-
2.MySQL 基础知识
文章目录
- MySQL 基础知识
- 知识点一 : MySQL命令行常用命令
- 知识点二 : 持久化 相关概念
- 知识点三 : 数据库 相关概念
- 知识点四 : DB 和 DBMS 关系图示
- 知识点五 : MySQL 概述
- 知识点六 : RDBMS 对比 非RBDMS
- 知识点七 : 数据库表的特性 ( 行、列 )
- 知识点八 : 数据库表的关联
- 知识点九 : SQL 语言功能分类 (DDL, DML, DCL)
- 知识点十 : SQL语言规则与规范
- 知识点十一 : SELECT 语句
- 知识点十二 : 事件
- 知识点十三 : 存储过程
- 知识点十四 : 主键
- 知识点十五 : 外键
- 知识点十六 : 字段属性
- 知识点十七 : 属性解释
- 知识点十八 : 联表查询
- 知识点十九 : 自连接
- 知识点二十 : 分页(limit)和排序(order by)
- 知识点二十一 : 子查询
- 知识点二十二 : 常用函数
- 知识点二十三 : 分组和过滤
- 知识点二十四 : MD5加密
- 知识点二十五 : 事务
- 知识点二十六 : 索引
- 知识点二十七 : 权限管理
- 知识点二十八 : 数据库备份
- 知识点二十九 : 通过sql文件插入百万条数据
- 知识点三十 : 通过 pymysql 模块操作数据库
MySQL 基础知识
知识点一 : MySQL命令行常用命令
-
(cmd) 启动mysql(需要管理员身份) : net start mysql
-
(cmd) 显示mysql版本号 : mysql --version
-
(cmd) 登录本地mysql服务器: mysql -u root -h localhost -P <版本端口号> -p
-
(cmd) 其他电脑通过网络登录mysql服务器 : mysql -u root -h <目标mysql电脑IP地址> -P <版本端口号> -p
-
(mysql) 增建一个数据库 : create database if not exists <数据库名>;
-
(mysql) 增建一个新的表格 : create table <表名称> ( <字段名> <数据类型>, <字段名> <数据类型> );
-
(mysql) 增加多条数据到数据表中 : insert into <表名> values (数据1,数据2,数据3), (数据1,数据2,数据3), (数据1,数据2,数据3) …;
-
(mysql) 增建一个用户 : create user ‘user100’@‘192.168.10.%’ identfied by ‘123456’;
- 192.168.10.% 表示用户可以从所有192.168.10开头的IP地址登录, 123456是设置的登录密码
-
(mysql) 删除表格 : drop table if exists <表名称>;
-
(mysql) 删除数据库 : drop database if exists <数据库名>;
-
(mysql) 删除字段 : alter table <表名> drop 字<段名>;
-
(mysql) 删除主键 : alter table <表名> drop primary key;
-
(mysql) 改用某个数据库 : use <数据库名>;
-
(mysql) 改变一张表的表名:alter table <旧表名> rename as <新表名>;
-
(mysql) 改变登录密码(在 " " 中输入想要设置的密码) : alter user user() identified by “”;
-
(mysql) 改变用户权限 : grant select, insert, update, delete on <库名>.<表名> to ‘用户名’@‘IP地址’;
- 查询权限 : select
- 增加权限 : insert
- 修改权限 : update
- 删除权限 : delete
-
(mysql) 改变用户权限为完全权限 : grant all privileges on . to ‘用户名’@‘IP地址’;
- 表示授权用户可以对所有数据库中的数据表进行任何操作
-
(mysql) 查看所有的数据库 : show databases;
-
(mysql) 查看某个数据库所有的表格 : show tables;
-
(mysql) 查看数据库中的某个表 : show tables from <数据库名>;
-
(mysql) 查看一张表中的数据 : select * from <数据库表名称>;
-
(mysql) 查看创建数据表时的定义语句 : show create table <表名称>;
-
(mysql) 查看创建数据库时的定义语句 : show create database <数据库名>;
-
(mysql) 查看一张表的具体结构:desc <表名>;
-
(mysql) 查看所有用户的ID地址和用户信息 : select host,user from mysql.user;
-
(mysql) 查看用户权限 : show grants for ‘用户名’@‘IP地址’;
-
(mysql) 刷新权限 : flush privileges;
-
(mysql) 退出mysql : quit;
注意点1 : 所有的数据库文件都存在data目录下,一个文件夹就对应一个数据库
注意点2 : mysql关键字不区分大小写,如果表名或字段名是一个特殊字符用``修饰
注意点3 : 保存字符串常用 varchar, 而保存大文本(博客、论文等) 通常用 text
知识点二 : 持久化 相关概念
为什么要使用数据库? 是为了将内存中的数据进行持久化存储.
内存中进程结束后其进程相关数据会丢失(如关闭后台中运行的QQ程序),但是再次打开之前关闭的应用后我们之前的数据还在的原因就是因为程序进行了持久化存储,将内存中的数据存到了关系型数据库中(持久化的主要作用).
