一、ES简介
1 - es简介
- mysql面临的问题
- 性能低下:数据量或者并发比较大的情况下,like的效率低下
- 没有相关性排名:我们使用搜索引擎搜索的时候,希望关联度比较高的搜索在前面展示
- 无法全文搜索
- 搜索不准确 —— 没有分词
- 什么是全文搜索
- 我们生活中的数据总体分为两种:结构化数据和非结构化数据
- 结构化数据:具有固定格式或有限长度的数据,如数据库、元数据等
- 非结构化数据:指不定长或无固定格式的数据,如邮件、word文档等
- 什么是ES:ES是一个分布式可扩展的实时搜索和分析引擎,一个简历在全文搜索引擎Apache Lucene(TM)基础上的搜索引擎;当然ES并不仅仅是Lucene那么简单,它不仅包括了全文搜索功能,还可以进行以下工作
- ①.分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索
- ②.实时分析的分布式搜索引擎
- ③.可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据
- ES适用场景
- 电商网站、检索商品
- 日志数据分析、logstash采集日志、ES进行复杂的数据分析(ELK)
- 商品价格监控网站、用户设定价格阀值
- BI系统、商业智能、ES执行数据分析和挖掘
2 - es中的type、index、mapping、dsl
| mysql | Elasticsearch |
|---|
| database | —— |
| table | index(7.x开始理解为table)、(7.x开始type为固定值_doc) |
| row | document |
| column | field |
| schema | mapping |
| sql | DSL(Descriptor Structure Language) |
