-
2021论文阅读笔记集合
文章目录
- backbone
- operator
- ocr
- scene text recognition
- 基础知识
- An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
- Robust Scene Text Recognition with Automatic Rectification
- ASTER: An attentional scene text recognizer with flexible rectification
- What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis
- Revisiting Classification Perspective on Scene Text Recognition文章地址: https://arxiv.org/pdf/2102.10884.pdf
- On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention
- What If We Only Use Real Datasets for Scene Text Recognition?Toward Scene Text Recognition With Fewer Labels
- transformer
- visualization
- contrastive learning
- Self-Supervised Learning基本知识
- Momentum Contrast for Unsupervised Visual Representation Learning(MoCov1)
- A Simple Framework for Contrastive Learning of Visual Representations(SimCLRv1)
- Improved Baselines with Momentum Contrastive Learning(MoCov2)
- Big Self-Supervised Models are Strong Semi-Supervised Learners(SimCLRv2)
- An Empirical Study of Training Self-Supervised Vision Transformers(MoCov3)
- Bootstrap Your Own Latent A New Approach to Self-Supervised Learning(BYOL)
- Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning
- Understanding Self-Supervised Learning Dynamics without Contrastive Pairs
- image super resolution
backbone
(HRNetv2)High-Resolution Representations for Labeling Pixels and Regions
论文地址:https://arxiv.org/pdf/1904.04514.pdf
开源代码:https://github.com/HRNet网络结构:
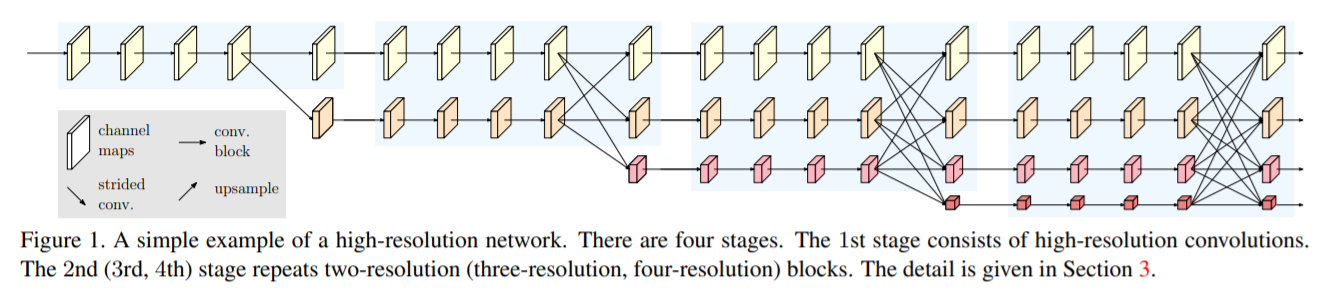
文章创新点:
网络分四个stage,每个stage结束时会新分出一个更低分辨率(指hw更小)的分支,该分支是对上一个stage所有特征图融合的结果。每个stage中各不同分辨率的分支会与其他分支产生的特征图进行融合,高分辨率特征与低分辨率特征相互融合增加了特征图包含的信息。不同分辨率特征图的融合方式不同,对高分辨率特征图使用卷积进行下采样,对低分辨率图片则是用上采样+1x1卷积,融合时做element wise add操作。在第四个stage之后,低分辨率的特征图通过上采样放大后不断与高分辨率特征图融合,具体操作方式根据任务不同略有区别(图b和c)。
 该网络在分类、检测、分割、人体姿态估计任务中均可作为backbone使用。具体结果可查看官方开源代码。
该网络在分类、检测、分割、人体姿态估计任务中均可作为backbone使用。具体结果可查看官方开源代码。(RepVGG)RepVGG: Making VGG-style ConvNets Great Again
论文地址:https://arxiv.org/pdf/2101.03697.pdf
开源代码:https://github.com/DingXiaoH/RepVGG网络结构:
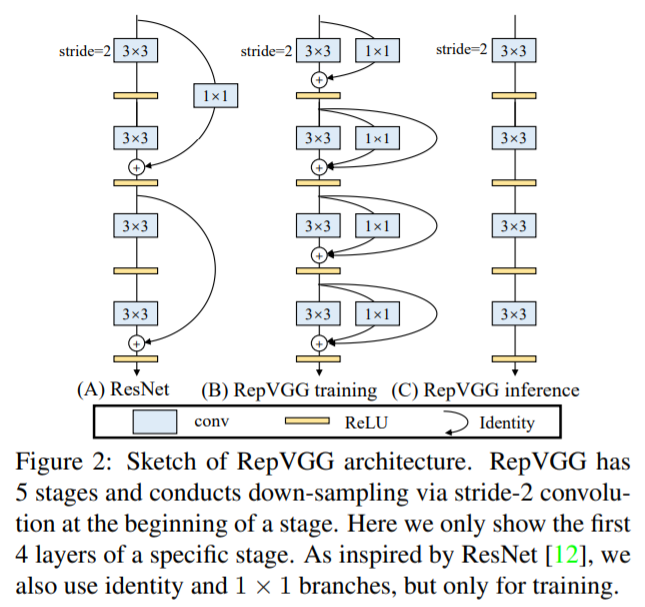
文章创新点:
该网络属于结构重参数化网络,类似的网络还有ACNet、RepMLP等等。所谓结构重参数化,是指网络在训练和推理时使用的网络结构不同,但可以通过数学上的等价关系将训练时的网络结构参数转化为推理时的网络结构参数。在很久以前,就有人在推理时将conv层的卷积核参数与其后的bn层参数通过数学上的公式转换计算得到一个新的卷积核参数,然后将这个卷积核参数赋予卷积层,这样就达到了在推理时去掉conv层之后的bn层的目的,加快了网络的推理速度。

本文在这种操作基础上更进一步,在训练时,每个conv层是一个多分支的结构,即一个3x3卷积+一个1x1卷积+一个shortcut连接,最后做相加融合操作,再经过一个relu层。注意3x3卷积、1x1卷积、shortcut连接后均有独立的Bn层。网络训练完成后,通过对3x3卷积、1x1卷积、shortcut连接以及它们后面的bn层的参数做数学上的转换计算,得到对应的一个新的3x3卷积核参数。转换完成后,构建一个新的网络,该网络为单分支网络,网络的每一层均为一个conv层+一个relu层的结构,然后将转换后的参数赋予该网络即可进行推理。文中给出了严格的数学推导公式证明,训练时的网络与转换后的推理时的网络在相同输入时输出是完全一致的。operator
Decoupled Dynamic Filter Networks
论文地址:https://arxiv.org/pdf/2104.14107.pdf
开源代码:https://github.com/theFoxofSky/ddfnet本文提出了一种名为Decoupled Dynamic Filter(DDF)的结构来替代标准卷积层(卷积核必须大于1x1),并在DDF的基础上,提出了DDF-up结构替换传统的上采样层(可用于目标检测中)。DDF结构如下图:
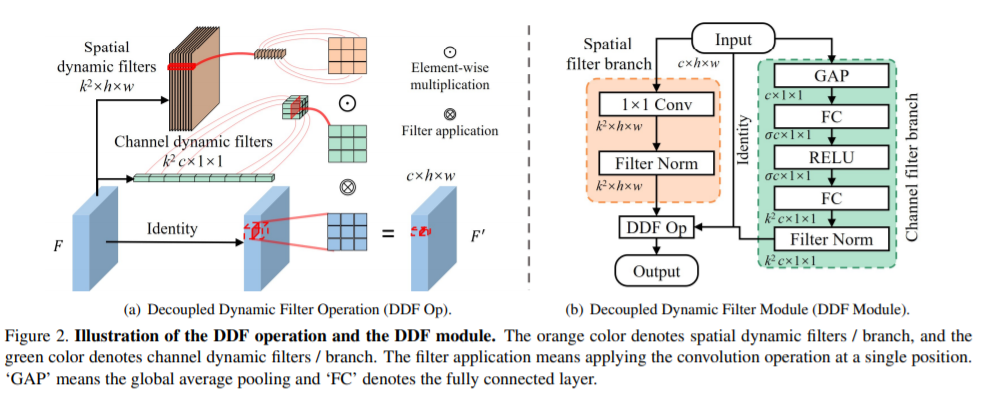
文章创新点:
相比于标准卷积,DDF结构更加轻量。它的核心思想是设计动态的卷积核,并且把卷积核拆分为空间和通道两个维度上。看上图右边可知,输入分别进入空间和通道卷积核生成分支生成空间卷积核和通道卷积核。在空间维度上,首先用1x1卷积将特征图通道变为k平方,每个像素点对于的k平方个值就是对应该像素点的空间卷积核;在通道维度上,先使用GAP将特征图变成一维向量,然后通过一个类似se模块的操作,将维度变为k平方乘以c,即对每一个通道,其通道卷积核尺寸为kxk;对不同通道采用不同的通道卷积核,其尺寸为kxkxc。然后,将两个卷积核做element wise multiply操作(维度不同自动广播),这样就生成了一个动态卷积核。然后,将该动态卷积核与输入特征图做卷积。DDF结构可以直接替换ResNet block中的3x3卷积。(总感觉这又是一种花式attention…)文中还对这种结构的参数量、内存占用和速度进行了分析,相比于标准卷积具有明显的优势。同时,作者将DDF结构应用于ResNet,取得了明显的涨点(见下图)。

根据DDF结构作者还创造了一种DDF-up结构,用于在目标检测任务中替换传统的上采样层。这部分详细可看原论文。(RedNet)Involution: Inverting the Inherence of Convolution for Visual Recognition
论文地址:https://arxiv.org/pdf/2103.06255.pdf
开源代码:https://github.com/d-li14/involution本文提出了一种新的算子。
算子结构:

文章创新点:
传统的卷积具有两个重要的特征:空间无关性和通道特定性。假设有一个3x3卷积层,输入为C1个channel,输出为C2个channel,那么其卷积核尺寸为C2xC1x3x3。具体来说,对于每个输出channel,都有一个C1x3x3的卷积核,再细分一下,对每个输入channel,都有一个3x3的卷积核。对于每个卷积核,其在hw尺度上是共用的,即卷积核与特征图的hw空间位置无关,这就是空间无关性。对于每个输出channel,都有不同的C1x3x3的卷积核,这就是通道特定性。本文作者提出了involution算子,并据此提出了RedNet。involution算子可以看成另一种形式的卷积,它具有空间特定性和通道无关性。同样的,involution算子也具有卷积核,但其卷积核(称为内卷核)产生的方式与传统卷积有所不同。
假设输入特征图尺寸为(1,G,C,H,W)。如果involution模块的stride不为1,则先用avgpool缩小输入特征图。然后,使用两个卷积层,输出通道由C变为kernel_size的平方再乘以G,这里的kernel_size是involution模块的kernel_size。这样就生成了involution算子的内卷核。然后,将内卷核尺寸变为(1,G,kernel_size的平方,H,W)。再将输入特征图通过nn.fold对内卷核进行滑动窗口取值,再reshape为(1,G,C//G,kernel_size的平方,H,W),最后与内卷核进行element wise multiply即可。
根据文章中给出的实验结果,使用该模块构建的RedNet在分类和检测任务上相对于ResNet有精度优势。

值得注意的是,对于同样层数的RedNet和ResNet,RedNet的速度要慢20%左右,但即使拿同样速度的RedNet与ResNet比较,RedNet仍然具有精度优势,如下表所示。ocr
(DBNet)Real-time Scene Text Detection with Differentiable Binarization
论文地址:https://arxiv.org/pdf/1911.08947.pdf
开源代码:https://github.com/MhLiao/DB网络结构:

文章创新点:
backbone采用ResNet18,在stage2、3、4中,将basicblock中的第二个conv换成deformable conv,从消融实验对比来看,涨点明显(见下图,DConv代表使用了deformable conv);

各级特征图上采样后与上一级特征图相加融合,最后concate起来,这种操作较为常见。concate之后得到下采样4倍的特征图F,使用F预测出概率图(probability map,P,代表各像素点是文本的概率)和阈值图(threshold map,T,代表各像素点的阈值),然后,由下面的公式计算出近似二值图(approximate binary map,B)。损失函数如下图:
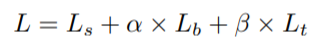
后处理直接使用近似二值图(approximate binary map,B)按照Vatti clipping algorithm扩大成原图大小即可。(PAN++)PAN++: Towards Efficient and Accurate End-to-End Spotting of Arbitrarily-Shaped Text
论文地址:https://arxiv.org/pdf/2105.00405.pdf
开源代码:https://github.com/whai362/pan_pp.pytorch该网络是在前作PAN基础上的改进。网络演进:PSENet->PAN->PAN++,均为同一班作者。
网络结构:
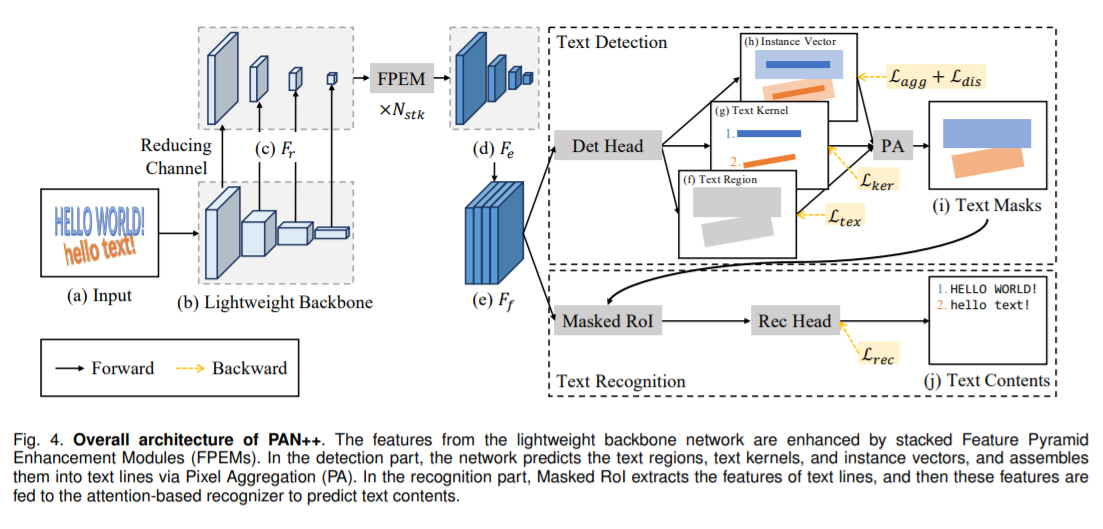
文章创新点:
网络采用了轻量级的backbone ResNet18,并使用堆叠特征金字塔增强模块(FPEM)在backbone之后继续提取特征。如上图所示,ResNet18在stage2、3、4、5输出的特征图各经过一层conv层将通道缩减为128,然后特征图输入FPEM模块。FPEM模块是可以堆叠的,随着堆叠数量的增加,网络感受野逐渐增大。在作者的开源代码中,FPEM的堆叠次数为2。之后,将stage3、4、5特征图全部放大到与stage2特征图一样大小,并concate起来。最后,将特征图输入轻量级检测头,检测头的结构如下:
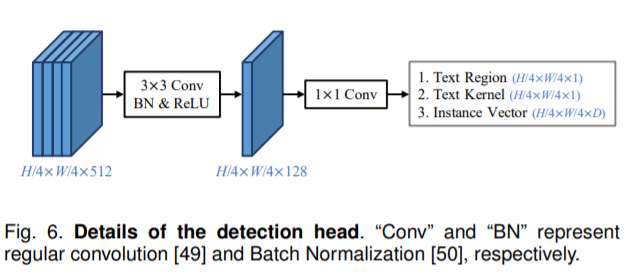
检测头输出特征图再次放大到输入图片大小,检测头同时预测生成文本的区域、文本内核和实例向量,然后通过PA算法融合得到最后的检测结果。该网络的性能非常不错,由于也使用ResNet18作为backbone,该网络的性能可以与DBNet进行比较。两者都在CTW1500数据集上进行了测试,且均使用单张1080Ti显卡进行测试。在PAN++未使用在SynthText上的预训练模型时,在CTW1500上,PAN++ S:512训练后的性能在同样的FPS水平下R和F指标要好于DBNet-ResNet18(DConv+DB);如果使用了SynthText预训练模型,则性能更强。
scene text recognition
基础知识
文本识别是在文本检测模型检出的文本框基础上,利用文本识别网络识别出检测框中的文字。识别文字时,既可以将一行文字先做单个字符切割后分别识别单个字符,也可以不切割单个字符,基于字符串进行识别。
目前文本识别有以下几类方法:
1、seq2seq-based方法,即encoder-decoder,采用CTC或attention的方法,这类方法最为经典,而且不需要字符级别标注,对数据集要求低,后面介绍的主要是这类方法;
2、segmentation-based方法,由于此类方法必须要使用字符级别的标注,对数据集限制很大,考虑到OCR应用场景的广泛性,需要各种场景的数据集,因此对这类方法不做调研;
3、classification-based方法,即将文本识别建模为图像分类任务,这类方法比较少,具有代表性的是CSTR。
4、Transformer类方法,这类方法其实是利用Transformer结构的优势,使用Transformer替代传统的CNN+LSTM那套encoder-decoder结构,大部分属于第一类方法。由于Transformer结构的self-attention层擅长对长依赖状态进行建模,对于形状多变的文本,或中间有个别字符遮挡严重的文本效果很好。学术数据集
一般论文里使用的训练集和测试集(全是英文数据集)介绍。来自该文章:https://arxiv.org/pdf/1904.01906.pdf 。这篇19年的文章对数据集做了统一并进行模型性能比较,后续scene text recognition文章大多数采用该训练集、验证集和测试集。训练集
MJSynth:英文,900万张单词图片,合成数据集;
SynthText:英文,80万张场景图片,约550万单词,合成数据集;验证集(不包括IC03训练集,因为部分与IC13测试集重复)
IIIT:英文,谷歌图像搜索抓取,包含广告牌、海报等,规则文本,2000张训练集用来验证;
SVT:英文,室外街景文本,有一些低分辨率或模糊,规则文本, 257张训练集用于验证;
ICDAR2013:英文,场景文本,规则文本,848张训练集用于验证;
ICDAR2015:英文,用谷歌眼镜在运动状态下获得,不规则文本,4468张训练集用于验证;测试集(不规则文本主要指弯曲、任意旋转或扭曲)
IIIT:英文,谷歌图像搜索抓取,包含广告牌、海报等,规则文本,3000张测试集用于测试;
SVT:英文,室外街景文本,有一些低分辨率或模糊,规则文本, 647张测试集用于测试;
ICDAR2003:英文,场景文本,规则文本,867张测试集用于测试(忽略少于3字符或非字母数字字符单词);
ICDAR2013:英文,场景文本,规则文本,1015张测试集用于测试(忽略非字母数字字符单词);
ICDAR2015:英文,用谷歌眼镜在运动状态下获得,不规则文本,2077张测试集用于测试;
SVT Perspective:英文,谷歌街景文本,非正面视角,不规则文本,645张图片用于测试;
CUTE80:英文,自然场景中收集,不规则文本,288张图像用于测试;标注情况
训练集
MJSynth:都是已经裁剪成单词的图像,高度固定32像素,包括单词标注,此外还有单字符数据集;
SynthText:80万张场景图片,平均每张图十个单词左右,标注了单词框和单词、单个字符框和单字符;验证和测试集
IIIT:英文,单词图片,标注了单词、单个字符框、单个字符;
SVT:英文,场景图片,标注单词框和单词;
ICDAR2003:英文,划分出860张单词图片,标注单词框和单词;
ICDAR2013:英文,划分出1013个单词图片,标注单词框和单词;
ICDAR2015:英文,划分出7548个单词图片,标注单词框和单词;
SVT Perspective:英文,场景图片,标注单词框和单词;
CUTE80:英文,288张单词图片,标注单词框和单词;其他公开数据集
Chinese Text in the Wild(CTW):中文,32285张街景图片,1M个单字符实例,标注单字符框和字符,不注释非中文字符。
ICDAR2017-RCTW-17:中文,手机或相机收集的照片,包括屏幕截图,室外街道、室内场景等,11514训练+1000测试图片,标注中文字符串框和字符串。
Chinese Street View Text Recognition:中文,21万张训练(带标签)+8万测试(不带标签)。训练图片为裁好的单词图片,通过放射变换映射为高度48像素图片,标注字符串,文本水平。
Chinese Document Text Recognition:中文(新闻+文言文),364万张图片,99:1划分训练集和测试集。图像均为10个字符的图片,分辨率固定280x32,文本水平。
ICDAR2019-MLT:10种语言,20000张图。标注单词框和单词。
ICDAR2019-Art:中英文,5603张训练+4563张测试。有四分之一的文本实例形状多变。Art数据集是Total-Text, SCUT-CTW1500、Baidu Curved Scene Text三个数据集的组合。
ICDAR2019-LSVT:中文,45万街景照片,包括2万测试+3万训练全标记数据(字符串框+字符串),40万弱标记数据(只有字符串)。
MTWI:中文,10000训练+10000测试,基本是网络图片。标注字符串框和字符串。
ReCTS:中文,20000张图,街景中的店铺招牌,标注中文词和中文文本行。
Chinese urban license plate dataset:车牌数据集,25万张车牌,标注检测框和车牌号。注意车牌角度不一定是正的。数据在合肥停车场采集,其他省车牌较少。
handwritten Chinese dataset:中文手写体数据集。数据为单字符,包含389万个单字,白底,可组合成大量文本行训练。 白色背景可换其他背景。
NIST19:英文手写体数据集。包含81万个字符图像。
Bank credit card dataset:银行卡数据集。主要是招行卡有618张图,其他卡有50张图。有单字图片。银行卡只有标注文本内容,没有标注框。
ICDAR2019-Art:中英文,5603张训练+4563张测试。有四分之一的文本实例形状多变。Art数据集是Total-Text, SCUT-CTW1500、Baidu Curved Scene Text三个数据集的组合。An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
论文地址:https://arxiv.org/pdf/1507.05717.pdf
第三方Pytorch开源代码:https://github.com/meijieru/crnn.pytorch文章看点
本文即经典的CRNN+CTC文字识别网络。网络从下到上分成三部分:
CNN层,提取特征图;
RNN层,使用双向RNN(BLSTM)学习特征向量,输出预测标签;
转录层,计算CTC损失,把RNN输出的标签转换成最终的标签序列。