知识点三 : 数据库 相关概念
名称 解释 说明 DB 数据库(Database) 即存储数据的“仓库”,其本质是一个文件系统。它保存了一系列有组织的数据。 DBMS 数据库管理系统(Database Management System) 是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制。用户通过数据库管理系统访问数据库中表内的数据。 SQL 结构化查询语言(Structured Query Language) 专门用来与数据库通信的语言。
知识点四 : DB 和 DBMS 关系图示
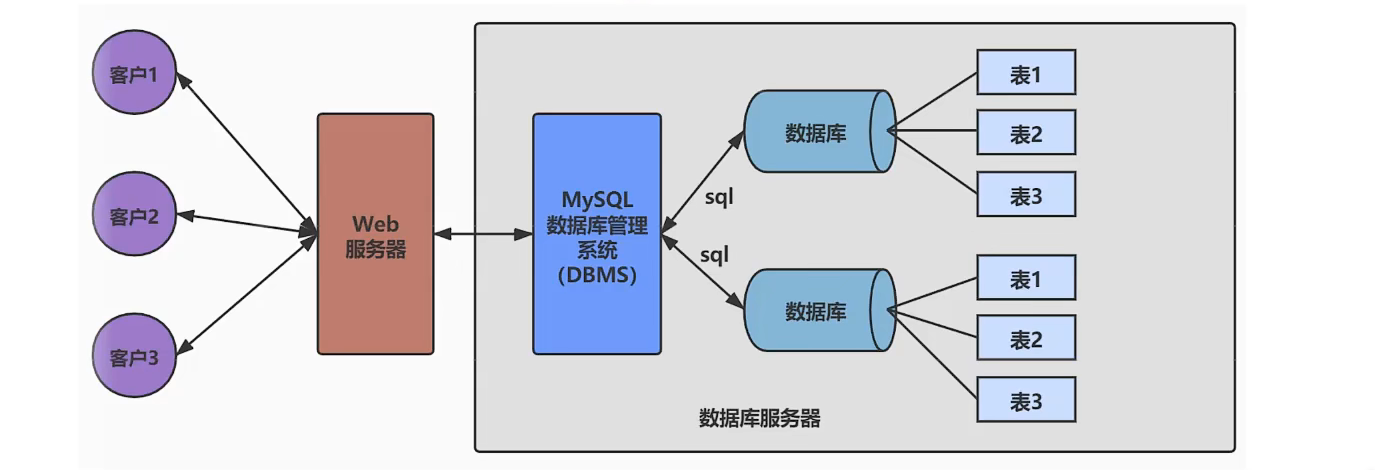
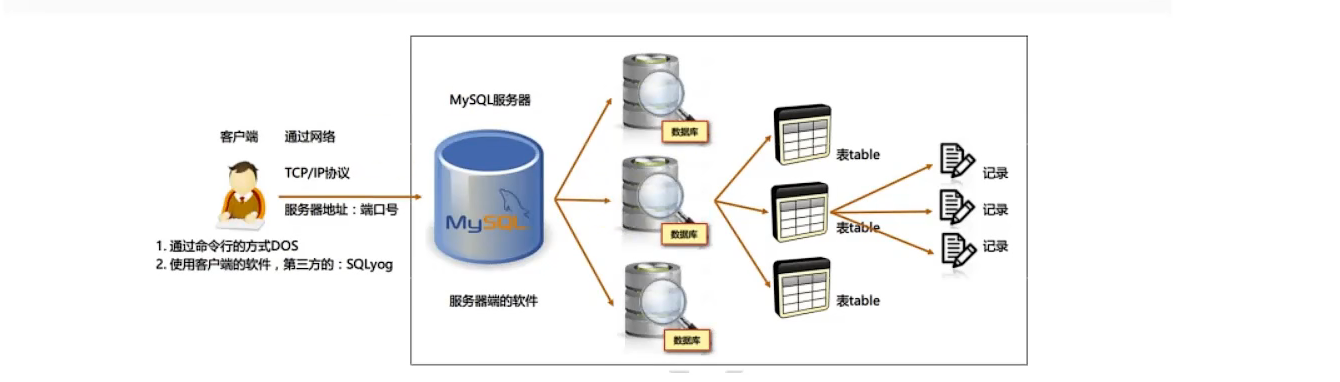
知识点五 : MySQL 概述
- MySQL是一个开放源代码的关系型数据库管理系统.
- MySQL6.x版本之后分为社区版和商业版.
- MySQL支持大型数据库,支持5000万条记录的数据仓库,32位系统表文件最大可支持4GB ,64位系统支持最大的表文件为8TB.
- MySQL使用标准的SQL数据语言形式.
- MySQL可以允许运行于多个系统上,并且支持多种语言。这些编程语言包括C、C++、Python、Java、Perl、PHP和Ruby等.
- MySQL从5.7版本直接跳跃发布了8.0版本.
