end < request->start || fl->start > request->end)其反向为
(fl->end >= request->start && request->start <= fl->end)
上面的判断方式其实就是通过判断锁区间不重叠的方法,掠过活跃锁和结束遍历的。接下来就是有区间重叠的部分了,即合并操作。
合并操作:
第一次,request新的区间start取两者最小,end取两者最大,request替换fl的位置,added=true。后面如果还有区间重叠的fl,就直接调用**locks_delete_lock()**进行删除。
下面举一个例子加深一下理解。
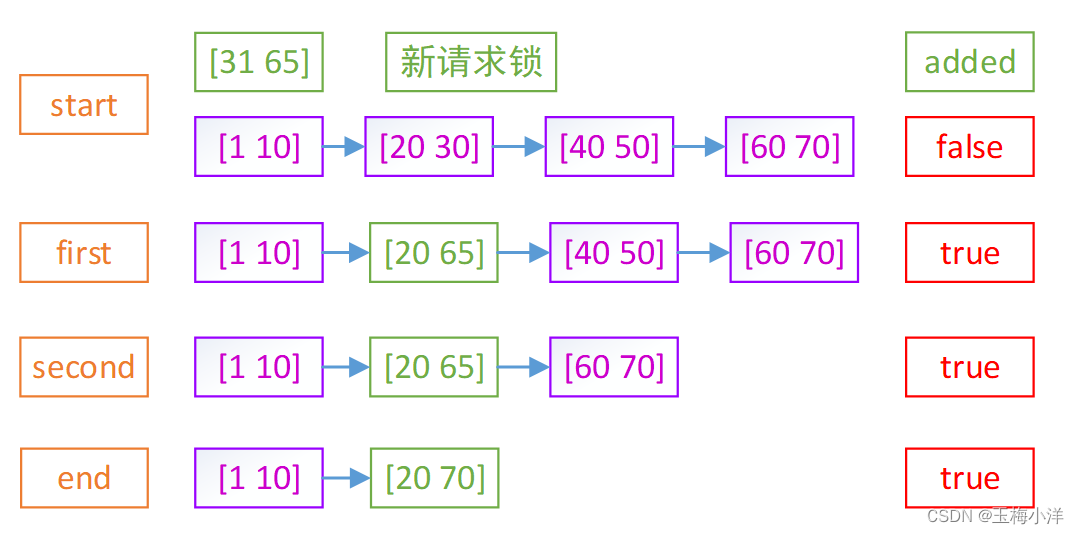
注意:fisrt这步,[20 65]是直接替换[20 30],并没有删除[20 30]这个活跃锁。
锁的类型不同(1028~1072):
遍历方法:
if (fl->fl_end < request->fl_start) goto next_lock; if (fl->fl_start > request->fl_end) break; if (request->fl_type == F_UNLCK) added = true;- 1
- 2
- 3
- 4
- 5
- 6
此处跟锁的类型相同处理相同,只是start不减1了。接下来就是处理区间重叠的情况了,如果是解锁请求设置added=true,因为解锁区间不需要添加,直接删除即可。
if (fl->fl_start < request->fl_start) left = fl; if (fl->fl_end > request->fl_end) { right = fl; break; }- 1
- 2
- 3
- 4
- 5
- 6
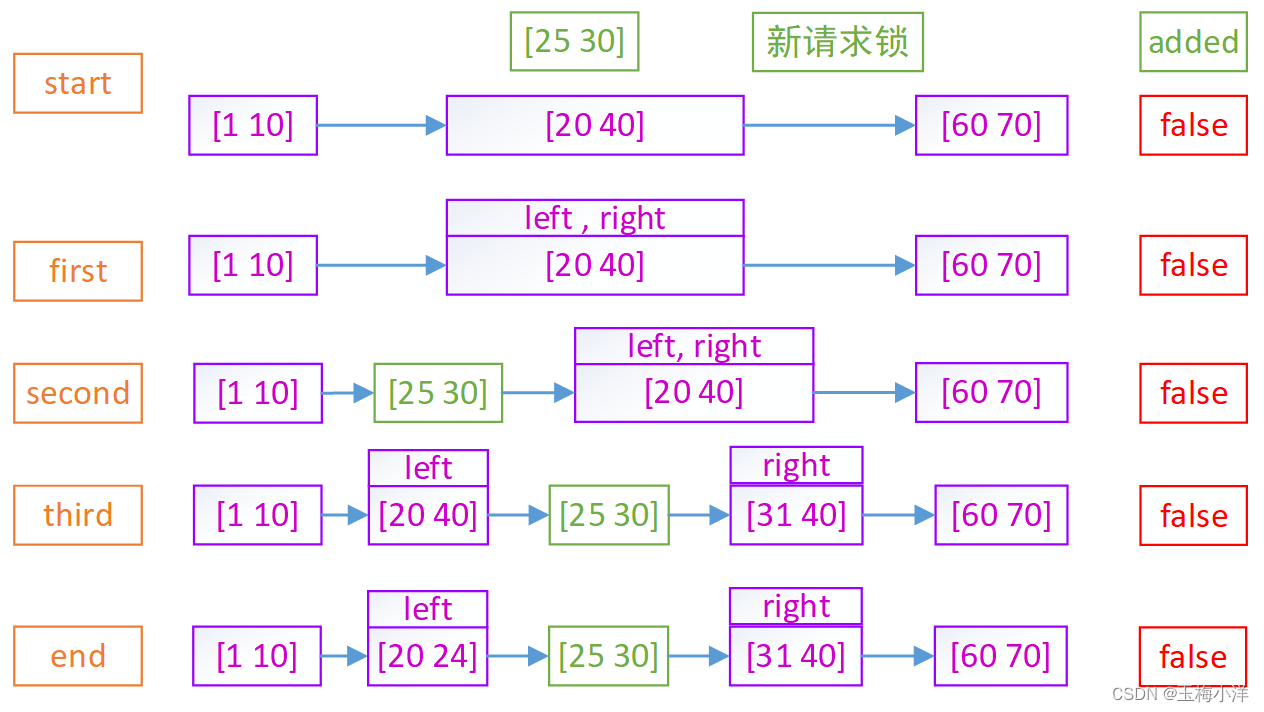
此时需要找到重叠区间最左边left和最右边right的活跃锁位置。找到right也就可以结束遍历了。此时判断是不带等号的,因为相等的话,直接用request->start替换left->start或request->end替换right->end即可。如果left==right需要进行拆分操作。
合并操作:
