-
【学习笔记】Redis的主从复制
【学习笔记】Redis的主从复制
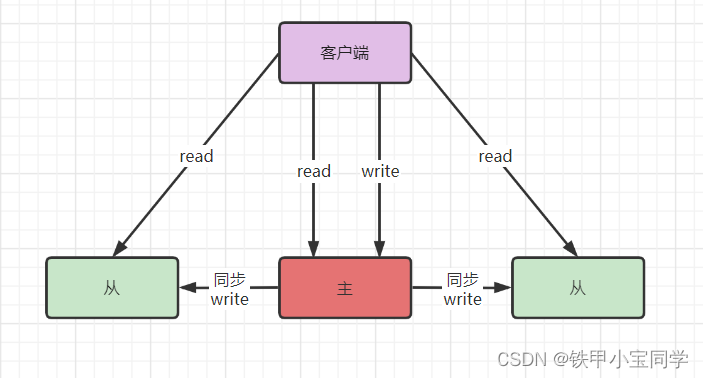
什么是主从复制?
主机数据更新后根据配置和策略,自动同步到备机的
master/slaver 机制,Master 以写为主,Slave以读为主。注意:
只有一对一或一对多。作用:
- 读写分离,性能扩展。
- 容灾快速恢复。
主从复制的实现
主从服务器之间的第一次同步
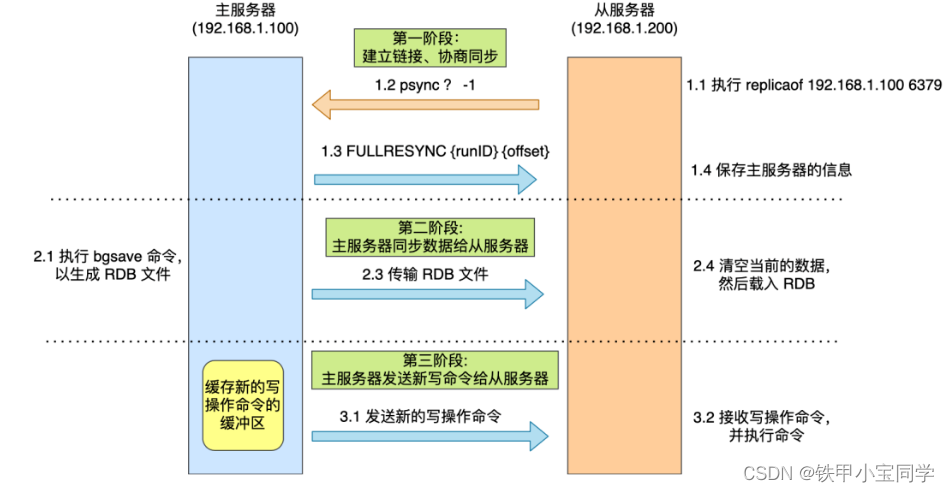
主从服务器之间的第一次同步过程可分为三个阶段:
- 第一阶段:建立链接,协商同步。
- 第二阶段:主服务器同步数据给从服务器。
- 第三阶段:主服务器发送新写操作命令给从服务器。
注: 由于博主画的图不堪入目,所以此处借鉴 小林 大神的图。非常感谢!
我们来逐一分析每一个步骤:
第一阶段:
执行了 replicaof 命令后,从服务器就会给主服务器发送
psync命令,表示要进行数据同步。psync 命令包含两个参数,分别是主服务器的 runID 和复制进度 offset。
- runID,每个 Redis 服务器在启动时都会自动生产一个随机的 ID 来唯一标识自己。当从服务器和主服务器第一次同步时,因为不知道主服务器的 run ID,所以将其设置为 “?”。
- offset,表示复制的进度,第一次同步时,其值为 -1。
主服务器收到 psync 命令后,会用
FULLRESYNC作为响应命令返回给对方。并且这个响应命令会带上两个参数:主服务器的 runID 和主服务器目前的复制进度 offset。从服务器收到响应后,会记录这两个值。
FULLRESYNC响应命令的意图是采用全量复制的方式,也就是主服务器会把所有的数据都同步给从服务器。也就是说第一阶段是为 全量复制 做准备的。
第二阶段:
主服务器使用
bgsave命令来生成RDB文件,然后发送给从服务器。此时从服务器清空当前数据并载入RDB。注意: 如果在这期间,主服务器收到 写操作 命令时是不会记录到
RDB中的,那么此时就会导致 主从不一致 的问题。那么为了保证 主从数据一致 ,主服务器在下面这三个时间间隙中将收到的写操作命令,写入到 replication buffer 缓冲区里。- 主服务器生成 RDB 文件期间;
- 主服务器发送 RDB 文件给从服务器期间;
- 「从服务器」加载 RDB 文件期间;
第三阶段:
在主服务器生成的
RDB文件发送完,从服务器加载完RDB文件后,然后将replication buffer缓冲区里所记录的写操作命令发送给从服务器,然后「从服务器」重新执行这些操作,至此主从服务器的数据就一致了。至此,主从服务器的第一次同步的工作就完成了。
