-
Redis 缓存相关 - Reids 缓存淘汰机制和缓存异常问题处理
一. Redis 缓存淘汰机制
直奔主题,
Redis是部署在某个机器上的,而内存是有限的,数据却可以是无限的,那么当Redis中的数据太多了,该怎么办?这就用上了Redis的缓存淘汰机制。Redis中的缓存淘汰策略主要可以分为两大类:- 不会进行数据淘汰的策略(
Redis3.0版本之后):noeviction。当Redis使用的内存超过了maxmemory值时,并不会淘汰数据。此时Redis不再提供对外服务,而是直接返回错误。 - 会进行数据淘汰的策略:7种。
会进行数据淘汰策略又可以分为两大类:
针对设置了过期时间的数据进行淘汰:4种
volatile-random:在设置了过期时间的键值对中,随机进行删除。volatile-ttl:在设置了过期时间的键值对中,越早过期的数据优先被删除。volatile-lru:在设置了过期时间的键值对中,采用LRU算法进行删除(最近最少使用(最长时间)淘汰算法)。volatile-lfu:在设置了过期时间的键值对中,采用LFU算法进行删除(最不经常使用(最少次)淘汰算法)。
针对所有数据进行淘汰:3种
allkeys-lru:使用LRU算法在所有数据中进行筛选。allkeys-random:从所有键值对中随机选择并删除数据allkeys-lfu:使用LFU算法在所有数据中进行筛选。
1.1 Redis 中的 LRU 算法
LRU算法(Least Recently Used):这是按照最近最少使用的原则来筛选数据,最不常用的数据会被筛选出来被淘汰,如图:
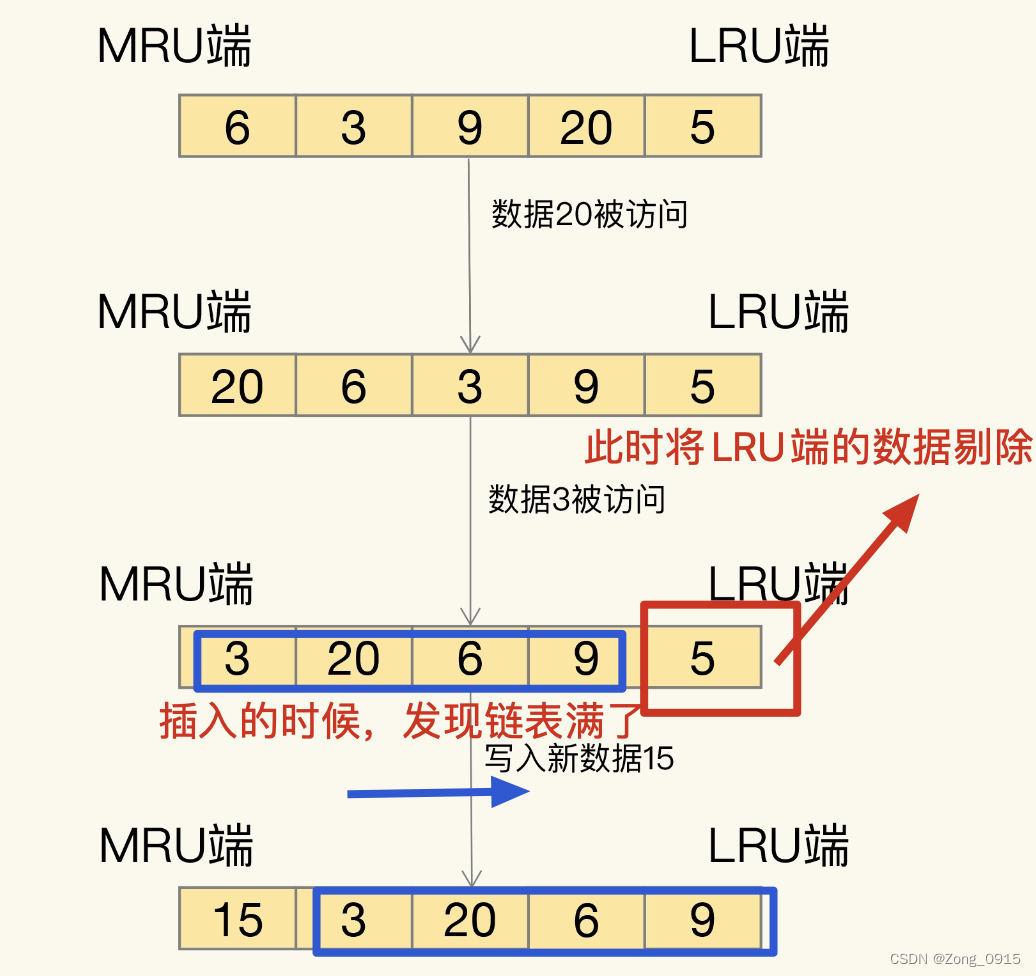
传统的LRU算法有着一定的缺陷:- 需要用链表管理所有的缓存数据,这会带来额外的空间开销。
- 向上面图所示,
LRU在数据更新的时候会造成链表移动操作。这个过程很耗时,会影响Redis缓存性能。
Redis对LRU做了一定的优化:- 默认记录每个数据的最近一次访问的时间戳。保存于
RedisObject.lru字段。 - 进行数据淘汰的时候,第一次会随机选出
N个数据,作为一个候选集合S。 - 比较
N个数据的lru字段,将lru字段值最小的数据从缓存中淘汰。 N这个参数可以通过maxmemory-samples来配置:

- 那么后续再淘汰数据的时候,将挑选出对应的数据补充到集合
S中。(保持集合S中元素总量不变)同时要求能够进入的数据必须满足这样的条件:其lru字段必须小于候选集合S中最小的lru值。 - 从而避免了传统
LRU算法中,对于链表的频繁维护操作。
1.2 总结
对于
Redis的缓存淘汰机制,有几个建议:- 优先使用
allkeys-lru策略。把最近最常访问的数据留在缓存中,提升应用的访问性能。尤其是那些有明显的冷热数据划分的应用缓存。 - 否则,倘若数据没有明显的冷热划分,可以使用
allkeys-random策略,随机淘汰。
