-
【Python实战】美哭你的极品壁纸推荐|1800+壁纸自动换?美女动漫随心选(高清无码)
前言
哈喽,各位小伙伴们,你们好!(*๓´╰╯`๓)

没关注?伸出手指点这里---
自从在写爬虫系列的文章后,有小伙伴在后台留言问:栗子有能不能爬一批二次元好看的高颜
值小姐姐、cosplay等壁纸图片分享一下。
所有文章完整的素材+源码都在👇👇
嘿嘿,今天小编就分享一个爬虫的案例实战项目给大家啦——里面不仅仅有好看的新番、古
风、手办等还有好看的小姐姐呢~

正文
一、运行环境
环境: Python 3 、Pycharm、requests 。 内置模块 你安装 好python环境就可以了。
(win + R 输入cmd 输入安装命令 pip install 模块名 (如果你觉得安 装速度比较慢, 你可以切
换国内镜像源))
第三方库的安装:pip install + 模块名 或者 带镜像源 pip install -i https://pypi.douban.com/simple/ +模块名
二、代码实现
主程序:
- import requests # 第三方模块
- import os
- # 伪装
- headers = {
- 'cookie': 'tt_webid=7080861394355144200; MONITOR_WEB_ID=c27b9f4a-4917-4256-be93-e948308467e3; _ga=GA1.2.129525347.1648641528; mobile_set=no; _gid=GA1.2.65241243.1648881025; ttcid=7fe011fccdef4bb499adfaa2a66fe91523; Hm_lvt_330d168f9714e3aa16c5661e62c00232=1648641528,1648881024,1648881406; s_v_web_id=verify_l1hhezfz_DPGGYf9t_xlZo_4XMT_A2sB_XTxuLFCn9F0N; _csrf_token=286c9c233158922e343eb557dff2edb6; Hm_lpvt_330d168f9714e3aa16c5661e62c00232=1648881639; _gat_gtag_UA_121535331_1=1; msToken=y0CPmCLvPhDlOHFTJ6Pbe7I6Yn_qHXWZCV6H2jCS6CSFDeOr9D2ay5oXSBenhEVJE13LumKz8r_Z_NkDf-q6YvymJb2WtmgoEhlNX-ECCMR2-cqikWcaBI2GoYLPrpQ=; tt_scid=PKf8Ei-xP9zbLe9A2gRCWsQrM.BLxDRwCzU5RwxC2Cll0u0kK09ctPib3QLfmh5i1436',
- 'referer': 'https://bcy.net/coser/toppost100?type=week&date=20220319',
- 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36'
- }
- url = 'https://bcy.net/apiv3/rank/list/itemInfo'
- params = {
- 'p': '1',
- 'ttype': 'cos',
- 'sub_type': 'week',
- 'date': '20220319'
- }
- # 1. 发送请求
- response = requests.get(url=url, headers=headers, params=params)
- # 2. 获取数据
- json_data = response.json()
- # 3. 解析数据
- # 结构化数据 json数据 字典键值对取值 re
- # 非结构化数据 html网页 网页源代码 css xpath re
- top_list = json_data['data']['top_list_item_info']
- for top in top_list:
- uname = top['item_detail']['uname']
- print(f'正在爬取: {uname}')
- if not os.path.exists(f'img/{uname}'):
- os.mkdir(f'img/{uname}')
- image_list = top['item_detail']['image_list']
- for img in image_list:
- path = img['path']
- mid = str(img['mid'])
- print(f' {mid}.jpg')
- # 4. 保存数据
- img_data = requests.get(path).content
- with open(f'img/{uname}/{mid}.jpg', mode='wb') as f:
- f.write(img_data)
 三、效果展示
三、效果展示1)批量下载图片壁纸

2)文件夹保存
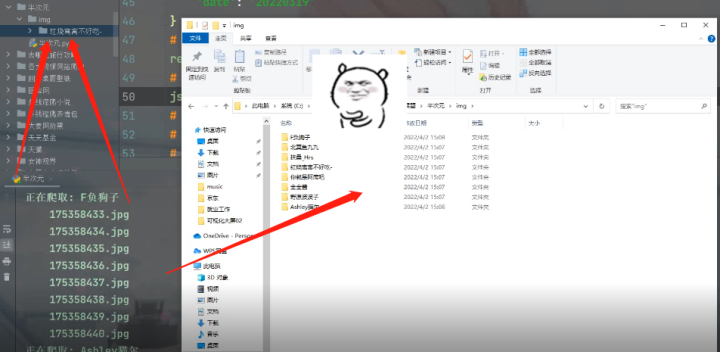
3)图片展示随机
随机(1)

随机(2)
很多高清壁纸的哦~批量一键下载嘿嘿!看看下面的图能有多高清~



总结
好啦!这些壁纸总有大家喜欢的类型嘞~超级多滴 上面只是一丢丢啦,还在等什么赶快跟我一
起学习来叭~
✨完整的素材源码等:可以滴滴我吖!或者点击文末hao自取免费拿的哈~
🔨推荐往期文章——
项目0.4 【Python爬虫】过来人告诉你:为什么找工作抓住这个细节,能少踩很多坑哦~(招聘网站实战)
项目0.1 【Python抢票神器】火车票枪票软件到底靠谱吗?实测—终极攻略。
项目0.2 【Python实战】WIFI密码小工具,甩万能钥匙十条街,WIFI任意连哦~(附源码)
项目0.3 【Python实战】再分享一款商品秒杀小工具,我已经把压箱底的宝贝拿出来啦~
🎁文章汇总——
Python文章合集 | (入门到实战、游戏、Turtle、案例等)
(文章汇总还有更多你案例等你来学习啦~源码找我即可免费!)
-
相关阅读:
2022年中高级Android面试知识点记录
对分段有序的数组排序(前、后部分分别递增)
python进阶(25)协程
如何恢复xp笔记本盘符找不到的数据
ubuntu 安装 微服务 dapr
【Linux详解】——环境变量
linux下离线安装JDK,GeoServer,tomcat,nginx,redis,rabbitmq,postgresql。
Python自动化之定时任务
R语言机器学习 趋势分析 SMA EMA
【软件安装】服务器(docker) 安装 jupyter
- 原文地址:https://blog.csdn.net/xy258009/article/details/126310163
