-
【数据结构与算法】第三篇:二叉搜索树
一.二叉搜索树背景
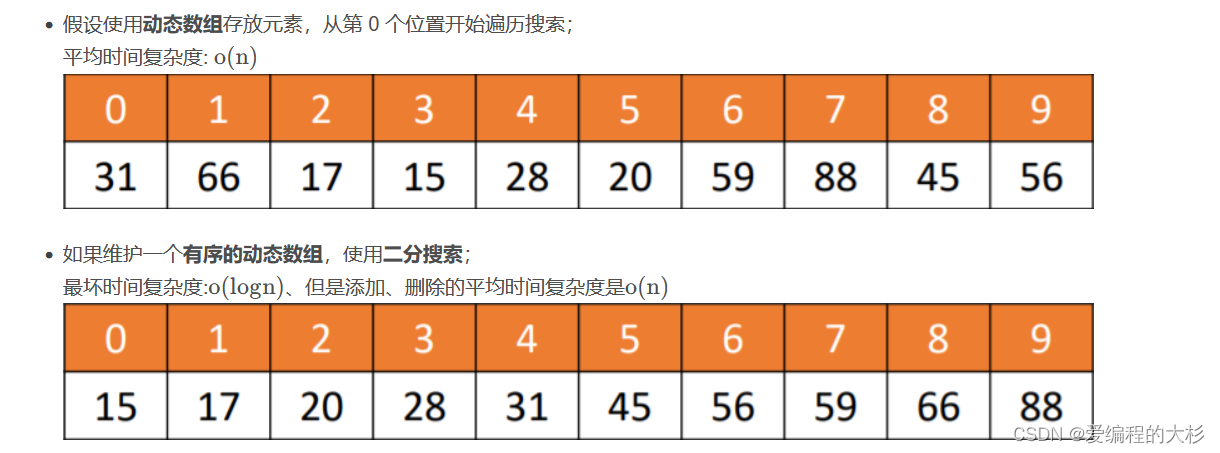
对于动态数组来说,查找元素,从头向后遍历最好情况是O(1),最坏情况是O(n).平均下来复杂度是O(n)
如果维护一个有序的动态数组,使用二分搜索,最坏时间复杂度:O(logn)
但是添加、删除的平均时间复杂度是 O(n)
所以对于动态数组其实有进一步优化的空间但是如果用二叉搜索树,由于根节点,左边都是比根节点小的元素,根节点右边都是比根节点大的元素。最坏的情况下也只是之前一半的执行次数。上一章我们提到了二叉树的高度为,floor(log2n)+1(2的n次取对数在向下取整加一)所以最坏复杂度才为O(log2n)–>无论是添加还是删除;
二.二叉搜索树的性质
◼ 二叉搜索树是二叉树的一种,是应用非常广泛的一种二叉树,英文简称为 BST
任意一个节点的值都大于其左子树所有节点的值
任意一个节点的值都小于其右子树所有节点的值
它的左右子树也是一棵二叉搜索树
◼ 二叉搜索树可以大大提高搜索数据的效率
◼ 二叉搜索树存储的元素必须具备可比较性
😅比如 int、double 等
🤡如果是自定义类型,需要指定比较方式(对于类型的比较
有两种方式---->(1)通过类实现Comparable接口,重写compareTo方法指定比较逻辑(或者直接利用Comparable自带的)
(2)通过比较器重写比较逻辑
)
🤡不允许为 null
三.二叉搜索树的接口设计
◼ int size() // 元素的数量
◼ boolean isEmpty() // 是否为空
◼ void clear() // 清空所有元素
◼ void add(E element) // 添加元素
◼ void remove(E element) // 删除元素
◼ boolean contains(E element)// 是否包含某元素四.添加元素
🌟🌟添加元素,肯定是添加到叶子节点,所以只要只要找到可以存放特定元素的位置,放置元素即可。但是设计并不是直接找到这个叶子节点,而是找到该位置节点的父节点位置,然后通过parent.left或parnet.right=new Node<>(element,null)
private void elementNullCheck(E element) { if(element==null){ throw new UnsupportedOperationException("element="+null+"不合法"); } } public void add(E element){ //element可能为空,为避免其为空要进行事先的检验 elementNullCheck(element); if(this.root==null) { root=new Node<>(element,null); size++; return; } //添加的不是第一个节点 //所以要从根接待你往下去寻找合适的位置,首先先记录根节; Node<E> parent1=this.root;//这里只是初始化一下,写成null也可以 //node可以认为是一个工具节点,去寻找可以存放的位置 Node<E> node=this.root; int ins=0; while (node!=null) { ins=compare(element,node.element); //实时记录目标节点的根节点 parent1=node; if (ins>0){ node=node.right; }else if(ins<0){ node=node.left; }else { return; } } Node<E> newNode=new Node<>(element,parent1); //注意节点的插入位置要与前面一致 if (ins>0){ parent1.right=newNode; }else { parent1.left=newNode; } } //自定义比较标准:如果e1>e2返回正数,e1接口本身的逻辑进行判定 */ if(comparator!=null) { return comparator.compare(e1, e2); } return ((java.lang.Comparable<E>)e1).compareTo(e2); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
设计点: 比较器与Comparable接口的结合设计
private int compare(E e1,E e2){ /** * 两种方法的优化:如果传入了构造器则优先靠考虑用构造器的逻辑,如果没有传入构造器,则使用 * Comparable接口本身的逻辑进行判定 */ if(comparator!=null) { return comparator.compare(e1, e2); } return ((java.lang.Comparable<E>)e1).compareTo(e2); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
五.删除元素
(1)删除度为2节点
将删除度为2的节点转化为删除度为1的叶子节点
删除的节点是度为二的节点
1.找到要删除的节点
2.找到该节点的前驱(后继),用前驱(后继)覆盖要删除的值
3.删除相应的前驱(后继)
4.如果一个节点的度为 2,那么
5.它的前驱、后继节点的度只可能是 1 和 0(2)删除度为1节点
(2)删除的节点是度为一的节点
1.找到要删除的节点node
2.找到要删除的节点的下一个节点child
以node是左子节点为例
node.parent.left=child
child.parent=node.parent;(3)删除度为0节点
(1)删除的节点是叶子节点
1.找到叶子节点node