当第一次同步完后,主从服务器之间就会建立起来一个
TCP长链接。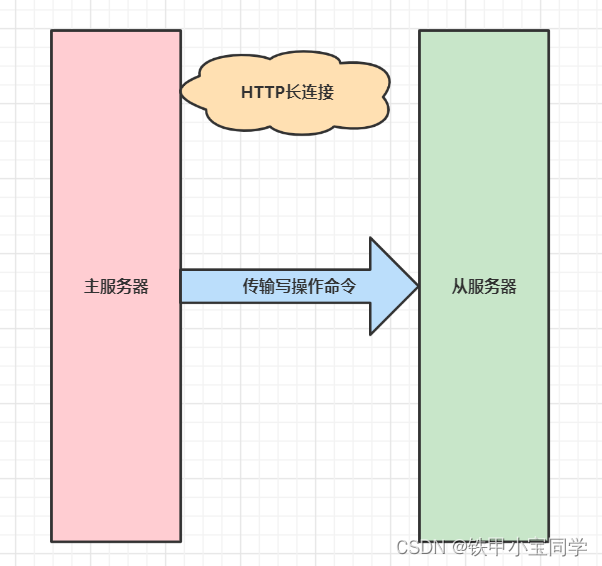
那为什么是 长连接 呢?
答:
目的是避免频繁的 TCP 连接和断开带来的性能开销。(如果不明白这块知识,小伙伴可以去补一下http的长连接那块知识点!)压力分担
上述中我们直到在创建
RDB和发送RDB文件时会十分消耗时间。当从服务器过多而且都与主服务器进行全量同步的话,则就会出现下列问题:
- 由于是通过
bgsave命令来生成RDB文件的,那么主服务器就会忙于使用fork()创建子进程,如果主服务器的内存数据非大,在执行fork()函数时是会阻塞主线程的,从而使得Redis无法正常处理请求; - 传输
RDB文件会占用主服务器的网络带宽,会对主服务器响应命令请求产生影响。
级联结构图:
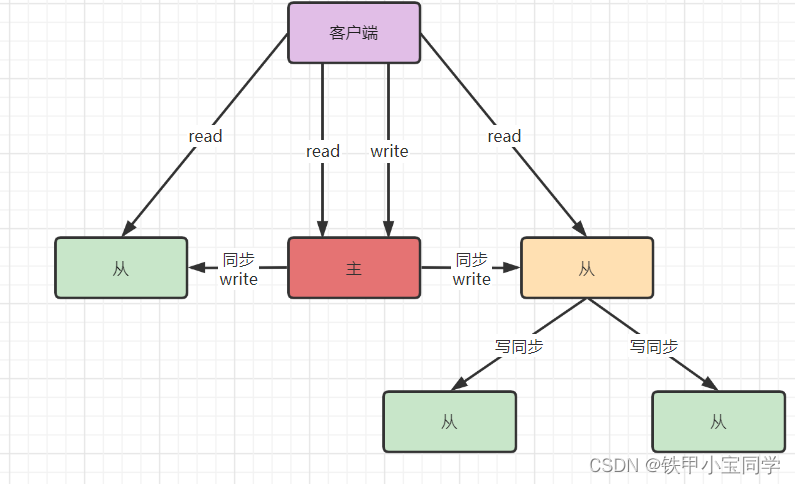
这就就能为主服务器分担
RDB编写和传输的压力了。增量复制
我们知道服务器有时候说延时就延时,说断开就断开。
如果主从服务器间的网络连接断开了,那么就无法进行命令传播了,这时从服务器的数据就没办法和主服务器保持一致了,客户端就可能从「从服务器」读到旧的数据。
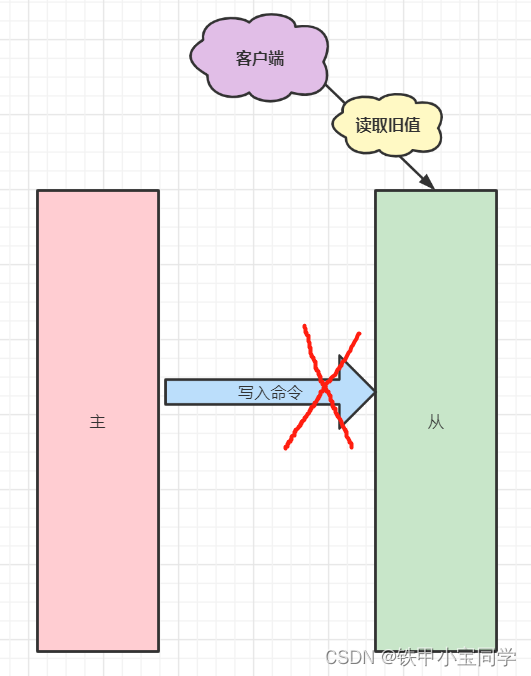
一般的解决办法有:
- 重新进行一次全量复制
- 增量复制
当然如果在进行一次 全量复制 会消耗很大的资源,这显然不是我们想要的结果。所以也就有了 增量复制 。
也就是只会把网络断开期间主服务器接收到的写操作命令,同步给从服务器。
网络恢复后的 增量复制 过程图如下:

上图中的三个主要步骤:
- 从服务器在恢复网络后,会发送
psync命令给主服务器,此时的psync命令里的offset参数不是-1; - 主服务器收到该命令后,然后用
CONTINUE响应命令告诉从服务器接下来采用增量复制的方式同步数据; - 然后主服务将主从服务器断线期间,所执行的写命令发送给从服务器,然后从服务器执行这些命令。
那么主服务器怎么知道将哪些增量数据发送给从服务器呢?
- repl_backlog_buffer,是一个「环形」缓冲区,用于主从服务器断连后,从中找到差异的数据;
- replication offset,标记上面那个缓冲区的同步进度,主从服务器都有各自的偏移量,主服务器使用 master_repl_offset 来记录自己「写」到的位置,从服务器使用
slave_repl_offset来记录自己「读」到的位置。
那
repl_backlog_buffer缓冲区是什么时候写入的呢?在主服务器进行命令传播时,不仅会将写命令发送给从服务器,还会将写命令写入到
