-
论文阅读 CVPR2022《Rethinking Semantic Segmentation:A Prototype View》

回顾一下语义分割,其实可以分为两种。一种是参数化的softmax投射,另一种是部分transformer的方法——query based的方法。
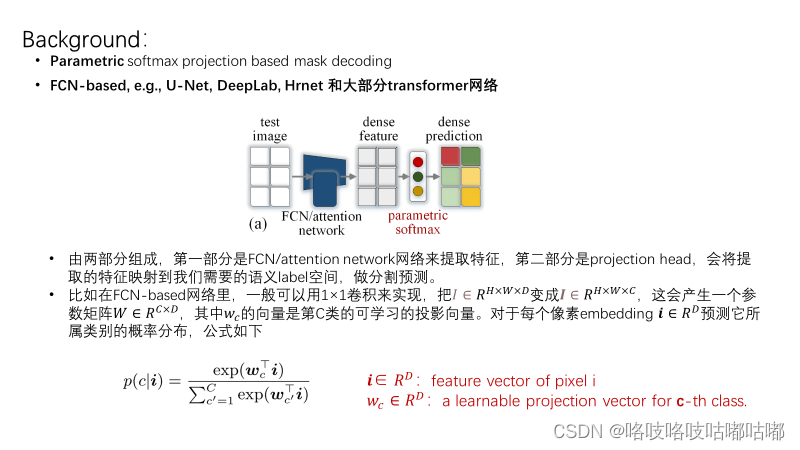

再回到论文的题目
 关于prototype的类似定义,可参考18年一篇图像分类的工作。
关于prototype的类似定义,可参考18年一篇图像分类的工作。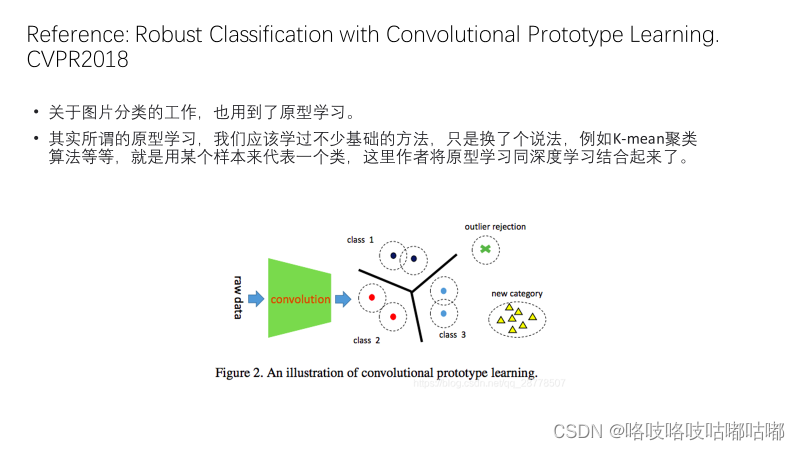

文中作者一直强调关于一张图片里的像素投射的embedding space的结构是缺乏关注的,这个思想在他去年的一项工作里就有涉及,他提出了一个insight的问题,如下图红字。

因此,基于这个well-structured embeddings space和投射头的参数这两个motivations,作者提出了本文的方法。下面具体来看方法的内容(提醒一下:PPT所展示的内容有限,具体还是推荐去看看原文。)
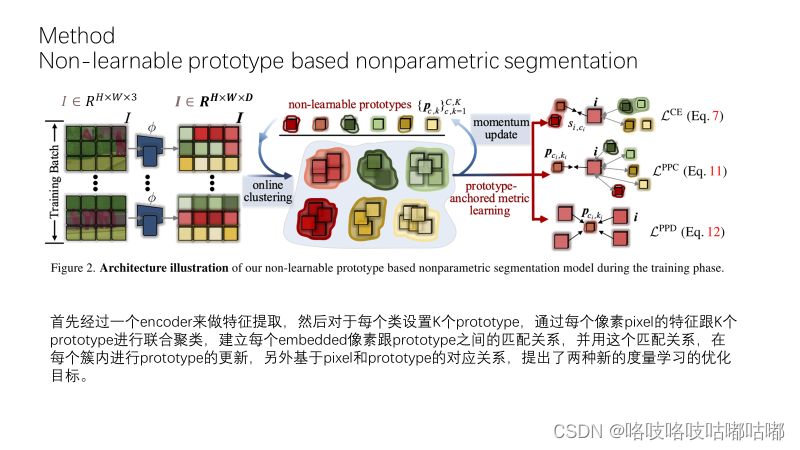
对于每个像素 i 会计算与所有portotype之间的相似度,选取跟像素i最相近的prototype。这个prototype对应的类别就是像素对应的类别。在网络训练过程中,可以计算每个 i 在c个类别上的概率分布,然后我们用交叉熵损失来进行网络的训练,但交叉熵损失的有缺陷的,只考虑了pixel和class之间的关系,没有考虑和proto之间的关系,也就是只保证了类间的分散,没有保证类内的紧凑。

