-
python如何删除数据中含有“.0.01“的异常数据
1、摘要
本文主要讲解:使用python删除数据中含有".0.01"的异常数据
主要思路:- 替换"."
- 替换".0."
- 计算"."的数量,超过1就删除
- 将数据转为float,并用try捕获异常,属于异常就删除
2、数据介绍
含有".0.01"的异常数据
示例1:

示例2:
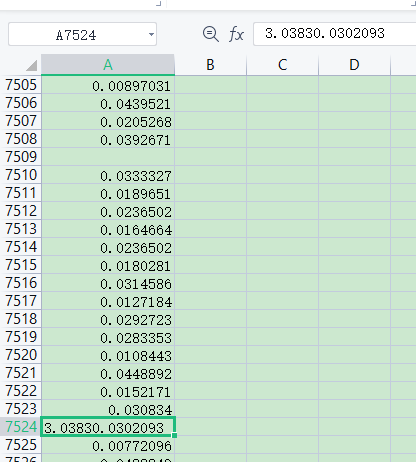
给你们提供一部分数据:
-0.0244498
8.00209-0.0450641
0.00740863
0.00428525
-0.00789592
-0.012581
-0.0353816
-0.00446021
-0.0141427
-0.0319459
-0.00414787
-0.0269485
30.0128933
-0.012890.00366057
-0.0281979
-0.0225758
-0.00196151
-0.0369433
0.0080333
-0.037568
-0.0110193
-0.00539722
-0.0207018
-0.0263239
0.0136554
-0.0197648
0.0142801
-0.0378803
-0.0303842
0.0111567
-0.0222635
-0.0256992
-0.0113316
-0.016329
-0.00133683
0.0111567
0.0245872
-0.0100823
-0.00664657
-0.015392
-0.0360063
0.00522226
0.00459759
-0.0188277
-0.0260115
-0.0313213
0.00834564
-0.011644
-0.00539722
-0.0244498
0.0117814
-0.0225758
0.0283353
-0.00539722
-0.0288226
80.0182031
-0.032250.0233379
3.03830.0302093
0.007720963、相关技术
捕获异常 try…except
编写格式
Exception代码要捕获的异常,as e代表储存异常的基本信息try: #写一个 try 把可能出错的代码放进去。 代码段 except Exception as e:# 写一个except 获取到异常时的处理 # 书写捕获异常的处理方案- 1
- 2
- 3
- 4
示例:
try: values = .0.00147421 values = float(values) except Exception as e: print(values) print(e)- 1
- 2
- 3
- 4
- 5
- 6
4、完整代码和步骤
主运行程序入口
import pandas as pd import numpy as np data = pd.read_csv('3.xlsx', sep='\t', dtype=str, names=['col'], error_bad_lines=False) for index, one in data.iterrows(): values = one[0] resoult = {} for i in values: resoult[i] = values.count(i) print(resoult) values = values.replace('.0.', '0.') if '.0.' in values: data.drop(index=index) if '.' in resoult.keys(): if resoult['.'] > 1: data.drop(index=index) if values == '.0.00147421': data.drop(index=index) try: values = float(values) except: print(values) data.drop(index=index) if data.shape[0] < 10324: data = np.append(data.values, [0.0] * (10324 - data.shape[0])) print(len(data)) for i in range(len(data)): try: data[i] = float(data[i]) except: print(data[i]) np.delete(data, [i], axis=0) data = data.astype(float)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
-
相关阅读:
opencv 人脸识别,并抓拍
第三部分—数据结构与算法基础_5. 排序算法
算法通关村第九关-青铜挑战二分查找算法
软件过程与管理_期末复习知识点回顾总结
从 ArcMap 迁移到 ArcGIS Pro
DHCPsnooping 配置实验(2)
显卡天梯图2022年11月新版 显卡性能排行榜天梯图
OceanBase 金融项目优化案例
Android学习笔记 28. Fragement总结
Python使用GARCH,EGARCH,GJR-GARCH模型和蒙特卡洛模拟进行股价预测
- 原文地址:https://blog.csdn.net/qq_30803353/article/details/126317754