知识点六 : RDBMS 对比 非RBDMS
名称 解释 说明 RDBMS 关系型数据库(Relational Database Management System),也指的是SQL 1.二维表格形式(二元关系):行(row)和列(column).
2.行+列=表,一组表=一个库.
3.表与表间数据记录有关系,即关系模型.
4.便于用SQL语句在一表及多表之间做非常复杂的数据查询.
5.事务支持使得对于安全性能很高的数据访问要求得以实现.非RDBMS 非关系型数据库(No SQL) 1.相当于传统关系型数据库的功能阉割版本,性能非常高.
2.只要不是Relational类型的数据库都属于非关系型数据库
3.非关系型数据库类型: 键值型(Key-Value)、文档型(Decument)、搜索引擎型(Search engine)、列式型(Wide column)、图形型(Graph)
4.NoSQL是对SQL的补充
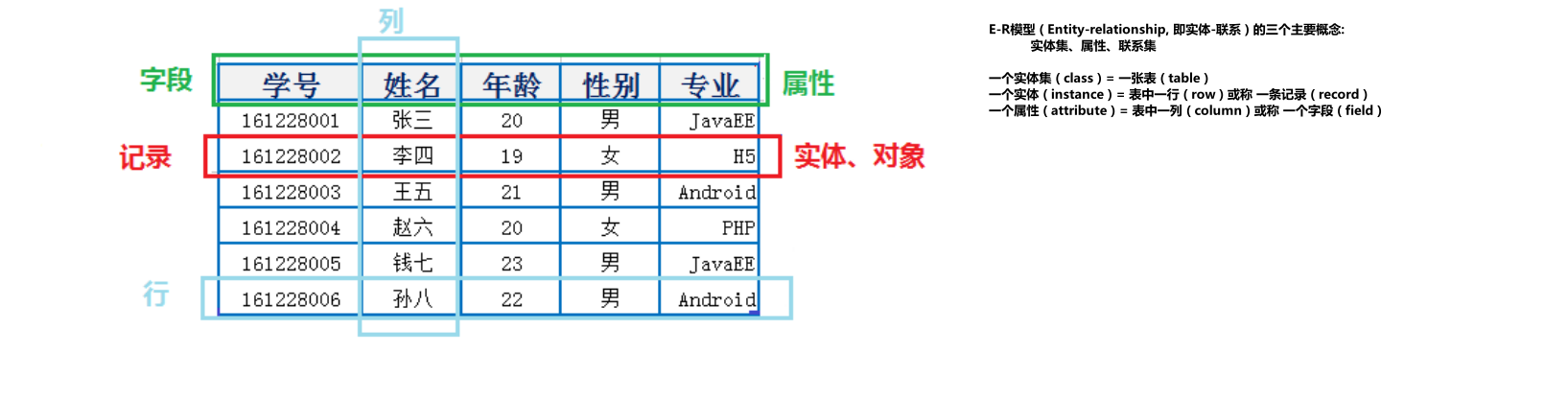
知识点七 : 数据库表的特性 ( 行、列 )
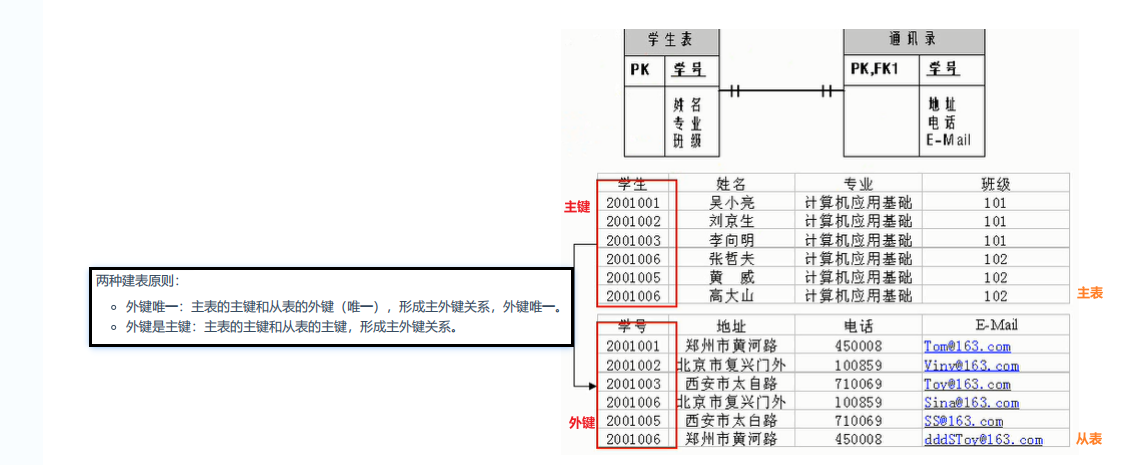
知识点八 : 数据库表的关联
-
一对一关系 :
-
一对多关系 :
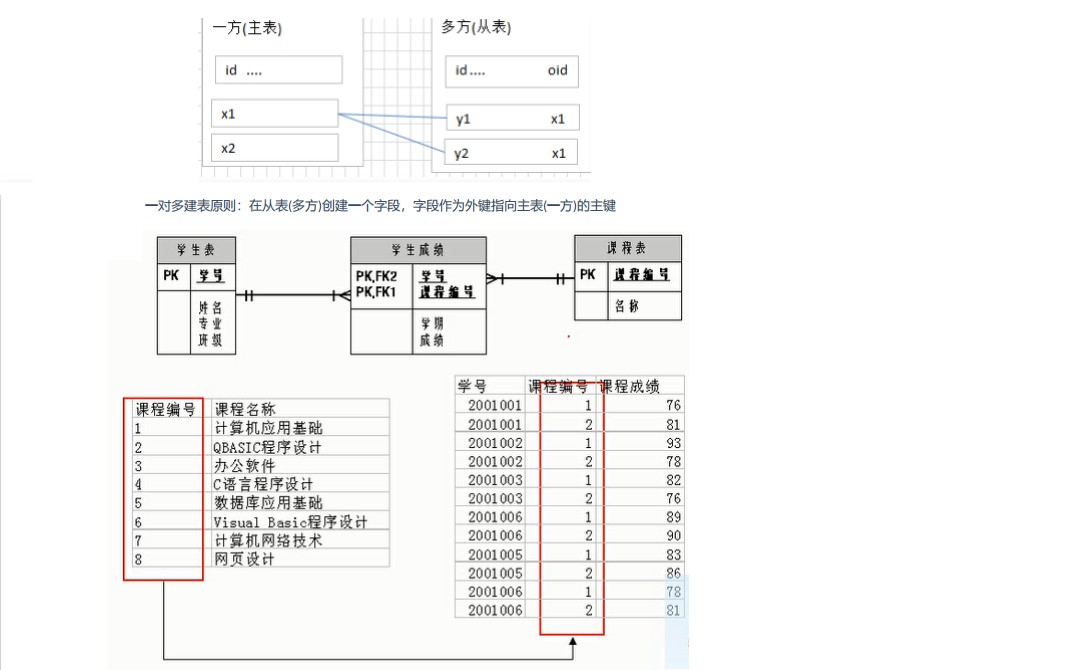
-
多对多关系 :

-
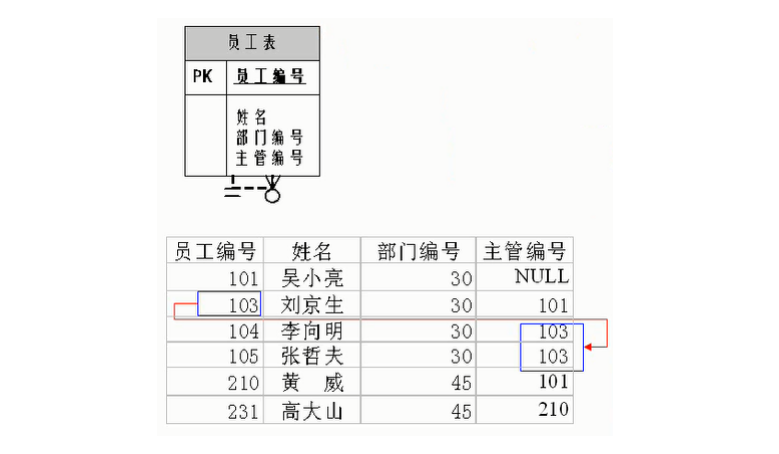
自我引用 :
知识点九 : SQL 语言功能分类 (DDL, DML, DCL)
分类 解释 说明 DDL 数据定义语言(Data Definition Languages) 这些语句定义了不同的数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构.
主要的语句关键字包括 CREATE 、 DROP 、 ALTER 、RENAME 、TRUNCATE等.DML (重要) 数据操作语言(Data Manipulation Language) 用于添加、删除、更新和查询数据库记录,并检查数据完整性.
主要的语句关键字包括 INSERT 、 DELETE 、 UPDATE 、 SELECT 等.(SELECT是SQL语言的基础,最为重要)DCL 数据控制语言(Data Control Language) 用于定义数据库、表、字段、用户的访问权限和安全级别.
主要的语句关键字包括 GRANT 、 REVOKE 、 COMMIT 、 ROLLBACK 、 SAVEPOINT 等.注意点1 : 因为查询语句使用的非常的频繁,所以很多人把查询语句单拎出来一类:DQL(数据查询语言).还有单独将 COMMIT 、 ROLLBACK 取出来称为TCL(Transaction Control Language,事务控制语言).
知识点十 : SQL语言规则与规范
-
SQL每条命令以 “;” 或 “\g” 或 “\G” 结束(我们常用";"结尾).
