-
JVM调优
目录
JDK = JRE + 其他(一堆java工具(javac编译器)和java核心类库)
JRE = JVM + 其他(runtime class libraries等组件)
什么是JVM?
JVM英文Java Virtual Machine,称为Java虚拟机,是Java跨平台运行的关键部分。
作用:Java通过JVM就可以跨平台实现一次编译过后,在多个系统平台进行运行。
Java是如何实现跨平台的?
主要是通过JVM,当有一个java源文件,JDK中的javac编译器将java文件编译成字节码文件(.class文件),通过JVM【java虚拟机】将字节码文件通过类加载器编译成不同系统【windows、linux、Mac】能够识别的二进制机器码,这样就实现了一次编译,到处(多个系统平台上)运行。【关键因素就是系统是否安装相应的虚拟机。java程序实际是在虚拟机JVM上运行的】
JDK 、JRE、JVM 有什么区别和联系?

JDK(Java Development Kit) :是Java开发工具包,它提供了Java的开发环境(提供了编译器javac等工具,用于将java文件编译为.class[字节码]文件)和运行环境(提供了JVM和Runtime辅助包,用于解析class文件使其得到运行)。JDK是整个Java的核心,包括了Java运行环境(JRE),一堆Java工具tools.jar和Java标准类库 (rt.jar)。
JRE(Java Runtime Enviroment) :是Java的运行环境,JRE是运行Java程序所必须的环境,包含JVM及 Java核心类库
三者之间的关系:
JDK = JRE + 其他(一堆java工具(javac编译器)和java核心类库)
JRE = JVM + 其他(runtime class libraries等组件)
为什么要JVM调优【目的是什么】?
JVM调优目的:就是减少GC垃圾回收的频率,通过减少Minor GC【新生代】和减少Full GC【老年代】回收的的次数来实现。从而使用较小的内存占用来获取较高的吞吐量。【因为每次进行GC都会暂停JVM。】
JVM优化方法?
优化指标:
-
内存占用:程序正常运行需要的内存大小。
-
延迟:由于垃圾收集而引起的程序停顿时间。
-
吞吐量:用户程序运行时间占用户程序和垃圾收集占用总时间的比值
[重要]调优可以依赖、参考的数据有系统运行日志、堆栈错误信息、gc日志、线程快照、堆转储快照等。
JVM监控工具?
内存分析工具就是用来实时监控JVM的状态的。
JDK也有自己的可视化工具.Java提供了2个监视工具
Jconsole Jvisualvm
// 直接输入Dos命令 输入
=======================
Jvisualvm安装GC插件,用来实时监控垃圾回收。
JVM的组成以及作用?
JVM主要由两个系统和两个组件组成。
两个系统指的是类装载器(Class Loader)和执行引擎(Execution Engine),
两个组件指的是运行时数据区(Runtime data area)和本地接口(Native interface)

===================记住黑体字即可==========================
Class loader(类装载器):【将java代码加载成字节码文件】根据给定的全限定名类名(如:com.zs.xx)来装载class文件到Runtimedata area中的method area。
Runtime data area(运行时数据区域):【将字节码文件加载内存中】这就是我们常说的JVM的内存。
Execution engine(执行引擎):【将内存中的字节码文件解析成计算机能够识别的机器码(二进制)】执行classes中的指令。
Native Interface(本地接口):【实现程序的执行】与native libraries交互,是其它编程语言交互的接口。
JVM类加载流程
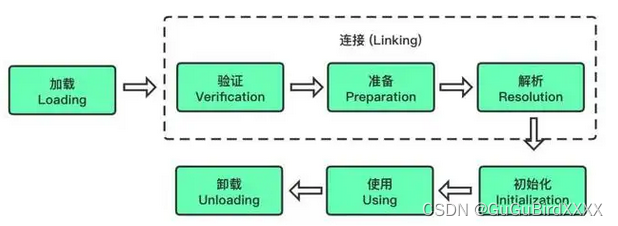
类加载的过程包括了加载,验证,准备,解析和初始化这5个步骤
加载:就是将字节码文件【Class文件】,读取到内存中。【隐式加载:通过new 关键字创建对象时,隐式的调用类的加载器把对应的类加载到jvm中。显示加载指的是通过直接调用class.forName()方法来把所需的类加载到jvm中。 】
验证:验证此字节码文件是不是真的是一个字节码文件 【毕竟后缀名可以随便改,而内在的身份标识是不会变的 】
准备:为类中static修饰的变量分配内存空间并设置其初始值为0或null【初始化的时候才会进行赋值】
解析 :解析阶段会将java代码中的符号引用替换为直接引用 【
使用全限定名来cn.wmx.mooccc.domain.user来找到这个类加载到分配的内存空间中。】
初始化:对变量进行赋值。
JVM类加载器有几种类型,分别加载什么东西?
什么是类加载器?
就是“通过一个类的全限定名来获取该类的二进制字节流”。实现这个动作的代码就叫做类加载器