从left后边第一个活跃锁开始。第一次先删除fl,然后在此位置插入request,added=true。后面如果还有区间重叠的fl,就直接调用**locks_delete_lock()**进行删除,直到遇到right停止操作。
1088~1119 如果added=false,则进行新锁添加。找到了right,如果left==right,需要将旧锁拆分成两个,此时用到new_fl2, left=new_fl2,复制right并插入到request前面,调整right区间,并唤醒其上挂起的进程。最后调整left区间,并唤醒其上挂起的进程。
下面举两个例子加深一下理解。
- left != right
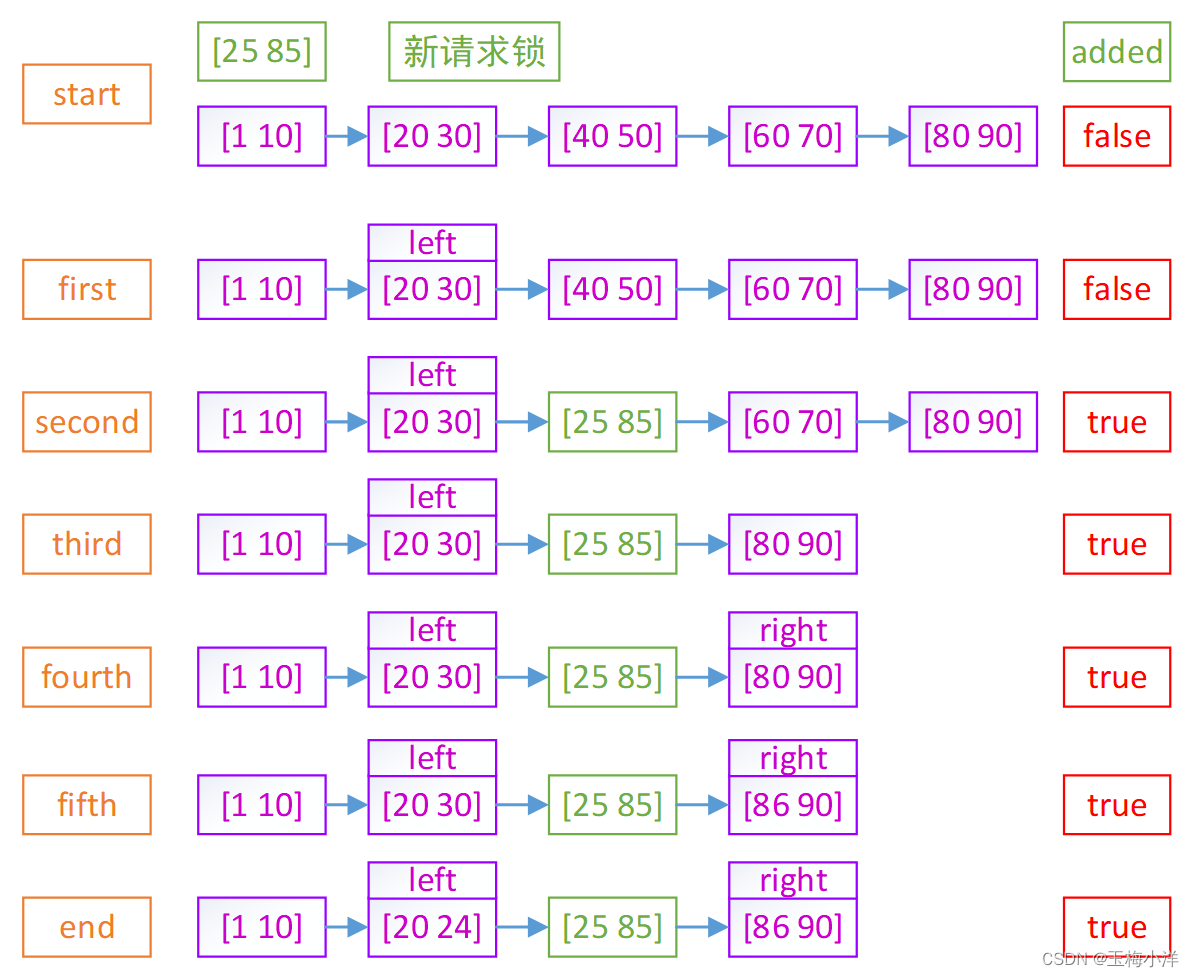
注意:second这步,[25 85]不是直接替换[40 50],而是先删除[40 50]这个活跃锁,然后再将[25 85]插入到此位置。
- left == right
posix_locks_deadlock()
内核对FL_POSIX阻塞模式加锁时,有死锁检查机制。其代码是实现如下:
/* Must be called with the blocked_lock_lock held! */ static int posix_locks_deadlock(struct file_lock *caller_fl, struct file_lock *block_fl) { int i = 0; /* * This deadlock detector can't reasonably detect deadlocks with * FL_OFDLCK locks, since they aren't owned by a process, per-se. */ if (IS_OFDLCK(caller_fl)) return 0; while ((block_fl = what_owner_is_waiting_for(block_fl))) { if (i++ > MAX_DEADLK_ITERATIONS) return 0; if (posix_same_owner(caller_fl, block_fl)) return 1; } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
caller_fl为请求的锁,其拥有者记为ownerA。block_fl为检查到的冲突的活跃锁,其拥有者记为ownerB。