CNN输出的特征图需要进行尺寸调整后才能输入RNN层:
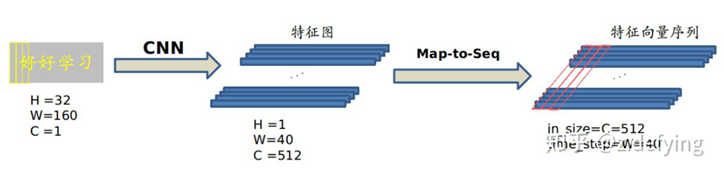
如图所示,CNN输出特征图尺寸为512x1x40,然后按列生成特征向量,每列包含512维特征(图中红框),即第i个向量是所有特征图第i列像素连起来,构成序列。每个向量的感受野对应原图上的一个矩形区域。

RNN层使用的是两层各256个cell的双向LSTM。Time_step设为40。每个time_step输入一个特征向量,输出所有字符的概率分布,即40个长度为字符的类别数的概率向量,然后输入转录层。RNN识别的每个时间步序列的字符之间可能会有重复。CTC使用blank机制解决这个问题,即RNN输出序列时,在文本标签重复的字符直接插入-,被-隔开的相同字符不合并,只合并一个时间步内字符序列的重复字符。比如输出序列为“bbooo-ookk”,则最后将被映射为“book”。
CTC loss
CTCloss的输入为RNN层后softmax层的输出,输入尺寸是time_stepnum_classes,即时间序列长度类别数。这里首先要说明一个假设,即每个时间步的字符相互独立,与上下文无关。用x代表网络的输入,y表示softmax层的输出, ytk表示第t个时间步时,第k个类别上的softmax值。假设字符均为英文,再考虑空格的话,就是一共有27个类别。使用:
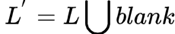
表示字符集合。然后定义一个映射:

表示解码中多对一的映射,比如:
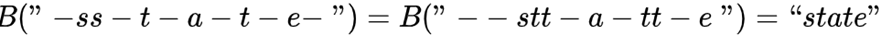
给定输入x,输出路径的概率表示为:

这里应用了上面的假设。比如,若l是映射得到‘state’的路径集合,则:
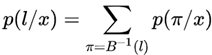
上面的“-ss-t-a-t-e-” 和“–stt-a-tt-e”都属于路径集合。训练时目标是:

我们希望它越大越好,将其取反就可作为损失函数。CTC原理地址:https://zhuanlan.zhihu.com/p/108547594
Robust Scene Text Recognition with Automatic Rectification
论文地址:https://arxiv.org/pdf/1603.03915.pdf
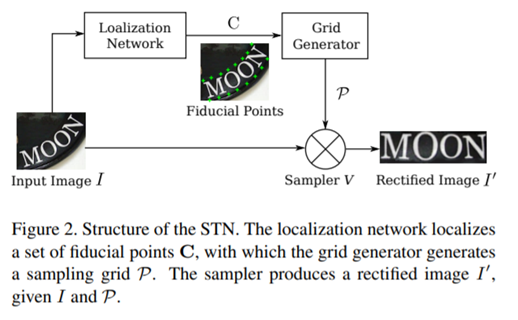
网络结构
网络分成两部分:STN和SRN。主要介绍STN,后面许多网络都有用到。STN用于对输入的不规则文本进行矫正,得到形状规则的文本作为SRN的输入。注意虽然STN可以对文本形状进行矫正,但对于形变特别严重或极度弯曲的文本仍然效果不佳。
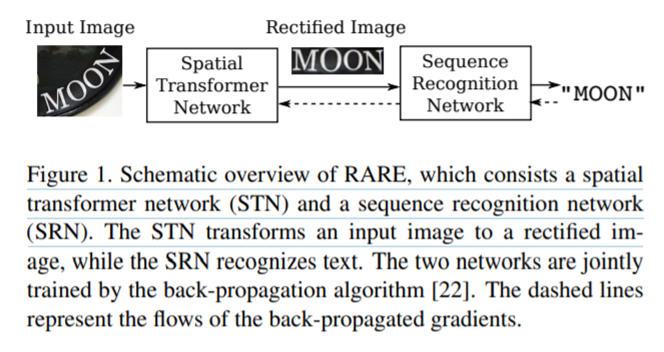
STN包含Localization network、Grid Generator和Sampler。Localization network可在没有标注数据的前提下,定位基准点位置。Grid Generator和Sampler配合使用,Grid generator估计出TPS变换参数,生成一个采样网格。
然后进行变换,给定pi′的坐标,计算出pi的坐标,我们的目的是计算target图像pi’坐标的像素值。先算出pi的坐标后,在sampler中,pi坐标附近像素值已知,通过双线性插值得到pi坐标的像素值。

ASTER: An attentional scene text recognizer with flexible rectification
论文地址:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8395027
网络结构
经典的CNN+RNN+seq2seq文本识别网络。前面的text rectification部分就不说了,用的STN,主要说后面的text recognition部分。网络从下到上,分成encoder和decoder部分。Encoder部分是CNN+BiLSTM模块。decoder部分是LSTM+attention模块。
这是一个seq2seq结构,encoder将输入序列都编码成一个统一的语义向量,decoder再进行解码。解码过程中,不断将前一时刻
t-1的输出作为后一时刻t的输入,循环解码,直到输出停止符为止。

具体来说,将encoder最后时间步的输出特征作为语义向量作为Decoder初始输入,然后开始解码,并不断将前一时刻的decoder
输出作为下一时刻输入解码,直到输出停止符为止。What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis
论文地址:https://arxiv.org/pdf/1904.01906.pdf
开源代码:https://github.com/clovaai/deep-text-recognition-benchmark文章要点
相当于对经典的文本识别算法做了总结对比。发布了一个简单的文本识别框架,包含四种文本识别算法,并做了各种算法下修改各组件后的实验,确定了一个最好的算法:TRBA(TPS-ResNet-BiLSTM-Attention)。提出了场景文本识别的四阶段范式:
1、变换,使用STN网络norm输入文本图像;
2、特征提取,输入图像映射到关注字符识别相关的属性表示;
3、序列建模,捕获字符序列的上下文信息,使预测更加准确;
4、预测,根据图像特征预测输出字符序列。之前的工作其训练和测试设置不一致,不能公平比较。所以统一使用MJSynth和Synth Text数据集用于训练,两者均为合成数据集。
常用于测试的七个数据集:
1、IIIT5K-Words:Google图像搜索中抓取,包含广告牌、门牌号、海报等;
2、Street View Text (SVT):室外街景文本,有许多分辨率低或者模糊;
3、ICDAR2003:ICDAR2003比赛数据集;
4、ICDAR2013:ICDAR2013比赛数据集,继承了ICDAR2003大部分图像;
5、ICDAR2015:ICDAR2015比赛数据集,人使用谷歌眼镜在场景中自然运动下获得;
6、SVT Perspective:谷歌街景中收集,非正面视角多,包含透视投影;
7、CUTE80:自然场景中收集,弯曲文本较多;首先将输入图像变换为标准形状的图像(尤其是弯曲和倾斜的文本图像),这步使用STN网络。然后使用CNN网络提取特征。再对特征重新reshape作为序列向量,输入序列建模网络,比如双向LSTM(BiLSTM)。然后,预测字符输出,可以使用CTC或者Attention方法。