repl_backlog_buffer缓冲区里,因此 这个缓冲区里会保存着最近传播的写命令。网络断开后,当从服务器重新连上主服务器时,从服务器会通过 psync 命令将自己的复制偏移量 slave_repl_offset 发送给主服务器,主服务器根据自己的 master_repl_offset 和 slave_repl_offset 之间的差距,然后来决定对从服务器执行哪种同步操作:
- 如果判断出从服务器要读取的数据还在 repl_backlog_buffer 缓冲区里,那么主服务器将采用增量同步的方式;
- 相反,如果判断出从服务器要读取的数据已经不存在 repl_backlog_buffer 缓冲区里,那么主服务器将采用全量同步的方式。
面试考点
1、Redis主从链接是什么链接?
采用HTTP之间的长连接。
2、Redis是同步复制还是异步复制?
首先主服务器收到写命令后,会先写入到 缓存区 ,然后在 异步 发送给从服务器。
3、replication buffer 、repl backlog buffer 两者之间的区别
- replication buffer 是在全量复制阶段会出现,主库会给每个新连接的从库,分配一个 replication buffer;repl backlog buffer 是在增量复制阶段出现,一个主库只分配一个repl backlog buffer;
- 这两个 Buffer 都有大小限制的,当缓冲区满了之后。repl backlog buffer,因为是环形结构,会直接覆盖起始位置数据,replication buffer则会导致连接断开,删除缓存,从库重新连接,重新开始全量复制。
致谢
非常感谢 小林 大佬提供的免费文章!!!
在这里非常的感谢啦!!!
本篇文章也是在小林大佬的文章基础上面按照自己的理解写了一些,其中还有一些是小林大佬文章中的原话(因为感觉自己写不出来那么好的哈哈哈)。
也希望本篇文章能够帮助到屏幕前的你,当然来个三联最棒嘿嘿嘿!!!
OK那今天的分享就到这里了,我们下期见!!!
-
相关阅读:
go 的结构体极速序列化
Java面试附答案:掌握关键技能,突破面试难题!
xgboost 与 lgbm
【LeetCode】191、461、190、118、268
Reg注册表读写
NoSQL 之 Redis 高可用与持久化(二)
【Java 进阶篇】深入了解 Bootstrap 组件
信息学奥赛一本通:1839:【05NOIP提高组】谁拿了最多奖学金
Java的POI-word模板生成目录自动更新
二叉树层序遍历及判断完全二叉树
- 原文地址:https://blog.csdn.net/m0_54355125/article/details/126245388