检查死锁的处理步骤如下:
-
通过**what_owner_is_waiting_for()**遍历全局blocked_hash,查找ownerB是否也存在阻塞的锁,如果存在阻塞的锁waiterB1,则获取waiterB1->fl_next指向的活跃锁blockerC,其拥有者记为ownerC,如果不存在则退出循环,返回0。
-
如果ownerC==ownerA,则证明存在死锁,返回1。否则以blockerC开始下一轮循环,最多遍历10次。10次已经很多,如果超过了10次,还是有可能会产生死锁,这是则需要用户自己去排查了。
同一个文件的不同区间加锁或不同文件加锁,都有可能产生死锁。
接下来以同一文件三个进程导致的死锁的例子,加深一下理解:
- processA、B、C分别对文件file1区间[1 20] [30 50] [60 80]加锁成功。活跃锁的结构分别为blockerA,blockerB和blockerC。
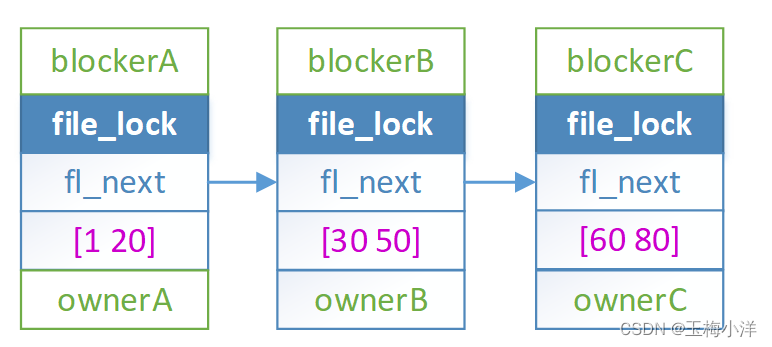
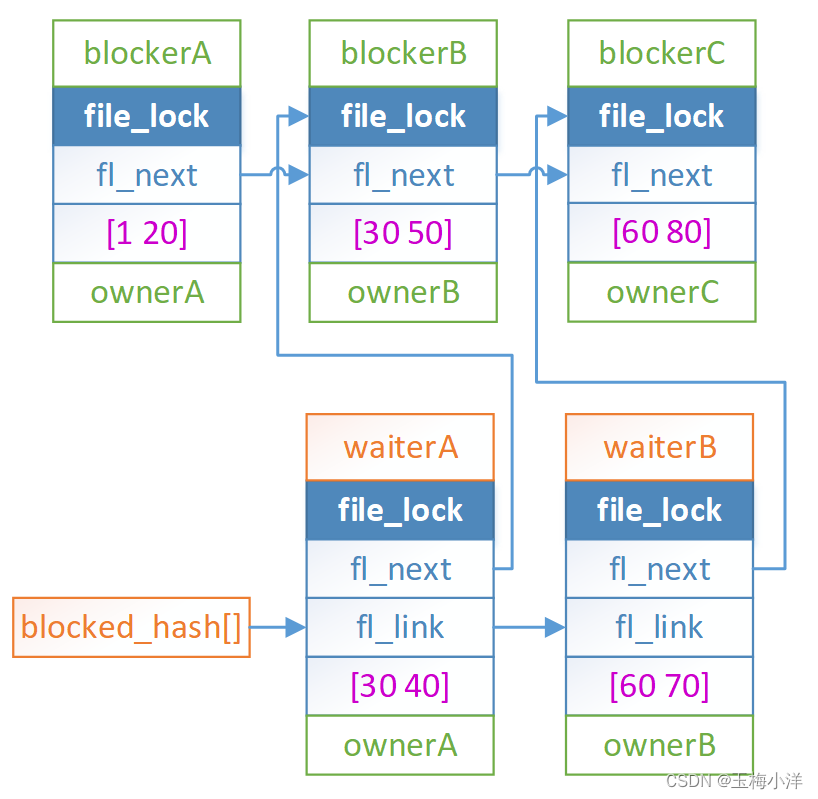
- processA、B分别对文件file1区间[30 40] [60 70]加锁阻塞。阻塞锁的结构分别为wiaterA和waiterB。
-
processC对文件file1区间[10 20] 进行加锁请求
-
检查到与活跃锁blockerA冲突,然后根据blockerA的ownerA,通过blocked_hash查找到其有一个阻塞锁watierA->fl_next=blockerB,在等待blockerB释放锁。blockerB的ownerB!=ownerC,继续通过blockerB遍历。
-
根据blockerB的ownerB,通过blocked_hash查找到其有一个阻塞锁watierB->fl_next=blockerC,在等待blockerC释放锁,blockerC的拥有者owernC就是processC,此时上报processC出现死锁了。
-
fcntl_getlk()
位置: kernel.function(“fcntl_getlk@fs/locks.c:1998”)
函数声明: int fcntl_getlk(struct file *filp, unsigned int cmd, struct flock *flock)
