-
Java网络编程-IO模型篇之从BIO、NIO、AIO到内核select、epoll剖析
引言
IO(Input/Output)方面的基本知识,相信大家都不陌生,毕竟这也是在学习编程基础时就已经接触过的内容,但最初的IO教学大多数是停留在最基本的BIO,而并未对于NIO、AIO、多路复用等的高级内容进行详细讲述,但这些却是大部分高性能技术的底层核心,因此本文则准备围绕着IO知识进行展开。BIO、NIO、AIO、多路复用等内容其实在很多文章中都有谈及到,但很多仅是停留在理论层次的定义,以及表面内容的讲解,很少有文章去深入剖析底层的实现,这样会让读者很难去理解IO的基本原理。而本文则打算结合多线程知识以及系统内核函数,对IO方面的内容进行全方面的剖析。一、IO基本概念综述
对于
IO知识,想要真正的去理解它,需要结合多线程、网络、操作系统等多方面的知识,IO最开始的定义就是指计算机的输入流和输出流,在这里主体为计算机本身,当然主体也可以是一个程序。PS:从外部设备(如
U盘、光盘等)中读取数据,这可以被称为输入,而在网络中读取一段数据,这也可以被称为输入。最初的
IO流也只有阻塞式的输入输出,但由于时代的不断进步,技术的不停迭代,慢慢的IO也会被分为很多种,接下来咱们聊聊IO的分类。1.1、IO的分类
IO以不同的维度划分,可以被分为多种类型,比如可以从工作层面划分成磁盘IO(本地IO)和网络IO:- 磁盘
IO:指计算机本地的输入输出,从本地读取一张图片、一段音频、一个视频载入内存,这都可以被称为是磁盘IO。 - 网络
IO:指计算机网络层的输入输出,比如请求/响应、下载/上传等,都能够被称为网络IO。
也可以从工作模式上划分,例如常听的
BIO、NIO、AIO,还可以从工作性质上分为阻塞式IO与非阻塞式IO,亦或从多线程角度也可被分为同步IO与异步IO,这么看下来是不是感觉有些晕乎乎的?没关系,接下来我们对IO体系依次全方位进行解析。1.2、IO工作原理
无论是Java还是其他的语言,本质上
IO读写操作的原理是类似的,编程语言开发的程序,一般都是工作在用户态空间,但由于IO读写对于计算机而言,属于高危操作,所以OS不可能100%将这些功能开放给用户态的程序使用,所以正常情况下的程序读写操作,本质上都是在调用OS内核提供的函数:read()、 write()。也就是说,在程序中试图利用
IO机制读写数据时,仅仅只是调用了内核提供的接口函数而已,本质上真正的IO操作还是由内核自己去完成的。IO工作的过程如下: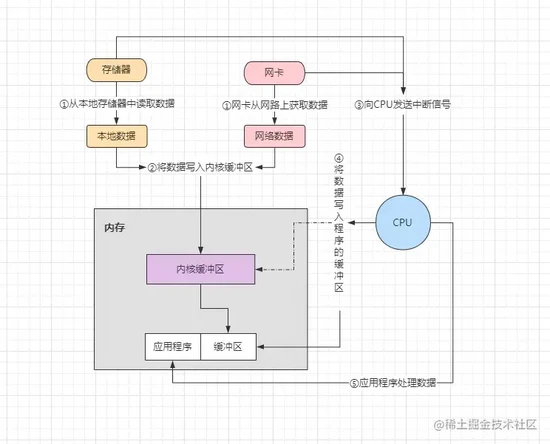
- ①首先在网络的网卡上或本地存储设备中准备数据,然后调用
read()函数。 - ②调用
read()函数厚,由内核将网络/本地数据读取到内核缓冲区中。 - ③读取完成后向
CPU发送一个中断信号,通知CPU对数据进行后续处理。 - ④
CPU将内核中的数据写入到对应的程序缓冲区或网络Socket接收缓冲区中。 - ⑤数据全部写入到缓冲区后,应用程序开始对数据开始实际的处理。
在上述中提到了一个
CPU中断信号的概念,这其实属于一种I/O的控制方式,IO控制方式目前主要有三种: 忙等待方式、中断驱动方式以及DMA直接存储器方式 ,不过无论是何种方式,本质上的最终作用是相同的,都是读取数据的目的。在上述
IO工作过程中,其实大体可分为两部分: 准备阶段和复制阶段 ,准备阶段是指数据从网络网卡或本地存储器读取到内核的过程,而复制阶段则是将内核缓冲区中的数据拷贝至用户态的进程缓冲区。常听的BIO、NIO、AIO之间的区别,就在于这两个过程中的操作是同步还是异步的,是阻塞还是非阻塞的。1.3、内核态与用户态
用户态与内核态这两个词汇在前面多次提及到,也包括之前在分析 《Synchronized关键字实现原理》 时也曾讲到过用户态和内核态的切换,那它两究竟是什么意思呢?先上图:
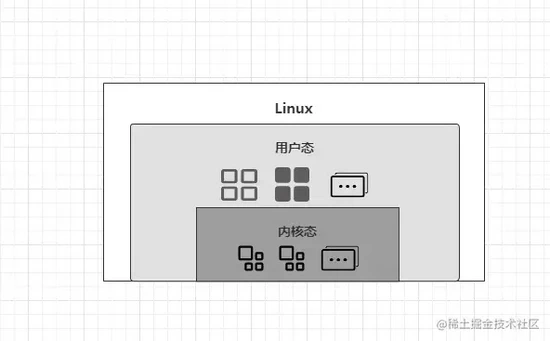
Linux为了确保系统足够稳定与安全,因此在运行过程中会将内存划分为内核空间与用户空间,其中运行在用户空间的程序被称为“用户态”程序,同理,运行在“内核态”的程序则被称为“内核态”程序,而普通的程序一般都会运行在用户空间。那么系统为什么要这样设计呢?因为如果内核与用户空间都为同一块儿,此时假设某个程序执行异常导致崩溃了,最终会导致整个系统也出现崩溃,而划分出两块区域的目的就在于:用户空间中的某个程序崩溃,那自会影响自身,而不会影响系统整体的运行。
同时为了防止普通程序去进行
IO、内存动态调整、线程挂起等一些高危操作引发系统崩溃,因此这些高危操作的具体执行,也只能由内核自己来完成,但程序中有时难免需要用到这些功能,因此内核也会提供很多的函数/接口提供给外部调用。当处于用户态的程序调用某个内核提供的函数时,此时由于用户态自身不具备这些函数的执行权限,因此会发生用户态到内核态的切换,也就是说:当程序调用某个内核提供的函数后,具体的操作会切换成内核自己去执行。
但用户态与内核态切换时,由于需要处理操作句柄、保存现场、执行系统调用、恢复现场等等过程,因此状态切换其实也是一个开销较大的动作,因此在设计程序时,要尽量减少会发生状态切换的事项,比如Java中,解决线程安全能用
ReetrantLock的情况下则尽量不使用Synchronized。最后对于用户态和内核态的区别,用大白话来说就是:类似于做程序开发时, 普通用户和管理员的区别 ,为了防止普通用户到处乱点,从而导致系统无法正常运转,因此有些权限只能开放给管理员身份执行,例如删库~
1.4、同步与异步
在上面我们提及到了同步与异步的概念,相信掌握多线程技术的小伙伴对这两个概念并不陌生,这两个概念本身并不难理解,上个<熊猫煮泡面>的栗子:
①先烧水,再开封泡面倒调料,倒开水,等泡面泡好,开吃。
②“熊猫”要煮泡面,然后“竹子”听到了,接下来由竹子去做一系列的工作,泡面好了之后,竹子会端过来或告诉熊猫可以了,然后开吃。
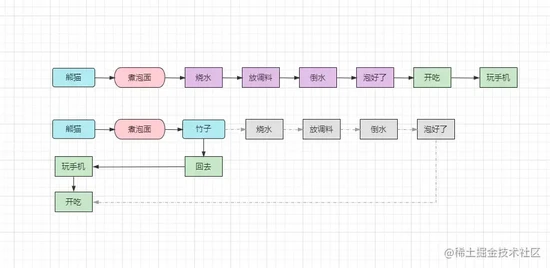
在这个栗子中,第一种情况就属于同步执行的,每一个步骤都需要建立在上一个步骤的基础上依次进行,一步一步全部做完了才能吃上泡面,最后玩手机。而第二种情况则属于异步执行的,熊猫主要煮泡面时,只需要告诉竹子后就能立马回去玩手机了,其他的一系列工作都会由竹子完成,最后熊猫也能吃上泡面。
