-
ORB-SLAM2 ---- ORBmatcher::SearchByBoW函数
1.本函数的作用
匹配两帧中的特征点,与ORBmatcher::SearchForInitialization相比,ORBmatcher::SearchForTriangulation利用了词袋BoW加速了匹配速度。
2.词袋原理 Bow
直观理解词袋
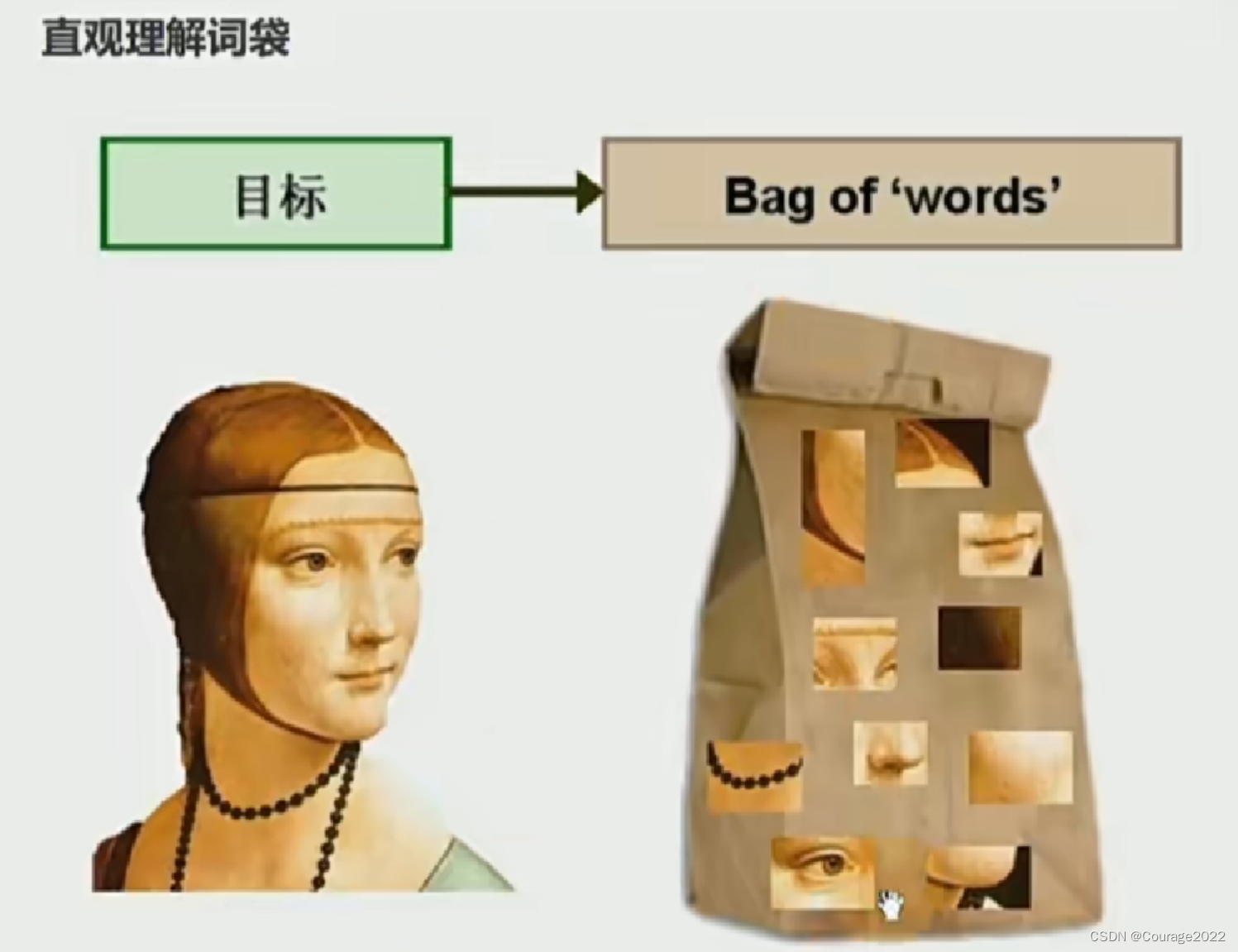
词袋的形成:
提取ORB特征点、对描述子进行聚类;有新的一帧传进来时、我们将其在词袋内进行遍历得到很多单词,可以用频率来表示。
3 如何制作BoW
3.1 离线训练
首先图像提取ORB 特征点,将描述子通过 k-means 进行聚类,根据设定的树的分支数和深度,从叶子节点开始聚类一直到根节点,最后得到一个非常大的 vocabulary tree,
1、遍历所有的训练图像,对每幅图像提取ORB特征点。
2、设定vocabulary tree的分支数K和深度L。将特征点的每个描述子用 K-means聚类,变成 K个集合, 作为vocabulary tree 的第1层级,然后对每个集合重复该聚类操作,就得到了vocabulary tree的第2层级,继续迭代最后得到满足条件的vocabulary tree,它的规模通常比较大,比如ORB-SLAM2使用的离线字典就有108万+ 个节点。
3、离根节点最远的一层节点称为叶子或者单词 Word。根据每个Word 在训练集中的相关程度给定一个权重weight,训练集里出现的次数越多,说明辨别力越差,给与的权重越低。(这个我感觉像哈夫曼树....)
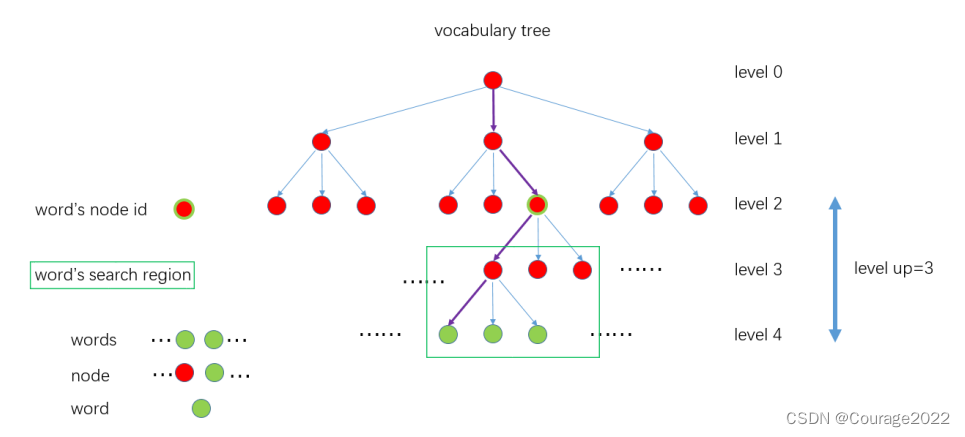
3.2 在线图像生成BoW向量
1、对新来的一帧图像进行ORB特征提取,得到一定数量(一般几百个)的特征点,描述子维度和 vocabulary tree中的一致
2、对于每个特征点的描述子,从离线创建好的vocabulary tree中开始找自己的位置,从根节点开始, 用该描述子和每个节点的描述子计算汉明距离,选择汉明距离最小的作为自己所在的节点,一直遍历到叶子节点。 整个过程是这样的。紫色的线表示一个特征点从根节点到叶子节点的过程。
3.3 代码解析: Frame::ComputeBoW函数
4 ORBmatcher::SearchByBoW函数解析
4.1 该函数的作用及参数
- /*
- * @brief 通过词袋,对关键帧的特征点进行跟踪
- * 步骤
- * Step 1:分别取出属于同一node的ORB特征点(只有属于同一node,才有可能是匹配点)
- * Step 2:遍历KF中属于该node的特征点
- * Step 3:遍历F中属于该node的特征点,寻找最佳匹配点
- * Step 4:根据阈值 和 角度投票剔除误匹配
- * Step 5:根据方向剔除误匹配的点
- * @param pKF 关键帧
- * @param F 当前普通帧
- * @param vpMapPointMatches F中地图点对应的匹配,NULL表示未匹配
- * @return 成功匹配的数量
- */
- int ORBmatcher::SearchByBoW(KeyFrame* pKF,Frame &F, vector