2.判断此叶子节点是它父节点的左树还是右树
3.直接删除删除代码
//提供给外界的接口 public void remove(E element){ Node<E> s= node(element); remove(s); } //具体实施删除操作 private void remove(Node<E> node){ //处理顺序先难后易->先处理度为2的时候 if (node==null)return; //度为2 if(node.doubleChildren()){ //找到前驱节点 Node<E> s=preTarget(node); node.element=s.element; //可以和其他情况达到统一,到时候直接删除node node=s; } //删除node节点(此时node已经指向前驱或者后继,度只可能为1或0) Node<E> child=node.left==null?node.right:node.left; if(child!=null){ //能进到这里说明不是叶子节点 //更新parent,删除node child.parent=node.parent; if (node.parent==null){//node是度为一节点,且是根节点 //类似链表,删除头节点 //root指向child root=child; //问:不用删除之前的根节点对象吗;child.parent=node.parent;更新就完成了 }else if(node==node.parent.left){//node是度为一节点,且不是根节点,在父节点的左子树 node.parent.left=child; }else if(node==node.parent.right){ node.parent.right=child; } //往后都是被叶子节点的几种情况 }else if(node.parent==null){ root=null; } else { //删除叶子节点(不是根节点) if(node==node.parent.left){ node.parent.left=null; }else { node.parent.right=null; } } } //查找要删除的节点 private Node<E> node(E element){ Node<E> node=this.root; while (node != null) { //这个要写在循环内因为node是时刻更新的 int cmp=compare(element,node.element); if (cmp == 0) { return node; } else if (cmp < 0) { node = node.left; } else { node = node.right; } } return null; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
六.整体代码
package com.Domain; /** * ◼ int size() // 元素的数量 * ◼ boolean isEmpty() // 是否为空 * ◼ void clear() // 清空所有元素 * ◼ void add(E element) // 添加元素 * ◼ void remove(E element) // 删除元素 * ◼ boolean contains(E element)// 是否包含某元素 * @param*/ import Util.printer.BinaryTreeInfo; import java.util.Comparator; import java.util.LinkedList; import java.util.Queue; /** * 比较的两种方式:1.Comparable接口 * (1)让BinarySearch类严格遵守Comparable方法 * public class BinarySearch* (也就是比较类型必须重写Comparable中的compareTo方法) * (2)Person必须严格遵守Comparable接口,实现这个接口并重写compareTo方法 *public class Person @SuppressWarnings("unchecked") public class BinarySearch<E> { private int size;//节点个数 private Node<E> root;//根节点 private Comparator<E> comparator; public BinarySearch (){this(null);}; public BinarySearch(Comparator<E> comparator){ this.comparator=comparator; } public int size(){ return this.size; } public boolean isEmpty(){ return this.size==0; } public void clear(){ size=0; } private void elementNullCheck(E element) { if(element==null){ throw new UnsupportedOperationException("element="+null+"不合法"); } } public void add(E element){ //element可能为空,为避免其为空要进行事先的检验 elementNullCheck(element); if(this.root==null) { root=new Node<>(element,null); size++; return; } //添加的不是第一个节点 //所以要从根接待你往下去寻找合适的位置,首先先记录根节; Node<E> parent1=this.root;//这里只是初始化一下,写成null也可以 //node可以认为是一个工具节点,去寻找可以存放的位置 Node<E> node=this.root; int ins=0; while (node!