JVM类加载器包含了
1启动类加载器:
负责将
/jre/lib /jre/lib/rt.jar)。2扩展类加载器
加载
/jre/lib/ext 3应用程序加载器
负责将系统类路径(CLASSPATH)中指定的类库加载到内存中
JVM类加载器使用到了什么设计模式【双亲委派模式】?
通俗易懂的双亲委派机制_IT烂笔头的博客-CSDN博客_双亲委派
加载优先级顺序:1启动类加载器>2扩展类加载器>3应用程序加载器
JVM会优先使用优先级高的进行加载字节码文件,然后最后是应用程序加载器进行加载,如果都没有加载就会报错ClassNotFountException。
实际是如何运作的呢?【其实就是先委托上级进行加载,委托不成功。】
我们以应用程序类加载器举例,它在需要加载一个类的时候,不会直接去尝试加载,而是委托上级的扩展类加载器去加载,而扩展类加载器也是委托启动类加载器去加载.
启动类加载器在自己的搜索范围内没有找到这么一个类,表示自己无法加载,就再让扩展类加载器去加载,同样的,扩展类加载器在自己的搜索范围内找一遍,如果还是没有找到,就委托应用程序类加载器去加载.如果最终还是没找到,那就会直接抛出异常了.
为什么采用这种设计模式?
1不让我们轻易覆盖系统提供功能,防止危险代码的植入 【即使我们自定义了类加载器,启动类或扩展类任意一个加载了,我们自定义的也不会生效】
2也要让我们扩展我们功能【当原本的三个加载器都没有进行加载,就可以使用我们自定义的加载器】。
线程在JVM中是如何执行的?涉及到哪些区域?

JDK1.8以后,方法区被元空间替代,没有方法区了,元空间直接使用本地内存
Java 程序在 JVM 中是怎样执行的呢?
直接举例:
- public class Example {
- public static void main(String[] args) {
- a();
- }
- public static void a() {
- int a = 1;
- b();
- }
- public static void b() {
- User b = new User();
- }
- }
代码很简单,一个类,main() 方法调用 a() 方法,a() 方法中定义了一个 int 变量 a,然后调用 b() 方法,b() 方法中 new 了一个 User 对象 b。
想要弄明白这个问题,你需要一丢丢的前置知识:
-
栈内存中用于存放 Java 的基本类型和对象的引用类型
-
堆内存主要存放一些对象,栈中有对应的引用类型指向该【实例的内存地址】
线程在JVM的执行流程
线程执行,每个方法都会形成一个栈帧进行压榨保存到虚拟机栈中,方法调用结束就回出栈。调用过程中创建的变量在虚拟机栈,对象实例存放在堆内存中,栈中的变量指向了对中的内存。当方法执行完成就出栈,创建的变量会被销毁,堆中的对象等待GC。
上面文字看不懂,可以看下面举例和视频。
http://vd3.bdstatic.com/mda-ngfib23r5ybsj286/360p/h264/1657976173300279887/mda-ngfib23r5ybsj286.mp4
-
程序运行
-
main() 方法入栈
-
a() 方法被调用,入栈
-
基本类型 a 变量在栈中被创建
-
b() 方法被调用,入栈
-
引用类型 b 在栈中被创建【b方法中需要创建User实例】
-
User 类型的实例在堆中被创建【堆内存用来存储对象】
-
将 User 实例的内存地址指向引用类型 b
-
b() 方法执行结束,b 变量销毁,断开对 User 实例的引用,出栈
-
a() 方法执行结束,a 变量销毁,出栈
-
垃圾回收将不再被引用的 User 实例回收掉
-
main() 方法执行结束,出栈
-
程序执行结束
虚拟机栈(FILO):java方法执行的内存模型。
栈帧(
一个栈帧就对应Java代码中的一个方法,当线程执行到一个方法时,就代表这个方法对应的栈帧已经进入虚拟机栈并且处于栈顶的位置,每一个Java方法从被调用到执行结束,就对应了一个栈帧从入栈到出栈的过程)局部变量表:编译器可知的8种基本类型、reference类型、returnAddress类型
操作数栈:一个用于计算的临时数据存储区(明显,此栈是为了存放要操作的数据用的)
动态链接:支持java多态
返回地址:方法结束的地方。return/Exception
本地方法栈:Native方法执行的内存模型。
程序计数器:这个计数器记录的是正在执行的虚拟机字节码指令的地址(如果线程正在执行的是一个java方法,程序执行到第5行,然后时间片用完了,就需要执行其他的代码,当再次回到当前线程时,通过程序计数器就可以继续再原来的地方继续执行)。
JVM堆的组成
堆内存是所有线程所共享的,堆内存主要是用于存储对象。
其中堆的组成部分包括 新生代和老年代。
新生代可分为一个Eden,两个Survivor区(From,To)
Eden中存放的是通过new 或者newInstance方法创建出来的对象 。
新生代采用的是复制算法。
老年代采用的是标记整理法。