- {
- // 获取该关键帧的地图点
- const vector
- // 和普通帧F特征点的索引一致
- vpMapPointMatches = vector
- // 取出关键帧的词袋特征向量
- const DBoW2::FeatureVector &vFeatVecKF = pKF->mFeatVec;
- int nmatches=0;
- // 特征点角度旋转差统计用的直方图
- vector<int> rotHist[HISTO_LENGTH];
- for(int i=0;irotHist[i].reserve(500);// 将0~360的数转换到0~HISTO_LENGTH的系数// !原作者代码是 const float factor = 1.0f/HISTO_LENGTH; 是错误的,更改为下面代码const float factor = HISTO_LENGTH/360.0f;// We perform the matching over ORB that belong to the same vocabulary node (at a certain level)// 将属于同一节点(特定层)的ORB特征进行匹配DBoW2::FeatureVector::const_iterator KFit = vFeatVecKF.begin();DBoW2::FeatureVector::const_iterator Fit = F.mFeatVec.begin();DBoW2::FeatureVector::const_iterator KFend = vFeatVecKF.end();DBoW2::FeatureVector::const_iterator Fend = F.mFeatVec.end();while(KFit != KFend && Fit != Fend){// Step 1:分别取出属于同一node的ORB特征点(只有属于同一node,才有可能是匹配点)// first 元素就是node id,遍历if(KFit->first == Fit->first){// second 是该node内存储的feature indexconst vector<unsigned int> vIndicesKF = KFit->second;const vector<unsigned int> vIndicesF = Fit->second;// Step 2:遍历KF中属于该node的特征点for(size_t iKF=0; iKF{// 关键帧该节点中特征点的索引const unsigned int realIdxKF = vIndicesKF[iKF];// 取出KF中该特征对应的地图点MapPoint* pMP = vpMapPointsKF[realIdxKF];if(!pMP)continue;if(pMP->isBad())continue;const cv::Mat &dKF= pKF->mDescriptors.row(realIdxKF); // 取出KF中该特征对应的描述子int bestDist1=256; // 最好的距离(最小距离)int bestIdxF =-1 ;int bestDist2=256; // 次好距离(倒数第二小距离)// Step 