此函数就是内核态检查是否存在于请求的FL_POSIX类型锁有冲突的活跃锁,如果存在则将存在的此活跃锁信息上报给客户端,否者只将锁类型改为F_UNLCKf返回给客户端。
函数调用关系如下:
fcntl(F_GETLK)–>sys_fcntl()–>do_fcntl ()–>fcntl_getlk()–>vfs_test_lock()–>posix_test_lock()
函数流程如图5-3所示
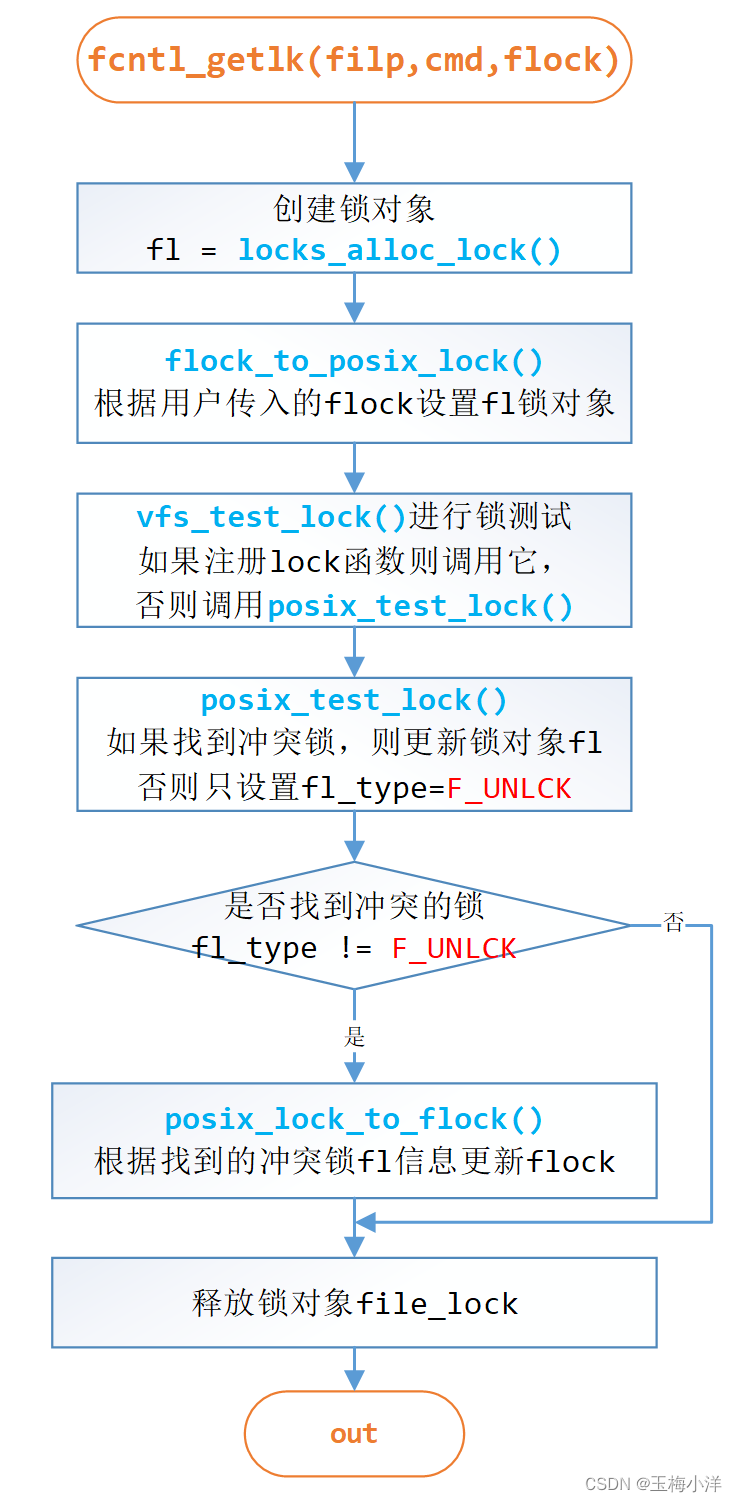
图5-3 fcntl_getlk函数流程 其代码如下:
/* Report the first existing lock that would conflict with l. * This implements the F_GETLK command of fcntl(). */ int fcntl_getlk(struct file *filp, unsigned int cmd, struct flock *flock) { struct file_lock *fl; int error; fl = locks_alloc_lock(); if (fl == NULL) return -ENOMEM; error = -EINVAL; if (flock->l_type != F_RDLCK && flock->l_type != F_WRLCK) goto out; error = flock_to_posix_lock(filp, fl, flock); if (error) goto out; if (cmd == F_OFD_GETLK) { error = -EINVAL; if (flock->l_pid != 0) goto out; cmd = F_GETLK; fl->fl_flags |= FL_OFDLCK; fl->fl_owner = (fl_owner_t)filp; } error = vfs_test_lock(filp, fl); if (error) goto out; flock->l_type = fl->fl_type; if (fl->fl_type != F_UNLCK) { error = posix_lock_to_flock(flock, fl); if (error) goto