- 索引:index。es将它的数据存储到一个或者多个索引(index)中,索引就像数据库,可以向索引写入文档或者从索引中读取文档
- 在es索引有2个概念:动词(insert)、名词(表)
- 动词:es中描述添加数据 -> 索引一个数据
- 名词:es中描述一个数据在一个表中 -> 一个数据在一个索引中
3 - es的本质
二、安装ES和kibana
三、ES创建添加数据
1 - 新建数据
- put + id新建数据:account是index;_doc是固定写法;1是id
- put必须添加id,否则会报错
- account不存在也会帮我们新建
- account嵌套了company
PUT account/_doc/1
{
"name":"bobby",
"age":18,
"company":[
{
"name":"imooc",
"address":"beijing"
},
{
"name":"immoc2",
"address":"shanghai"
}
]
}
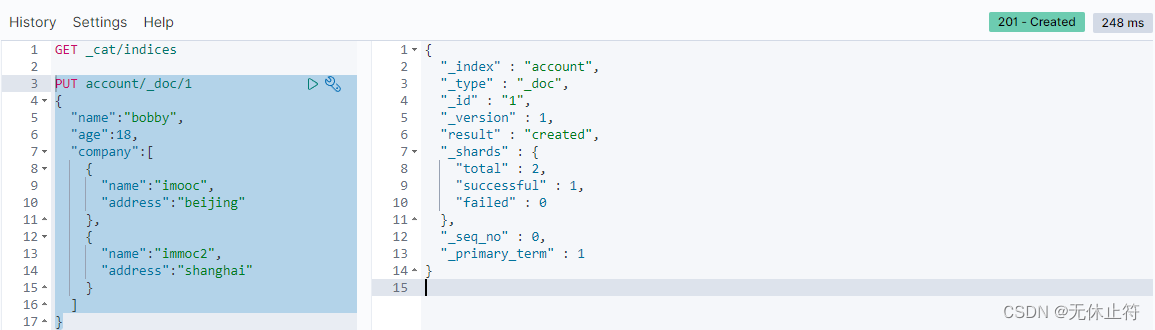
- put + id新建数据返回:_shards分布式中的分片;_seq_no乐观锁;
{
"_index" : "account",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
- put如果id数据存在则为update,否则为create:updated状态码200,created状态码201
- 查看新建的index

- post不带id新建数据
post user/_doc/
{
"name":"bobby",
"company":"imooc"
}
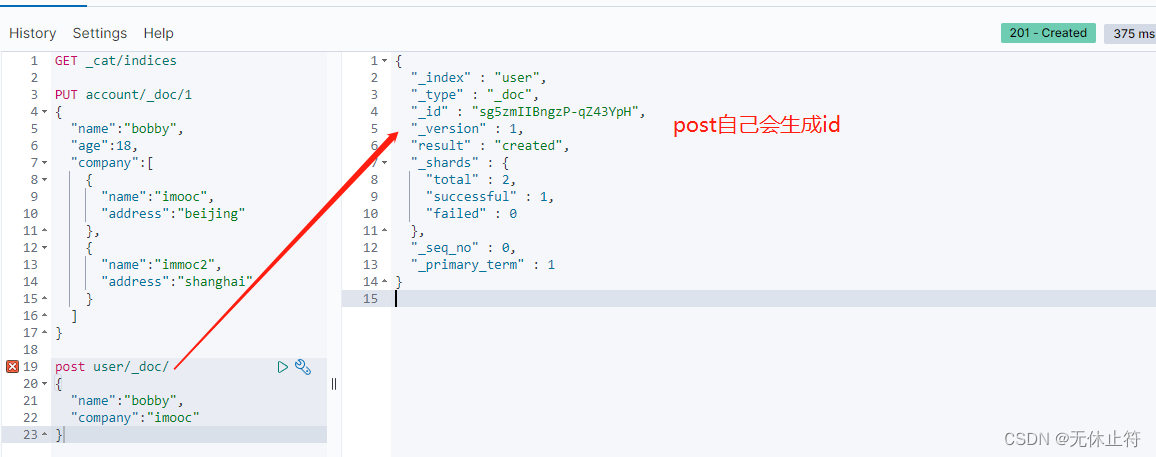