在这个例子中,熊猫可以理解成主线程,竹子又可以理解成另外一个线程,同步是指线程串行的依次执行,异步则是可以将自己要做的事情交给其他线程执行,然后主线程就能立马返回干其他事情。
1.5、阻塞与非阻塞
同步与阻塞,异步与非阻塞,很多人都会对这两组概念产生疑惑,都会有些区分不清,这是由于它们之间的确是存在关系的,而且是相辅相成的关系,从某种意义上来说: “同步天生就是阻塞的,异步天生就是非阻塞的” 。这句话听起来似乎有些难以理解,那先来看看阻塞与非阻塞的概念:
- 阻塞:对于需要的条件不具备时会一直等待,直至具备条件时才继续往下执行。
- 非阻塞:对于需要的条件不具备时不会等待,而是直接返回等后期具备条件时再回来。
还是之前<熊猫煮泡面>的例子,在第一种同步执行的事件中,由于烧水、泡面等过程都需要时间,因此在这些过程中,由于条件还不具备(水还没开,泡面还没熟),所以熊猫会在原地傻傻等待条件满足(等水开,等泡面熟),那这个过程就是阻塞式过程。
反之,在第二种异步执行的事件中,由于煮泡面的活交给竹子去做了,因此烧水、泡面这些需要等待条件满足的过程,自己都无需等待条件满足,所以在<煮泡面>这个过程中,对于熊猫而言就是非阻塞式的过程。
噼里啪啦一大堆下来,这跟我们本次的主题有何关系呢?
其实这些跟本次的内容关系很大,因为基于上述的概念来说,
IO总共可被分为四大类:同步阻塞式IO、同步非阻塞式IO、异步阻塞式IO、异步非阻塞式IO,当然,由于异步执行在一定程度上而言,天生就是非阻塞式的,因此不存在异步阻塞式IO的说法。二、Linux的五种IO模型浅析
在上述中,对于一些
IO、同步与异步、阻塞与非阻塞等基础概念已经有了基本认知,那此时再将这些概念结合起来后,同步阻塞IO、同步非阻塞IO.....,这又如何理解呢?接下来则依次按顺展开。Linux系统中共计提供了五种IO模型,它们分别为BIO、NIO、多路复用、信号驱动、AIO,从性能上来说,它们属于依次递进的关系,但越靠后的IO模型实现也越为复杂。2.1、同步阻塞式IO-BIO
BIO(Blocking-IO)即同步阻塞模型,这也是最初的IO模型,也就是当调用内核的read()函数后,内核在执行数据准备、复制阶段的IO操作时,应用线程都是阻塞的,所以本次IO操作则被称为同步阻塞式IO,如下: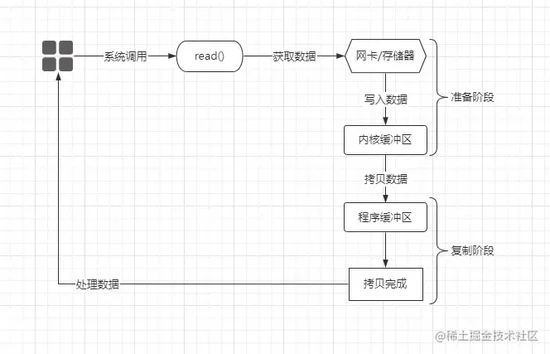
当程序中需要进行
IO操作时,会先调用内核提供的read()函数,但在之前分析过IO的工作原理,IO会经过“设备→内核缓冲区→程序缓冲区”这个过程,该过程必然是耗时的,在同步阻塞模型中,程序中的线程发起IO调用后,会一直挂起等待,直至数据成功拷贝至程序缓冲区才会继续往下执行。简单了解了
BIO的含义后,那此刻思考一个问题: 当本次IO操作还在执行时,又出现多个IO调用,比如多个网络数据到来,此刻该如何处理呢?很简单,采用多线程实现,包括最初的
IO模型也的确是这样实现的,也就是当出现一个新的IO调用时,服务器就会多一条线程去处理,因此会出现如下情况: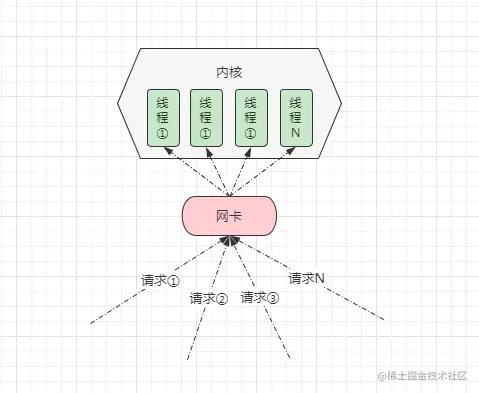
在
BIO这种模型中,为了支持并发请求,通常情况下会采用“请求:线程”1:1的模型,那此时会带来很大的弊端:- ①并发过高时会导致创建大量线程,而线程资源是有限的,超出后会导致系统崩溃。
- ②并发过高时,就算创建的线程数未达系统瓶颈,但由于线程数过多也会造成频繁的上下文切换。
但在
Java常用的Tomcat服务器中,Tomcat7.x版本以下默认的IO类型也是BIO,但似乎并未碰到过:并发请求创建大量线程导致系统崩溃的情况出现呢?这是由于Tomcat中对BIO模型稍微进行了优化,通过线程池做了限制: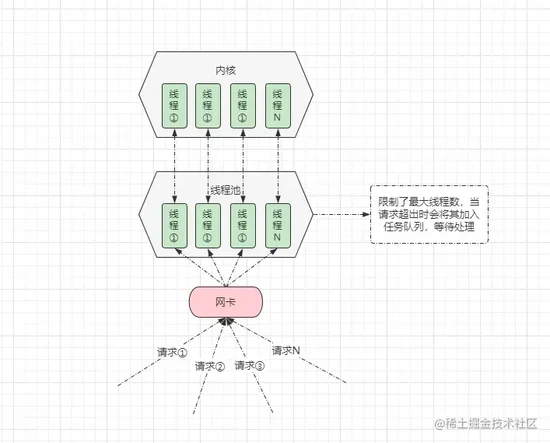
在
Tomcat中,存在一个处理请求的线程池,该线程池声明了核心线程数以及最大线程数,当并发请求数超出配置的最大线程数时,会将客户端的请求加入请求队列中等待,防止并发过高造成创建大量线程,从而引发系统崩溃。2.2、同步非阻塞式IO-NIO
NIO(Non-Blocking-IO)同步非阻塞模型,从字面意思上来说就是:调用read()函数的线程并不会阻塞,而是可以正常运行,如下: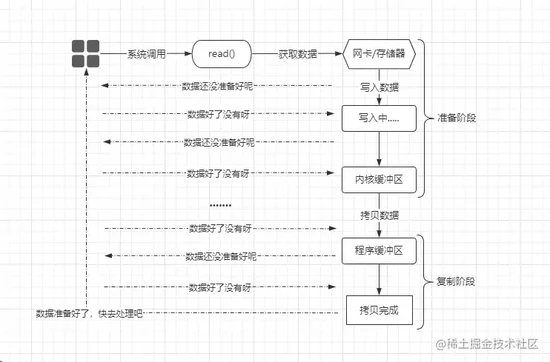
当应用程序中发起
IO调用后,内核并不阻塞当前线程,而是立马返回一个“数据未就绪”的信息给应用程序,而应用程序这边则一直反复轮询去问内核:数据有没有准备好?直到最终数据准备好了之后,内核返回“数据已就绪”状态,紧接着再由进程去处理数据.....其实相对来说,这个过程虽然没有阻塞发起
IO调用的线程,但实际上也会让调用方不断去轮询发起“数据是否准备好”的信号,这也并非真正意义上的非阻塞,就好比:原本竹子在给熊猫煮泡面,然后熊猫就一直在旁边等着泡面煮好(同步阻塞式),在这个过程中熊猫是“阻塞”的。
现在竹子给熊猫煮泡面。熊猫告诉竹子要吃泡面后就立马回去了,但是过了一会儿又跑回来:泡面有没有好?然后竹子回答没好,然后片刻后又回来问泡面有没有好?竹子又回答还没好......,一直反复循环这个过程直到泡面好了为止。
通过如上的例子,应该能明显感受到这种所谓的
NIO相对来说较为鸡肋,因此目前大多数的NIO技术并非采用这种多线程的模型,而是基于单线程的 多路复用模型 实现的,Java中支持的NIO模型亦是如此。2.3、多路复用模型
在理解多路复用模型之前,我们先分析一下上述的
NIO模型到底存在什么问题呢?很简单,由于线程在不断的轮询查看数据是否准备就绪,造成CPU开销较大。既然说是由于大量无效的轮询造成CPU占用过高,那么等内核中的数据准备好了之后,再去询问数据是否就绪是不是就可以了?答案是Yes。那又该如何实现这个功能呢?此时大名鼎鼎的 多路复用模型 登场了,该模型是基于文件描述符
File Descriptor实现的,在Linux中提供了select、poll、epoll等一系列函数实现该模型,结构如下: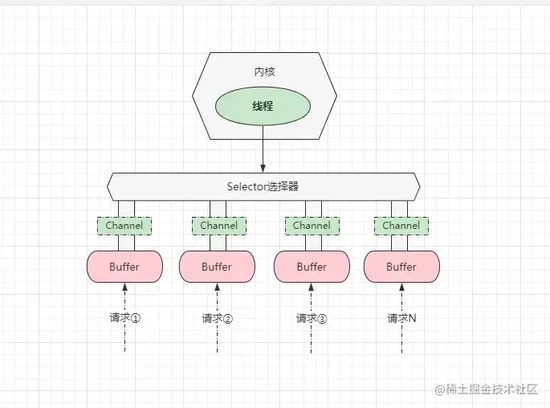
在多路复用模型中,内核仅有一条线程负责处理所有连接,所有网络请求/连接(
Socket)都会利用通道Channel注册到选择器上,然后监听器负责监听所有的连接,过程如下: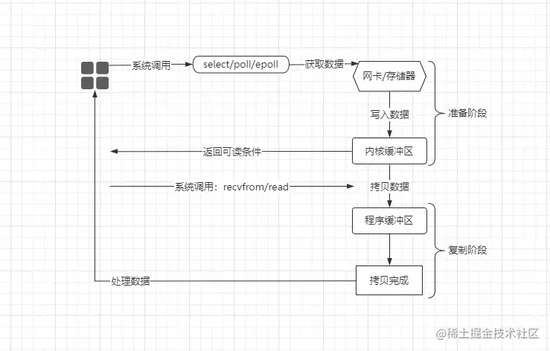
当出现一个