各个模块组合后的精度与时间表和精度与参数表。加粗的表示是最有优势的模块。

提出了一个精度最高,且时间和内存方面均有优势的网络TRBA (TPS-ResNet-BiLSTM-Attn)。训练阶段区分大小写,测试时不区分大小写。Bad case分析
考虑24个模型没有一个识别对的644个图像。书法字体:比较飘逸的那种字体,比如品牌字体,街道上的商店名字(这种字体使用DCNv2应当可以改善性能);
垂直文本:由于模型结构处理都采用水平文本的方式考虑,未涵盖垂直文本;
特殊字符:因为当前测试集不测试特殊字符,所以训练时也没训练这些数据。使用特殊字符训练后特殊字符性能大大改善;
文本中间有遮挡:当前的方法没有充分利用上下文信息,所以对这类文本识别率不高;
低分辨率图像:使用超分模块或FPN可能提高对此类图像的识别;
标签噪音:七个测试集不考虑特殊字符错误率1.3%,考虑特殊字符6.1%,考虑区分大小写错误率24.1%。

Revisiting Classification Perspective on Scene Text Recognition文章地址: https://arxiv.org/pdf/2102.10884.pdf
作者知乎文章:https://zhuanlan.zhihu.com/p/352348349
官方源码:https://github.com/Media-Smart/vedastr/tree/cstr
其他文章: https://zhuanlan.zhihu.com/p/368778777文章要点
文本识别目前有两大类方法:seq2seq-based方法和segmentation-based方法。过去达到SOTA的文字识别方法大部分是seq2seq-based方法,但这类方法的流程比较复杂,大部分需要STN网络先进行文本矫正。Segmentation-based方法比较简洁,但需要字符级别的标注,对数据集限制很大。作者又提出了一类classification-based方法,将文本识别任务建模为图像分类任务,创造了CSTR网络,该网络性能全面超越DAN,而且不需要STN网络,也不需要字符级别的标注。
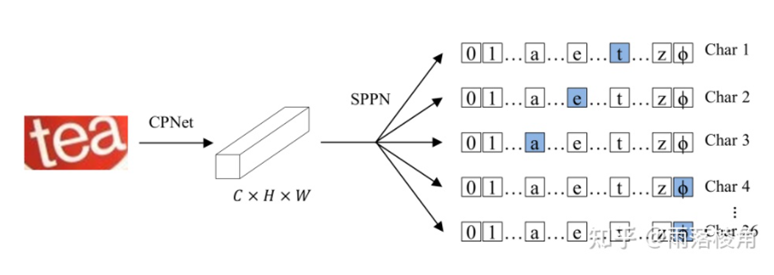
网络结构十分简单,是ResNet+CBAM+non-local2d+FPN。测试了三种head头,最后发现SPPN最好。


缺点
最后的分类fc层的设置。根据开源代码,分类fc层数量与文本最大长度一样,比如最大长度150的文本,需要150个fc层,每层参数为512x字符类别数。如果字符里有中文,那么类别数至少上千类。Fc层是否可以在文本长度上共享?我认为是可以的,但是作者没有这么做,可能是文章里数据集都是英文+数字,只有三十几类,而且测试的都是单词,所以影响不大?On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention
文章地址:https://arxiv.org/pdf/1910.04396.pdf
第三方开源代码: https://github.com/chibohe/text_recognition_toolbox
第三方开源代码: https://github.com/Media-Smart/vedastr (small-SATRN)网络结构
通过shallow CNN得到的特征图和adaptive 2D positionalEncoding一起输入encoder模块。文中说Transformer的 Position Encoding模块可能在视觉任务中不work,但位置信息很重要,因此作者提出了如下的方法:

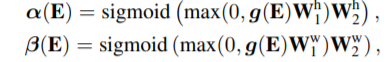
α和β直接影响高度和宽度位置编码,以控制水平轴和垂直轴之间的相对比率,以表达空间分集。通过学习从输入推断出α和β,
adaptive 2D positional Encoding允许模型沿高度和宽度方向调整长度元素。作者认为Self-attention 层本身擅长对长期依赖进行建模,但不能充分关注局部结构。因此将原始的pointwise feedforward layer改为Locality-aware feedforwar,使用两个1x1卷积和
一个3x3卷积。

What If We Only Use Real Datasets for Scene Text Recognition?Toward Scene Text Recognition With Fewer Labels
文章地址:https://arxiv.org/pdf/2103.04400v2.pdf
开源代码: https://github.com/ku21fan/STR-Fewer-Labels文章看点
这是一篇组合分析型的文章,文章主要比较CRNN和TRBA两种经典网络,通过一系列组合式实验得到了以下结论:
1、真实数据与合成数据对模型性能的影响:在2019年,当真实数据达到276k张图像时,只使用真实数据训练的CRNN和TRBA模型性能已经与合成数据训练出的模型性能十分接近,这说明只靠真实数据已经足以训练出令人满意的模型;
2、我们大概需要146k到276k张真实图像训练模型,但是训练集的多样性比数量更加重要,不能简单地认为276k图像就够了(这与TRBA那篇文章结论一致)。因此本文使用了11种真实图像数据集一起训练;
3、仅使用1.74%的合成图像进行训练,大约277k张,与真实图像数量相近,模型性能大概比真实图像训练结果低10%,即真实图像要更加重要;
4、合成数据集由于本身已经用了数据增强,因此训练时不宜再用数据增强,这样会掉点。但是如果是真实图像,可以再用数据增强,能够小幅度涨点;
5、Pseudo-Label和Mean Teacher两种半监督方式,前者对CRNN和TRBA都可以涨点,后者对CRNN和TRBA都掉点;
6、使用RotNet和MoCo两种自监督方式预训练TPS和ResNet,发现掉点非常严重,于是只预训练ResNet。使用RotNet时,对CRNN和TRBA均有小幅度涨点;使用MoCo时,CRNN小幅度涨点,TRBA小幅度掉点。这篇文章最大的意义在于证明文章种列举的11个真实标注数据集的数据量已经足以充分训练文本识别模型。另外,对于半监督和对比学习的自监督方法,在文本识别模型上效果不是很明显。开源代码中提供CRNN和TRBA预训练模型。
transformer
基础知识
论文:Attention Is All You Need
论文地址: https://arxiv.org/pdf/1706.03762.pdfTransformer的核心是attention模块,而attention模块的核心是计算相关性。Transformer中attention计算公式:
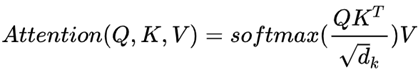
QKV为三个输入向量,其中KV是对相同token的不同描述,Q可能是相关token的描述,也可能是不同token的描述。根号dk用于归一化。这个公式对应的结构叫scaled Dot-Product Attention。若KV是对token2的描述,Q是对token1的描述,则相当于用Q和K向量的相关性对V加权,获取对token2的新描述。
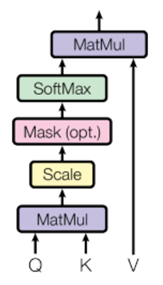
单个的scaled Dot-Product Attention只能描述一种特征空间下Q和V的相关性,将多个scaled Dot-Product Attention并行,再将它们最后输出的特征Concate起来,也就是多个特征空间共同计算相关性,这样就形成了Multi-Head Attention结构。这是Transformer中的基础模块。

Transformer的典型结构如下图。其中Feed Forward是多个全连接层。左半部是encoder部分,其由若干个multi-head-attention+feed-forward+layernorm组成的基本block组成。不使用BN的原因是输入样本的原始长度可能不一致,训练时padding到同一长度,但样本越是最后的部分其Padding的可能性越高,这会影响BN学习。由于RNN/LSTM按时间序列接受输入,隐含了token的先后次序关系。但transformer结构是并行输入,因此需要额外的Positional Encoding嵌入token位置信息。右半部分是decoder,其结构与encoder类似,但输入有变化,Q来自Decoder,K和V来自encoder,用于计算当前时刻输出和其他输入的相关性。

视觉任务中如何使用Transformer?
由于图像不像文字天然是序列,图像需要划分成许多小的区块,并提供Positional Encoding位置信息后再一起输入encoder。关于这一操作,详细可看ViT论文。之后的处理部分则完全相同。(ViT)AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
论文地址:https://arxiv.org/pdf/2010.11929.pdf
官方开源代码:https://github.com/google-research/vision_transformer
第三方Pytorch开源代码:https://github.com/lucidrains/vit-pytorch本文即第一个将Transformer应用于分类任务上的网络ViT。
网络结构:

文章创新点:
和一般的CNN网络不同,ViT的输入图像被划分成若干个PxP大小的块,块的数量就是输入序列的长度。通过线性变换,得到Patch embedding,然后输入Transformer结构,注意这里的Transformer只有Encoder部分。通过encoder可提取出特征,再经过全连接层就可以分类了。除了patch embedding之外,模型还需要Positional embedding来编码token的位置信息。ViT中采用1D的positional embedding,在输入encoder前将patch embedding和positional embedding相加。之所以采用1D的positional embedding,是因为不同类型的positional embedding对性能影响都差不多。