注意点1 : 如
USE dbtest2; -
字符串型和日期时间类型的数据可以使用单引号(’ ')表示
-
统一书写规范:
-
数据库名、表名、表别名、字段名、字段别名等都小写
-
SQL 关键字、函数名、绑定变量等都大写
注意点2 : MySQL 在 Windows 环境下大小写不敏感
-
-
注释:
- 单行注释:#注释文字(MySQL特有的方式)
- 单行注释:-- 注释文字 (–后面必须包含一个空格.)
- 多行注释:/* 注释文字 */
-
导入现有的数据表、表的数据:
- 方式1: source+文件全路径名
- 方式2: 基于具体的图形化界面的工具可导入数据
注意点3 : 在SQLyog–左上角[工具]–[执行SQL脚本] 中导入.
知识点十一 : SELECT 语句
-
员工信息表 (部分) :
employee_id first_name last_name email phone_number hire_date job_id salary commission_pct manager_id department_id 1 100 Steven King SKING 515.123.4567 1987/6/17 AD_PRES 24000 90 2 101 Neena Kochhar NKOCHHAR 515.123.4568 1989/9/21 AD_VP 17000 100 90 3 102 Lex De Haan LDEHAAN 515.123.4569 1993/1/13 AD_VP 17000 100 90 4 103 Alexander Hunold AHUNOLD 590.423.4567 1990/1/3 IT_PROG 9000 102 60 5 104 Bruce Ernst BERNST 590.423.4568 1991/5/21 IT_PROG 6000 103 60 6 105 David Austin DAUSTIN 590.423.4569 1997/6/25 IT_PROG 4800 103 60 7 106 Valli Pataballa VPATABAL 590.423.4560 1998/2/5 IT_PROG 4800 103 60 8 107 Diana Lorentz DLORENTZ 590.423.5567 1999/2/7 IT_PROG 4200 103 60 9 108 Nancy Greenberg NGREENBE 515.124.4569 1994/8/17 FI_MGR 12000 101 100 10 109 Daniel Faviet DFAVIET 515.124.4169 1994/8/16 FI_ACCOUNT 9000 108 100 注意点1 : 员工信息表的路径是 atguigudb.employees.
-
操作员工信息表 :
-
1.查询所有员工12个月的基本工资总和,并起别名为"年薪".
USE `atguigudb`; SELECT employee_id, last_name, salary * 12 AS "年薪" FROM employees;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注意点1 : 使用 AS 为字段 (字段即列) 起别名, 注意列的别名可以使用一对" "引起来而不要使用’ '.
-
2.计算所有员工12月的基本工资和奖金,并起别名为"年薪".
SELECT employee_id, last_name, salary * 12 * (1 + IFNULL(commission_pct,0)) AS "年薪" FROM employees;- 1
- 2
- 3
- 4
- 5
- 6
注意点2 : 空值用null表示 ,但null不等同于0,‘’ 或 ‘null’ , 当表中有空值,且空值参与运算后,其结果也一定为空.当我们在实际问题中遇到有空值的情况时,解决方法是引入IFNULL.
注意点3 : IFNULL (commission_pct,0) 的含义是, 如果该行数据的commission_pct属性为空值,则用0代替计算.
-
3.查询employees表中去除重复的job_id以后的数据.
SELECT DISTINCT job_id FROM employees;- 1
- 2
- 3
- 4
注意点4 : 使用DISTINCT语句去重.
-
4.查询工资大于12000的员工姓名和工资
SELECT last_name AS "姓氏", salary AS "薪资" FROM employees WHERE salary > 12000;- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
5.查询员工号为176的员工的姓名和部门号
SELECT last_name, department_id FROM employees WHERE employee_id = 176;- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
6.显示表 departments 的结构,并查询其中的全部数据
DESCRIBE departments; SELECT * FROM departments;- 1
- 2
- 3
注意点5 : 使用DESCRIBE语句查看表的结构.