=null) { ins=compare(element,node.element); //实时记录目标节点的根节点 parent1=node; if (ins>0){ node=node.right; }else if(ins<0){ node=node.left; }else { return; } } Node<E> newNode=new Node<>(element,parent1); //注意节点的插入位置要与前面一致 if (ins>0){ parent1.right=newNode; }else { parent1.left=newNode; } } //自定义比较标准:如果e1>e2返回正数,e1implements Comparable ,括号注明要比较的类型 * 比较的两种方式:2.Comparator比较器 * (1)在BinarySearch中创建比较器类型,并设计构造方法 * (2)在main函数中设计比较器类: * private static class personComparator implements Comparator 注明比较类型 * (3)通过构造方法传入比较器。 * BinarySearch list=new BinarySearch<>(new personComparator()); * (4)compare调用自己比较器中的方法进行比较 * private int compare(E e1,E e2){ * return comparator.compare(e1,e2); * } * 比较器的优点:不用拘泥于Comparable固定的比较逻辑(一次只能按照一种逻辑,避免反复重写), * 可以根据需要定义重写多中逻辑,只要传入的构造器不同就可以按不同的逻辑执行 * * * 完美结合:l08行(不一开始就写死) * @param */ 接口本身的逻辑进行判定 */ if(comparator!=null) { return comparator.compare(e1, e2); } return ((java.lang.Comparable<E>)e1).compareTo(e2); } /** * 删除树的节点: * (1)删除的节点是叶子节点 *1.找到叶子节点node * 2.判断此叶子节点是它父节点的左树还是右树 * 3.直接删除 * node==node.parent.left-->node.parent.left=null; * node==node.parent.right-->node.parent.right=null; * (2)删除的节点是度为一的节点 * 1.找到要删除的节点node * 2.找到要删除的节点的下一个节点child * 以node是左子节点为例 * node.parent.left=child * child.parent=node.parent; * (3)删除的节点是度为二的节点 *1.找到要删除的节点 * 2.找到该节点的前驱(后继),用前驱(后继)覆盖要删除的值 * 2.删除相应的前驱(后继) * ◼ 如果一个节点的度为 2,那么 * 它的前驱、后继节点的度只可能是 1 和 0 * @param element */ //提供给外界的接口 public void remove(E element){ Node<E> s= node(element); remove(s); } //具体实施删除操作 private void remove(Node<E> node){ //处理顺序先难后易->先处理度为2的时候 if (node==null)return; //度为2 if(node.doubleChildren()){ //找到前驱节点 Node<E> s=preTarget(node); node.element=s.element; //可以和其他情况达到统一,到时候直接删除node node=s; } //删除node节点(此时node已经指向前驱或者后继,度只可能为1或0) Node<E> child=node.left==null?node.right:node.left; if(child!=null){ //能进到这里说明不是叶子节点 //更新parent,删除node child.parent=node.parent; if (node.parent==null){//node是度为一节点,且是根节点 //类似链表,删除头节点 //root指向child root=child; //问:不用删除之前的根节点对象吗;child.parent=node.parent;更新就完成了 }else if(node==node.parent.left){//node是度为一节点,且不是根节点,在父节点的左子树 node.parent.left=child; }else if(node==node.parent.right){ node.parent.right=child; } //往后都是被叶子节点的几种情况 }else if(node.parent==null){ root=null; } else { //删除叶子节点(不是根节点) if(node==node.parent.left){ node.parent.left=null; }else { node.parent.right=null; } } } //查找要删除的节点 private Node<E> node(E element){ Node<E> node=this.root; while (node != null) { //这个要写在循环内因为node是时刻更新的 