-
重学java基础----集合框架(2)
参考于韩顺平老师JAVA基础课程以及笔记
本文讲解双列集合
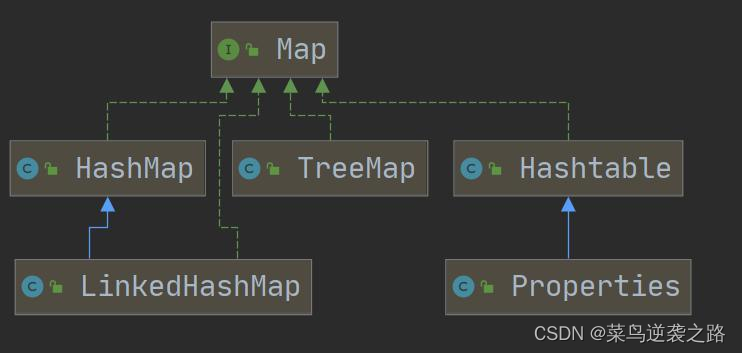
Map接口以及常用方法
-
JDK1.8 接口的特点

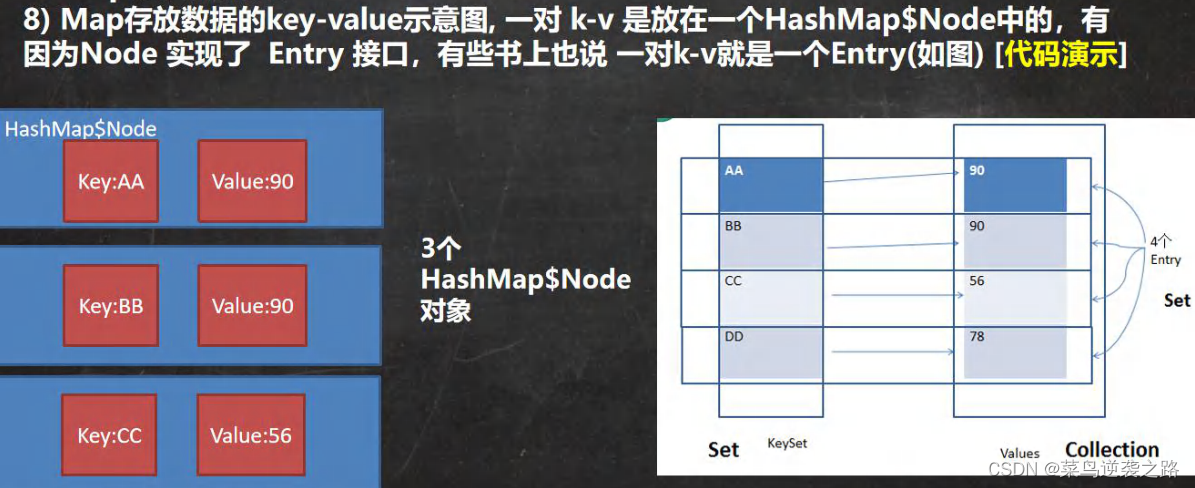
-
Map接口常用方法






-
Map接口遍历方法
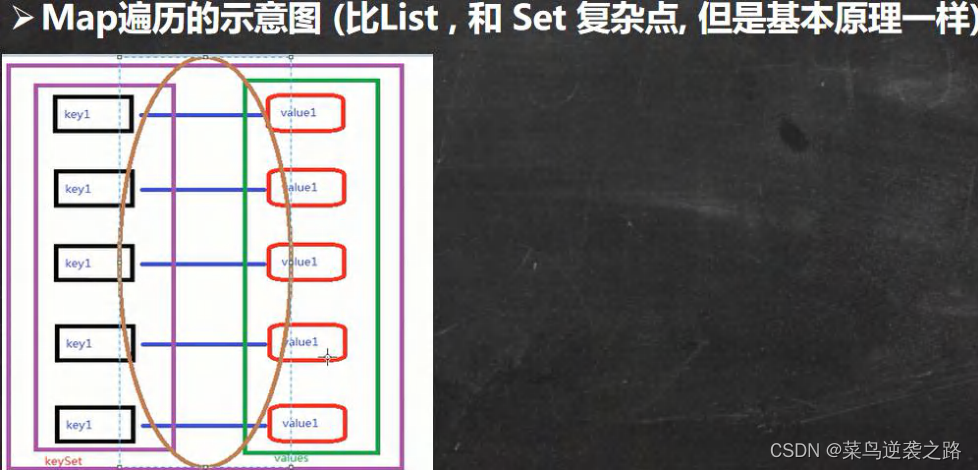
使用KeySet(),取出所有的key,通过key取出对应的value
主要两种方法:增强for循环、迭代器//增强for循环 for (Object key : set) { System.out.println(map.get(key)); } //迭代器 System.out.println("==========="); Iterator iterator = set.iterator(); while (iterator.hasNext()) { Object key = iterator.next(); System.out.println(map.get(key)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
使用values()获取所有的值
主要有:增强for循环、迭代器Collection values = map.values(); //可以使用所有的collection遍历的方法 //(1)增强for for (Object value : values) { System.out.println(value); } //(2)迭代器 while (iterator.hasNext()) { Object next = iterator.next(); System.out.println(next); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
通过EntrySet来获取k-v
主要有:增强for循环、迭代器Set entrySet = map.entrySet();// EntrySet- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Map接口实现类–HashMap
-
特点
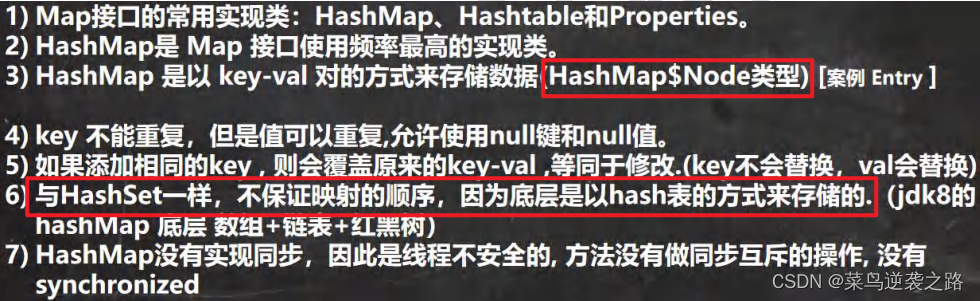
-
HashMap底层机制与源码剖析(重要)
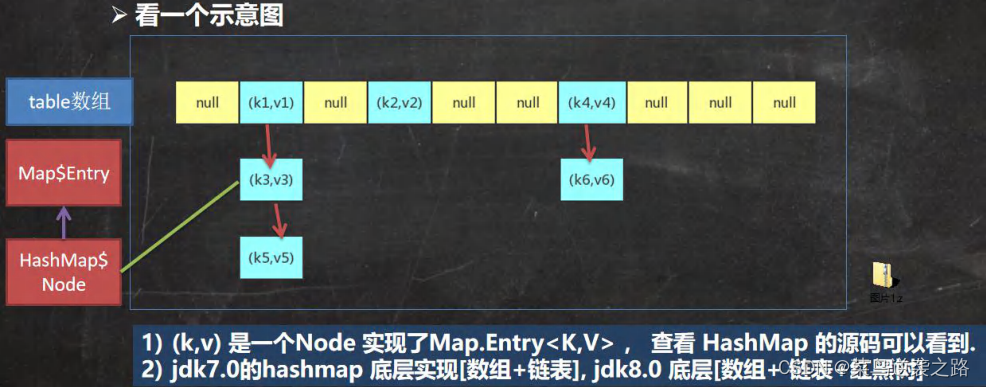

-
测试代码