-
知识点十二 : 事件
-
1.事件 常用命令
-
1.1 查看是否开启事件功能: show variables like ‘%event_sch%’;
-
1.2 开启事件功能: set global event_scheduler=1;
-
1.3 关闭事件功能: set global event_scheduler=0;
-
1.4 删除事件: drop event if exists <事件名>;
-
1.5 查看当前系统有哪些事件: show events;
-
1.6 查看事件具体信息: show create event <事件名>;
-
1.7 创建事件语法:
create event <事件名> <间隔> on schedule <间隔> starts <时间> ends <时间> do <SQL语句;>- 1
- 2
- 3
- 4
-
-
2.事件 实例
-
2.1 从2022-6-11 12:00:00到2022-6-12 00:00:00期间,每10分钟分析一次user表
create event analyzeUser on schedule every 10 minute starts '2022-6-11 12:00:00' ends '2022-6-12 00:00:00' do analyze table user;- 1
- 2
- 3
- 4
-
2.2 从当前时间开始,十分钟之后每10秒钟分析一次user表
create event analyzeUser on schedule every 10 second starts current_timestamp + interval 10 minute do analyze table user;- 1
- 2
- 3
-
2.3 从当前时间开始,十分钟之后每10分钟分析一次user表,10天之后结束
create event analyzeUser on schedule every 10 minute starts current_timestamp + interval 10 minute ends now() + interval 10 day; do analyze table user;- 1
- 2
- 3
- 4
注意点1 : 事件默认情况下不开启
注意点2 : 开启/关闭 事件值也可以用 ON/OFF (对应 1/0)
注意点3 : starts和ends后面无;
注意点4 : 表示当前时间: current_timestamp 或 now()
注意点5 : 表示间隔: interval
-
知识点十三 : 存储过程
-
1.存储过程 常用命令
-
1.1 调用存储过程: call <过程名()>;
-
1.2 删除存储过程: drop procedure if exists <过程名>;
-
1.3 查看全部存储过程: show procedure status;
-
1.4 查看某个数据库全部存储过程:show procedure status where db=‘<数据库名>’;
-
1.5 查看某个存储过程详细信息: show create procedure <过程名>;
-
1.6 创建存储过程语法:
delimiter // create procedure <过程名()> begin <SQL语句;> end // delimiter ;- 1
- 2
- 3
- 4
- 5
- 6
-
-
2.存储过程 实例
delimiter // create procedure countNumber(in i int) begin select i*i; end // delimiter ; 执行: call countNumber(10);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注意点1 : 存储过程相当于是函数, 一个存储过程就相当于是一个功能模块,可以反复调用
注意点2 : 因为SQL语句也是以;界定语句是否结束,所以用delimiter将存储过程的结束符转换为//,最后再用 delimiter 换回;
注意点3 : in i int的意思是in是输入,输入的值赋值给变量i, 这个值的类型为整型int
知识点十四 : 主键
-
1.主键 常用命令
- 1.1 创建表时添加单主键: primary key ( <列名>)
- 1.2 创建表时添加多主键: primary key ( <列名1>,<列名2>,<列名3>,…)
- 1.3 创建表时未指定主键后追加主键: alter table <表名> add primary key( <列名> );
- 1.4 删除主键: alter table <表名> drop primary key;
注意点1 : 一张表中只能有一个主键,主键唯一不可重复
注意点2 : 一个主键可以包含多列,此时多列值仅一列不同则不算重复(如id和name为主键,(1,“小明”)和(1,“小红”)不算重复,只有id和name都相同时才算重复)
知识点十五 : 外键
-
1.外键 常用命令
- 1.1 创建外键(在子表中): constraint <外键名> foreign key(<子表列名>) references <父表(父表列名)>
- 1.2 删除外键: alter table <表名> drop foreign key <外键名>;
- 1.3 追加外键: alter table <表名> add constraint <外键名> foreign key(<子表列名>) references <父表(父表列名)> on delete cascade on update cascade
-
2.外键 解释
-
2.1 外键约束即B表(子表)受限于A表(父表),在B表中插入的值id必须在A表中存在,通过外键将不相关的A表和B表联系成一个整体(如学生表中只有两个学生,则成绩表中无法插入第三行数据,因为第三个学生不存在)
-
2.2 未设置on delete cascade/on delete cascade时,子表中有值,父表中对应的值不能删除(子表score表中有(1,87),此时父表stu表(1,“小明”)就不能被删除) 未设置on delete cascade/on delete cascade时,父表中有值,子表中对应的值可以删除(父表stu表中有(1,“小明”),此时子表score表中对应的列(1,87)可以被删除)
-
2.3 on delete cascade: 父表删除行数据,子表相对应的数据也要删除
on delete cascade: 父表做相应修改,子表也做相应修改
-
2.4 只有innodb存储引擎才能使用外键
-
知识点十六 : 字段属性
-
1.字段属性 常用命令
- 1.1 自增主键归零: truncate table 表名;
注意点1 : 注意 truncate 会一次性地从表中删除所有数据且删除不可逆.