int cmp=compare(element,node.element); if (cmp == 0) { return node; } else if (cmp < 0) { node = node.left; } else { node = node.right; } } return null; } public boolean contains(E element){ return false; } @Override public Object root() { return root; } @Override public Object left(Object node) { return ((Node)node).left; } @Override public Object right(Object node) { return ((Node)node).right; } //告诉打印器打印的内容; @Override public Object string(Object node) { //在原有基础上打印父节点,便于对结果的分析,维护父节点,减小产生bug的概率 Node<E> myNode=(Node<E>)node; String parentString=(myNode.parent==null?null:myNode.parent.element.toString()); return myNode.element+"(p)"+parentString; } //进一步改进,限制控制(设置阀门) // 为控制遍历,需要一个变量存储visit的boolean的返回值,一旦返回为true 终止便利。为了统一这个变量将其放在接口中 //又因为接口不能设置成员变量所以将其改变为抽象方法:抽象方法和接口有异曲同工之秒 public abstract static class Visitor<E>{ abstract boolean visit(E element); //方法改为抽象类型,否则必须实例化 boolean stop; } public void preDisplay1(Visitor<E> visitor) { if (visitor==null){ return; } preDisplay(this.root,visitor); } private void preDisplay(Node<E> node,Visitor<E> visitor) { //stop初始默认为false if(node==null||visitor.stop){ return; } //处理选中的遍历元素:好处——>可以在main()函数里重写visit()方法,可以对选定元素进行任意操作 //根据主函数中重写的visit()方法,对stop进行更新 ,如果为true,直接终止递归 visitor.stop=visitor.visit(node.element); preDisplay(node.left,visitor); preDisplay(node.right,visitor); } //中序遍历 public void inOderDisplay(Visitor<E> visitor){ if(visitor==null) { return; } inOderDisplay1(this.root,visitor); } private void inOderDisplay1(Node<E> node,Visitor<E>visitor) { if (node==null||visitor.stop) { return; } inOderDisplay1(node.left,visitor); visitor.stop=visitor.visit(node.element); //减少复杂度,只要stop一不符合直接终止方法,不用在执行一下的递归 if(visitor.stop){ return; } inOderDisplay1(node.right,visitor); } //后序遍历 public void postDisplay(Visitor<E> visitor){ if(visitor==null) { return; } postDisplay1(this.root,visitor); } private void postDisplay1(Node<E> node,Visitor<E> visitor) { if (node==null||visitor.stop){ return; } postDisplay1(node.left,visitor); postDisplay1(node.right,visitor); //减少运行次数:上一次已经是true了所以没必要在进行了 if(visitor.stop) { return; } visitor.stop=visitor.visit(node.element); } //重点:层序遍历 public void levelDisplay(Visitor<E>visitor){ Queue<Node<E>> queue=new LinkedList<>(); if (this.root==null||visitor==null) { return; } queue.offer(root); while (!queue.isEmpty()){ Node<E> node=queue.poll(); //在开发中还有一种需求就是:遍历二叉树,但是控制遍历的长度,比如说限制遍历到2,或者只遍历前三个元素 //此时就需要有一个开关(阀门)来进行控制-->通过boolean类性 if(visitor.visit(node.element)){ return; } if (node.left!=null) { queue.offer(node.left); } if (node.right!