接下来首先介绍在线聚类的算法,基于在线聚类结果,介绍提出的两个新的metric learning 的训练目标。
聚类是对每个类别单独进行的处理,前两个约束保证每个c类内的像素点只能匹配到一个prototype,第三个约束是鼓励所有的像素点均匀匹配到各个prototype,避免许多个像素点几乎都匹配到同一个prototype上了。此外作者还为了快速求解矩阵运算,对式子做了一定松弛,不具体解释了。

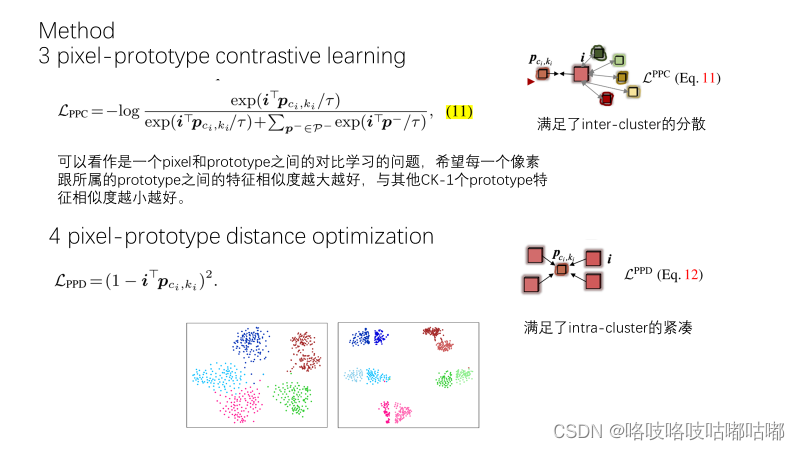
前面提到了,交叉熵损失着眼的是类间inter-class,设计的ppc则是在同一个类内,不同prototype之间的分散,再来一个ppd损失,着眼于同一个簇内,像素点与prototype的紧凑性优化.



 comment:
comment:因为我现在刚刚起步阅读论文,读的书还比较少,读了这篇论文之后的一个感悟是,或许一项工作不一定要有惊人的改动,改进才算好工作吧(看了李沐老师对于novelty的理解)?能感受到作者是在循序渐进的思考一些东西,而且感觉很本质诶?很厉害。。一开始粗读的时候感觉整个方法很朴实无华,但整个读下来又感觉能想到从embedding space角度以及用统一的视角去找到相通之处,其实好难啊。这篇工作拿到了oral,应该是有他的价值存在的,只是现在的我还体会不够深?这种对于性能提升较有贡献的改进,或许能在实际应用、比赛中发挥更多价值?值得学习。。
最后,PS:
每次论文阅读分享要做PPT,真的特别损伤元气orz,不过也确实督促我更好更仔细的去阅读每一个细节了,尽量把不懂的地方弥补清楚。别看ppt看起来觉得论文思路非常简单清晰,但感觉这真的是一个拆炸弹的过程,需要耐心、反复,自己搞懂了逻辑,才敢给大家分享。。。疲惫.jpg
希望自己能越来越游刃有余!~
一起讨论学习呀
-
相关阅读:
误删记录/表/库怎么办?该如何防范误删?
【HTML】前端网页开发工具Vscode中DOCTYPE和lang以及字符集的作用
【Stm32】【Lin通信协议】Lin通信点亮灯实验
GPU进程暂停(CTRL+Z)后,进程保留,显存保留,需要清理进程释放缓存。
WPF 笔迹算法 从点集转笔迹轮廓
【构建一套Spring Cloud项目的大概步骤】&【Springcloud Alibaba微服务分布式架构学习资料】
计算机毕设 大数据商城人流数据分析与可视化 - python 大数据分析
【C#】认识C# (为了游戏开发 O(≧口≦)O)
02.初识C语言2
【探索Linux】—— 强大的命令行工具 P.23(线程池 —— 简单模拟)
- 原文地址:https://blog.csdn.net/weixin_41469023/article/details/126316853