需要值得注意的一点是:
Redis通过淘汰机制将需要淘汰的数据进行删除的时候,无论这个数据在当前状态下是否是干净的,它都会删除。- 干净的数据:和数据库(比如
Mysql)中的数据保持一致。 - 脏数据:和数据库中的数据不一致。不是最新的数据。
因此在使用
Redis作为缓存的时候,在更新缓存的时候,倘若数据库中也有这个缓存字段,那么需要同时修改数据库中的值。也就是所谓的保持数据一致性。二. 缓存异常问题
在第一章节我提到了数据的一致性。但是,往往在实际生产中,这样一个说起来简单的操作,却是代码编写上一个很大的难题:如何保证缓存和后端数据库的一致性问题?
除此之外,比较常见的缓存问题还有:缓存雪崩、缓存击穿、缓存穿透。
2.1 如何保证缓存一致性
首先什么是缓存和数据库数据的数据一致性?满足以下条件:
- 缓存中有数据:那么缓存的数据值需要和数据库中的值相同。
- 缓存中没有数据:那么数据库中的值必须是最新值。
如果不满足上述条件,就是所谓的缓存不一致性了。对于这个问题,常见的有三种解决方案:
Cache Aside。Read/Write Throught。Write Back。
首先粗略的来说下三种策略。
Cache Aside策略:即缓存只用来读。(最常用也是最容易实现的策略)- 读取操作如果命中缓存直接返回,否则从数据库中加载数据,先放到缓存,再返回。
- 如果是写操作,直接对数据库进行更新,同时将缓存进行删除。
- 保证一切的操作以后端数据为准。但是写操作会让缓存失效。
Read/Write Throught策略:读写操作都只操作缓存。- 应用层在操作缓存时,缓存层会自动从数据库中加载或写回到数据库中。
Write Back策略:读写缓存 + 异步写回。- 写操作只写缓存,不写数据库。
- 读操作如果缓存存在,返回。否则先读数据库,将数据加载到缓存中,再返回。
- 加载到缓存之前,若缓存满了,先将需要淘汰的数据写回到数据库中。
- 写操作速度快,但是如果数据还没有来得及写入数据库,就发生了宕机,此时就会造成数据不一致性。常用于操作系统的
Page Cache中。
接下来具体说下一致性问题,首先需要明确几点:
- 我们无法完全保证数据和缓存的完全一致性。只能做到精益求精。
- 利用
Redis作为缓存的目的是为了快,那么在解决缓存一致性问题的时候,难免会加大系统的复杂度,性能和一致性不可能两全其美,只能做到平衡。 - 正常的情况下,利用
Cache Aside策略就可以了。代码的业务逻辑也非常的简单。而且,正常情况下(不宕机,没有夸张的网络延迟),非常普通的(没有高并发)那种业务发生这种数据不一致性的可能性也太低了。当然作为一名合格的程序员,需要防患于未然。
如果需要寻求缓存一致性,难以避免的是:在对缓存或者数据库里的数据进行删除或者修改操作的时候。肯定需要同时对缓存和数据库里的数据进行操作,也就是有两个步骤。 那么就有一个顺序问题:是先操作数据库还是缓存?