IO操作时,会通过调用内核提供的多路复用函数,将当前连接注册到监听器上,当监听器发现该连接的数据准备就绪后,会返回一个可读条件给用户进程,然后用户进程从内核中将数据拷出来后进行处理。这里面涉及到一个概念:系统调用,本意是指调用内核所提供的API接口函数。
recvfrom函数则是指经Socket套接字接收数据,主要用于网络IO操作。read函数则是指从本地读取数据,主要用于本地的文件IO操作。此时对比之前的
NIO模型,是不是看起来就性能方面好很多啦?当然是的,不过多路复用模型远比咱们想象的要复杂很多,在后面会深入剖析。2.4、信号驱动模型
信号驱动
IO模型(Signal-Driven-IO)是一种偏异步IO的模型,在该模型中引入了信号驱动的概念,在用户进程中首先会创建一个SIGIO信号处理程序,然后基于信号的模型进行处理,如下: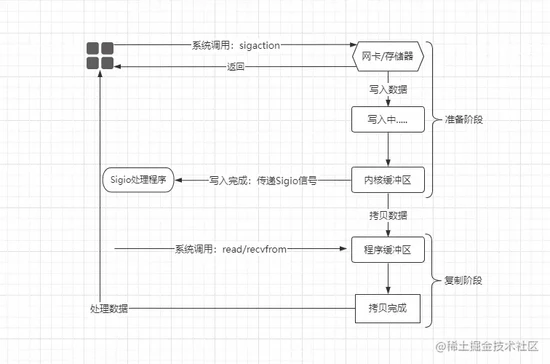
在该模型中,首先用户进程中会创建一个
Sigio信号处理程序,然后会系统调用sigaction信号处理函数,紧接着内核会直接让用户进程中的线程返回,用户进程可在这期间干别的工作,当内核中的数据准备好之后,内核会生成一个Sigio信号,通知对应的用户进程数据已准备就绪,然后由用户进程在触发一个recvfrom的系统调用,从内核中将数据拷贝出来进行处理。信号驱动模型相较于之前的模型而言,从一定意义上实现了异步,也就是数据的准备阶段是异步非阻塞执行的,但数据的复制阶段却依旧是同步阻塞执行的。
纵观上述的所有
IO模型:BIO、NIO、多路复用、信号驱动,本质上从内核缓冲区拷贝数据到程序缓冲区的过程都是阻塞的,如果想要做到真正意义上的异步非阻塞IO,那么就牵扯到了AIO模型。2.5、异步非阻塞式IO-AIO
AIO(Asynchronous-Non-Blocking-IO)异步非阻塞模型,该模型是真正意义上的异步非阻塞式IO,代表数据准备与复制阶段都是异步非阻塞的: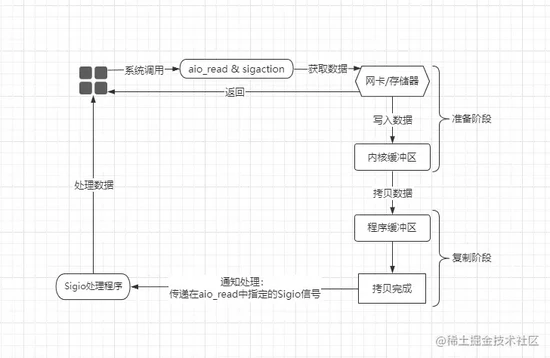
在
AIO模型中,同样会基于信号驱动实现,在最开始会先调用aio_read、sigaction函数,然后用户进程中会创建出一个信号处理程序,同时用户进程可立马返回执行其他操作,在数据写入到内核、且从内核拷贝到用户缓冲区后,内核会通知对应的用户进程对数据进行处理。在
AIO模型中,真正意义上的实现了异步非阻塞,从始至终用户进程只需要发起一次系统调用,后续的所有IO操作由内核完成,最后在数据拷贝至程序缓冲区后,通知用户进程处理即可。2.6、五种IO模型小结
还是以《竹子给熊猫煮泡面》的过程为例,煮泡面的过程也可以大体分为两步:
- 准备阶段:烧水、拆泡面、倒调料、倒水。
- 等待阶段:等泡面熟。
煮泡面的这两个阶段正好对应
IO操作的两个阶段,用这个案例结合前面的五种IO模型理解:- 事件前提:熊猫要吃泡面,竹子听到后开始去煮。
BIO:竹子煮泡面时,熊猫从头到尾等待,期间不干任何事情就等泡面煮好。NIO:竹子煮泡面时,让熊猫先回去坐着等,熊猫期间动不动过来问一下泡面有没有好。多路复用:和
BIO过程相差无几,主要区别在于多个请求时不同,单个不会有提升。信号驱动:竹子煮泡面时,让熊猫先回去坐着等,并且给了熊猫一个铃铛,当泡面准备阶段完成后,竹子摇一下铃铛通知熊猫把泡面端走,然后熊猫等泡面熟了开吃。
AIO:竹子煮泡面时,让熊猫先回去坐着等,并且给了熊猫一个铃铛,当泡面熟了后摇一下铃铛通知熊猫开吃。三、Java中BIO、NIO、AIO详解
在简单聊完了五种
IO模型后,咱们再转过头来看看Java语言所提供的三种IO模型支持,分别为BIO、NIO、AIO,BIO代表同步阻塞式IO,NIO代表同步非阻塞式IO,而AIO对应着异步非阻塞式IO,但其中的NIO与上述分析的不同,Java中的NIO实现是基于多路复用模型的,接下来则依次来展开叙述。为了方便叙述,所有案例中的
IO类型都以网络IO操作举例说明!3.1、Java-BIO模型
BIO就是Java的传统IO模型,与其相关的实现都位于java.io包下,其通信原理是客户端、服务端之间通过Socket套接字建立管道连接,然后从管道中获取对应的输入/输出流,最后利用输入/输出流对象实现发送/接收信息,案例如下:// BIO服务端 public class BioServer { public static void main(String[] args) throws IOException { System.out.println(">>>>>>>...BIO服务端启动...>>>>>>>>"); // 1.定义一个ServerSocket服务端对象,并为其绑定端口号 ServerSocket server = new ServerSocket(8888); // 2.监听客户端Socket连接 Socket socket = server.accept(); // 3.从套接字中得到字节输入流并封装成输入流对象 InputStream inputStream = socket.getInputStream(); BufferedReader readBuffer = new BufferedReader(new InputStreamReader(inputStream)); // 4.从Buffer中读取信息,如果读到信息则输出 String msg; while ((msg = readBuffer.readLine()) != null) { System.out.println("收到信息:" + msg); } // 5.从套接字中获取字节输出流并封装成输出对象 OutputStream outputStream = socket.getOutputStream(); PrintStream printStream = new PrintStream(outputStream); // 6.通过输出对象往服务端传递信息 printStream.println("Hi!我是竹子~"); // 7.发送后清空输出流中的信息 printStream.flush(); // 8.