-
论文阅读CVPR2022 MaskformerV1和V2
前言(碎碎念):
七月初学完最原始的transformer之后,一直感觉对attention和transformer的理解云里雾里的,似懂非懂,后来又学习了关于visual transformer,像是ViT、Swin、MAE、MoCo和DETR之后,尤其是学习了DETR之后感觉那个query更加神奇了。决心趁热打铁,对transformer再加深理解。
这两篇工作比较有名,在benchmark的CoCo和ADE等数据集里表现非凡。FAIR出品,钞能力~
因为我还是一个初出茅庐的小白,水平和精力实在有限,所写的内容仅为目前为止对工作的理解和思考。其实是更想借这几个工作好好理解一下transformer query based的分割任务,其中如果有理解的不对的地方希望大家指出来,一起交流学习!~
题外话:为什么想学这篇工作?
想读的原因:1、对上一篇汇报的《Rethinking Semantic Segmentation:A Prototype View》里提到的分割任务里的query vector查询方式做分割挺好奇,正好maskformer就是如此
2、学完detr之后,觉得DETR的learnable positional encoding很厉害,启发了很多后续的工作。感觉理解的还不够,想进一步理解。
正文:
maskformer的其中一个作者是DETR的作者,就是标黄的那位。

快速回顾一个大家都非常熟悉的问题,语义分割任务的像素分类方式是如何定义这个分割问题的?
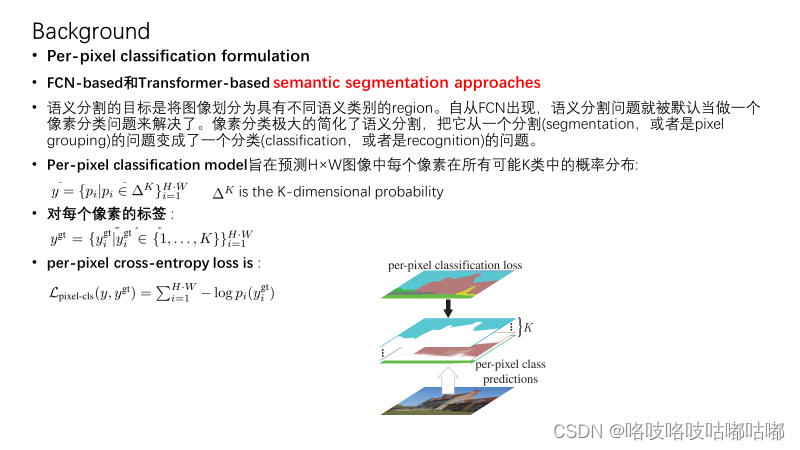
感兴趣的可以再看一个关于maskformer、transformer和OCRNet的思考,会有一些收获.

基于这几个问题(我自己的疑问),作者提出的动机表面上看动机很简单:用mask classification的范式来统一不同的分割任务,而且是一种简洁通用的方式。(剧透:受DETR启发,1、不再依赖box prediction,2、且预测的数量N受query的作用,不必固定等于K类别/物体数了,感觉transformer的作用就很神奇伟大??~)

总览整个model的结构,非常简洁,由三个module组成,也可以看到并没有依赖box prediction。
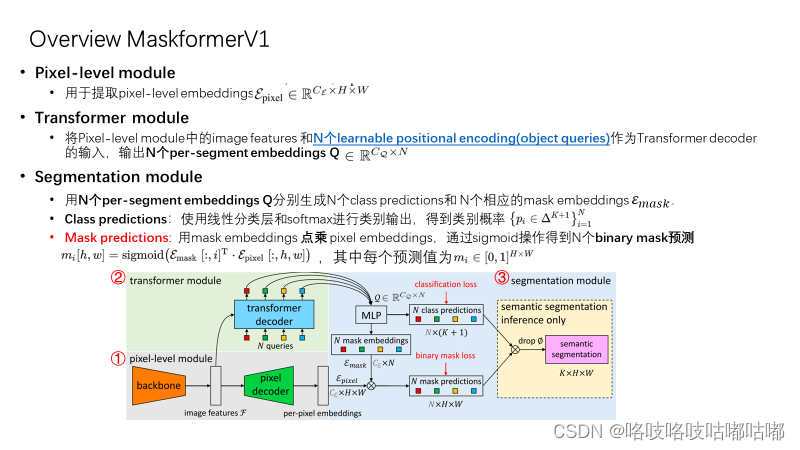
对这个learnable positional encoding有些好奇,回顾了一下DETR,想知道怎么启发的。
这里看到另一位博主的DETR的理解,也有许多收获,推荐读一下!(他的导图方式非常奈斯,以及pipeline的整理也非常清晰,这些学习习惯值得学习~!respect)