回答:
- 首先,缓存的目的只是为了快。那么它的一个地位是什么?就是一个辅助的第三方工具。
- 因此,无论是什么操作(除了读操作),我们应该先操作数据库,在操作缓存。
要想保证数据的一致性,在上述基础上,我们先更新数据库,再删除缓存。同时利用消息队列来保证重试。 流程如下:
假设有个
主线程A:需要对某个Key进行修改。- 首先我们应该更新数据库中的数据,保证数据库中的数据永远是最新的。
- 其次我们再删除缓存,那么这一步骤可能会因为各种原因而导致失败。不管怎样,代码上先尝试将其删除。
- 针对第二步,倘若失败了,我们可以将要删除的这个
key加入到第三方消息队列中。然后通过另起一个线程B,去不断地尝试删除它,直到成功。(可以限制一下重试的次数,避免无限死循环) - 这里还需要注意一点,记得对
Key做幂等性处理。保证这个Key只会被消费一次。
例如:
public void updateData(String key, Object data){ // 1.先更新数据库 updateMysqlData(data); if(!redis.del(key)){ // 2.如果失败了,放到队列中,去不断重试。 mq.send(key); new Thread(()->asyncDel()).start(); } } public void asyncDel(){ int count = 0; String key = mq.get(); // 循环调用删除 while(!redis.delKey(key)) { count++; // 设定个阈值,避免死循环 if (count > 5) { throw new MyException(); } } // 删除完毕,不管是否成功,记得把队列中的key移除 mq.remove(key); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
至于其他的什么延时双删的解决方案,可以自行百度。再者,你可以给文章中的两个操作加上事务,但是这样会造成性能的下降,可能会适得其反。
除了用消息队列做重试机制以外,也可以订阅数据库的变更日志,在操作缓存(阿里的
canal,仅供参考)。2.2 缓存雪崩
缓存雪崩:短时间内大量缓存失效,导致请求直接访问数据库。数据库压力剧增。
其发生的原因主要是:缓存中有大量的数据同时过期。那么我们只需要给不同的
key设置不同的过期时间即可。除此之外,在业务逻辑上我们可以通过服务降级的方式来解决,服务降级根据数据的不同采取不一样的处理方式:
- 非核心数据:缓存不存在时,返回空值或者错误信息。
- 核心数据:缓存不存在时,继续走数据库查询。
同时可以通过服务限流,控制一段时间内的最高请求数量,将数据库需要处理的请求控制在一定范围内。
2.3 缓存击穿
缓存击穿:针对某个访问非常频繁的热点数据的请求,缓存中不存在,从而导致请求发送到了后端数据库,导致了数据库压力激增。
和缓存雪崩比较相似,两者都是
Redis缓存中没有对应的数据而导致请求直接流入数据库,导致其压力剧增。只不过具体的表现形式有所不同而已。- 缓存雪崩:合理设置
key的过期时间,避免key在同一时间大量过期,可以给的过期时间加上一定的随机数。 - 缓存击穿:主要针对的是热点数据,可以给热点数据不设置过期时间,即永久保存。
2.4 缓存穿透
缓存穿透:要访问的数据既不在
Redis中,也不在数据库中。一般是攻击请求,即发起大量的查询请求,而查询的数据本身不存在。导致同时给Redis和数据库造成巨大压力。首先,针对一些特定的恶意攻击请求,我们最好在请求入口处加上参数的校验,避免恶意攻击。我们甚至可以对一些恶意攻击的
IP进行封锁。另一方面,这里我们可以利用
Redis中的布隆过滤器,它的工作机制:- 布隆过滤器由一个初值都为 0 的
bit数组和N个哈希函数组成,可以用来快速判断某个数据是否存在。 - 当插入一条数据之后,会使用
N个哈希函数,分别计算这个数据的哈希值,得到对应的N个哈希值。 - 将
N个哈希值对bit数组的长度进行取模,得到每个哈希值在数组中的对应位置。 - 最后将对应的位置的
bit值设置为1即可。
这样,我们就可以在插入数据的时候,将这个数据也放进去,然后每次查询的时候用布隆过滤器做一次校验即可。不过布隆过滤器有这么几个点需要引起注意:
- 布隆过滤器存在误判,可能存在两个不同的值映射到同一组
bit上。即哈希冲突。 - 布隆过滤器应该放在缓存和数据库之前操作,先看其是否存在对应的数据,否则再走后续流程。
- 虽然布隆过滤器存在哈希冲突,对于某个
key是否存在可能有误判。但是对于某个key不存在,却是能准确地计算出来的。
2.5 总结
简单总结下就是:
- 缓存一致性:通过重试机制,引入消息队列。先操作数据库,在操作缓存。
- 缓存雪崩:为不同的
key设置不同的过期时间。服务降级、服务限流。 - 缓存击穿:热点数据不设置过期时间。
- 缓存穿透:布隆过滤器+恶意攻击拦截。
- 不会进行数据淘汰的策略(
-
相关阅读:
C++基础入门详解(二)
复制粘贴(一):copy paste 事件
【CS224N 论文精读】Efficient Estimation of Word Representations in Vector Space(2013)
计算机艺术和动画之父肯·诺尔顿去世,享年91岁
大数据学习3.2 部署Hadoop
websocket 初识
_c++11(包装器)
独立站新手卖家应注意的要点
让工程师拥有一台“超级”计算机——字节跳动客户端编译加速方案
STC15单片机-按键检测单击、双击和长按(状态机)
- 原文地址:https://blog.csdn.net/Zong_0915/article/details/126308409