=null){ queue.offer(node.right); } } } //添加判断叶子节点的方法 public static class Node<E>{ E element; Node<E> left; Node<E> right; Node<E> parent; public Node(E element,Node<E> parent){ this.element=element; this.parent=parent; } public boolean isLeaf(){ return left==null&&right==null; } public boolean doubleChildren(){ return left!=null&&right!=null; } } //判断是否是完全二叉树 public boolean isComplete(){ if(this.root==null){ return false; } Queue<Node<E>> queue=new LinkedList<>(); queue.offer(root); boolean leaf=false; while (!queue.isEmpty()){ Node<E> node=queue.poll(); /** * leaf->true要求为叶子节点 * !node.isLeaf()如果成立->node节点并不是叶子节点->不是完全二叉树 */ if(!node.isLeaf()&&leaf){ return false; } if (node.left!=null){ queue.offer(node.left); }else if(node.right!=null) { return false; } if (node.right!=null){ queue.offer(node.right); }else{ leaf=true; } } return true; } /** * 计算二叉树的高度 * * 方法一:递归——>二叉树深度=Math.max(左子树深度,右子树深度)+1(+1就是加上本身这一层) public int height(){ return height(root); } private int height(Nodenode){ if(node==null){ return 0; } return 1+Math.max(height(node.left),height(node.right)); } 方法二;利用层序遍历统计层数 */ public int height(){ if(root==null){ return 0; } Queue<Node<E>> queue=new LinkedList<>(); queue.offer(root); //记录高度 int height=0; //记录每层的元素 int levelSize=1; while (!queue.isEmpty()){ Node<E> node=queue.poll(); levelSize--; if(node.left!=null){ queue.offer(node.left); } if (node.right!=null){ queue.offer(node.right); } //换层,高度加一 if (levelSize==0){ levelSize=queue.size(); height++; } } return height; } /** * 重构而二叉树 * 前序遍历+中序遍历 * 后序遍历+中序遍历 * * 前序遍历+后序遍历(前提:是一颗真序二叉树) */ /** * 前缀节+后继节点 */ //后继节点就是前驱节点代码中left和right对换 public Node<E> preTarget(Node<E> node){ if (node==null){ return null; } Node<E> p=node.left; //该节点有左子树的情况,直接找左子树的最右节点 if (p!=null) { while (p.right != null) { //遍历左子树找到最右边的最后一个节点 p = p.right; } return p; } //到这里说明没有左子树。遍历右子树(从右子树最左边的节点开始) //从该节点通过parent不断向上遍历,只到发现某个节点将目标节点当作右节点(找到比节点小的前一个节点) while (node.parent!=null&&node==node.parent.left) { node=node.parent; } //走到这有两种情况1.node.parent==null,node=node.parent.right //如果第一种情况,没有前驱节点返回null。 return node.parent; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469

-
相关阅读:
Javascript EventListener 事件监听 (mouseover、mouseout)
线程纵横:C++并发编程的深度解析与实践
【网络安全】文件包含漏洞--使用session进行文件包含
贪心算法练习
JAVA:实现使用快速排序算法获取给定数组中的第 k 个最大或第 k 个最小元素算法(附完整源码)
【Python基础】高级数据类型:初识 “列表” || 列表的增删改查 || del关键字 || 列表的定义
技术干货|昇思MindSpore 1.5版本中的亲和算法库——MindSpore Boost
栈和队列【数据结构与算法Java】
【UE4】最简化碰撞检测
图像处理:图像清晰度评价
- 原文地址:https://blog.csdn.net/qq_61571098/article/details/126329743