out; } out: locks_free_lock(fl); return error; } /** * vfs_test_lock - test file byte range lock * @filp: The file to test lock for * @fl: The lock to test; also used to hold result * * Returns -ERRNO on failure. Indicates presence of conflicting lock by * setting conf->fl_type to something other than F_UNLCK. */ int vfs_test_lock(struct file *filp, struct file_lock *fl) { if (filp->f_op && filp->f_op->lock && is_remote_lock(filp)) return filp->f_op->lock(filp, F_GETLK, fl); posix_test_lock(filp, fl); return 0; } void posix_test_lock(struct file *filp, struct file_lock *fl) { struct file_lock *cfl; struct inode *inode = locks_inode(filp); spin_lock(&inode->i_lock); for (cfl = inode->i_flock; cfl; cfl = cfl->fl_next) { if (!IS_POSIX(cfl)) continue; if (posix_locks_conflict(fl, cfl)) break; } if (cfl) locks_copy_conflock(fl, cfl); else fl->fl_type = F_UNLCK; spin_unlock(&inode->i_lock); return; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
locks_remove_posix()
位置: kernel.function(“locks_remove_posix@fs/locks.c:2343”)
函数声明: int locks_remove_posix(struct file *filp, fl_owner_t owner)
此函数会删除指定owner的filp对应文件的所有FL_POSIX类型锁,在fd从files->fd_array[]中删除时会调用,即所谓的close操作。
其主要调用关系如下:
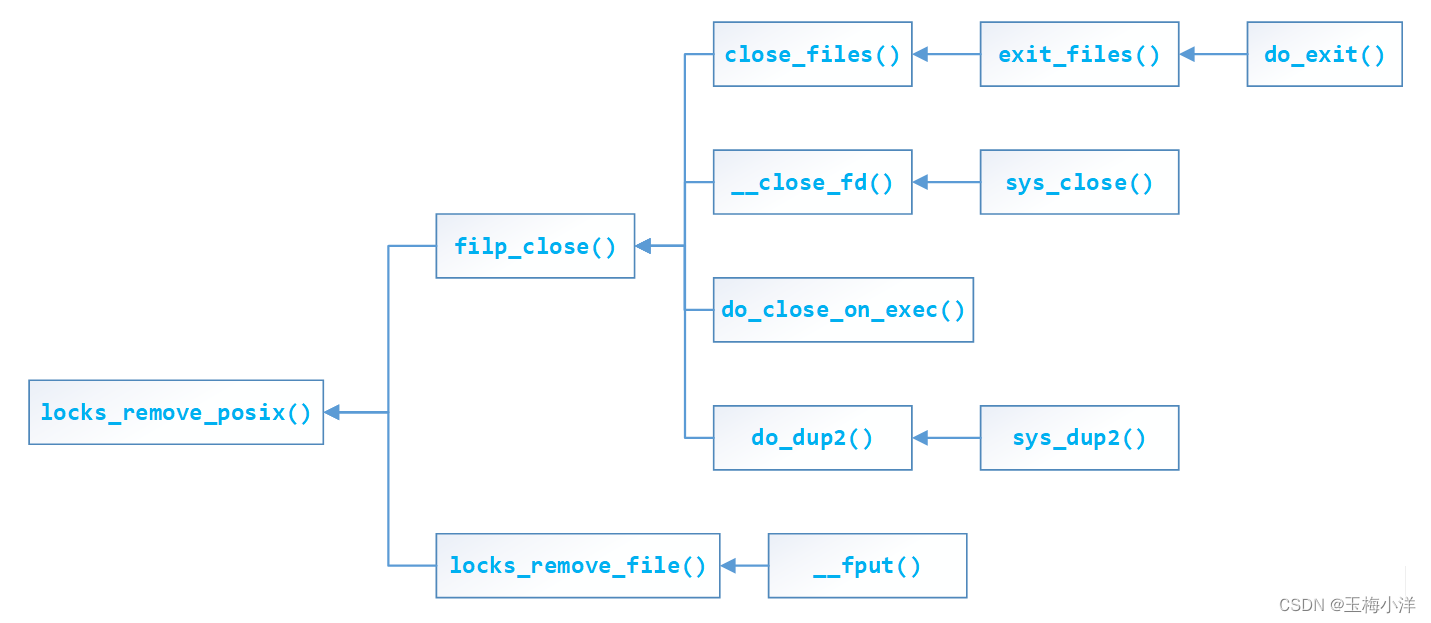
其代码如下:
/* * This function is called when the file is being removed * from the task's fd array. POSIX locks belonging to this task * are deleted at this time. */ void locks_remove_posix(struct file *filp, fl_owner_t owner) { struct file_lock lock; /* * If there are no locks held on this file, we don't need to call * posix_lock_file(). Another process could be setting a lock on this * file at the same time, but we wouldn't remove that lock anyway. */ if (!locks_inode(filp)->i_flock) return; lock.fl_type = F_UNLCK; lock.fl_flags = FL_POSIX | FL_CLOSE; lock.fl_start = 0; lock.fl_end = OFFSET_MAX; lock.fl_owner = owner; lock.fl_pid = current->tgid; lock.fl_file = filp; lock.fl_ops = NULL; lock.fl_lmops = NULL; vfs_lock_file(filp, F_SETLK, &lock, NULL); if (lock.fl_ops && lock.fl_ops->fl_release_private) lock.fl_ops->fl_release_private(&lock); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