3:遍历F中属于该node的特征点,寻找最佳匹配点for(size_t iF=0; iF{// 和上面for循环重名了,这里的realIdxF是指普通帧该节点中特征点的索引const unsigned int realIdxF = vIndicesF[iF];// 如果地图点存在,说明这个点已经被匹配过了,不再匹配,加快速度if(vpMapPointMatches[realIdxF])continue;const cv::Mat &dF = F.mDescriptors.row(realIdxF); // 取出F中该特征对应的描述子// 计算描述子的距离const int dist = DescriptorDistance(dKF,dF);// 遍历,记录最佳距离、最佳距离对应的索引、次佳距离等// 如果 dist < bestDist1 < bestDist2,更新bestDist1 bestDist2if(dist{bestDist2=bestDist1;bestDist1=dist;bestIdxF=realIdxF;}// 如果bestDist1 < dist < bestDist2,更新bestDist2else if(dist{bestDist2=dist;}}// Step 4:根据阈值 和 角度投票剔除误匹配// Step 4.1:第一关筛选:匹配距离必须小于设定阈值if(bestDist1<=TH_LOW){// Step 4.2:第二关筛选:最佳匹配比次佳匹配明显要好,那么最佳匹配才真正靠谱if(static_cast<float>(bestDist1){// Step 4.3:记录成功匹配特征点的对应的地图点(来自关键帧)vpMapPointMatches[bestIdxF]=pMP;// 这里的realIdxKF是当前遍历到的关键帧的特征点idconst cv::KeyPoint &kp = pKF->mvKeysUn[realIdxKF];// Step 4.4:计算匹配点旋转角度差所在的直方图if(mbCheckOrientation){// angle:每个特征点在提取描述子时的旋转主方向角度,如果图像旋转了,这个角度将发生改变// 所有的特征点的角度变化应该是一致的,通过直方图统计得到最准确的角度变化值float rot = kp.angle-F.mvKeys[bestIdxF].angle;// 该特征点的角度变化值if(rot<0.0)rot+=360.0f;int bin = round(rot*factor);// 将rot分配到bin组, 四舍五入, 其实就是离散到对应的直方图组中if(bin==HISTO_LENGTH)bin=0;assert(bin>=0 && binrotHist[bin].push_back(bestIdxF); // 直方图统计}nmatches++;}}}KFit++;Fit++;}else if(KFit->first < Fit->first){// 对齐KFit = vFeatVecKF.lower_bound(Fit->first);}else{// 对齐Fit = F.mFeatVec.lower_bound(KFit->first);}}// Step 5 