作者在ImageNet-1k、ImageNet-21k等数据集上做了实验。ImageNet-21K数据集的数据量是ImageNet-1K的11倍左右。在ImageNet-1k这样较小规模的数据集上,ViT的性能比ResNet差,但是在更大规模的ImageNet-21K数据集上,ViT的性能要好于ResNet。在大规模数据集上训练的ViT在相对小的数据集上具有很好的迁移能力。Early Convolutions Help Transformers See Better
论文地址:https://arxiv.org/pdf/2106.14881.pdf
文章创新点:
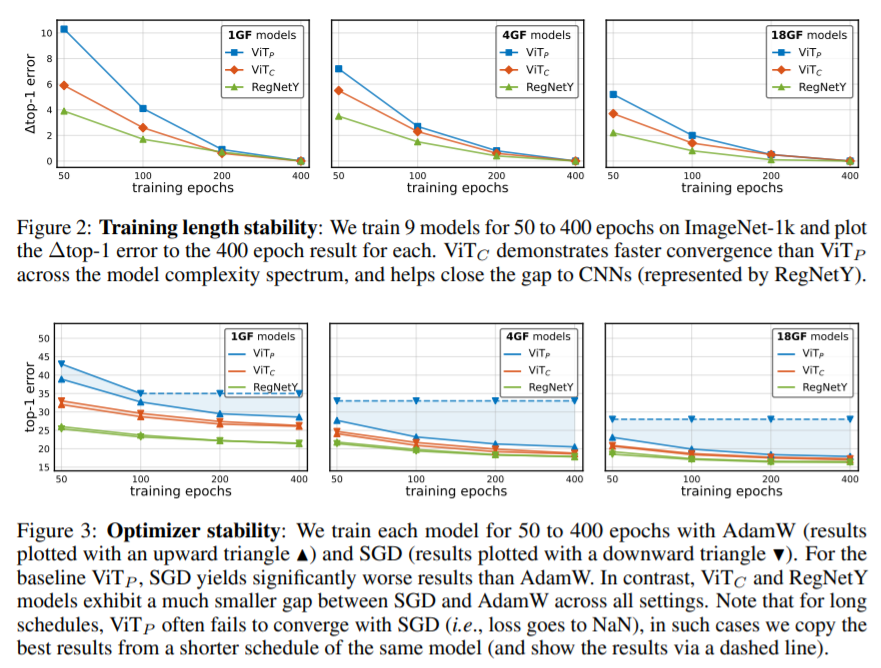
这是一篇分析型的文章。像ViT这类网络的可优化性没有CNN网络那么好,通常它们对优化器(adamw和SGD)、超参数和epoch数都很敏感。比如,使用SGD训练的ViT网络要比使用AdamW训练的ViT网络性能下降几个点。本文提出了一个观点,即在Transformer结构前,使用conv steam替换patchify stem,只需大约5个conv层就可以让ViT网络能够使用SGD优化器进行优化,其精度和使用AdamW时相比不会有明显差距,且对学习率和weight decay变得不那么敏感,训练收敛速度加快。
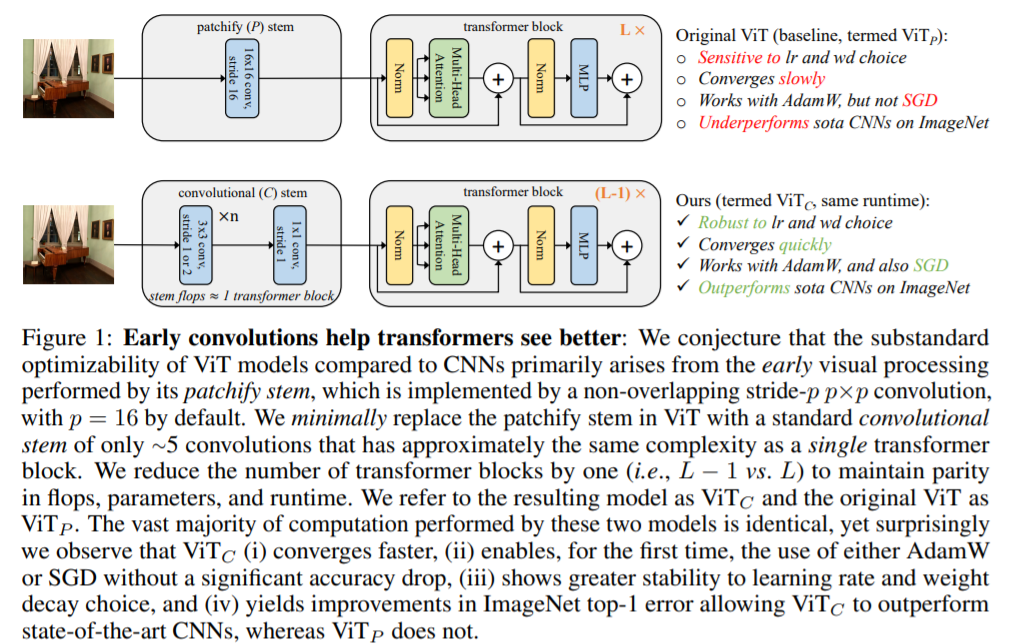
作者用ViTp代表原始的ViT网络,用ViTc代表使用conv stem的ViT网络。为了与原来维度对齐,conv stem使用3x3卷积下采样到14x14。使用4个3x3,stride=2的卷积和一个1x1卷积。此时conv stem输出与原来的patchify stem输出维度一致。同时,作者修改了conv stem通道数,使得conv stem flops约等于一个Transformer的block,然后在后面减掉一个Transformer block,使ViTc与ViTp的flops基本一致。

实验结果表明ViTc相比于ViTp收敛的更快,且在使用SGD优化器时与使用AdamW优化器时的性能差距很小,可优化性变好了。
visualization
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
论文地址:https://arxiv.org/pdf/1610.02391.pdf
开源代码:https://github.com/ramprs/grad-cam/
第三方pytorch开源代码:https://github.com/jacobgil/pytorch-grad-cam本文介绍了一种对专门对分类模型使用的可视化解释工具。该工具针对一个分类模型对具体的一张测试图片输出的某一个类的具体概率值可画出一张类激活热力图。该图片是类别相关的,对于同一张图预测的不同类的概率值,其类激活热力图不同。该工具使用时不需要对原模型进行结构修改,十分方便。
类激活热力图的计算方法:
首先计算某类预测的概率值对模型最后一层卷积层输出的特征图上所有像素的偏导数;
求出偏导数后,将它们在hw维度上做一次全局平均,得到akc即c类相对于最后一层卷积层输出特征图的第k个通道的敏感程度;

akc作为权重与最后一层特征图做加权乘法,再经过relu函数处理输出,得到最后的CAM图,将图resize到原图大小,叠加显示即可;

加relu的原因是如果特征图通过加权某个位置是负值,那么该位置更可能与c类以外的类相关。论文效果图:

见图f和l。对同一张图片的猫类和狗类预测值画出的CAM图是不同的。Grad-CAM++: Generalized Gradient-based Visual Explanations for Deep Convolutional Networks
论文地址:https://arxiv.org/pdf/1710.11063.pdf
第三方pytorch开源代码:https://github.com/jacobgil/pytorch-grad-cam本文提出的Grad-CAM++工具是对Grad-CAM的改进。grad-cam通过求某一类预测值在最后一层特征图上的梯度图再求平均获取每个通道的权重,也就是说,对于特征图每个通道上的每个位置其权重认为是一样的。这样就会带来一个问题,当图中有多个同类物体时,它只能定位到多个同类物体上的某一部分。Grad-CAM++认为特征图上每个元素的贡献不同,因此额外增加了位置权重进行加权,解决了上面的问题。
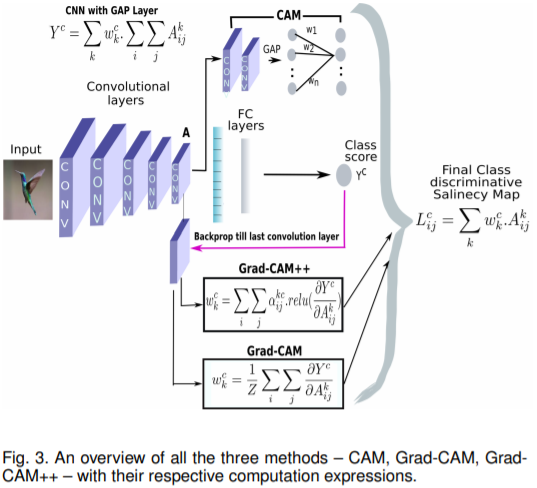
三种方法的对比见上图。Grad-CAM++求像素级平均加权值wkc公式如下:
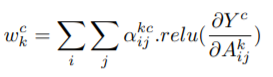
其中akcij是c类与特征图akij上各像素点梯度的加权系数,公式如下:
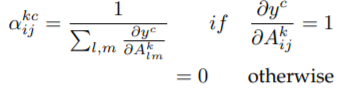
接下来,作者进行了一系列推导,最后得到akcij和wkc公式如下:


在一张图出现多个同类目标时,Grad-CAM++比Grad-CAM显示的定位更加精准。论文中给出了Grad-CAM++和Grad-CAM的效果对比:

contrastive learning
Self-Supervised Learning基本知识
Ankesh Anand博客:https://ankeshanand.com/blog/2020/01/26/contrative-self-supervised-learning.html
自监督学习,即不需要人工标注的类别标签信息,直接将数据本身作为监督信息,来学习数据的特征表达,并用于任务中。当前,自监督学习可分为两大类方法:生成式方法和对比式方法。
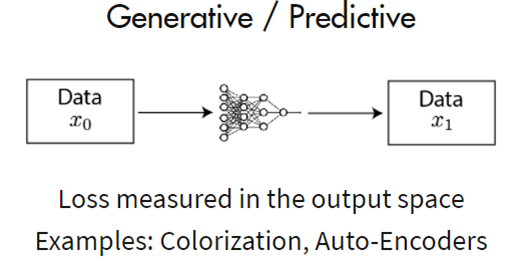
Generative Methods(生成式方法)
如GAN这类网络,网络对数据样本先encode再decode,如果decode效果较好则认为网络学到了比较好的特征表达。
Contrastive Methods(对比式方法)
将数据样本按照某种规则分为正样本和负样本,网络学习这两类样本在特征空间上的区别,通过这种方法学习数据的特征表达。该方法的关键点在于如何构造正负样本。相比于生成式方法,该方法不需要对每个像素细节进行重构来学习特征表达,而只需要在特征空间上学习不同样本的区分性。因此,其优化相对要简单一些。

对比式方法具体是如何让模型f学习到特征的呢?对于输入数据x,模型f的优化目标为:

其中x+是一个与x相似的正样本,而x-是一个与x不相似的负样本。score函数则是度量两个输入之间是否相似的标准。x被称为锚数据点,为了进行优化,构建一个能够正确区分正负样本的softmax分类器。这个分类器应该为正样本分配大的值,而对负样本分配小的值。分母项为正数。包含一个正样本和N-1个负样本,使用点乘作为score函数。