- 如果post带id就和put的操作是一样的了:只是put不允许带id
- post + _create:有就新建没有报错
POST user/_create/1
{
"name":"bobby",
"company":"imooc"
}

2 - 查看索引
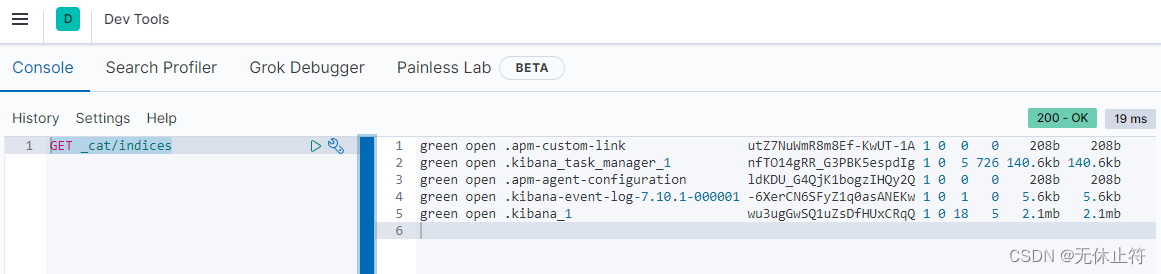
- 查看所有索引:
GET _cat/indices

- 查看具体索引:
GET account
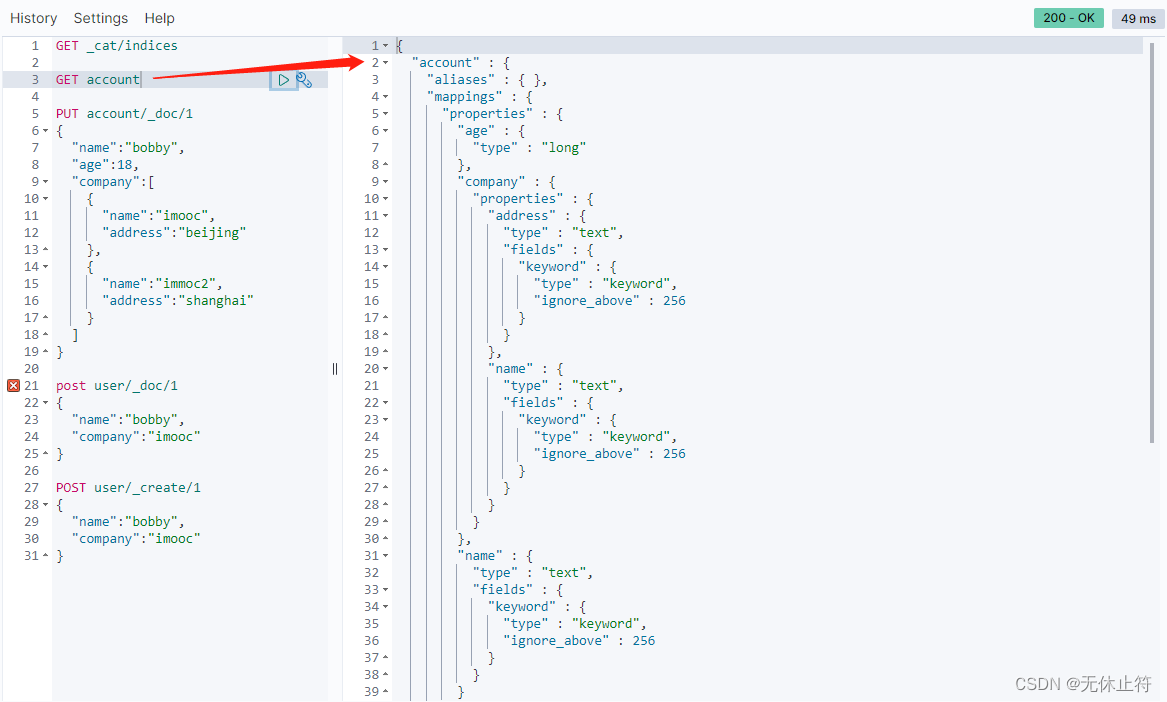
3 - post的坑
- post的updated会删除掉之前的数据:put也是一样的
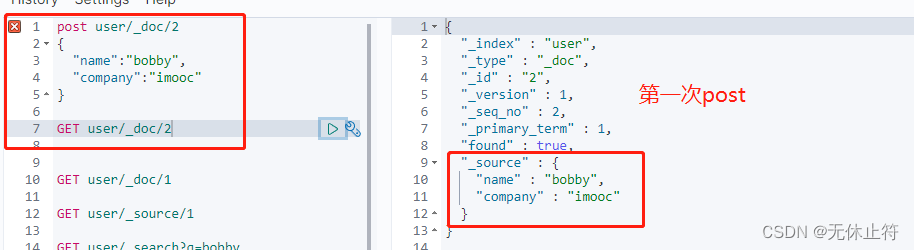
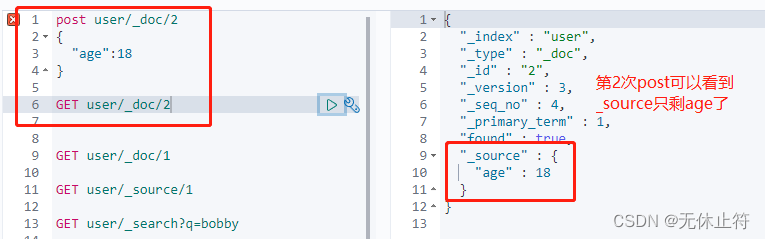