package com.map; import java.util.HashMap; import java.util.HashSet; /** * @Description * @autor wzl * @date 2022/8/13-21:48 */ public class HashMapSource { public static void main(String[] args) { HashMap map =new HashMap(); map.put("java",10); map.put("php",10); map.put("java",20); System.out.println("map="+map); } /* * 执行构造器 new HashMap() 初始化加载因子 loadfactor = 0.75 HashMap$Node[] table = null * 执行 put 调用 hash 方法,计算 key 的 hash 值 (h = key.hashCode()) ^ (h >>> 16) public V put(K key, V value) {//K = "java" value = 10 return putVal(hash(key), key, value, false, true); } * 执行 putVal final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- HashMap扩容机制(与HashSet部分一样)
public class HashMapSource2 { public static void main(String[] args) { HashMap hashMap = new HashMap(); for(int i = 1; i <= 12; i++) { hashMap.put(i, "hello"); } hashMap.put("aaa", "bbb"); System.out.println("hashMap=" + hashMap);//12 个 k-v } } class A { private int num; publicA(int num) { this.num = num; } //所有的 A 对象的 hashCode 都是 100 // @Override // public int hashCode() { // return 100; // } @Override public String toString() { return "\nA{" + "num=" + num + '}'; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
Map接口实现类-HashTable
-
特点