对于这种N个query的查询方式,进一步看了一篇去年的transformer visual的综述,原来已经有人总结并分类了在分割任务里的不同的使用方法呀~!
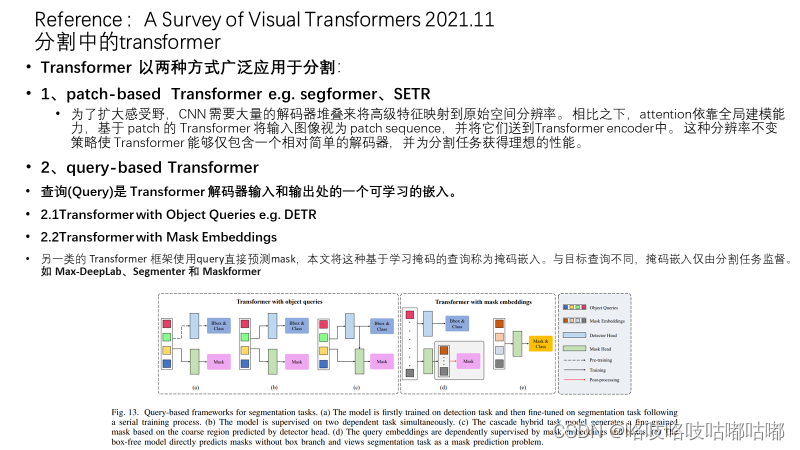
来具体看一下maskformer如何用Mask classification方式来定义的分割任务问题的。 (提醒一下:因为原文信息量巨大,作者写作也相当扎实,很清晰,PPT展示内容有限,墙裂推荐拜读原文!~)


结果不详细说了文中列出了semantic segmentation (ADE20K)和panoptic segmentation (COCO)的主要结果。这里就不多展开讲了,MaskFormer不仅结果更好,而且速度更快参数更少。

在Maskformer之后作者对其进行了改进,发出了本作Mask2former,在统一图像分割的进程上又迈进了一步。在通用模型问世后并没有出现分割领域的网络架构统一的现象,作者认为现存的通用模型虽然足够灵活,能够处理全景分割、实例分割、语义分割所有这些问题,但是存在训练困难以及精度不高等问题。值得一提的是以前的通用模型(包括Maskformer),例如DETR等,对显存的占用都较大,在Maskformer上训练一张图片就占用了约18GB显存,对于计算能力有限的我们来说很不友好,而作者通过优化损失函数的计算方式成功减少了模型的显存占用以及训练负担,现在使用Mask2former训练一张1024 ×\times 1024的图像只占用6GB显存,减小了近3倍。
V2的动机非常简单,就是想办法把收敛速度提高,方便训练,同时提高精度,让这个universal model在不同数据集上不同分割任务都更加SOTA。