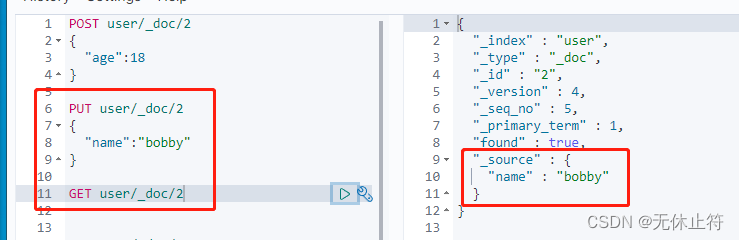
- 如何向已有数据添加数据?:带上_update,并且将新数据包裹在doc中
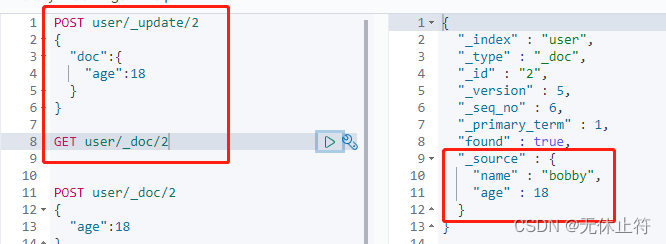
- 使用_update和_doc这种方式是会检查的:可以发现无论怎么执行_version和_seq_no都是不会改变的

四、ES获取数据
1 - 数据获取
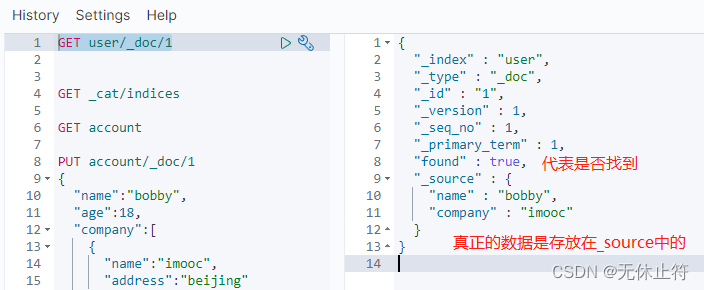
- 获取数据:
GET user/_doc/1
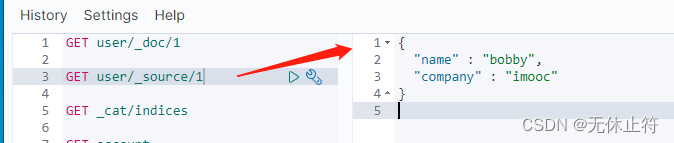
- 获取特定的数据:
GET user/_source/1
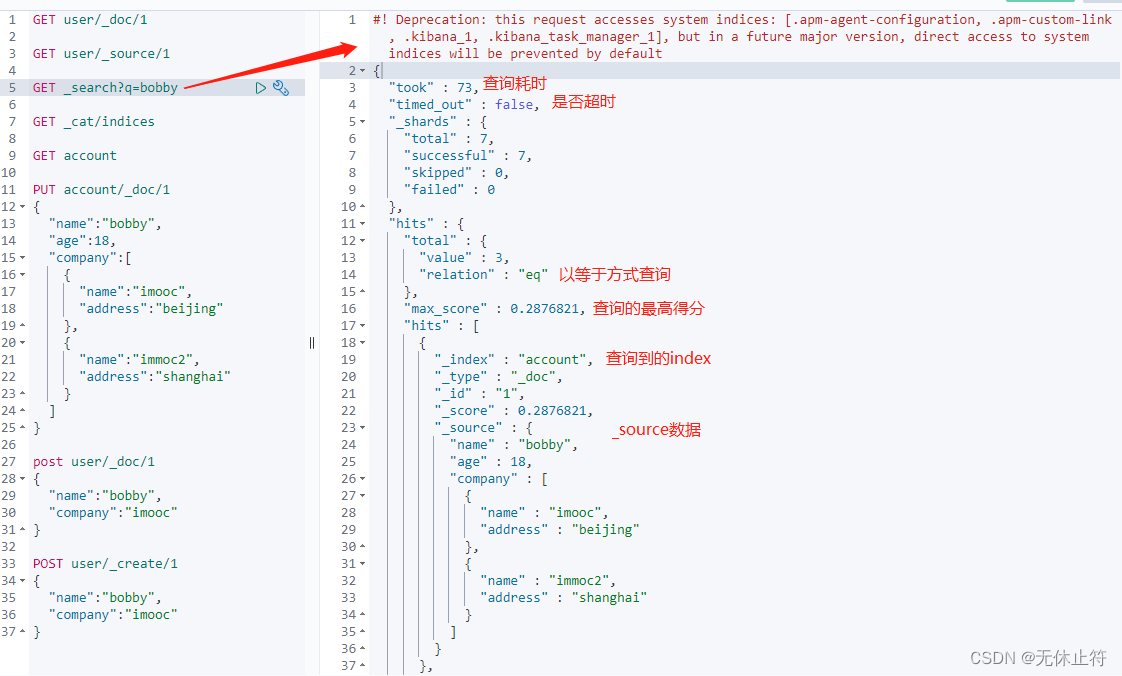
2 - 通过url搜索数据
- 查询所有index:
GET _search?q=bobby