-
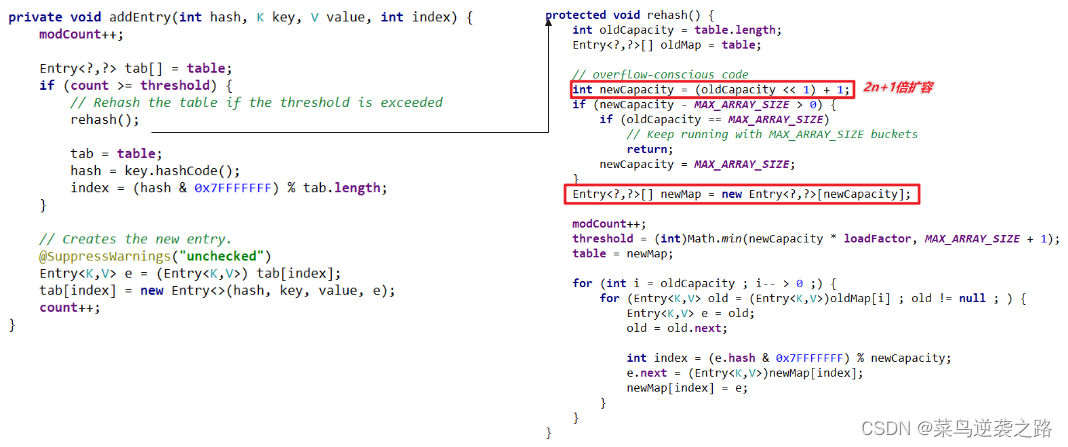
底层源码与扩容机制
1.底层有数组,Hashtable$Entry[],初始化大小为11
2.临界值 threshold 8=11*0.75
3.扩容:按照自己的扩容机制进行
4.执行方法 addEntry(hash,key,value,index);添加k-v封装到Entry
5.当if(count>=threshold)满足时,就进行扩容
6.按照2n+1扩容package com.map; import javax.swing.table.TableCellEditor; import java.lang.annotation.Target; import java.util.Hashtable; /** * @Description * @autor wzl * @date 2022/8/14-7:50 */ public class HashTableSoure { public static void main(String[] args) { Hashtable hashtable =new Hashtable(); hashtable.put("lucy",100); hashtable.put("jack",200); hashtable.put("jac",200); hashtable.put("ja",200); hashtable.put("j",200); hashtable.put("ack",200); hashtable.put("ck",200); hashtable.put("k",200); hashtable.put("jackk",200); System.out.println(hashtable); //HashTable底层原理 /* 1.底层有数组,Hashtable$Entry[],初始化大小为11 2.临界值 threshold 8=11*0.75 3.扩容:按照自己的扩容机制进行 4.执行方法 addEntry(hash,key,value,index);添加k-v封装到Entry 5.当if(count>=threshold)满足时,就进行扩容 6.按照2n+1扩容 */ } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
HashMap VS HashTable