根据方向剔除误匹配的点if(mbCheckOrientation){// indexint ind1=-1;int ind2=-1;int ind3=-1;// 筛选出在旋转角度差落在在直方图区间内数量最多的前三个bin的索引ComputeThreeMaxima(rotHist,HISTO_LENGTH,ind1,ind2,ind3);for(int i=0; i{// 如果特征点的旋转角度变化量属于这三个组,则保留if(i==ind1 || i==ind2 || i==ind3)continue;// 剔除掉不在前三的匹配对,因为他们不符合“主流旋转方向”for(size_t j=0, jend=rotHist[i].size(); j{vpMapPointMatches[rotHist[i][j]]=static_castnmatches--;}}}return nmatches;}
4.2 分别取出属于同一node的ORB特征点(只有属于同一node,才有可能是匹配点
- // 获取该关键帧的地图点
- const vector
- // 和普通帧F特征点的索引一致
- vpMapPointMatches = vector
- // 取出关键帧的词袋特征向量
- const DBoW2::FeatureVector &vFeatVecKF = pKF->mFeatVec;
- int nmatches=0;
- // 特征点角度旋转差统计用的直方图
- vector<int> rotHist[HISTO_LENGTH];
- for(int i=0;irotHist[i].reserve(500);// 将0~360的数转换到0~HISTO_LENGTH的系数// !原作者代码是 const float factor = 1.0f/HISTO_LENGTH; 是错误的,更改为下面代码const float factor = HISTO_LENGTH/360.0f;// We perform the matching over ORB that belong to the same vocabulary node (at a certain level)// 将属于同一节点(特定层)的ORB特征进行匹配DBoW2::FeatureVector::const_iterator KFit = vFeatVecKF.begin();DBoW2::FeatureVector::const_iterator Fit = F.mFeatVec.begin();DBoW2::FeatureVector::const_iterator KFend = vFeatVecKF.end();DBoW2::FeatureVector::const_iterator Fend = F.mFeatVec.end();while(KFit != KFend && Fit != Fend){// Step 1:分别取出属于同一node的ORB特征点(只有属于同一node,才有可能是匹配点)// first 元素就是node id,遍历if(KFit->first == Fit->first){// second 是该node内存储的feature indexconst vector<unsigned int> vIndicesKF = KFit->second;const vector<unsigned int> vIndicesF = Fit->second;