其实现方式很简单,主要设置fl_type = F_UNLK, fl_flags = FL_POSXI|FLCOSE, fl_start = 0, fl_end = OFFSET_MAX,然后调用**vfs_lock_file()**进行解锁操作。
问题解答
锁和打开权限的检查
权限检查失败,不论是阻塞模式还是非阻塞模式,返回EBADF。此件检查在内核系统调用的时候已经检查了,不会在vfs层或文件系统从检查。
FL_FLOCK类型加锁请求,只要是读或写打开,就可以加读或这写锁。检查规则如下表所示
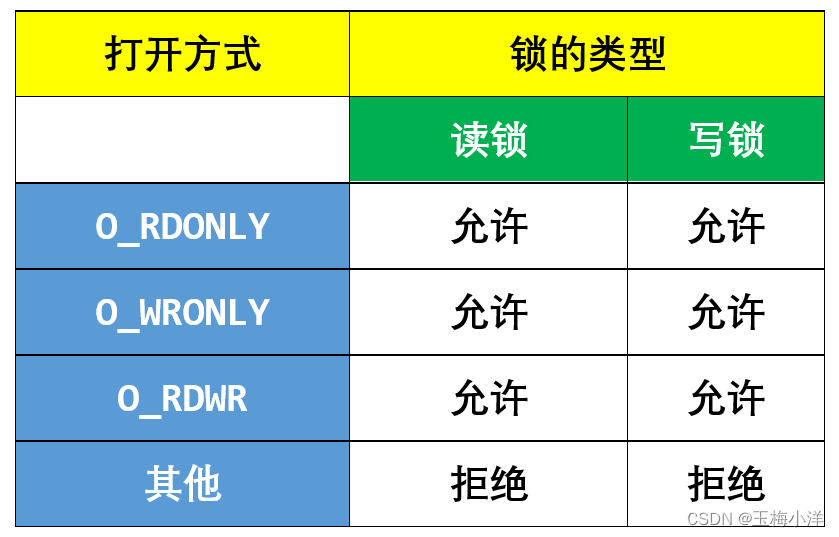
权限检查代码如下:
SYSCALL_DEFINE2(flock, unsigned int, fd, unsigned int, cmd) { .... if (!unlock && !(cmd & LOCK_MAND) && !(f.file->f_mode & (FMODE_READ|FMODE_WRITE))) // 权限检查 goto out_putf; ... out_free: locks_free_lock(lock); out_putf: fdput(f); out: return error; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
FL_POSIX类型加锁请求,读锁需要读打开权限,写锁需要写打开权限。检查规则如下表所示
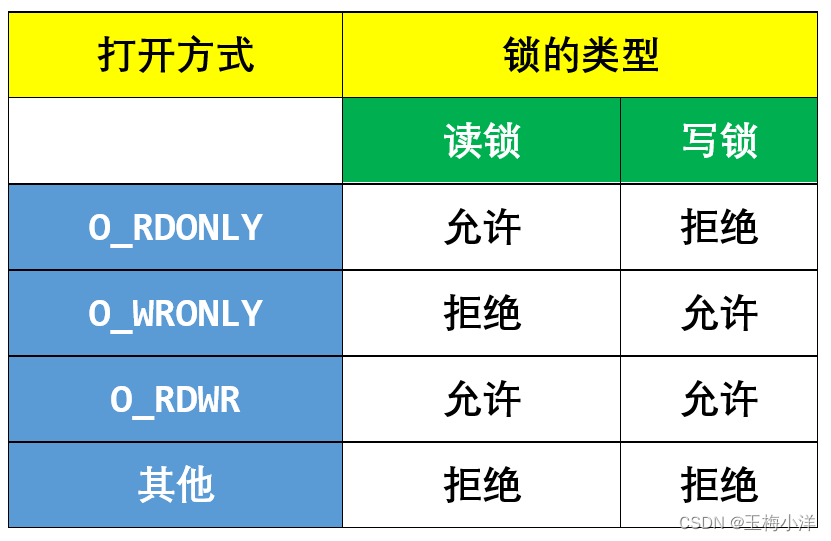
权限检查代码如下:
/* Ensure that fl->fl_filp has compatible f_mode for F_SETLK calls */ static int check_fmode_for_setlk(struct file_lock *fl) { switch (fl->fl_type) { case F_RDLCK: if (!(fl->fl_file->f_mode & FMODE_READ)) return -EBADF; break; case F_WRLCK: if (!(fl->fl_file->f_mode & FMODE_WRITE)) return -EBADF; } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