知识点十七 : 属性解释
名称 解释 主键(primary key) 唯一标识 非空(not null) 必须有值 自增(auto_increment) 每次自己+1 Zerofill 零填充不足位数用0填充 如int(3):5——>005 unsigned 无符号的整数,不能为负数 datetime YYY-MM-DD(date日期格式) HH:mm:ss(time时间格式) 最常用的时间格式 timestamp 时间戳,从1970.1.1到现在的毫秒数
知识点十八 : 联表查询
- 联表查询 : 数据不对称时,以哪张表为主显示
知识点十九 : 自连接
-
1.自连接定义 : 一张表拆为两张一样的表
-
2.自连接实例 :
CREATE TABLE `category`( `categoryid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主题id', `pid` INT(10) NOT NULL COMMENT '父id', `categoryname` VARCHAR(50) NOT NULL COMMENT '主题名字', PRIMARY KEY (`categoryid`) ) ENGINE=INNODB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8; INSERT INTO `category` (`categoryid`, `pid`, `categoryname`) VALUES ('2','1','信息技术'), ('3','1','软件开发'), ('5','1','美术设计'), ('4','3','数据库'), ('8','2','办公信息'), ('6','3','web开发'), ('7','5','ps技术'); SELECT a.categoryname AS '父类',b.categoryname AS '子类' FROM category AS a ,category AS b WHERE a.categoryid = b.pid SELECT studentno,studentname,gradename FROM student s INNER JOIN grade g ON s.gradeid = g.gradeid SELECT `subjectname`,`gradename` FROM `subject` sub INNER JOIN `grade` g ON sub.gradeid = g.gradeid SELECT s.`studentno`,`studentname`,`subjectname`,`studentresult` FROM `student` s INNER JOIN `result` r ON s.`studentno` = r.`studentno` INNER JOIN `subject` sub ON r.`subjectno` = sub.`subjectno` WHERE subjectname LIKE "高等数学%" -- like _和% in ("xxx","xxx")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
知识点二十 : 分页(limit)和排序(order by)
-
1.排序定义 : 升序 ASC(上小下大),降序DESC(上大下小)
-
2.排序实例 :
-
2.1 创建相关信息的sql文件
-- 创建一个school数据库 CREATE DATABASE IF NOT EXISTS `school`; -- 使用school数据库 USE `school`; -- 创建年级表 DROP TABLE IF EXISTS `grade`; CREATE TABLE `grade`( `gradeid` INT(11) NOT NULL AUTO_INCREMENT COMMENT '年级编号', `gradename` VARCHAR(50) NOT NULL COMMENT '年级名称', PRIMARY KEY (`gradeid`) ) ENGINE=INNODB AUTO_INCREMENT = 6 DEFAULT CHARSET = utf8; INSERT INTO `grade` (`gradeid`,`gradename`) VALUES (1,'大一'),(2,'大二'),(3,'大三'),(4,'大四'),(5,'预科班'); -- 创建成绩表 DROP TABLE IF EXISTS `result`;`school` CREATE TABLE `result`( `studentno` INT(4) NOT NULL COMMENT '学号', `subjectno` INT(4) NOT NULL COMMENT '课程编号', `examdate` DATETIME NOT NULL COMMENT '考试日期', `studentresult` INT (4) NOT NULL COMMENT '考试成绩', KEY `subjectno` (`subjectno`) )ENGINE = INNODB DEFAULT CHARSET = utf8; INSERT INTO `result`(`studentno`,`subjectno`,`examdate`,`studentresult`) VALUES (1000,1,'2013-11-11 16:00:00',85), (1000,2,'2013-11-12 16:00:00',70), (1000,3,'2013-11-11 09:00:00',68), (1000,4,'2013-11-13 16:00:00',98), (1000,5,'2013-11-14 16:00:00',58); -- 创建学生表 DROP TABLE IF EXISTS `student`; CREATE TABLE `student`( `studentno` INT(4) NOT NULL COMMENT '学号', `loginpwd` VARCHAR(20) DEFAULT NULL, `studentname` VARCHAR(20) DEFAULT NULL COMMENT '学生姓名', `sex` TINYINT(1) DEFAULT NULL COMMENT '性别,0或1', `gradeid` INT(11) DEFAULT NULL COMMENT '年级编号', `phone` VARCHAR(50) NOT NULL COMMENT '联系电话,允许为空', `address` VARCHAR(255) NOT NULL COMMENT '地址,允许为空', `borndate` DATETIME DEFAULT NULL COMMENT '出生时间', `email` VARCHAR (50) NOT NULL COMMENT '邮箱账号允许为空', `identitycard` VARCHAR(18) DEFAULT NULL COMMENT '身份证号', PRIMARY KEY (`studentno`), UNIQUE KEY `identitycard`(`identitycard`), KEY `email` (`email`) )ENGINE=MYISAM DEFAULT CHARSET=utf8; INSERT INTO `student` (`studentno`,`loginpwd`,`studentname`,`sex`,`gradeid`,`phone`,`address`,`borndate`,`email`,`identitycard`) VALUES (1000,'123456','张伟',0,2,'13800001234','北京朝阳','1980-1-1','text123@qq.com','123456198001011234'), (1001,'123456','赵强',1,3,'13800002222','广东深圳','1990-1-1','text111@qq.com','123456199001011233'); -- 