- 查询指定索引数据:
GET user/_search?q=bobby

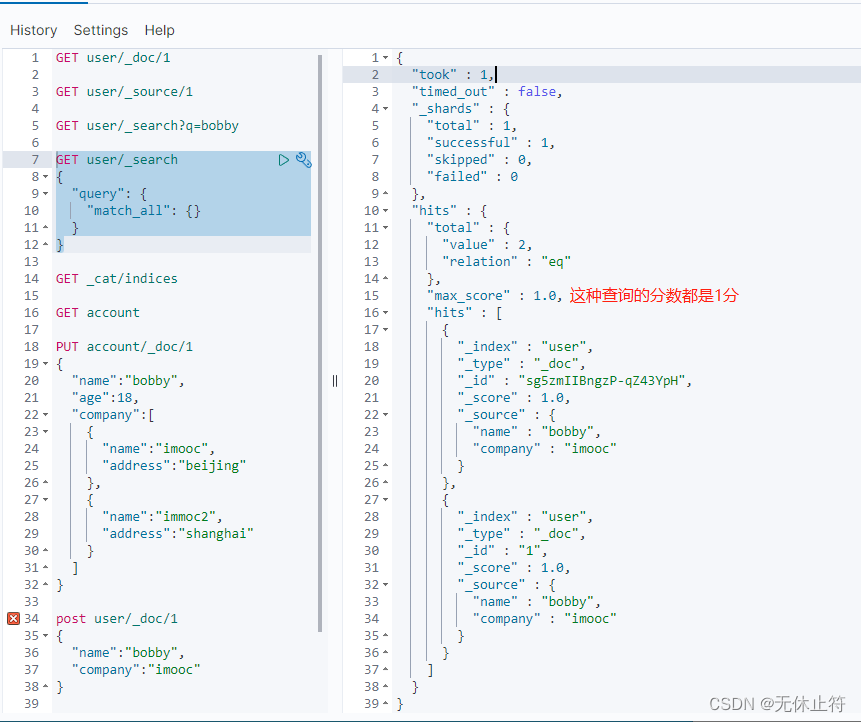
3 - 通过request body查询数据(重点)
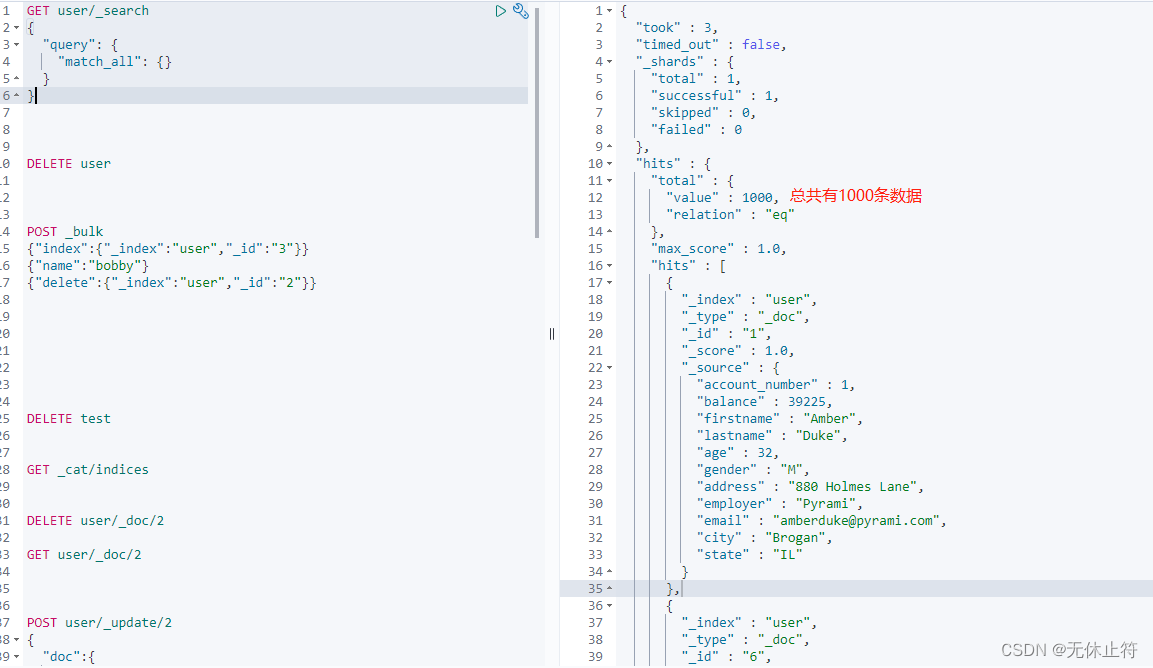
GET user/_search
{
"query": {
"match_all": {}
}
}
五、删除数据
- 删除数据:
DELETE user/_doc/2
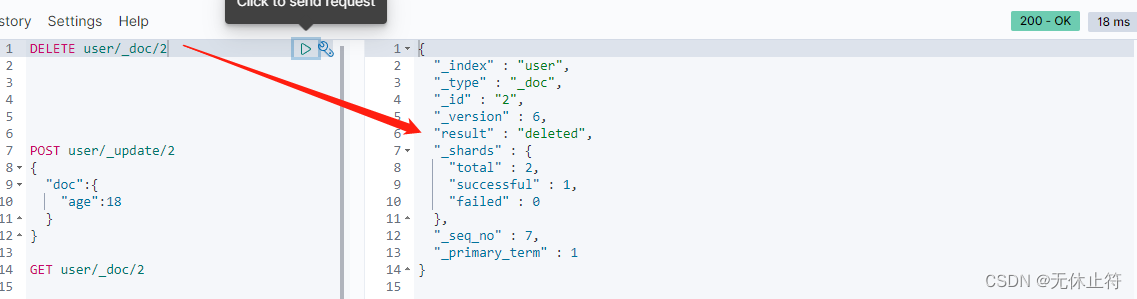
- 删除后再查询:_found为false,并且状态为404

- 删除索引:
DELETE user


六、批量插入和批量查询
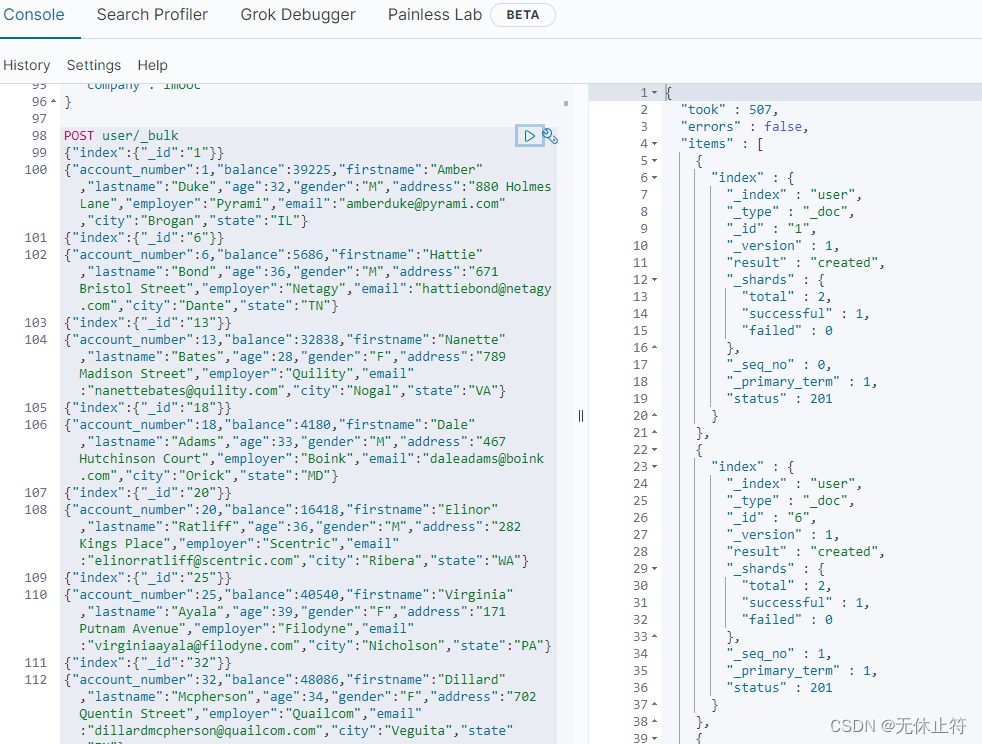
1 - POST _bulk
