-
文本生成不同解码方法的具体实现
Greedy Search
贪婪搜索指的是在每一个时间步中使用前n-1的词来预测第n个生成词。即
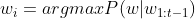 ,在这个过程中,第n个词是前n-1个词预测的概率最高的词。
,在这个过程中,第n个词是前n-1个词预测的概率最高的词。
- """
- Greedy Search
- """
- import tensorflow as tf
- from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
- tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
- # add the EOS token as PAD token to avoid warnings
- model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
- # 将句子转化为可用的输入形式
- input_ids = tokenizer.encode('the japanese is so ', return_tensors='tf')
- # 设置生成文本的最大长度未50
- greedy_output = model.generate(input_ids, max_length=50, early_stopping=True)
- """
- 输出内容:
- the japanese is so - that it's not even -
- that it's -that it's - that it's - that it's - that it's
- """
Beam Search
虽然贪心搜索在每一步都能得到最优的解,但在总体上来看,可能会陷入到一个次优解或者是非常不好的解中。为此束搜索被提出来解决这个全局优化的问题,该算法在生成下一个单词的时候,会生成K个候选词,然后在这个基础上继续进行K个候选词的选择,最后在全局的基础上选择一条概率最大的路径。
- # 这里使用了5个束来进行搜索
- beam_output = model.generate(input_ids, max_length=50, early_stoppping=True, num_beams=5)
- """
- the japanese is so iced up that I don't even know how to pronounce it.
- I'm not sure how to pronounce it.
- I'm not sure how to pronounce it.
- """
由于以上的得到的结果会出现重复的输出内容,为此我们对其进行设置,使用n-gram penatly来确保没有n-gram在预测的句子中出现两次。但这样也会出现一个问题,那就是在需要重复的场景中,也只能出现一次。
- ngram_beam_output = model.generate(input_ids, max_length=50, early_stoppping=True, num_beams=5,no_repeat_ngram_size=2) # 这里的no_repeat_gram_size表示ngram
- """
- 输出内容:
- the japanese is so iced up that I don't even know how to pronounce it.
- I'm not sure if it's because I'm lazy, or if I just want to be able to say it in Japanese, but I
- """
topk answer
对于生成的句子可能会存在表达或者语义的问题,有的时候我们需要查看多个生成的句子以人工搜索一个最好的句子。
- ngram_beam_topk_output = model.generate(input_ids, max_length=50, early_stoppping=True, num_beams=5,no_repeat_ngram_size=2, num_return_sequences=5)
- """
- 0: the japanese is so iced up that I don't even know how to pronounce it.
- I'm not sure if it's because I'm lazy, or if I just want to be able to say it in Japanese, but I
- 1: the japanese is so iced up that I don't even know how to pronounce it.
- I'm not sure if it's because I'm lazy, or if I just want to be able to say it in Japanese, but it
- 2: the japanese is so iced up that I don't even know how to pronounce it.
- I'm not sure if it's because I'm lazy, or if I just want to be able to read Japanese, but I think it
- 3: the japanese is so iced up that I don't even know how to pronounce it.
- I'm not sure if it's because I'm lazy, or if I just want to be able to say it in Japanese. But I
- 4: the japanese is so iced up that I don't even know how to pronounce it.
- I'm not sure if it's because I'm lazy, or if I just want to be able to read Japanese, but I think I
- """
sampling
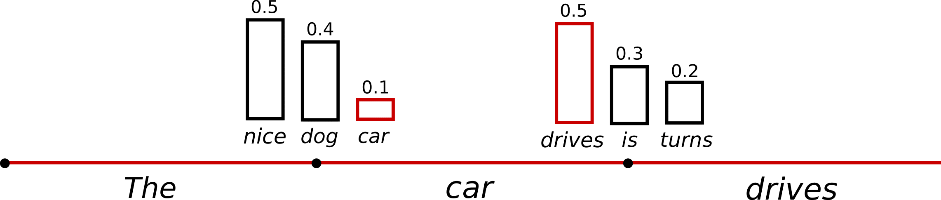
采样是另外一种不同的策略,其对条件概率生成的词进行随机的采样。如下图所示,
- tf.random.set_seed(0)
- # print("Output:\n" + 100 * '-')
- sample_output = model.generate(input_ids, do_sample=True, max_length=200, top_k=50)
- print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
- """
- 输出:
- the japanese is so icky, that even the "Japan's food is the finest" is not really an excuse.
- My point is what it is that does the Japanese taste better than others in this country. The reason is that
- """
对于随机生成的句子,乍一看没问题,但是读起来很不合理,所以对于随机采样,我们尽可能地采样概率较高的词,而减少低概率词地采样
- sample_output = model.generate(
- input_ids,
- do_sample=True,
- max_length=50,
- top_k=0,
- temperature=0.9
- )
- print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
- """
- 输出:
- the japanese is so familiar with the Japanese language that it's hard to imagine it being used in a Japanese context.
- The Japanese language is a very complex language, and it's hard to imagine a Japanese person using it in
- """
为了进一步优化,我们只对前K个概率最高的词进行采样,
- sample_output = model.generate(
- input_ids,
- do_sample=True,
- max_length=50,
- top_k=50
- )
- """
- the japanese is so iaa.
- I mean, that's true that people are very hard at finding words in japanese. In fact it might
- be more accurate to say that Japanese means "Japanese", which is what you
- """
对于上面的方法,还可以对可能的词进行百分比的随机抽样,即采样最可能的词的概率(个人认为是对词的可能性/概率进行排序,然后只对前百分之多少的词进行采样)
- # deactivate top_k sampling and sample only from 92% most likely words
- sample_output = model.generate(
- input_ids,
- do_sample=True,
- max_length=50,
- top_p=0.92,
- top_k=0
- )
- """
- the japanese is so!!!! Cuz of that, you forgot to put caps properly!!!!
- I'll make this shit up for those who can't usually talk with one who can PLEASE READ THE INPICIOUS and SATURN INVINC
- """
同样地,我们也可以对topk中的词进行概率为p的采样
- # set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
- sample_outputs = model.generate(
- input_ids,
- do_sample=True,
- max_length=50,
- top_k=50,
- top_p=0.95,
- num_return_sequences=3
- )
- """
- the japanese is so icky in mine. it's a lot like someone's salivating over peas and chocolate.
- rxtfffffff.......ooh they need Japanese drinking?? Just a thought....... Join us and talk to us about all kinds
- """
-
相关阅读:
PostgreSQL备份工具pg_dump和pg_dumpall
docker部署clickhouse-server
Unity布料系统_Cloth组件(包含动态调用相关)
设计模式-中介者模式
探索人工智能 | 模型训练 使用算法和数据对机器学习模型进行参数调整和优化
【云原生之Docker实战】使用Docker部署MongDB数据库管理工具Mongo-Express
一文看懂推荐系统:物品冷启06:冷启的AB测试
LightDB中的存储过程(八)—— 包
torch lighting 为不同模型设置不同的学习率
python生成器总结
- 原文地址:https://blog.csdn.net/qq_38901850/article/details/126312051
