-
MySQL - 慢查询优化
1. 慢查询定位
1.1 开启慢查询日志
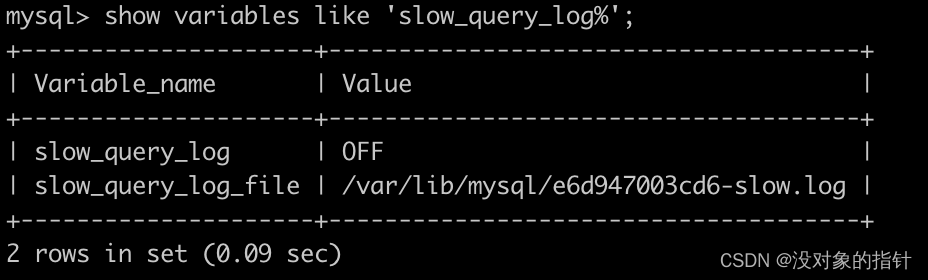
查看 MySQL 数据库是否开启了慢查询日志和慢查询日志的存储位置的命令如下:
show variables like 'slow_query_log%';- 1
通过如下命令开启慢查询日志:set global slow_query_log = on; set global slow_query_log_file = 'oak-slow.log'; set global log_queries_not_using_indexes = on; set long_query_time = 10;- 1
- 2
- 3
- 4
- long_query_time:指定慢查询的阀值,单位秒。如果 SQL 执行时间超过阀值,就属于慢查询记录到日志文件中。
- log_queries_not_using_indexes:表示会记录没有使用索引的查询 SQL。前提是 slow_query_log 的值为 ON,否则不会奏效。
1.2 查询慢查询日志
- 查看慢查询日志:
直接使用文本编辑器打开slow.log日志即可:

- time:日志记录的时间
- User@Host:执行的用户及主机
- Query_time:执行的时间
- Lock_time:锁表时间
- Rows_sent:发送给请求方的记录数,结果数量
- Rows_examined:语句扫描的记录条数
- SET timestamp:语句执行的时间点
- select…:执行的具体的SQL语句
- 使用 mysqldumpslow 查看
MySQL 提供了一个慢查询日志分析工具 mysqldumpslow,可以通过该工具分析慢查询日志
内容。
在 MySQL bin 目录下执行下面命令可以查看该使用格式:perl mysqldumpslow.pl --help- 1
运行如下命令查看慢查询日志信息:
perl mysqldumpslow.pl -t 5 -s at C:\ProgramData\MySQL\Data\OAK-slow.log- 1
除了使用 mysqldumpslow 工具,也可以使用第三方分析工具,比如 pt-query-digest、
mysqlsla 等。2. 慢查询优化
2.1 索引和慢查询
- 如何判断是否为慢查询?
MySQL 判断一条语句是否为慢查询语句,主要依据 SQL 语句的执行时间,它把当前语句的执行时间跟 long_query_time 参数做比较,如果语句的执行时间 > long_query_time,就会把这条执行语句记录到慢查询日志里面。long_query_time 参数的默认值是 10s,该参数值可以根据自己的业务需要进行调整。
- 如何判断是否应用了索引?
SQL 语句是否使用了索引,可根据 SQL 语句执行过程中有没有用到表的索引,可通过 explain 命令分析查看,检查结果中的 key 值,是否为NULL。
- 应用了索引是否一定快?