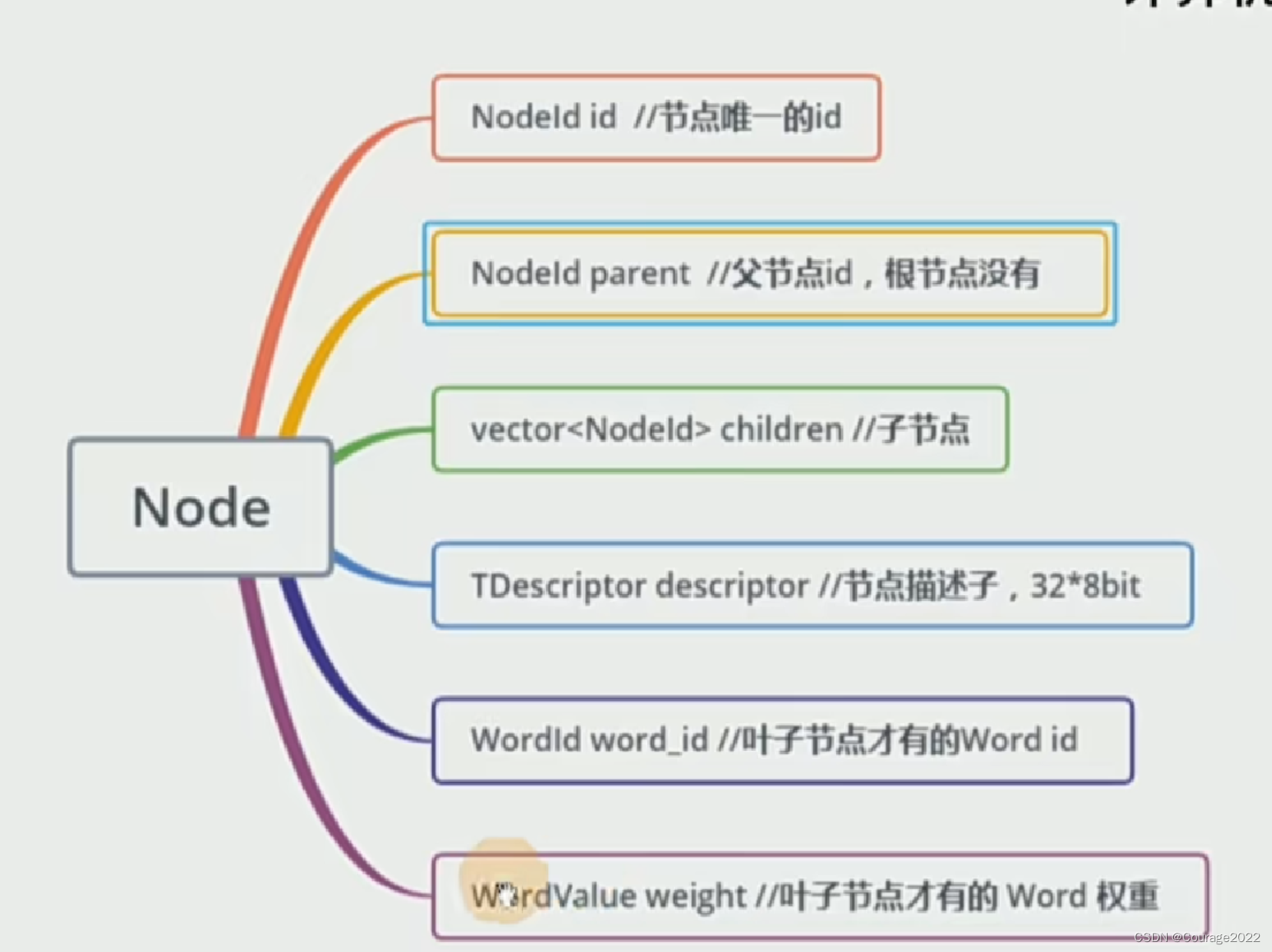
class BowVector: public std::mapclass FeatureVector: public std::mappKF是关键帧、F是当前普通帧。用vpMapPointsKF容器提取关键帧中的地图点。vpMapPointMatches 容器记录匹配关系,建立指向关键帧词袋特征向量的引用vFeatVecKF、匹配数目的指示器nmatches、建立旋转直方图rotHist、建立关键帧和普通帧的FeatureVector的迭代器KFit、Fit、KFend、Fend。
由Frame::ComputeBoW函数的解析我们知:如果两个描述子要成功匹配,其必属于同一个node。
4.3 遍历KF中属于该node的特征点
4.4 遍历F中属于该node的特征点,寻找最佳匹配点
- while(KFit != KFend && Fit != Fend)
- {
- // Step 1:分别取出属于同一node的ORB特征点(只有属于同一node,才有可能是匹配点)
- // first 元素就是node id,遍历
- if(KFit->first == Fit->first)
- {
- // second 是该node内存储的feature index
- const vector<unsigned int> vIndicesKF = KFit->second;
- const vector<unsigned int> vIndicesF = Fit->second;
- // Step 2:遍历KF中属于该node的特征点
- for(size_t iKF=0; iKF
- {
- // 关键帧该节点中特征点的索引
- const unsigned int realIdxKF = vIndicesKF[iKF];
- // 取出KF中该特征对应的地图点
- MapPoint* pMP = vpMapPointsKF[realIdxKF];
- if(!pMP)
- continue;
- if(pMP->isBad())
- continue;
- const cv::Mat &dKF= pKF->mDescriptors.row(realIdxKF); // 取出KF中该特征对应的描述子
- int bestDist1=256; // 最好的距离(最小距离)
- int bestIdxF =-1 ;
- int bestDist2=256; // 次好距离(倒数第二小距离)
- // Step 3:遍历F中属于该node的特征点,寻找最佳匹配点
- for(size_t iF=0; iF
- {
- // 和上面for循环重名了,这里的realIdxF是指普通帧该节点中特征点的索引
- const unsigned int realIdxF = vIndicesF[iF];
- // 如果地图点存在,说明这个点已经被匹配过了,不再匹配,加快速度
- if(vpMapPointMatches[realIdxF])
- continue;
- const cv::Mat &dF = F.mDescriptors.row(realIdxF); // 取出F中该特征对应的描述子