使用完成后关闭流对象与套接字 outputStream.close(); inputStream.close(); socket.close(); inputStream.close(); outputStream.close(); socket.close(); server.close(); } } // BIO客户端 public class BioClient { public static void main(String[] args) throws IOException { System.out.println(">>>>>>>...BIO客户端启动...>>>>>>>>"); // 1.创建Socket并根据IP地址与端口连接服务端 Socket socket = new Socket("127.0.0.1", 8888); // 2.从Socket对象中获取一个字节输出流并封装成输出对象 OutputStream outputStream = socket.getOutputStream(); PrintStream printStream = new PrintStream(outputStream); // 3.通过输出对象往服务端传递信息 printStream.println("Hello!我是熊猫~"); // 4.通过下述方法告诉服务端已经完成发送,接下来只接收消息 socket.shutdownOutput(); // 5.从套接字中获取字节输入流并封装成输入对象 InputStream inputStream = socket.getInputStream(); BufferedReader readBuffer = new BufferedReader(new InputStreamReader(inputStream)); // 6.通过输入对象从Buffer读取信息 String msg; while ((msg = readBuffer.readLine()) != null) { System.out.println("收到信息:" + msg); } // 7.发送后清空输出流中的信息 printStream.flush(); // 8.使用完成后关闭流对象与套接字 outputStream.close(); inputStream.close(); socket.close(); } } 复制代码分别启动
BioServer、BioClient类,运行结果如下:// ------服务端--------- >>>>>>>...BIO服务端启动...>>>>>>>> 收到信息:Hello!我是熊猫~ // ------客户端--------- >>>>>>>...BIO客户端启动...>>>>>>>> 收到信息:Hi!我是竹子~ 复制代码
观察如上结果,其实执行过程原理很简单:
- ①服务端启动后会执行
accept()方法等待客户端连接到来。 - ②客户端启动后会通过
IP及端口,与服务端通过Socket套接字建立连接。 - ③然后双方各自从套接字中获取输入/输出流,并通过流对象发送/接收消息。
大体过程如下:
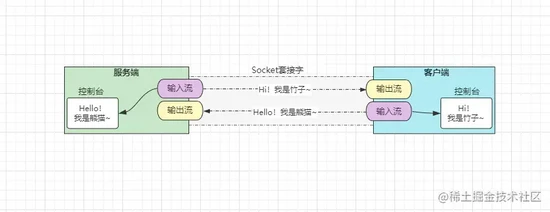
在上述
Java-BIO的通信过程中,如若客户端一直没有发送消息过来,服务端则会一直等待下去,从而服务端陷入阻塞状态。同理,由于客户端也一直在等待服务端的消息,如若服务端一直未响应消息回来,客户端也会陷入阻塞状态。3.2、Java-NIO模型
Java-NIO则是JDK1.4中新引入的API,它在BIO功能的基础上实现了非阻塞式的特性,其所有实现都位于java.nio包下。NIO是一种基于通道、面向缓冲区的IO操作,相较BIO而言,它能够更为高效的对数据进行读写操作,同时与原先的BIO使用方式也大有不同。Java-NIO是基于多路复用模型实现的,其中存在三大核心理念:Buffer(缓冲区)、Channel(通道)、Selector(选择器) ,与BIO还有一点不同在于:由于BIO模型中数据传输是阻塞式的,因此必须得有一条线程维护对应的Socket连接,在此期间如若未读取到数据,该线程就会一直阻塞下去。而NIO中则可以用一条线程来处理多个Socket连接,不需要为每个连接都创建一条对应的线程维护。具体原因我们先慢慢聊,稍后你就理解了!先来看看
NIO三大件。3.2.1、Buffer缓冲区
缓冲区其实本质上就是一块支持读/写操作的内存,底层是由多个内存页组成的数组,我们可以将其称之为内存块,在Java中这块内存则被封装成了
Buffer对象,需要使用可直接通过已提供的API对这块内存进行操作和管理。再来看看Java-NIO封装的Buffer类:// 缓冲区抽象类 public abstract class Buffer { // 标记位,与mark()、reset()方法配合使用, // 可通过mark()标记一个索引位置,后续可随时调用reset()恢复到该位置 private int mark = -1; // 操作位,下一个要读取或写入的数据索引 private int position = 0; // 限制位,表示缓冲区中可允许操作的容量,超出限制后的位置不能操作 private int limit; // 缓冲区的容量,类似于声明数组时的容量 private int capacity; long address; // 清空缓冲区数据并返回对缓冲区的引用指针 // (其实调用该方法后缓冲区中的数据依然存在,只是处于不可访问状态) // 该方法还有个作用:就是调用该方法后会从读模式切换回写模式 public final Buffer clear(); // 调用该方法后会将缓冲区从写模式切换为读模式 public final Buffer flip(); // 获取缓冲区的容量大小 public final int capacity(); // 判断缓冲区中是否还有数据 public final boolean hasRemaining(); // 获取缓冲区的界限大小 public final int limit(); // 设置缓冲区的界限大小 public final Buffer limit(int n); // 对缓冲区设置标记位 public final Buffer mark(); // 返回缓冲区当前的操作索引位置 public final int position(); // 更改缓冲区当前的操作索引位置 public final Buffer position(int n); // 获取当前索引位与界限之间的元素数量 public final int remaining(); // 将当前索引转到之前标记的索引位置 public final Buffer reset(); // 重置操作索引位并清空之前的标记 public final Buffer rewind(); // 省略其他不常用的方法..... } 复制代码对于Java中缓冲区的定义,首先要明白,当缓冲区被创建出来后,同一时刻只能处于读/写中的一个状态,同一时间内不存在即可读也可写的情况。理解这点后再来看看它的成员变量,重点理解下述三个成员:
pasition capacity limit
上个逻辑图来理解一下三者之间的关系,如下:
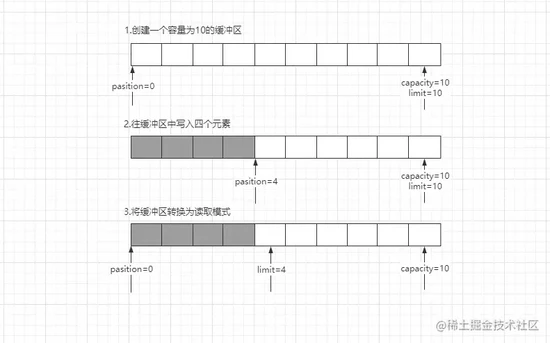
通过上述这个例子应该能很直观的感受出三者之间的关系,
pasition是变化的,每次都会记录着下一个要操作的索引下标,当发生模式切换时,操作位会置零,因为模式切换代表新的开始。简单了解了一下成员变量后,再来看看其中提供的一些成员方法,重点记住
clear()、flip()方法,这两个方法都可以让缓冲区发生模式转换,flip()可以从写模式切换到读模式,而clear()方法本质上是清空缓冲区的意思,但清空后就代表着缓冲区回归“初始化”了,因此也可以从读模式转换到最初的写模式。不过要注意:
Buffer类仅是一个抽象类,所以并不能直接使用,因此当我们需要使用缓冲区时,需要实例化它的子类,但它的子类有几十之多,但一般较为常用的子类就只有八大基本数据类型的缓冲区,如ByteBuffer、CharBuffer、IntBuffer......Buffer缓冲区的使用方式
当需要使用缓冲区时,都是通过
xxxBuffer.allocate(n)的方式创建,例如:ByteBuffer buffer = ByteBuffer.allocate(10); 复制代码
上述代码表示创建一个容量为
10的ByteBuffer缓冲区,当需要使用该缓冲区时,都是通过其提供的get/put类方法进行操作,这也是所有Buffer子类都会提供的两类方法,具体如下:// 读取缓冲区中的单个元素(根据position决定读取哪个元素) public abstract xxx get(); // 读取指定索引位置的字节(不会移动position) public abstract xxx get(int index); // 批量读取多个元素放入到dst数组中 public abstract xxxBuffer get(xxx[] dst); // 根据指定的偏移量(起始下标)和长度,将对应的元素读取到dst数组中 public abstract xxxBuffer get(xxx[] dst, int offset, int length); // 将单个元素写入缓冲区中(根据position决定写入位置) public abstract xxxBuffer put(xxx b); // 将多个元素写入缓冲区中(根据position决定写入位置) public abstract xxxBuffer put(xxx[] src); // 将另一个缓冲区写入进当前缓冲区中(根据position决定写入位置) public abstract xxxBuffer put(xxxBuffer src); // 向缓冲区的指定位置写入单个元素(不会移动position) public abstract xxxBuffer put(int index, xxx b); // 根据指定的偏移量和长度,将多个元素写入缓冲区中 public abstract xxxBuffer put(xxx[] src, int offset, int length); 复制代码
Buffer缓冲区的使用方式与Map容器的读/写操作类似,通过get读取数据,通过put写入数据。不过一般在使用缓冲区的时候都会遵循如下步骤:
put flip() get clear()、compact()
Buffer缓冲区的分类
Java中的缓冲区也被分为了两大类: 本地直接内存缓冲区与堆内存缓冲区 ,前面
Buffer类的所有子实现类xxxBuffer本质上还是抽象类,每个子抽象类都会有DirectXxxBuffer、HeapXxxBuffer两个具体实现类,这两者的主要区别在于:创建缓冲区的内存是位于堆空间之内还是之外。一般情况下,直接内存缓冲区的性能会高于堆内存缓冲区,但申请后却需要自行手动管理,不像堆内存缓冲区由于处于堆空间中,会有
GC机制自动管理,所以直接内存缓冲区的安全风险要高一些。两者之间的工作原理如下: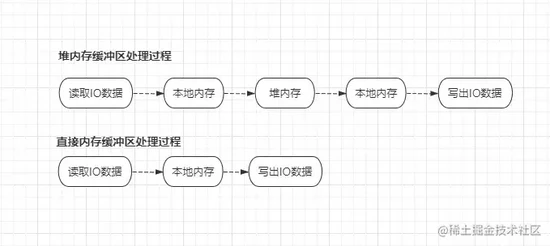
由于堆缓冲区创建后是存在于堆空间中的,所以
IO数据必须要经过一次本地内存的“转发后”才能达到堆内存,因此效率自然会低一些,同时也会占用Java堆空间。所以如若追求更好的IO性能,或IO数据过于庞大时,可通过xxxBuffer.allocateDirect()方法创建本地缓冲区使用,也可以通过isDirect()方法来判断一个缓冲区是否基于本地内存创建。3.2.2、Channel通道
NIO中的通道与BIO中的流对象类似,但BIO中要么是输入流,要么是输出流,通常流操作都是单向传输的。而通道的功能也是用于传输数据,但它却是一个双向通道,代表着我们即可以从通道中读取对端数据,也可以使用通道向对端发送数据。这个通道可以是一个本地文件的
IO连接,也可以是一个网络Socket套接字连接。Java中的Channel定义如下:// NIO包中定义的Channel通道接口 public interface Channel extends Closeable { // 判断通道是否处于开启状态 public boolean isOpen(); // 关闭通道 public void close() throws IOException; } 复制代码可以很明显看出,
Channel通道仅被定义成了一个接口,其中提供的方法也很简单,因为具体的实现都在其子类下,Channel中常用的子类如下:FileChannel:用于读取、写入、映射和操作本地文件的通道抽象类。DatagramChannel:读写网络IO中UDP数据的通道抽象类。SocketChannel:读写网络IO中TCP数据的通道抽象类。ServerSocketChannel:类似于BIO的ServerSocket,用于监听TCP连接的通道抽象类。........