这叫做infoNCE损失。当样本中只有一个正例,其他均为负例时,这个公式就是softmax函数。最小化infoNCE损失会最大化f(x)和f(x+)之间互信息的下限。互信息是评价两个随机变量之间的依赖程度的一个度量。具体来说,对于两个随机变量,互信息是在获得一个随机变量的信息之后,观察另一个随机变量所获得的“信息量”。当互信息最大,可以认为从数据集中拟合出来的随机变量的概率分布与真实分布相同。
InfoNCE损失可以进一步推导分为两部分,alignment和uniformity。alignment部分只跟正样本对有关,将正样本对的特征拉近;uniformity部分只与负样本对有关,将所有负样本点的特征尽可能均匀分布在单位超球面空间上。关于这一点,有一篇paper做了研究:Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere。
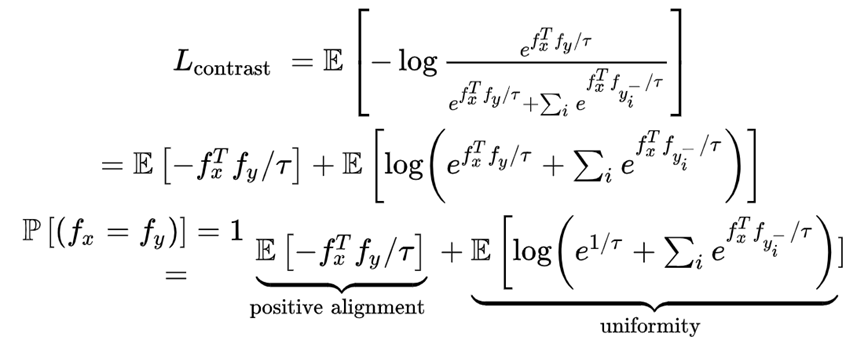
作者在CIFAR-10上对Random Initialization、Supervised Predictive Learning和Unsupervised Contrastive Learning三种模型进行实验,结论如下图:

其中,对alignment的分析计算正样本对特征之间距离的分布;对Uniformity的分析则使用高斯核密度估计在von Mises-Fisher在角度上的分布,最右边的四张图展示了特定类的特征分布。可以看到Random Initialization在uniformity上没有将不同类别的特征均匀分开,虽然alignment的平均距离很小,但模型判别能力很差;Supervised Predictive Learning因为有人工标注,在alignment上平均距离很小,uniformity上相对Random Initialization分的均匀的多,但因为引入了标注偏见,导致alignment的平均距离介于Random Initialization和Unsupervised Contrastive Learning之间;Unsupervised Contrastive Learning在alignment上的平均距离最小,而且在uniformity上均匀连续的散开,说明Unsupervised Contrastive Learning得到了最具判别力的特征。alignment和uniformity两部分缺一不可,如果uniformity没有alignment,模型缺少聚类能力;如果如何只有alignment没有uniformity,则模型的所有输入的输出表示容易趋同,形成退化解。
为什么无监督的对比式方法作为pretrained模型只需要很少的有标签数据就可以超越完全由有标签数据训练的同结构模型?
在某种意义上,对比式方法实际上是在学习一个具有这样特性的超球面特征空间:对于比较相似的一对图像(比如同类别的图像),其特征在该特征空间上距离很小;而对于不太相似的一对图像(比如非同类别图像),其特征在该特征空间上距离就比较远。对于整个数据集的图像,其在特征空间上呈现局部聚集,总体平均的状态,即比较像的图像距离都比较近,在特征空间上挨在一起;而不太像的图像在特征空间上距离就比较远。
随机初始化时,获得的特征空间非常平均,但相似的图像其特征没有聚集在一起;全部使用有标签数据训练模型时,由于标签是统一的,同一类图像其one-hot标签全部为1,相当于我们先验地认为同类图像在特征空间上都在同一点,但其实同一类内图像也是有差别的,比如一个标注为人的图像,其背景中可能会照进来一辆车,和一张只有人的图像相比会有差异,在特征空间上也不应该重合在一个点上,但人工标签引入了这种偏见;使用无监督的对比学习方法时,可以认为我们觉得各个图像都在特征空间上占据一个点,但点与点之间的距离通过与正样本和负样本距离的不断比较在特征空间上进行调整,这种调整的依据是图像本身内容上的区别,就不会存在人工标签引入的偏见,因此它训练得到的模型其特征空间呈现局部聚集,全局平均的状态,这时只需要很少的有标签数据学习,当前于为每个局部聚集的group找到其真实的标签即可让模型具有分类能力,故它fine-tune后的模型分类能力反而比全部由有标签数据训练的模型要高。
Momentum Contrast for Unsupervised Visual Representation Learning(MoCov1)
论文地址:https://arxiv.org/pdf/1911.05722.pdf
官方开源代码:https://github.com/facebookresearch/moco文章创新点:
对比学习,就是自监督学习一个encoder,对于任意一个输入样本x,在一个大的字典中,最小化与其相似的样本x+距离,最大化与其不相似的样本x-距离。对于这个字典,传统的方法是字典空间就是mini-batch(如triplet loss), 但是这样字典空间存在限制,不能太大。MoCo使用了队列存储这个字典。训练时,当一个新的batch样本编码后进入队列,队列中最先进入的编码出队列(先进先出)。这样,字典的大小就与batch大小无关,可以自由设置。也就是从下图a变为图b。

但是,图b结构也存在问题,即队列中存储的特征是上几轮迭代时的网络计算出来的,而网络在训练时会更新权重,这样就会出现输入特征和队列中特征不是同一轮迭代时的网络计算出来的情况。为了解决这种不一致的问题,MoCo采用了图c的结构,引入Momentum encoder让队列中特征差异变小,也就是让特征更平滑。即encoder和momentum encoder结构一样,但是参数不一样,encoder参数为当前迭代轮次的模型参数,而momentum encoder的参数为按动量更新的当前轮次与历史轮次模型参数计算后的混合。(同样的网络结构,训练时有两份参数在更新)训练过程:
开始时对两个encoder进行初始化,网络结构是一样的,初始化参数也一样,只是复制成两份;然后取一个batch的样本,做两次数据增强得到xq和xk。xq通过encoder得到特征q,xk通过momentum encoder得到特征k,计算qk乘积和q与队列中其他特征乘积,然后计算infoNCE损失,通过反向传播分别更新encoder和momentum encoder。然后特征k进入队列,遵循先进先出原则一部分特征出队列。

A Simple Framework for Contrastive Learning of Visual Representations(SimCLRv1)
论文地址:https://arxiv.org/pdf/2002.05709.pdf
官方开源代码:https://github.com/google-research/simclr (基于TF2)
第三方Pytorch实现代码:https://github.com/sthalles/SimCLR文章创新点:
多种数据增强方式的组合(3种)对对比学习非常重要;
研究发现encoder输出的特征会保留与数据增强方法相关的信息,在encoder之后加入projection head,这是两层非线性变换层,将特征从2048维压缩到128维,可以去掉这些信息。再利用128维特征计算NT-xent loss,训练完成后,抛弃projection head;
对128维特征做归一化并适当调整学习超参数会获得更好的学习效果;
在训练较少的epoch时,使用更大的batchsize更有利于训练。当训练较多的epoch时,大batch与小batch时模型的性能会越来越接近。这是因为较大的batch和较多的epoch均可以提供更多的负样本;网络结构与训练方式:
将原图经过不同数据增强得到两张数据增强后的图xi和xj,输入encoder和projection head,注意encoder和Projection head都是共享参数的。得到zi和zj后计算NT-Xent loss。自监督训练完成后抛弃projection Head。

Loss计算:
首先,获取每个batch的特征后,使用余弦相似度度量xi、xj,相似度定义为:

显然,成对图像的相似度会很高,而不一样的原图得到的相似度会比较低。再对batch中的每对图像用softmax函数计算两个图像相似的概率,此时剩余的2(N-1)个样本均为负样本:
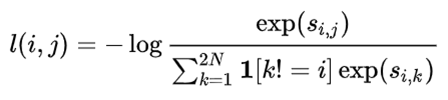
对同一对图像,交换位置后还要再算一次,最后所有对图像损失之后取平均值:
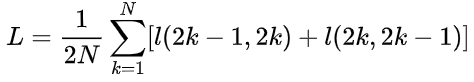
指标解释:
Linear Evaluation:指模型使用自监督学习方法训练完后,去掉projection这部分结构,在encoder之后添加一个全连接层,使用ImageNet数据集全部数据专门训练该全连接层(encoder部分的权重全部frozen),再进行测试得到的accuracy。Label fraction 1%/10%:指的是模型使用自监督学习方法训练完后,去掉projection这部分结构,在encoder之后添加一个全连接层,使用ImageNet数据集1%、10%的标签训练整个网络(这是没有任何层被froozen,网络所有层都在训练更新权重),再进行测试得到的accuracy。
Improved Baselines with Momentum Contrastive Learning(MoCov2)
论文地址:https://arxiv.org/pdf/2003.04297.pdf
官方开源代码:https://github.com/facebookresearch/moco文章创新点:
MoCov2在MoCov1基础上吸收了simCLRv1提出了projection head和更多数据增强的思想,达到了在分类和检测任务上更好的迁移学习效果;
与SimCLR相比,MoCov2不需要大的4k-8k的batch,batch=256,可以在典型的8卡GPU服务器上训练,文中给出了在8 V100 16G服务器上训练200个epoch的时间为53小时;Big Self-Supervised Models are Strong Semi-Supervised Learners(SimCLRv2)
论文地址:https://arxiv.org/pdf/2006.10029.pdf
官方开源代码: https://github.com/google-research/simclr (基于TF2)文章创新点:
自监督学习出的模型可以作为一个其他下游任务的预训练模型,由于训练数据不需要标注,数据成本很低。训练好预训练模型后,只需使用下游任务少量带标签的数据集做fine-tune,就可以达到很好的效果。本文结论:
更大的自监督模型在下游任务使用更少标签的数据做fine-tune效果更好;
独异于具体的某个下游任务,大模型可能结构太大显得多余,可以蒸馏一个小的模型;
使用了更深的3层mlp的projection head,且在迁移下游任务时保留第一层;
参考MoCo使用队列;网络训练具体步骤:
首先使用自监督学习训练encoder,然后使用少量有标签数据fine-tune模型,最后使用无标签数据(或结合少量有标签数据)蒸馏一个更小的encoder。An Empirical Study of Training Self-Supervised Vision Transformers(MoCov3)
论文地址:https://arxiv.org/pdf/2104.02057.pdf
官方还未放出开源代码。文章创新点:
使用ViT作为backbone来进行自监督学习;
ViT的不稳定性是影响自监督训练的主要问题;
移除ViT中的position embedding仅造成了轻微性能下降,这意味着自监督的ViT不需要位置信息就可以学习很强的特征表达;
仍然使用infoNCE损失,但移除了队列,而使用大的batch;Bootstrap Your Own Latent A New Approach to Self-Supervised Learning(BYOL)
论文地址:https://arxiv.org/pdf/2006.07733.pdf
官方开源代码:https://github.com/deepmind/deepmind-research/tree/master/byol文章创新点:
只使用正样本对,不需要使用负样本对;
对不同的batch大小和数据增强方式鲁棒性更强;网络结构:
网络分为online部分和target部分。Online部分包括encoder,projector和predictor(一层或两层fc),target部分则没有Predictor。Online部分的参数用一般的优化器更新,而target部分的参数则采用指数移动平均更新。Oneline网络的predictor预测target网络得到的 (注意做了L2 norm),这样loss就是一个回归loss。
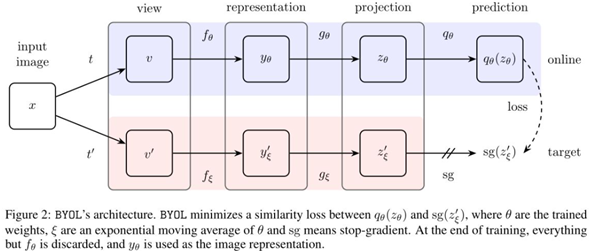
如何避免退化解?
BYOL使用以下几种方式避免退化解:
Target网络部分使用ema的方式根据online部分进行参数更新,这种更新方式变化不太剧烈,能够保持特征均匀分开的特性(初始化时均匀分开了);
Online部分最后多加一个predictor,之后的输出才与target输出做匹配,这样相当于predictor提供了缓冲,因为target部分没有predictor,不会把这部分参数更新到target部分;
特征在计算MSE loss前做了L2 norm,可防止loss使特征的scale学习到接近0;
Projection部分加入了BN,由于BN的均值和标准差与每张图都有关,因此从uniformity角度来说,BN会把不同样本特征分散开。Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning
论文地址:https://arxiv.org/pdf/2011.10043.pdf
官方开源代码:https://github.com/zdaxie/PixPro文章创新点:
第一个在pixel级别做对比学习的文章。由于是在pixel级别做对比学习,相比于Moco、SimCLR这些在instance级别做对比学习的方法,在目标检测和分割下游任务上fine-tune效果更好,而instance级别做对比学习的方法在分类下游任务上效果更好;作者以FCOS举例,对比学习时可以加上FPN和head结构,也就是说这些部分也可以一块儿来做对比学习,下游任务上效果比只用ResNet50做对比学习效果好。
网络结构:
X与x’之前是Mocov2的结构,x与x‘可用于计算本文提出的pixcontrast loss。X之后接PPM模块(这个跟attention里的non local模块很像)得到y来计算PixPro loss。PixContrast loss只尽可能区分每个像素的不同,使得学习的特征具有很强的空间敏感性,利于分割任务中边缘的识别。但是,特征的空间平滑性也很重要,这有利于物体内部部分的识别。为了学习特征的空间平滑性,提出了PixPro loss。先通过PPM模块通过传播类似像素的特征,让特征相似的像素之间做信息平均,起到一定的平滑作用。然后使用PixPro loss学习像素间的一致性,不学习负样本对。

PPM模块:
xi代表图片中的任意一个像素点,yi代表计算出的xi的平滑度, s()代表余弦相似度的计算,g()代表非线性变换,比如BN+RELU。先分别计算当前像素点(x)和周围其他像素点的相似度以及非线性变换的值,再将两个值相乘得到平滑度,最后再迫使另一张正样本学习对应像素点的平滑度。


Pixel Contrast loss:
i,j是两张特征图上同位置的两个像素,dist(i,j)是表示归一化距离,T是阈值,设为T=0.7。

Loss公式如下:
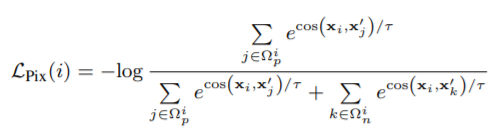
i是在第一张和第二张特征图上均存在的像素(因为有random crop,有的像素只存在于一张图上), 是第二章特征图上对于像素i的正样本和负样本, 是在两张特征图上该像素的特征向量,T是超参数,T=0.3。所有在两张特征图交集上的像素的损失取平均值。对于一个batch的损失,所有图像对的损失取平均值。
PixPro loss:
Loss公式如下:
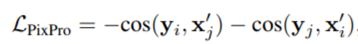
i,j为来自两张特征图的正样本对,xi和yj是像素的特征向量。Loss先对一张图像所有正样本对做平均,然后对所有图像做平均。
该loss与实例级的contrast loss一起使用效果更好(这里指检测和分割任务),因为像素级的contrast loss适合空间推理(比如检测框回归),而实例级contrast loss学习的特征表示适合分类任务。
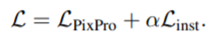
Understanding Self-Supervised Learning Dynamics without Contrastive Pairs
论文地址:https://arxiv.org/pdf/2102.06810.pdf
官方开源代码:https://github.com/facebookresearch/luckmatters/tree/master/ssl
作者知乎专栏:https://zhuanlan.zhihu.com/p/372521032文章创新点
本文过于硬核,有很多细节部分没看懂。作者主要是想分析为什么像BYOL和SimSiam这样的无负样本对对比学习不会收敛到一个平凡解。于是作者搭建了下面一个最简单的全线性结构:
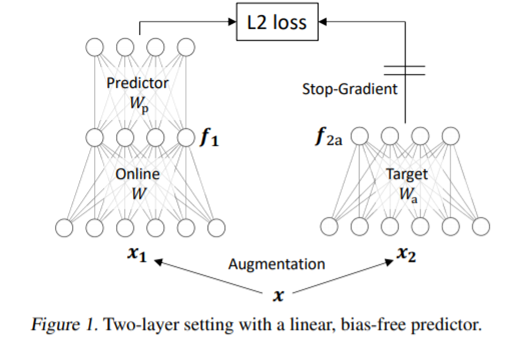 结构两边都是全线性的,左边多一层predictor,右边Target部分梯度不反传。之前的对比学习文章证明这两点对对比学习不崩溃至关重要。模型目标函数为左边:
结构两边都是全线性的,左边多一层predictor,右边Target部分梯度不反传。之前的对比学习文章证明这两点对对比学习不崩溃至关重要。模型目标函数为左边:
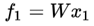
右边:
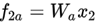
注意右边不参与梯度更新。左边经过predictor映射:

我们的目标是使两个表示向量的欧式距离最小化:
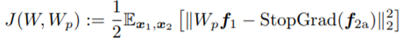
然后可以对权重W求偏导:

注意αp是predictor的学习率, η是权重衰减率(weight decay),β是指数衰减移动平均(EMA)的速率。如果没有梯度不能反传这个条件,那么这个J方程会立刻让权重W收敛到平凡解。
然后,文章又提出了三个假设:
假设1:假设输入向量p(x)为零均值分布,协方差矩阵为单位矩阵。数据增强后的向量服从均值x分布,协方差矩阵为同方差;
假设2:成比例的EMA,假设Target部分的参数在更新过程中永远是Online网络权重的一部分:
假设3:Predictor的网络权重Wp是对称的。基于三个假设,可对上面的方程进一步解耦。
基于假设1,可得:

基于假设2,可得:

基于假设3,可得:

解耦后的动力学方程如下:

基于上面的方程,对αp,η,β进行分析,列举了十种对比学习中的常见设置,并进行实验,实验结果表明基于该方程的分析与实验结果一致。但需要注意的是,作者实验时使用的是非线性网络ResNet18,但结论依然与理论分析一致。
1、大学习率的predictor时有利的;
2、学习率不能无限大;
3、weight decay是有利的;
4、EMA速率较大时,容易导致崩溃;
5、太强的weight decay情况下崩溃不可避免;
6、predictor较大的学习率可以提高学习的上限;
7、增加权重衰减也可以达到6的效果;
8、EMA是有利的;
9、缓慢的EMA会导致漫长的训练过程总结:

image super resolution
基本知识
PSNR(峰值信噪比)
对两个两个m×n单色图像I和K,I为无噪声原始图像,K为I的噪声近似图像(如压缩后的图像),它们的均方误差定义为:
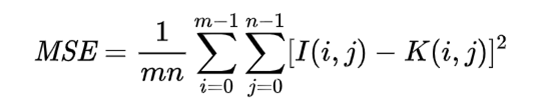
则PSNR定义为:
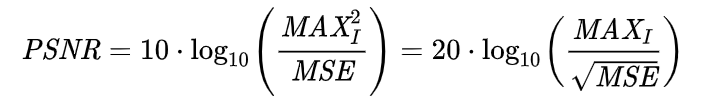
MAXI是表示图像点颜色的最大数值,如8位表示就是255。
对于RGB彩色图像,需要对3个通道每个通道计算MSE,然后除以3才是最终的MSE。其PSNR定义为:

该指标越大越好。SSIM(结构相似性)
用来衡量两张图像相似程度的指标,可用于衡量图片的质量。其中一张图像为无失真的图像,另一张为失真后的图像。给定两张图像x和y,其SSIM定义为:
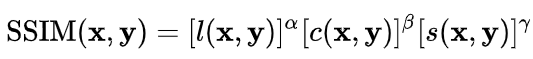
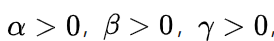
SSIM从三个维度比较两张图像:亮度l(x,y),对比度c(x,y),结构s(x,y)。它们的定义为:

实际使用时,一般会将参数设为:
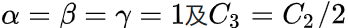
简化后SSIM定义为:

实际计算SSIM时,由于在整张图跨度上均值和方差的变化都很剧烈,而图像上不同区域的失真程度也不一样。故计算时使用步长为1、NXN大小的滑窗,计算两张图像每个滑窗内的SSIM,然后取平均值作为两张图最终的SSIM。计算每个滑窗内的均值、方差、协方差时,一般会采用高斯核做加权平均。如果像素xi对应的高斯核权重为wi,则加权均值,方差,协方差的公式为:
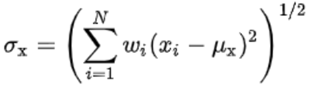

假设整张图像共有M个滑窗,则最终的MSSIM定义为:

SSIM的阈值范围是0到1,这个指标的值越大越好。当两张图像完全相同时,SSIM的值为1。
超分训练集和测试集
训练集
DIV2K:https://data.vision.ee.ethz.ch/cvl/DIV2K/
数据集有1000张2K图片,其中800张属于train集,100张属于valid集,100张属于test集(没有找到下载地址)。train集和valid集均包含x2/x3/x4/x8下采样图片。训练时仅采用其中的训练集。Flickr2K: http://cv.snu.ac.kr/research/EDSR/Flickr2K.tar
数据集有2650张图片,全部属于train集。Train集包含x2/x3/x4下采样图片。测试集
测试集包含五个数据集:DIV2K的valid集、set5、set14、BSD100、Urban100。超分网络类型
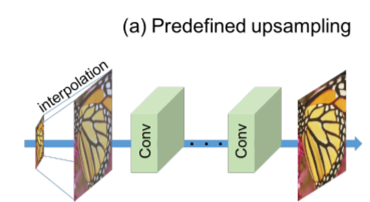
1、predefined upsampling SR,即先用传统上采样方法得到粗糙的HR,再用几层神经网络填充细节。
2、single-upsampling SR,即后置上采样,在模型最后增加一个可学习的上采样层,但这样上采样倍数被固定了。如FSRCNN。

3、progressive-upsampling SR,即在模型后端设置多个上采样层,每个上采样层放大一定的倍数,再被后面的CNN层补充细节,这样解决了多尺度SR的问题,但模型比较复杂,训练的稳定性也降低了。如LapSRN。
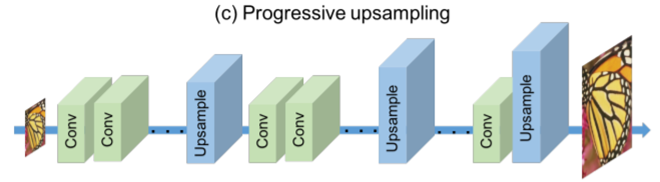
4、iterative up and down sampling SR,即迭代式上下采样SR,上采样层后紧跟下采样层,并迭代很多次,获取不同上采样倍数阶段HR图像的特征。

“Zero-Shot” Super-Resolution using Deep Internal Learning(ZSSR)
论文地址:https://arxiv.org/pdf/1712.06087.pdf
官方开源代码:https://github.com/assafshocher/ZSSR文章要点
“zero-shot”,即0样本学习,指直接从给定的待超分LR测试图像提取一些局部区域作为训练对,对网络进行微调训练。本文利用了图像的非局部相似性,即在大多数自然图像中,图像某处的纹理、结构会在该图像的其他地方多次、重复地出现。
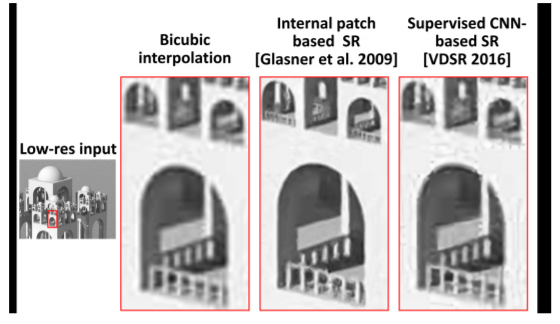
如上图,圆形的洞口和栏杆以不同角度出现了多次,但只有使用了图像内部信息的SR(中间图)对上面的两个栏杆有较好的重建
效果。ZSSR认为,单张图像内部的熵(可理解为有用的信息)要比一般自然图像集合的熵小很多,所以只需要一个小型的简单CNN网络就足够了。ZSSR在测试某张LR图像时使用该图像构建训练集,先训练再测试,不需要传统的预训练过程。 ZSSR只包含8个卷积层,每个卷积层60个通道,使用ReLU作为激活函数。输入和输出同尺寸(输入为LR插值上采样为HR尺寸图像)。因为网络结构小,因此和传统的supervised CNNs相比测试时间相差不多(但也要上千次梯度更新,所以用的网络很小)。
如何训练测试?
对测试图像I,进行s倍下采样,成为 I下s。网络学习其到I的映射,然后把网络用于I的上采样,得到I上s。对于很小的图像做较大尺度的超分,作者将SR过程逐步执行,每次超分的尺度较小,然后在上一步基础上再重复过程。优点
第一篇采用无监督方式的CNN超分算法;
不需要HR图像,从LR图像构建训练数据;
不需要进行预训练;
没有超分上采样倍数限制。Meta-Transfer Learning for Zero-Shot Super-Resolution(MZSR)
论文地址:https://arxiv.org/pdf/2002.12213.pdf
官方开源代码:https://github.com/JWSoh/MZSR (基于TF1.8)文章要点
传统的Supervised超分网仅仅学习到了外部数据集的特征,而ZSSR仅仅学习到了单张图像数据内部的特征,作者希望能够同时学习外部和内部的特征,即有监督学习和无监督学习相结合训练和测试过程
首先使用外部大规模训练集如DIV2K,使用L1损失训练得到预训练模型;
然后用大量不同的模糊核k合成训练数据集,即由HR图像用不同的模糊核生成HR-LR图像对。然后继续训练模型;
测试阶段,使用ZSSR的方法进行自监督训练,然后进行测试。由于有第二阶段的训练,此时训练只需少量的梯度更新次数即可。

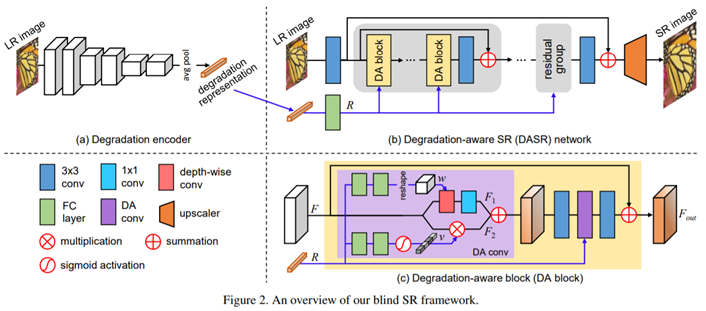
Unsupervised Degradation Representation Learning for Blind Super-Resolution(DASR)
论文地址:https://arxiv.org/pdf/2104.00416.pdf
官方开源代码:https://github.com/LongguangWang/DASR文章要点
将对比学习引入退化表达学习,在表达空间中学习特征表达来辨别不同的退化。本文基于一个先验假设:同一图像的退化是相同的,而不同图像的退化是不同的。训练过程
给定输入图像块作为query(橙色框),同一图像内的其他块视作正样本(红色框),其他图像提取的图像块视作负样本(蓝色框)。采用CNN网络对图像块提取退化表达特征,我们采用一个六层的CNN对上述图像块提取退化特征表示,然后参照SimCLR,使用两层MLP作为projection head,对比学习时采用infoNCE损失。训练时基于DIV2K与Flickr2K HR图像,采用不同的高斯模糊进行退化,并添加加性高斯噪声。

网络结构
采用DA block作为基本单位构建网络。整个网络包括五个残差组,每个组5个DAblock。在每个DABlock内,两个DA卷积层结合退化表达对特征进行自适应调节。
在真实退化数据上,DASR的视觉效果更好,边缘更清晰,且具有更少的模糊伪影。

Designing a Practical Degradation Model for Deep Blind Image Super-Resolution(BSRGAN)
论文地址:https://arxiv.org/pdf/2103.14006.pdf
官方开源代码:https://github.com/cszn/BSRGAN文章要点
提出一个广义的退化模型,相比于只考虑bicubic或blur-down退化模型的情况,将退化模型广义化,提出了更多复杂的情况,具体来说,采用两种模糊(各向同性高斯模糊和各向异性高斯模糊),四种降采样(nearest、bilinear、bicubic以及up-down scaling),三种噪声(3D高斯噪声、JPEG噪声、相机噪声),并且随机打乱模糊、降采样、噪声的顺序。这样,整个退化模型覆盖的退化空间大大扩充,可以建模各种不同情况的退化。超分模型不是本文的重点,现有的模型均可使用,本文使用了ESRGAN作为baseline。
-
相关阅读:
代码随想录算法训练营第六十五天 | 岛屿数量 深搜、岛屿数量 广搜、岛屿的最大面积
Linux下使用宏定义判断系统架构和系统类型
技术分享|电商数据接口|淘宝天猫京东商品API接口之数据同步
Metalama简介4.使用Fabric操作项目或命名空间
AF594 NHS 活化酯 Alexa Fluor 594 NHS ester,295348-87-7
我为什么使用Linux做开发
常用redis-lua脚本
(4)paddle---PCB检测的例子
oauth2.0使用JWT存储token连接数据库
【Unity】在Unity 3D中使用Spine开发2D动画
- 原文地址:https://blog.csdn.net/zgcr654321/article/details/118851820