下面我们来看看下面语句的 explain 的结果,你觉得这条语句有用上索引吗?比如:
select * from user where id > 0;- 1
虽然使用了索引,但是还是从主键索引的最左边的叶节点开始向右扫描整个索引树,进行了全表扫描,此时索引就失去了意义。
而像 select * from user where id = 2; 这样的语句,才是我们平时说的使用了索引。它表示的意思是,我们使用了索引的快速搜索功能,并且有效地减少了扫描行数。
查询是否使用索引,只是表示一个 SQL 语句的执行过程;而是否为慢查询,是由它执行的时间决定的,也就是说是否使用了索引和是否是慢查询两者之间没有必然的联系。
我们在使用索引时,不要只关注是否起作用,应该关心索引是否减少了查询扫描的数据行数,如果扫描行数减少了,效率才会得到提升。对于一个大表,不止要创建索引,还要考虑索引过滤性,过滤性好,执行速度才会快。
2.2 提高索引过滤性
假如有一个5000万记录的用户表,通过 sex = ‘男’ 索引过滤后,还需要定位3000万,SQL 执行速度也不会很快。其实这个问题涉及到索引的过滤性,比如1万条记录利用索引过滤后定位10条、100条、1000条,那他们过滤性是不同的。索引过滤性与索引字段、表的数据量、表设计结构都有关系。
下面我们看一个案例:
-- 建表 CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID', `name` varchar(32) NOT NULL DEFAULT '' COMMENT '名称', `sex` tinyint(4) NOT NULL DEFAULT '0' COMMENT '性别 1:男 2:女', `age` int(11) NOT NULL COMMENT '年龄', PRIMARY KEY (`id`), KEY `idx_name_age_sex` (`name`,`age`,`sex`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4; -- 插入数据 INSERT INTO `meta_demo`.`user` (`id`, `name`, `sex`, `age`) VALUES (1, 'javaboy001', 1, 18); INSERT INTO `meta_demo`.`user` (`id`, `name`, `sex`, `age`) VALUES (1, 'javaboy002', 2, 18); -- 查询语句 - 全表扫描 select * from user where age=18 and name like 'javaboy%';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
优化1:
-- 添加索引 alter table user add index idx_name (name);- 1
- 2
优化2:
-- 添加联合索引 alter table user add index idx_age_name (age, name);- 1
- 2
优化3:
可以看到,index condition pushdown 优化的效果还是很不错的。再进一步优化,我们可以把名字的第一个字和年龄做一个联合索引,这里可以使用 MySQL 5.7 引入的虚拟列来实现。
-- 为user表添加first_name虚拟列,以及联合索引(first_name,age) alter table user add first_name varchar(2) generated always as (left(name, 1)), add index idx_fname_age (first_name, age); -- 分析 select explain select * from user where first_name='张' and age=18;- 1
- 2
- 3
- 4
- 5
2.3 慢查询原因总结
-
全表扫描: explain 分析 type 属性 all
-
全索引扫描: explain 分析 type 属性 index
-
索引过滤性不好: 靠索引字段选型、数据量和状态、表设计
-
频繁的回表查询开销: 尽量少用 select *,使用覆盖索引
3. 分页查询优化
3.1 一般性分页
一般的分页查询使用简单的 limit 子句就可以实现。limit 格式如下:
SELECT * FROM table_name LIMIT [offset,] rows- 1
第一个参数指定第一个返回记录行的偏移量,注意从0开始;
第二个参数指定返回记录行的最大数目;
如果只给定一个参数,它表示返回最大的记录行数目;思考1:如果偏移量固定,返回记录量对执行时间有什么影响?
select * from user limit 10000,1; select * from user limit 10000,10; select * from user limit 10000,100; select * from user limit 10000,1000; select * from user limit 10000,10000;- 1
- 2
- 3
- 4
- 5
结果:在查询记录时,返回记录量低于100条,查询时间基本没有变化,差距不大。随着查询记录量越大,所花费的时间也会越来越多。
思考2:如果查询偏移量变化,返回记录数固定对执行时间有什么影响?
select * from user limit 1,100; select * from user limit 10,100; select * from user limit 100,100; select * from user limit 1000,100; select * from user limit 10000,100;- 1
- 2
- 3
- 4
- 5
结果:在查询记录时,如果查询记录量相同,偏移量超过100后就开始随着偏移量增大,查询时间急剧的增加。(这种分页查询机制,每次都会从数据库第一条记录开始扫描,越往后查询越慢,而且查询的数据越多,也会拖慢总查询速度。)
3.2 分页优化方案
第一步:利用覆盖索引优化
select * from user limit 10000,100; -- > select id from user limit 10000,100;- 1
- 2
- 3
第二步:利用子查询优化
select * from user limit 10000,100; -- > select * from user where id >= (select id from user limit 10000, 1) limit 100;- 1
- 2
- 3
原因:使用了 id 做主键比较(id >=),并且子查询使用了覆盖索引进行优化。
-
相关阅读:
electron自定义标题栏,并监听双击以及右键改变窗口大小。
【计算机网络实验】RIP的基本配置
swagger 接口测试,用 python 写自动化时该如何处理?
MySQL的索引原理
聊聊交互设计师的成长 优漫动游
visual studio 启用C++11
Dubbo-Adaptive实现原理
UE5实现相机水平矫正
C#软件架构设计原则
Spring Cloud ---Nacos集群搭建
- 原文地址:https://blog.csdn.net/weixin_42201180/article/details/126314360