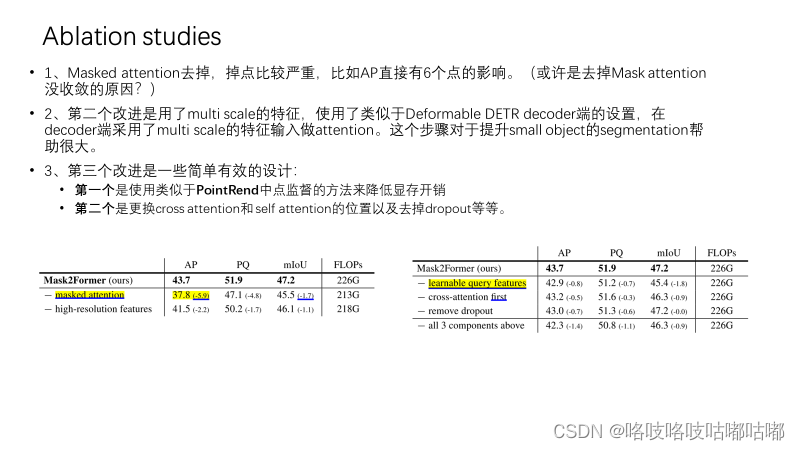
主要贡献就是在Transformer decoder中使用masked attention,将注意力限制在the foreground region of the predicated mask for each query,也就是局部特征上,predicated mask可以是objects,也可以是region,具体取决于分组的特定语义。
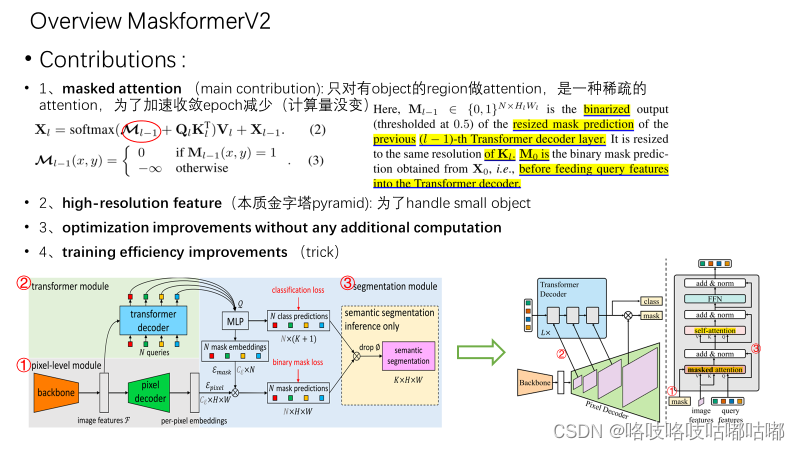
关于Optimization improvements里的第二条,因为我还没有来得及看源码,去理解细节,不是很理解“让query 也变成可学习的参数”是什么意思??(等开学去学校里,打算好好调试一下mmdetection 里的maskformer,理解一下整个forward和loss的训练过程)
 因为时间、水平,精力有限,论文里有太多太多实验结果、消融实验了!没有全仔细看,还是墙裂推荐阅读原文。
因为时间、水平,精力有限,论文里有太多太多实验结果、消融实验了!没有全仔细看,还是墙裂推荐阅读原文。

最后
做一次PPT实在元气大伤啊ORZ,,,,太累了(昨天开会被老师批了,说我读的“太慢了”,要兼顾整体的进度,跪)
然而还是有非常多的细节和工作没有做好:像那个DETR博主那样,做出清晰的导图来解释work的过程和流程图/表格做出pipeline。
还有一些内容没有来的及学习:比如V2里的pointrend的训练损失函数的策略是啥,之前学习的是semantic任务,对panoptic分割的评价指标和数据集还不是很了解等等。
因为疫情开学时间延迟了大概一周,好吧,那就再好好卷一下吧,多读几篇,挑战一下自己,提前看看VOS咯。所以下一次可能想了解一下RIS和R-VOS的内容了,敬请期待8.30嘿嘿嘿,不过也有可能因为水平有限,换题目。
-
相关阅读:
ROC曲线简明讲解
计算机组成原理-存储器概念
听书项目开发过程及重难点总结
python教程:使用gevent实现高并发并限制最大并发数
海泰前沿技术|隐私计算技术在医疗数据保护中的应用
【Linux】进程间通信 -- 管道
C# - Entity Framework 对一个或多个实体的验证失败。有关详细信息,请参阅“EntityValidationErrors”属性
【鲁棒电力系统状态估计】基于投影统计的电力系统状态估计的鲁棒GM估计器(Matlab代码实现)
SpringCloud02 --- Nacos安装指南
字段 != null在pycharm中标黄
- 原文地址:https://blog.csdn.net/weixin_41469023/article/details/126317256