- // 计算描述子的距离
- const int dist = DescriptorDistance(dKF,dF);
- // 遍历,记录最佳距离、最佳距离对应的索引、次佳距离等
- // 如果 dist < bestDist1 < bestDist2,更新bestDist1 bestDist2
- if(dist{bestDist2=bestDist1;bestDist1=dist;bestIdxF=realIdxF;}// 如果bestDist1 < dist < bestDist2,更新bestDist2else if(dist{bestDist2=dist;}}
KFit、Fit分别是指向关键帧、普通帧的FeatureVector容器的迭代器。如果他们的nodeID相同则进入匹配,若KFit的node小于Fit的node,则调整迭代器KFit指向大于等于Fit迭代器所指向的node大小的地方,方便下次匹配。
- else if(KFit->first < Fit->first)
- {
- // 对齐
- KFit = vFeatVecKF.lower_bound(Fit->first);
- }
- else
- {
- // 对齐
- Fit = F.mFeatVec.lower_bound(KFit->first);
- }
若node相同,则依次匹配利用选择排序,和前面讲的就完全一样了。
-
相关阅读:
Java计算机毕业设计 基于SpringBoot+Vue的毕业生信息招聘平台的设计与实现 Java实战项目 附源码+文档+视频讲解
nginx实现路由重定向功能 避免服务器出现 404 Not Found
【UML】类图Class Diagram
适合汽车应用的MAX49017ATA/VY、MAX40025AAWT、MAX40025CAWT、MAX40026ATA/VY(线性)微功耗比较器
【LeetCode】2022 8月 每日一题
设计模式22——备忘录模式
springboot+jsp教育机构OA系统(源码免费获取+论文+答辩PPT)
spring-boot-plus2.7.12版本重磅发布,三年磨一剑,兄弟们等久了,感谢你们的陪伴
容器数据卷+MYSQL实战
JVM(Java Virtual Machine)垃圾收集器篇
- 原文地址:https://blog.csdn.net/qq_41694024/article/details/126322962
 https://blog.csdn.net/qq_41694024/article/details/126319167?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22126319167%22%2C%22source%22%3A%22qq_41694024%22%7D
https://blog.csdn.net/qq_41694024/article/details/126319167?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22126319167%22%2C%22source%22%3A%22qq_41694024%22%7D