Map接口实现类-Properties
- 特点
由于继承Hashtable类,所以特性与它一样,底层扩容机制也一样

- 基本使用
package com.map; import java.util.Properties; /** * @Description * @autor wzl * @date 2022/8/14-8:16 */ public class Properties_ { public static void main(String[] args) { Properties properties =new Properties(); properties.put("lucy",100); properties.put("john",100); properties.put("lic",100); System.out.println(properties); //如何通过key获取对应值 查 System.out.println(properties.getProperty("lic")); System.out.println(properties.get("lic")); //删除 properties.remove("lucy"); System.out.println(properties); //改 properties.put("john",200); System.out.println(properties); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
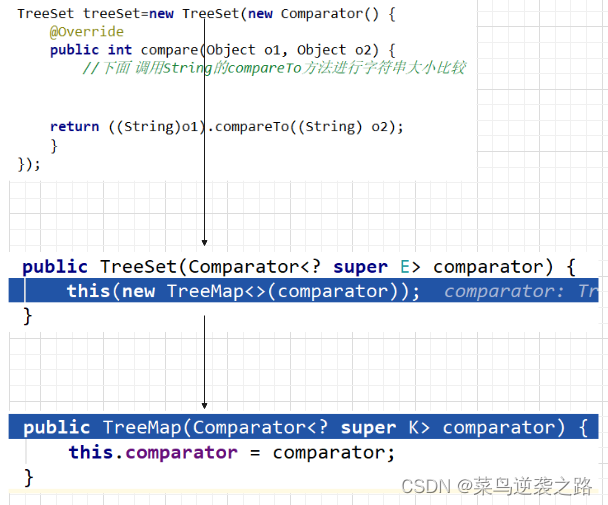
TreeSet源码解读
- 当我们使用无参构造器创建TreeSet时,它仍然是无序的
- 假设按照字符串大小来排序
- 使用TreeSet提供给的一个构造器,可以传入一个比较器(匿名内部类)
package com.map; import javax.transaction.TransactionRequiredException; import java.util.Comparator; import java.util.TreeSet; /** * @Description * @autor wzl * @date 2022/8/14-8:25 */ public class TreeSet_ { public static void main(String[] args) { /* 1. 当我们使用无参构造器创建TreeSet时,它仍然是无序的 2. 假设按照字符串大小来排序 3. 使用TreeSet提供给的一个构造器,可以传入一个比较器(匿名内部类) */ //TreeSet treeSet=new TreeSet(); TreeSet treeSet = new TreeSet(new Comparator() { @Override public int compare(Object o1, Object o2) { //下面 调用String的compareTo方法进行字符串大小比较 return ((String) o1).compareTo((String) o2); } }); treeSet.add("john"); treeSet.add("lucy"); treeSet.add("lick"); treeSet.add("a"); System.out.println(treeSet); /* 1. 构造器把传入的比较器对象,赋给了 TreeSet 的底层的 TreeMap 的属性 this.comparator public TreeMap(Comparator comparator) { this.comparator = comparator; } 2. 在 调用 treeSet.add("tom"), 在底层会执行到 if (cpr != null) {//cpr 就是我们的匿名内部类(对象) }do { parent = t; //动态绑定到我们的匿名内部类(对象)compare cmp = cpr.compare(key, t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else //如果相等,即返回 0,这个 Key 就没有加入 return t.setValue(value); } while (t != null); } */ } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
TreeMap源码解读
package com.map; import java.util.Comparator; import java.util.TreeMap; /** * @Description * @autor wzl * @date 2022/8/14-8:54 */ public class TreeMap_ { public static void main(String[] args) { //使用默认的构造器,创建TreeMap,输入和输出顺序是不一致的(也没有排序) //TreeMap treeMap=new TreeMap(); TreeMap treeMap=new TreeMap(new Comparator() { @Override public int compare(Object o1, Object o2) { return ((String)o1).length()-((String)o2).length(); // return ((String)o1).compareTo((String)o2); } }); treeMap.put("jack", "杰克"); treeMap.put("tom", "汤姆"); treeMap.put("kristina", "克瑞斯提诺"); treeMap.put("smith", "斯密斯"); treeMap.put("hsp", "韩顺平");//加入不了 System.out.println("treemap=" + treeMap); /* 1. 构造器. 把传入的实现了 Comparator 接口的匿名内部类(对象),传给给 TreeMap 的 comparator public TreeMap(Comparator comparator) { this.comparator = comparator; } * 调用 put 方法 2.1 第一次添加, 把 k-v 封装到 Entry 对象,放入 root Entry- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
如何选择集合类

Collections工具类
-
作用

-
常用方法举例


集合练习题


关键看Person()类是否实现了compareable接口,如果没有,会出现类型转换异常

-
-
相关阅读:
【.Net Core】程序相关各种全局文件
超市管理系统(java+Mysql)
3-1、python内置数据类型(字符串类型)
「Python入门」Python多线程
2022.07.20 NDK OpenGL ES 3.0 :画个三角形,纹理贴图(刚入门就入土)
笨蛋学C++【C++基础第六弹】
前三季度亏损近亿元,「缺钱」的北斗智联拟变更控股股东
物联网的挑战
过滤对象数组中有重复值的项
Numpy、Matplotlib and Pandas
- 原文地址:https://blog.csdn.net/qq_38716929/article/details/126268414