是的,你没有看错,实现
Channel接口的都是抽象类,最终具体的功能则是这些抽象类的实现类xxxChannelImpl去完成的,所以Channel通道在Java中是三层定义: 顶级接口→二级抽象类→三级实现类 。但由于Channel接口子类实现颇多,因此不再挨个分析,挑出最常用的ServerSocketChannel、SocketChannel举例分析,其他实现类都大致相同:// 服务端通道抽象类 public abstract class ServerSocketChannel extends AbstractSelectableChannel implements NetworkChannel { // 构造方法:需要传递一个选择器进行初始化构建 protected ServerSocketChannel(SelectorProvider provider); // 打开一个ServerSocketChannel通道 public static ServerSocketChannel open() throws IOException; // 绑定一个IP地址作为服务端 public final ServerSocketChannel bind(SocketAddress local); // 绑定一个IP并设置并发连接数大小,超出后的连接全部拒绝 public abstract ServerSocketChannel bind(SocketAddress local, int backlog); // 监听客户端连接的方法(会发生阻塞的方法) public abstract SocketChannel accept() throws IOException; // 获取一个ServerSocket对象 public abstract ServerSocket socket(); // .....省略其他方法...... } 复制代码ServerSocketChannel的作用与BIO中的ServerSocket类似,主要负责监听客户端到来的Socket连接,但观察如上代码,你会发现它并未定义数据传输(读/写)的方法,因此要牢记:ServerSocketChannel只负责管理客户端连接,并不负责数据传输。用法如下:// 1.打开一个ServerSocketChannel监听 ServerSocketChannel ssc = ServerSocketChannel.open(); // 2.绑定监听的IP地址与端口号 ssc.bind(new InetSocketAddress("127.0.0.1",8888)); // 也可以这样绑定 // ssc.socket().bind(new InetSocketAddress("127.0.0.1",8888)); // 3.监听客户端连接 while(true){ // 不断尝试获取客户端的socket连接 SocketChannel sc = ssc.accept(); // 如果为null则代表没有连接到来,非空代表有连接 if (sc != null){ // 处理客户端连接..... } } 复制代码接着再来看看
SocketChannel的定义:public abstract class SocketChannel extends AbstractSelectableChannel implements ByteChannel, ScatteringByteChannel, GatheringByteChannel, NetworkChannel{ // 打开一个通道 public static SocketChannel open(); // 根据指定的远程地址,打开一个通道 public static SocketChannel open(SocketAddress remote); // 如果调用open()方法时未给定地址,可以通过该方法连接远程地址 public abstract boolean connect(SocketAddress remote); // 将当前通道绑定到本地套接字地址上 public abstract SocketChannel bind(SocketAddress local); // 把当前通道注册到Selector选择器上: // sel:要注册的选择器、ops:事件类型、att:共享属性。 public final SelectionKey register(Selector sel,int ops,Object att); // 省略其他...... // 关闭通道 public final void close(); // 向通道中写入数据,数据通过缓冲区的方式传递 public abstract int write(ByteBuffer src); // 根据给定的起始下标和数量,将缓冲区数组中的数据写入到通道中 public abstract long write(ByteBuffer[] srcs,int offset,int length); // 向通道中批量写入数据,批量写入一个缓冲区数组 public final long write(ByteBuffer[] srcs); // 从通道中读取数据(读取的数据放入到dst缓冲区中) public abstract int read(ByteBuffer dst); // 根据给定的起始下标和元素数据,在通道中批量读取数据 public abstract long read(ByteBuffer[] dsts,int offset,int length); // 从通道中批量读取数据,结果放入dits缓冲区数组中 public final long read(ByteBuffer[] dsts); // 返回当前通道绑定的本地套接字地址 public abstract SocketAddress getLocalAddress(); // 判断目前是否与远程地址建立上了连接关系 public abstract boolean isConnected(); // 判断目前是否与远程地址正在建立连接 public abstract boolean isConnectionPending(); // 获取当前通道连接的远程地址,null代表未连接 public abstract SocketAddress getRemoteAddress(); // 设置阻塞模式,true代表阻塞,false代表非阻塞 public final SelectableChannel configureBlocking(boolean block); // 判断目前通道是否为打开状态 public final boolean isOpen(); } 复制代码SocketChannel所提供的方法大体分为三类:- ①管理类:如打开通道、连接远程地址、绑定地址、注册选择器、关闭通道等。
- ②操作类:读取/写入数据、批量读取/写入、自定义读取/写入等。
- ③查询类:检查是否打开连接、是否建立了连接、是否正在连接等。
其中方法的具体作用其实注释写的很明确了,再单独拎出来一点聊一下:上述所提到的批量读取/写入,其实还有个别的叫法,被称为:
Scatter分散读取和Gather聚集写入 ,其实说人话就是将通道中的数据读取到多个缓冲区,以及将多个缓冲区中的数据同时写入到通道中。OK,再补充一句:在将
SocketChannel通道注册到选择器上时,支持OP_READ、OP_WRITE、OP_CONNECT三种事件,当然,这跟Selector选择器有关,接下来聊聊它。3.2.3、Selector选择器
Selector是NIO的核心组件,它可以负责监控一个或多个Channel通道,并能够检测出那些通道中的数据已经准备就绪,可以支持读取/写入了,因此一条线程通过绑定一个选择器,就可以实现对多个通道进行管理,最终达到一条线程处理多个连接的效果,能够在很大程度上提升网络连接的效率。Java中的定义如下:public abstract class Selector implements Closeable { // 创建一个选择器 public static Selector open() throws IOException; // 判断一个选择器是否已打开 public abstract boolean isOpen(); // 获取创建当前选择器的生产者对象 public abstract SelectorProvider provider(); // 获取所有注册在当前选择的通道连接 public abstract Setkeys(); // 获取所有数据已准备就绪的通道连接 public abstract Set selectedKeys(); // 非阻塞式获取就绪的通道,如若没有就绪的通道则会立即返回 public abstract int selectNow() throws IOException; // 在指定时间内,阻塞获取已注册的通道中准备就绪的通道数量 public abstract int select(long timeout) throws IOException; // 获取已注册的通道中准备就绪的通道数量(阻塞式) public abstract int select() throws IOException; // 唤醒调用Selector.select()方法阻塞后的线程 public abstract Selector wakeup(); // 关闭创建的选择器(不会关闭通道) public abstract void close() throws IOException; } 复制代码 当想要实现非阻塞式
IO时,那必然需要用到Selector选择器,它可以帮我们实现一个线程管理多个连接的功能。但如若想要使用选择器,那需先将对应的通道注册到选择器上,然后再调用选择器的select方法去监听注册的所有通道。不过在向选择器注册通道时,需要为通道绑定一个或多个事件,注册后选择器会根据通道的事件进行切换,只有当通道读/写事件发生时,才会触发读写,因而可通过