相同waiter不同锁类型
- user1 加读锁R1成功, user2的线程1加读锁R2,线程2加写锁W2,此时加锁顺会影响结果。如果W2先加锁,则W2阻塞,R2加锁成功。如果R2先加锁,则R2删除,W2加锁阻塞。FLOCK锁,可能出现如下两个情况,因为其先检查是否有相同owner。POSIX锁,只有前面一种情况,因为其先检查是否有冲突的锁,如果有冲突,就没必要进行锁区间锁合并和拆分。如果不是先检查冲突,则即时相同的owner,还得检查是否有冲突,有冲突就不能进行锁区间合并替换等操作的。
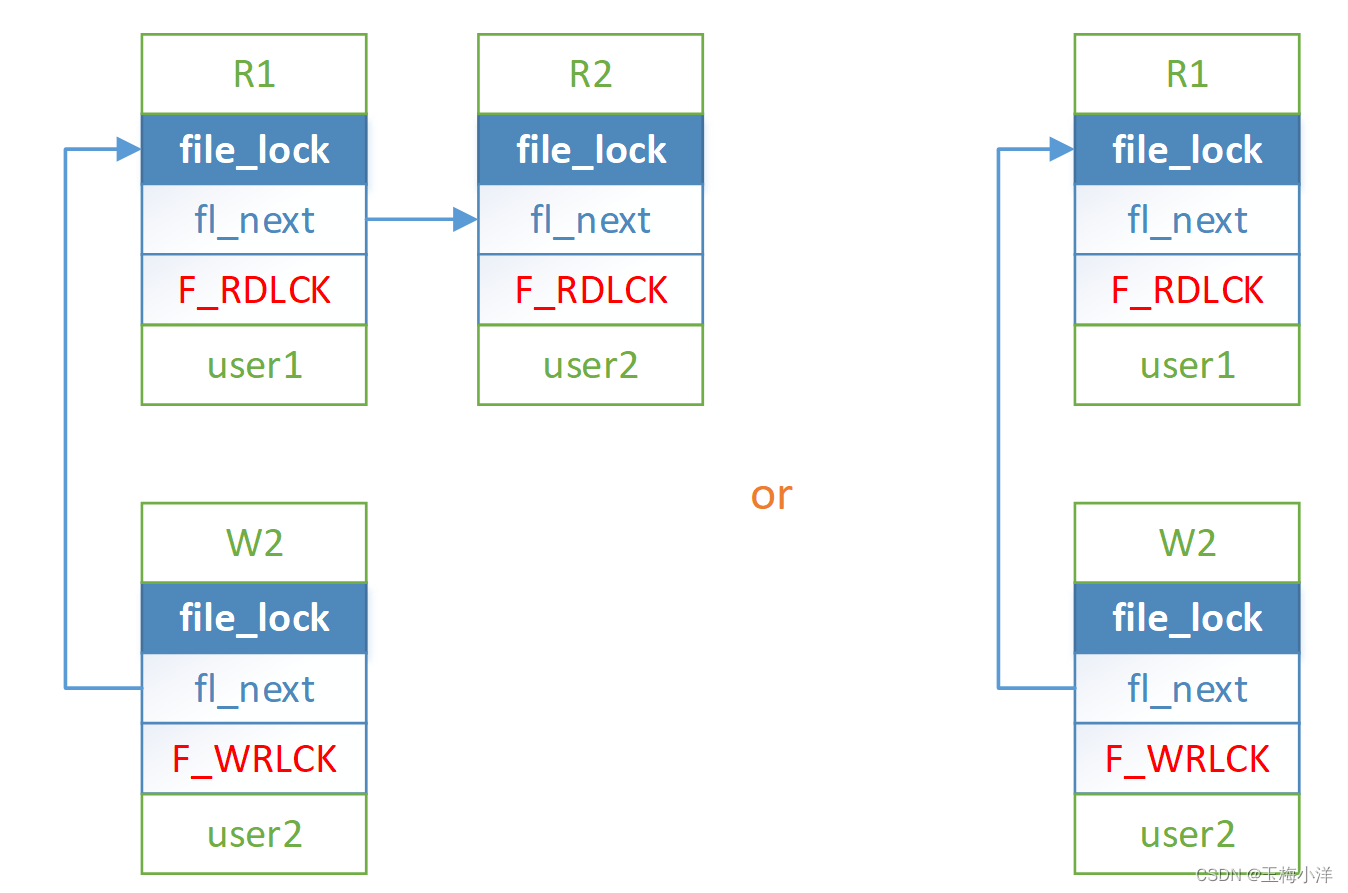
user1解锁R1后,W2被唤醒,重新加锁,把R2替换了,此时就剩下一个W2活跃锁。

- user1 加写锁W1成功, user2的线程1加读锁R2,线程2加写锁W2,此时加锁顺序不影响结果。R2和W2都阻塞。
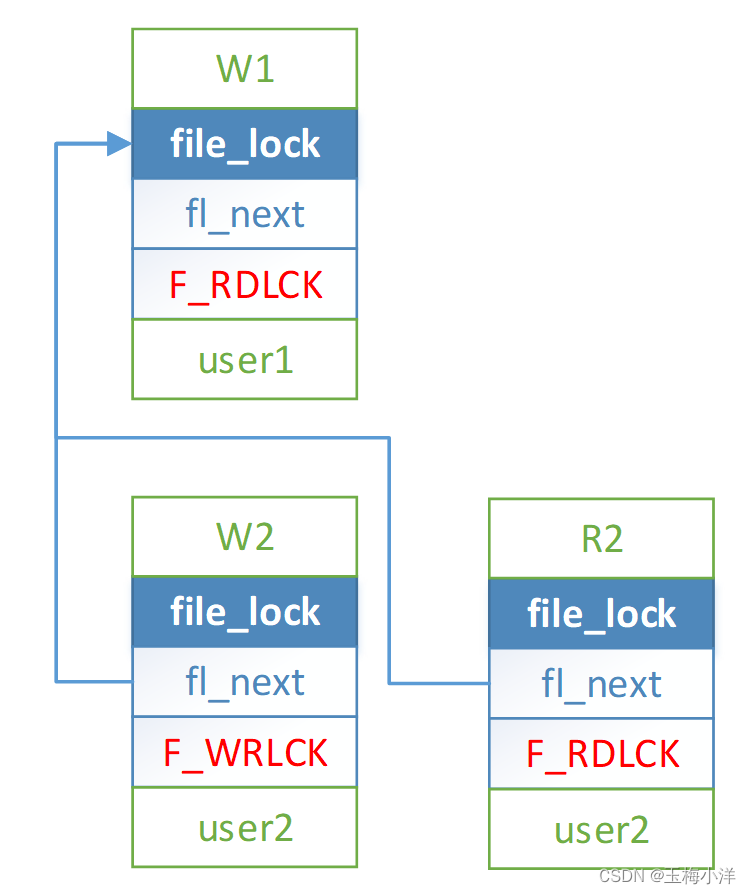
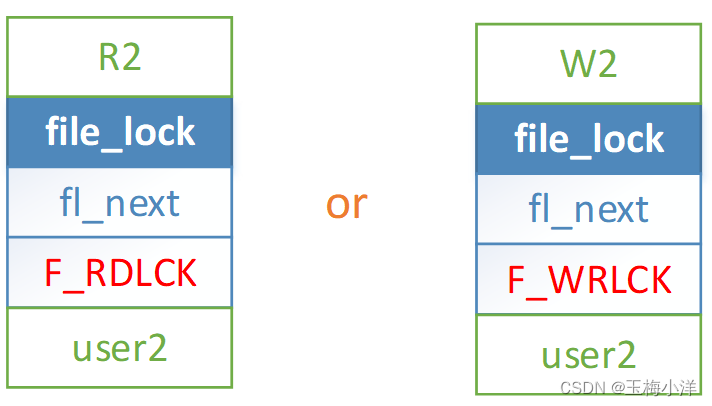
user1解锁W1后,R2和W2被唤醒,此时调用顺序影响最后加锁的类型了,锁的类型为最后调度者类型相同。可能是读锁,也可能是写锁。
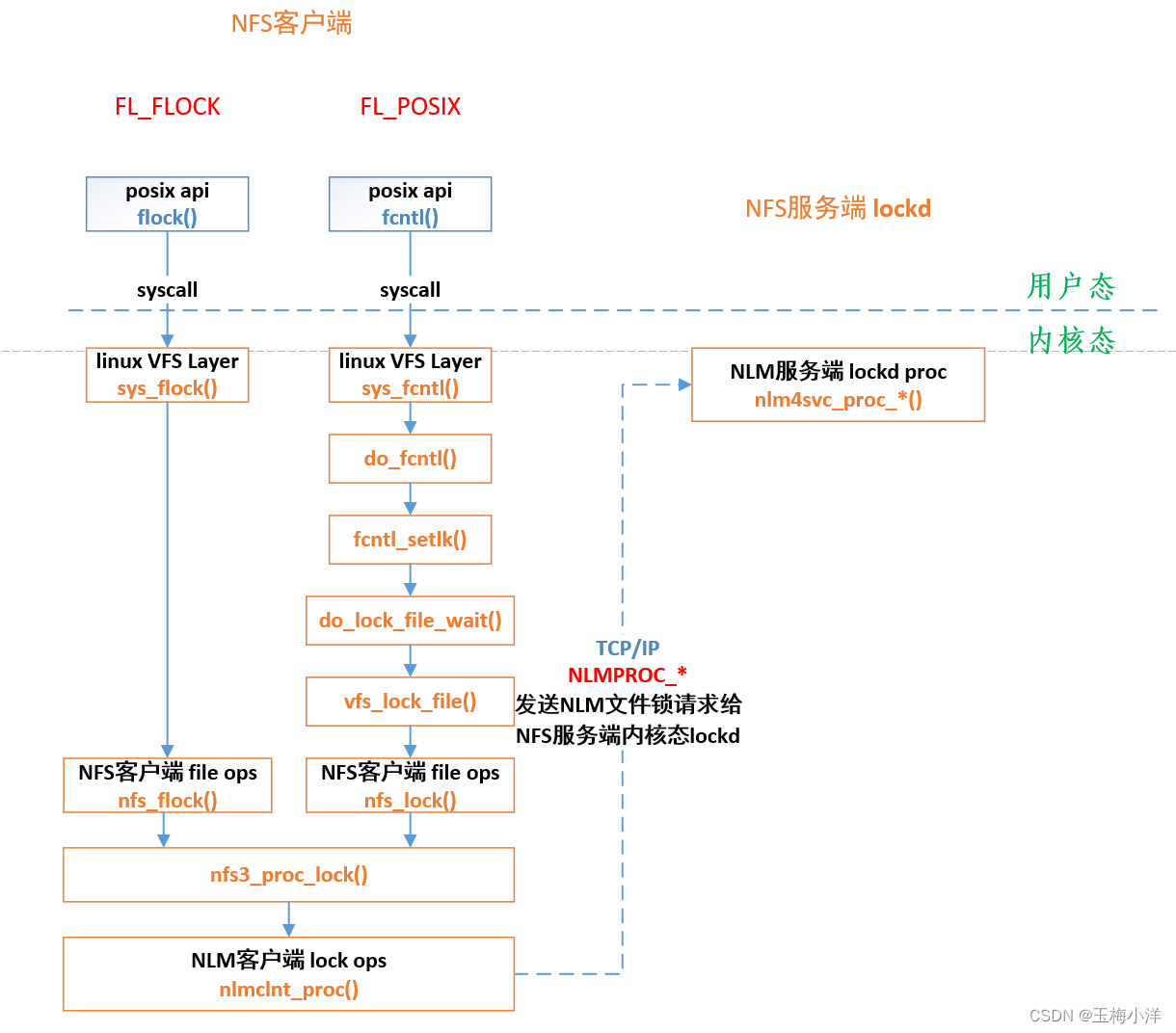
NFSV3调用关系
-
相关阅读:
【openKylin】OpenKylin1.0 x86_64 VMWare安装手册
【K8s入门必看】第二篇 —— 快速部署集群指南
Azure - 机器学习企业级服务概述与介绍
直流电源供电 LED升压 恒流驱动IC 方案AP9193
Linux实操篇-定时任务调度
1538_AURIX_TriCore内核架构_地址映射以及存储配置
echarts 多toolti同时触发图表实现
NFT火力暂停,休息一下?
Redis 数据迁移篇之redis-migrate-tool工具使用手册
Gem5模拟器之scon和模拟脚本时具体在做啥?
- 原文地址:https://blog.csdn.net/SaberJYang/article/details/126335051