POST _bulk
{"index":{"_index":"user","_id":"1"}}
{"name":"bobby"}
{"index":{"_index":"user","_id":"2"}}
{"name":"bobby2"}
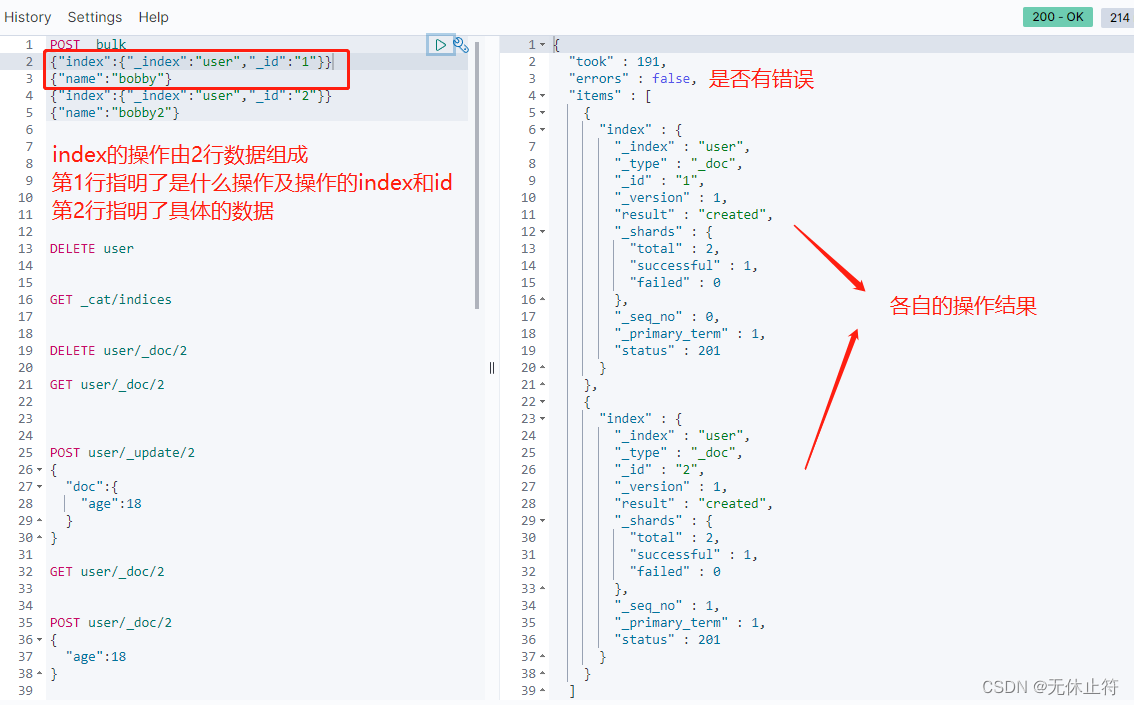
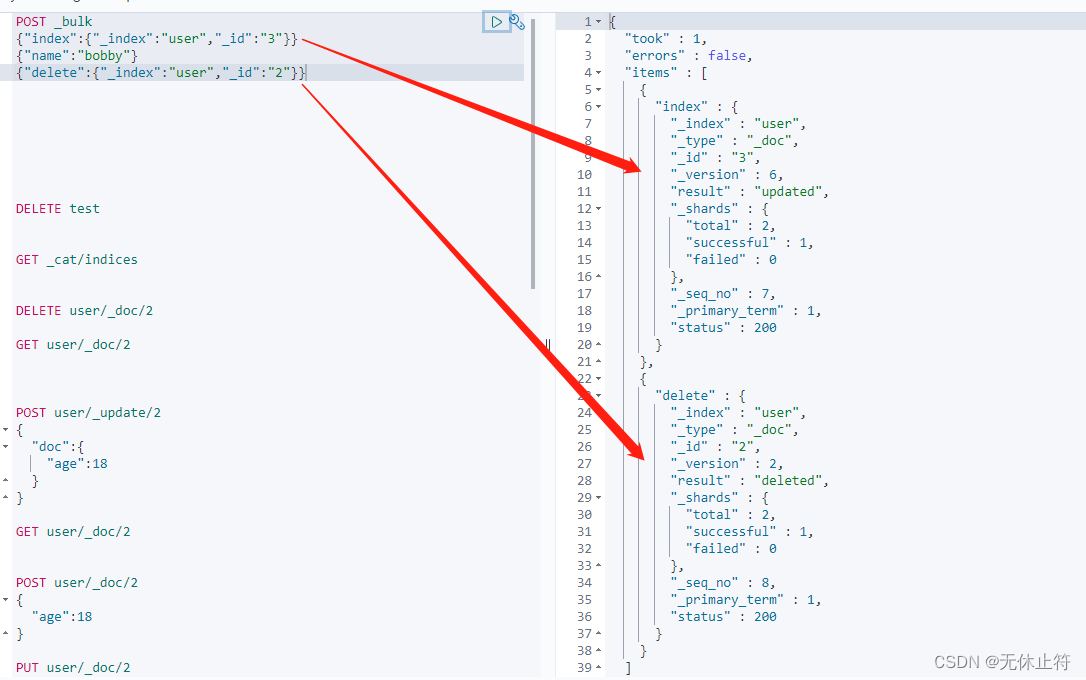
- 操作是独立的:批量操作,每个操作都是独立的,即使失败了也不会影响其他操作

- 操作是可以混合的:不要求各操作必须一样
2 - 导入官方数据测试
- 导入官方提供的accounts.json数据:因为
{"index":{"_id":"1"}}只有id,我们导入的时候带上index即可
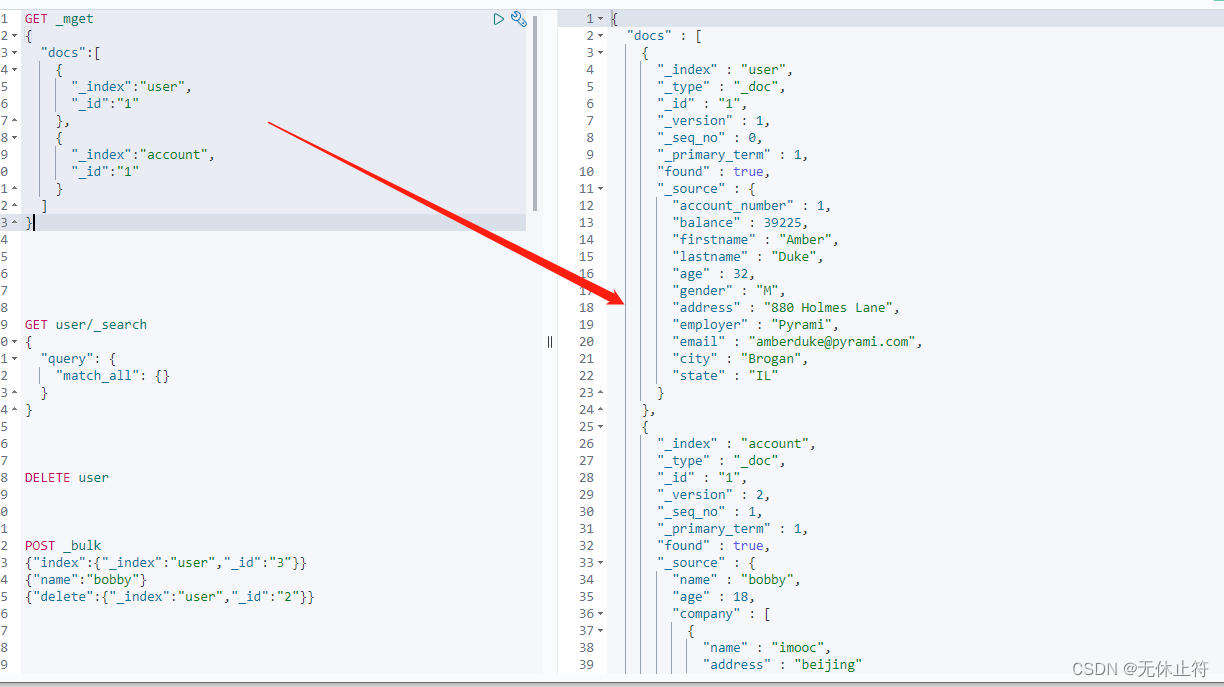
3 - GET _mget