-
使用mysql语句对分组结果进行再次筛选
使用mysql语句对分组结果进行再次筛选
1 作用
对分组结果进行再一次的筛选,就需要使用在GROUP BY子句中接上HAVING 子句。
例如求在员工表emp中求部门中的员工的最高工资大于2000的部门编号和最高工资,就得用上HAVING子句,用WHERE子句是不能直接操作分组函数的,因为要先分组了才可以使用分组函数。
2 如何用
2.1 本质
对分组结果进行筛选,筛选之后SELECT的子句中的分组函数就可以拿到筛选之后的数据了
其实,简单来说,HAVING子句就是在SELECT子句中有分组函数的情况下,在SELECT子句执行前,提前使用分组函数过滤掉了一些不需要的数据,
当然在HAVING子句也可以过滤分组字段,但是过滤分组字段的某些值的最优解法就是在WHERE子句里面进行过滤
HAVING子句只对分组结果进行再次过滤
2.2 语法
SELECT 分组字段,分组函数(想要汇总/计算的字段) FROM 表名 GROUP BY 分组字段 HAVING 分组函数(想要汇总/计算的字段) 比较运算符 常量;- 1
- 2
- 3
- 4
2.3 示例sql语句
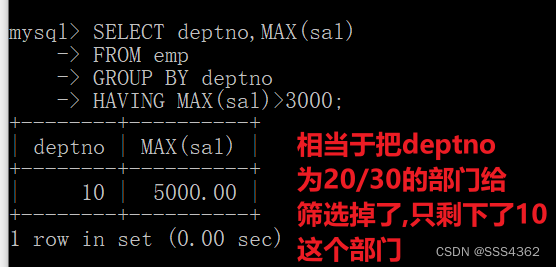
SELECT deptno,MAX(sal) FROM emp GROUP BY deptno HAVING MAX(sal)>3000; /* 查询中员工表中部门员工最高工资大于3000的部门编号和最高薪水 */- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.4 分析过程
a 分组
按照deptno字段可以把emp表分为三组(分组是没有先后顺序的,谁是第一组都行)
分组的数据的标题(EMPNO,ENAME…)实际上只是为了看的更清楚,它实际并不参与分组的
第一组 10,对应的数据如下所示
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO 7782 CLARK MANAGER 7839 1981-06-09 2450.00 NULL 10 7839 KING PRESIDENT NULL 1981-11-17 5000.00 NULL 10 7934 MILLER CLERK 7782 1982-01-23 1300.00 NULL 10 第二组 20,对应的数据如下所示
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO 7369 SMITH CLERK 7902 1980-12-17 800.00 NULL 20 7566 JONES MANAGER 7839 1981-04-02 2975.00 NULL 20 7788 SCOTT ANALYST 7566 1987-04-19 3000.00 NULL 20 7876 ADAMS CLERK 7788 1987-05-23 1100.00 NULL 20 7902 FORD ANALYST 7566 1981-12-03 3000.00 NULL 20 第三组 30 对应的数据如下所示
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO 7499 ALLEN SALESMAN 7698 1981-02-20 1600.00 300.00 30 7521 WARD SALESMAN 7698 1981-02-22 1250.00 500.00 30 7654 MARTIN SALESMAN 7698 1981-09-28 1250.00 1400.00 30 7698 BLAKE MANAGER 7839 1981-05-01 2850.00 NULL 30 7844 TURNER SALESMAN 7698 1981-09-08 1500.00 0.00 30 7900 JAMES CLERK 7698 1981-12-03 950.00 NULL 30 b 找最大值
b.1 第一组 10中的最大值为5000
b.2 第二组 20中的最大值为3000
b.3 第三组 30中的最大值为2850
c 仅把最大值大于3000的部门留下,另外的全部筛选掉
那么就只剩下了部门编号为10的部门,部门中的最高工资为5000
deptno max(sal) 10 5000.00 d 最后查询出来的结果就只剩下部门编号为10的部门以及它的最高工资了
2.5 示例sql语句运行截图
3 注意点
3.1 HAVING子句中只能存在分组字段、常数或者分组函数,不能出现非分组字段
3.1.1 错误sql示例语句
SELECT deptno,MAX(sal) FROM emp GROUP BY deptno HAVING job='SALESMAN';- 1
- 2
- 3
- 4
3.1.2 错误sql示例语句运行截图

3.2 有了HAVING子句的整体执行顺序
3.2.1 FROM子句---->WHERE子句---->GROUP BY子句---->HAVING子句---->SELECT子句---->ORDER BY子句
3.2.2 从左往右按照顺序依次执行
3.2.3 若其中某一个子句没有,就会往后找有的子句,然后按照顺序依次执行
-
相关阅读:
践行“双碳” 迈动互联节能数据产品上线
CDR插件开发之Addon插件007 - Addon插件简介和案例演示
【百战GAN】SRGAN人脸低分辨率老照片修复代码实战
精品MySQL面试题,备战八月99%必问!过不了面试算我的
人力资源小程序
2021-NeurlPS-RUl论文对应源码的复现过程记录
Leetcode 151. 反转字符串中的单词 JS版两种方法(内置API,双指针)有详细讲解 小白放心食用
聚观早报|蚂蚁集团发布“蚁天鉴”;vivo X100系列即将亮相
第一章:递归求n的阶乘n!
数据同步,还看Canal
- 原文地址:https://blog.csdn.net/SSS4362/article/details/126315540