程序内存溢出了,如何定位问题出在哪儿?
增加启动参数-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=d:\ 可以把内存溢出的日志输出到文件,然后通过JVM监视工具JVisualVM来分析日志,定位错误所在。在linux服务器也可以使用命令: jmap -dump 来下载堆快照。
垃圾回收算法
1.垃圾标记算法
1.1.引用计数算法
给每一个对象添加一个引用计数器,每当有一个地方引用它时,计数器值加1;每当有一个地方`不再引用它时,计数器值减1 这样只要计数器的值不为0,就说明还有地方引用它,它就不是无用的对象。

缺点:`当某些对象之间互相引用时,无法判断出这些对象是否还在被引用。

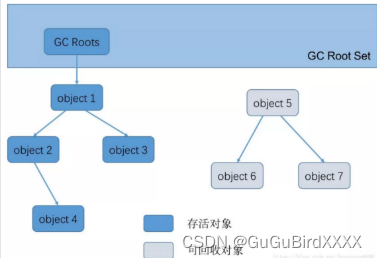
1.2.可达性分析算法
可达性指的对象到GC Root【垃圾收集的起点 】是否有任何引用链相连。当一个对象到GC Roots没有任何引用链相连(GC Roots到这个对象不可达)时,就说明此对象是不可用。
举例:【可回收对象,说明没有对象引用。】
2.常用垃圾回收算法
常用的垃圾回收算法有三种:标记-清除算法、复制算法、标记-整理算法,分代回收
2.1.标记清除算法
分为标记和清除两个阶段【先标记后清除】,首先标记出所有需要回收的对象,标记完成后统一回收所有被标记的对象。

缺点:标记和清除两个过程效率都不高;标记清除之后会产生大量不连续的内存碎片【就无法保存连续的需要回收的对象】。
2.2.复制算法
把内存分为大小相等的两块,每次存储只用其中一块,当这一块用完了,就把存活的对象全部复制到另一块上,同时把使用过的这块内存空间全部清理掉,往复循环。

缺点:实际可使用的内存空间缩小为原来的一半,比较适合
2.3.标记整理算法
先对可用的对象进行标记,然后所有被标记的对象向一段移动,最后清除可用对象边界以外的内存

2.4.分代收集算法
把堆内存分为新生代和老年代,新生代又分为Eden区、From Survivor和To Survivor。一般新生代中的对象基本上都是朝生夕灭的,每次只有少量对象存活,因此新生代采用复制算法,只需要复制那些少量存活的对象就可以完成垃圾收集;老年代中的对象存活率较高,就采用标记清除和标记整理算法【两个算法综合使用】来进行回收。

堆大小怎么调,栈大小怎么调【网上查不到英文,难记死了】
-Xms : 初始堆内存大小,默认1/64 物理内存
-Xmx【MaxHeapSize】 : 堆的最大内存,默认1/4物理内存
-Xmn【memory nursery/new】 堆中新生代初始及最大大小
-Xss【ThreadStackSize】 : 线程栈大小
-
-
相关阅读:
react基础教程学习(一)
vscode远程调试c++
(五)C++中的排序函数性能比较
coudn‘t deserialize object in variable ‘entity‘.获取流程变量无法反序列化问题
ArcGIS Engine:实现Shp/Mxd数据的加载、图层的简单查询
【华为机试真题 JAVA】数字反转打印-100
2022年全国大学生数学建模竞赛E题目-小批量物料生产安排详解+思路+Python代码时序预测模型(四)
JS虚拟机JS加密技术:优缺点及案例研究
Vue中如何进行数据请求拦截与错误处理
PHP写用户注册、登录和密码重置功能
- 原文地址:https://blog.csdn.net/m0_64210833/article/details/126321001