Selector选择器实现一条线程管理多个通道。当然,选择器一共支持4种事件:SelectionKey.OP_READ/1 SelectionKey.OP_WRITE/4 SelectionKey.OP_CONNECT/8 SelectionKey.OP_ACCEPT/16
当一个通道注册时,会为其绑定对应的事件,当该通道触发了一个事件,就代表着该事件已经准备就绪,可以被线程操作了。当然,如果要为一条通道绑定多个事件,那可通过 位或 操作符拼接:
int event = SelectionKey.OP_READ | SelectionKey.OP_WRITE; 复制代码
一条通道除开可以绑定多个事件外,还能注册多个选择器,但同一选择器只能注册一次,如多次注册相同选择器就会报错。
注意:
①并非所有的通道都可使用选择器,比如
FileChannel无法支持非阻塞特性,因此不能与Selector一起使用(使用选择器的前提是:通道必须处于非阻塞模式)。②同时,并非所有的事件都支持任意通道,比如
OP_ACCEPT事件则仅能提供给ServerSocketChannel使用。OK~,简单了解了选择器的基础概念后,那如何使用它实现非阻塞模型呢?如下:
// ----NIO服务端实现-------- public class NioServer { public static void main(String[] args) throws Exception { System.out.println(">>>>>>>...NIO服务端启动...>>>>>>>>"); // 1.创建服务端通道、选择器与字节缓冲区 ServerSocketChannel ssc = ServerSocketChannel.open(); Selector selector = Selector.open(); ByteBuffer buffer = ByteBuffer.allocate(1024); // 2.为服务端绑定IP地址+端口 ssc.bind(new InetSocketAddress("127.0.0.1",8888)); // 3.将服务端设置为非阻塞模式,同时绑定接收事件注册到选择器 ssc.configureBlocking(false); ssc.register(selector, SelectionKey.OP_ACCEPT); // 4.通过选择器轮询所有已就绪的通道 while (selector.select() > 0){ // 5.获取当前选择器上注册的通道中所有已经就绪的事件 Iteratoriterator = selector.selectedKeys().iterator(); // 6.遍历得到的所有事件,并根据事件类型进行处理 while (iterator.hasNext()){ SelectionKey next = iterator.next(); // 7.如果是接收事件就绪,那则获取对应的客户端连接 if (next.isAcceptable()){ SocketChannel channel = ssc.accept(); // 8.将获取到的客户端连接置为非阻塞模式,绑定事件并注册到选择器上 channel.configureBlocking(false); int event = SelectionKey.OP_READ | SelectionKey.OP_WRITE; channel.register(selector,event); System.out.println("客户端连接:" + channel.getRemoteAddress()); } // 9.如果是读取事件就绪,则先获取对应的通道连接 else if(next.isReadable()){ SocketChannel channel = (SocketChannel)next.channel(); // 10.然后从对应的通道中,将数据读取到缓冲区并输出 int len = -1; while ((len = channel.read(buffer)) > 0){ buffer.flip(); System.out.println("收到信息:" + new String(buffer.array(),0,buffer.remaining())); } buffer.clear(); } } // 11.将已经处理后的事件从选择器上移除(选择器不会自动移除) iterator.remove(); } } } // ----NIO客户端实现-------- public class NioClient { public static void main(String[] args) throws Exception { System.out.println(">>>>>>>...NIO客户端启动...>>>>>>>>"); // 1.创建一个TCP类型的通道并指定地址建立连接 SocketChannel channel = SocketChannel.open( new InetSocketAddress("127.0.0.1",8888)); // 2.将通道置为非阻塞模式 channel.configureBlocking(false); // 3.创建字节缓冲区,并写入要传输的消息数据 ByteBuffer buffer = ByteBuffer.allocate(1024); String msg = "我是熊猫!"; buffer.put(msg.getBytes()); // 4.将缓冲区切换为读取模式 buffer.flip(); // 5.将带有数据的缓冲区写入通道,利用通道传输数据 channel.write(buffer); // 6.传输完成后情况缓冲区、关闭通道 buffer.clear(); channel.close(); } } 复制代码 在如上案例中,即实现了一个最简单的
NIO服务端与客户端通信的案例,重点要注意:注册到选择器上的通道都必须要为非阻塞模型,同时通过缓冲区传输数据时,必须要调用flip()方法切换为读取模式。OK~,最后简单叙述一下缓冲区、通道、选择器三者关系:
如上图所示,每个客户端连接本质上对应着一个
Channel通道,而一个通道也有一个与之对应的Buffer缓冲区,在客户端尝试连接服务端时,会利用通道将其注册到选择器上,这个选择器则会有一条对应的线程。在开始工作后,选择器会根据不同的事件在各个通道上切换,对于已就绪的数据会基于通道与Buffer缓冲区进行读写操作。简单而言,在这三者之间,
Buffer负责存取数据,Channel负责传输数据,而Selector则会决定操作那个通道中的数据。至此,对于
Java-NIO技术就进行了简单学习,大家也可自行利用NIO技术实现一个聊天室,可加深对NIO技术的熟练度,实现起来也只需在上述案例基础上稍加改进即可。3.3、Java-AIO模型
Java-AIO也被成为NIO2,这是由于Java中的AIO是建立在NIO的基础上拓展的,主要是JDK1.7的时候,在Java.nio.channels包中新加了四个异步通道:AsynchronousServerSocketChannel AsynchronousFileChannel AsynchronousSocketChannel AsynchronousDatagramChannel
Java-AIO与Java-NIO的主要区别在于:使用异步通道去进行IO操作时,所有操作都为异步非阻塞的,当调用read()/write()/accept()/connect()方法时,本质上都会交由操作系统去完成,比如要接收一个客户端的数据时,操作系统会先将通道中可读的数据先传入read()回调方法指定的缓冲区中,然后再主动通知Java程序去处理。3.3.1、Java-AIO通信案例
先上个
AIO的案例:// ------AIO服务端---------- public class AioServer { // 线程池:用于接收客户端连接到来,这个线程池不负责处理客户端的IO业务(推荐自定义pool) // 主要作用:处理到来的IO事件和派发CompletionHandler(接收OS的异步回调) private ExecutorService servicePool = Executors.newFixedThreadPool(2); // 异步通道的分组管理,目的是为了资源共享,也承接了之前NIO中的Selector工作。 private AsynchronousChannelGroup group; // 异步的服务端通道,类似于NIO中的ServerSocketChannel private AsynchronousServerSocketChannel serverChannel; // AIO服务端的构造方法:创建AIO服务端 public AioServer(String ip,int port){ try { // 使用线程组,绑定线程池,通过多线程技术监听客户端连接 group = AsynchronousChannelGroup.withThreadPool(servicePool); // 创建AIO服务端通道,并通过线程组对到来的客户端连接进行管理 serverChannel = AsynchronousServerSocketChannel.open(group); // 为服务端通道绑定IP地址与端口 serverChannel.bind(new InetSocketAddress(ip,port)); System.out.println(">>>>>>>...AIO服务端启动...>>>>>>>>"); /** * 第一个参数:作为处理器的附加参数(你想传啥都行) * 第二个参数:注册一个提供给OS回调的处理器 * */ serverChannel.accept(this,new AioHandler()); /** * 这里主要是为了阻塞住主线程退出,确保服务端的正常运行。 * (与CompletableFuture相同,主线程退出后无法获取回调) * */ Thread.sleep(100000); } catch (Exception e){ e.printStackTrace(); } } // 关闭服务端的方法 public void serverDown(){ try { serverChannel.close(); group.shutdown(); servicePool.shutdown(); } catch (Exception e) { e.printStackTrace(); } } // 获取服务端通道的方法 public AsynchronousServerSocketChannel getServerChannel(){ return this.serverChannel; } public static void main(String[] args){ // 创建一个AIO的服务端 AioServer server = new AioServer("127.0.0.1",8888); // 关闭AIO服务端 server.serverDown(); } } // ------AIO服务端的回调处理类---------- public class AioHandler implements CompletionHandler上述
AIO的案例对比之前的BIO、NIO来说,可能略微显得复杂一些,这是确实的,但咱们先来看看运行结果,分别启动AioServer、AioClient,结果如下:// -------AioServer控制台--------- >>>>>>>...AIO服务端启动...>>>>>>>> 服务端收到信息:我是客户端-熊猫一号! 服务端收到信息:我是客户端-熊猫二号! // -------AioClient控制台--------- >>>>>>>...AIO客户端启动...>>>>>>>> 客户端收到信息:我是服务端-竹子! >>>>>>>...AIO客户端启动...>>>>>>>> 客户端收到信息:我是服务端-竹子! 复制代码
从结果中不难得知,上述仅是一个
AIO服务端与客户端通信的案例,相较于之前的NIO而言,其中少了Selector选择器这个核心组件,选择器在NIO中负责查询自身所有已注册的通道到OS中进行IO事件轮询、管理当前注册的通道集合、定位出发事件的通道等操作。但在Java-AIO中,则不是采用轮询的方式监听IO事件,而是采用一种类似于“订阅-通知”的模式。在
AIO中,所有创建的通道都会直接在OS上注册监听,当出现IO请求时,会先由操作系统接收、准备、拷贝好数据,然后再通知监听对应通道的程序处理数据。不过观察上述案例,其中多出来了AsynchronousChannelGroup、CompletionHandler这两个东西,那么它们是用来做什么的呢?接下来简单聊一聊。3.3.2、异步通道分组
AsynchronousChannelGroup主要是用来管理异步通道的分组,也可以实现线程资源的共享,在创建分组时可以为其绑定一个或多个线程池,然后创建通道时,可以指定分组,如下:group = AsynchronousChannelGroup.withThreadPool(servicePool); serverChannel = AsynchronousServerSocketChannel.open(group); 复制代码
上面首先创建了一个
group分组并绑定了一个线程池,然后在创建服务端通道将其分配到了group这个分组中,那此时连接serverChannel的所有客户端通道,都会共享servicePool这个线程池的线程资源。这个线程池中的线程,则负责类似于NIO中Selector的工作。3.3.3、异步回调处理
CompletionHandler则是AIO较为核心的一部分,主要是用于Server服务端的,前面聊到过:AIO中,对于IO请求的数据,会先交由OS处理,然后等OS处理完成后再通知应用程序进行具体的业务操作 。而CompletionHandler则作为异步IO数据结果的回调接口,用于定义操作系统在处理好IO数据之后的回调工作。CompletionHandler接口中主要存在completed()、failed()两个方法,分别对应IO数据处理成功、失败的回调工作。当然,对于
AIO的回调工作,也允许通过Future处理,但最好还是定义CompletionHandler处理。其实对于
Java中的异步回调机制,在之前的 《并发编程-CompletableFuture分析篇》 曾详细讲到过,其中分析过CompletionStage回调接口,这与AIO中的回调执行有异曲同工之妙。3.3.4、AIO的底层实现
和之前分析的
BIO、AIO一样,Java-BIO本质上是同步调用内核所提供的read()/write()/recvfrom()等函数实现的。Java-NIO则是通过调用内核所提供的select/poll/epoll/kqueue等函数实现。
而
Java-AIO这种异步非阻塞式IO也是由操作系统进行支持的,在Windows系统中提供了一种异步IO技术:IOCP(I/O Completion Port,所以Windows下的Java-AIO则是依赖于这种机制实现。不过在Linux系统中由于没有这种异步IO技术,所以Java-AIO在Linux环境中使用的还是epoll这种多路复用技术进行模拟实现的。对于具体的实现后续会详细剖析。
3.3.5、NIO、AIO的区别
对于
Java-NIO、AIO的区别,简单的就不再叙述了,最关键的一点就在于两者实现的模式不同,Java-NIO是基于Reacot模式构建的,Reacot负责事件的注册、监听、派发等工作,也就是对应着Selector选择器,它是NIO的核心。而Java-AIO则是基于Proactor模式构建的,Proactor负责异步IO的回调工作派发,在Java-AIO技术中,AsynchronousChannelGroup则担任着Proactor的角色。NIO在工作时,假设要发送数据给对端,那么首先会先去判断数据是否准备就绪,如若未就绪,那则会先向Reacot注册OP_WRITE事件并返回,接着由Reacot继续监听IO数据,当数据就绪后会触发注册的对应事件,Reacot会通知用户线程处理(也可以由Reacot自行处理,但不建议),等处理完成后一定要记得注销对应的事件,否则会导致CPU打满。而
AIO在工作时,假设要读取对端的数据,此时也会先判断数据是否准备就绪,如若未就绪,那会发起read()异步调用、注册CompletionHandler,然后返回。此时操作系统会先准备数据,数据就绪后会返回结果给Proactor,然后由Proactor来将数据派发给具体的CompletionHandler,然后在Handler中执行具体的回调工作。四、IO模型总结(未完待续)
在前面咱们详细叙述了
Linux五种IO模型以及Java所提供的三种IO模型支持,对于Java-IO这块内容,阻塞、非阻塞、同步、异步等这些区别就不再聊了,认真看下来本文后自然会有答案,最后是需要重点表明一点:NIO、AIO都是单线程处理多个连接 ,但并不代表着说永远只有一条线程对网络连接进行处理,这里所谓的单线程处理多个连接,其实本质上是指单条线程接收客户端连接。从上述这段话中应该可以得知:
Java-NIO、AIO本质上对于客户端的网络连接照样会启动多条线程处理,只不过与BIO的区别如下:Java-BIO:当客户端到来连接请求时,就会分配一条线程处理。Java-NIO:客户端的连接请求会先注册到选择器上,选择器轮询到有事件触发时,才会分配一条线程处理。Java-AIO:客户端的连接到来后同样会先注册到选择器上,但客户端的I/O请求会先交由OS处理,当内核将数据拷贝完成后才会分配一条线程处理。
Java-BIO、NIO、AIO本质上都会为一个请求分配一条线程处理,但核心区别在于启动的时机不同,当然,如果非要用一条线程处理多个客户端连接的所有工作也并非不行,但这样会造成系统极为低效,例如1000个文件下载的请求到来,全都交由选择器上监听客户端连接的那条线程处理,其效率诸位可想而知。最后多叨叨一句,其实
Java-NIO、AIO方面的设计,无论是从使用简洁度而言,还是从源码的可观性而言,其实都并不算理想,如若有小伙伴阅读过JUC包的源码,再回来对比NIO包的源码,两者差别甚大,所以本质上在之后的过程中,如若要用到Java-NIO、AIO方面的技术,一般都会采用Netty框架实现,Netty这个网络通信框架则对nio包提供的原生IO-API进一步做了封装,也解决了NIO包下原生API存在的诸多问题,因此在后续的文章中也会重点分析Netty这个框架。最后的歉语:由于编译了
linux-os-kernel-3.10.0-862.el7.x86_64内核的源码后,仅发现select函数的头文件定义,未曾在该内核版本中发现select的具体实现,后面查询后得知:在Linux内核2.6以后的版本默认支持的多路复用函数为EPoll,因此还需要额外编译2.6版本左右的内核源码,才能对Linux中的多路复用函数源码进行调试,因此请诸君稍等几天,对于select、poll、epoll原理分析的内容,由于本篇内容过长,再加上前提准备工作未就绪,因此会再单开一篇文章叙述。 - 磁盘
-
相关阅读:
Java 中模板下载
虚拟机备份
QT day5
“传统技术”快速搭建AI产品的利器——LLM技术
Dubbo详解,用心看这一篇文章就够了【重点】
C++歌曲播放管理系统
探索Python中的装饰器
甘特图是什么?如何快速搭建?
面试突击59:一个表中可以有多个自增列吗?
软件工程计算机操作系统
- 原文地址:https://blog.csdn.net/JHIII/article/details/126317223