创建科目表 DROP TABLE IF EXISTS `subject`; CREATE TABLE `subject`( `subjectno`INT(11) NOT NULL AUTO_INCREMENT COMMENT '课程编号', `subjectname` VARCHAR(50) DEFAULT NULL COMMENT '课程名称', `classhour` INT(4) DEFAULT NULL COMMENT '学时', `gradeid` INT(4) DEFAULT NULL COMMENT '年级编号', PRIMARY KEY (`subjectno`) )ENGINE = INNODB AUTO_INCREMENT = 19 DEFAULT CHARSET = utf8; INSERT INTO `subject` (`subjectno`,`subjectname`,`classhour`,`gradeid`) VALUES (1,'高等数学-1',110,1), (2,'高等数学-2',110,2), (3,'高等数学-3',100,3), (4,'高等数学-4',130,4), (5,'C语言-1',110,1), (6,'C语言-2',110,2), (7,'C语言-3',100,3), (8,'C语言-4',130,4), (9,'Java程序设计-1',110,1), (10,'Java程序设计-2',110,2), (11,'Java程序设计-3',100,3), (12,'Java程序设计-4',130,4), (13,'数据库结构-1',110,1), (14,'数据库结构-2',110,2), (15,'数据库结构-3',100,3), (16,'数据库结构-4',130,4), (17,'C#基础',130,1);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
-
2.2 相关语句
SELECT s.`studentno`,`studentname`,`subjectname`,`studentresult` FROM `student` s INNER JOIN `result` r ON s.`studentno` = r.`studentno` INNER JOIN `subject` sub ON r.`subjectno` = sub.`subjectno` WHERE subjectname LIKE "高等数学%" ORDER BY studentresult DESC- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
-
3.分页 : limit 起始下标,pagesize
- [pagesize:页面大小]
- [(n-1)*pagesize:起始值]
- [n:当前页]
- [数据总数/页面大小 = 总页数]
-
4.分页实例 :
SELECT s.`studentno`,`studentname`,`subjectname`,`studentresult` FROM `student` s INNER JOIN `result` r ON s.`studentno` = r.`studentno` INNER JOIN `subject` sub ON r.`subjectno` = sub.`subjectno` WHERE subjectname LIKE "高等数学%" ORDER BY studentresult DESC LIMIT 0,2- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
知识点二十一 : 子查询
-
1.子查询定义: 本质:where(select)
-
2.子查询实例
/* 查询所有高等数学的考试结果(学号,科目号,成绩),且降序排列 */ -- 方式1:连接查询 SELECT `studentno`,r.`subjectno`,`studentresult` FROM `result` r INNER JOIN `subject` sub ON r.`subjectno` = sub.`subjectno` WHERE subjectname LIKE "高等数学%" ORDER BY studentresult DESC -- 方式2:子查询 SELECT `studentno`,`subjectno`,`studentresult` FROM `result` WHERE studentno=(SELECT `subjectno` FROM `subject` WHERE `subjectname` = '高等数学-1') SELECT s.`studentno`,`studentname`,`studentresult` FROM student s INNER JOIN result r ON s.`studentno` = r.`studentno` WHERE `subjectname` = (SELECT `suject`)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
知识点二十二 : 常用函数
-
1.数学运算 :
SELECT ABS(-8) -- 取绝对值:返回8 SELECT CEILING(9.4) -- 向上取整:返回10 SELECT FLOOR(9.4) -- 向下取整:返回9 SELECT RAND() -- 返回一个随机数(范围[0,1]):返回随机值 SELECT SIGN(10) -- 判断符号(负数返回-1,0返回0,正数返回1):返回1- 1
- 2
- 3
- 4
- 5
- 6
-
2.字符串函数 :
SELECT CHAR_LENGTH("他朝若是同淋雪 此生也算共白头") -- 统计字符串长度(空格,符号等都算入):返回15 SELECT CONCAT('我','爱','祖国') -- 拼接字符串:返回我爱祖国 SELECT INSERT('我爱学习',1,2,'超级热爱') -- 查询替换(1,2表示从第1个字符串开始往后替换2个字符):返回超级热爱学习 SELECT LOWER('HELLOWORLD') -- 大写转小写:输出helloworld SELECT UPPER('helloworld') -- 小写转大写:输出HELLOWORLD SELECT INSTR('helloworld','o') -- 返回第一次出现的子串的索引:返回5 SELECT REPLACE('爱情使人无畏','爱情','学习') -- 替换出现的指定字符串:返回学习使人无畏 SELECT SUBSTR('爱情使人无畏',1,2) -- 返回指定的子字符串:返回爱情 SELECT NOW() -- 获取当前时间 SELECT SYSTEM_USER() -- 系统用户 SELECT VERSION() -- 版本 SELECT REPLACE(studentname,'张',"徐") FROM student WHERE studentname LIKE '张%'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
-
3.聚合函数 :
SELECT COUNT(studentname) FROM student; -- 统计表中数据- 1
知识点二十三 : 分组和过滤
-
分组和过滤实例 :
/*查询不同课程的平均分,最高分,最低分,平均分大于80*/ SELECT subjectname,AVG(studentresult) AS 平均分,MAX(studentresult) AS 最高分,MIN(studentresult) AS 最低分 FROM result r INNER JOIN `subject` sub ON r.`subjectno` = sub.`subjectno` GROUP BY r.subjectno -- 分组的依据 HAVING 平均分>80- 1
- 2
- 3
- 4
- 5
- 6
知识点二十四 : MD5加密
-
MD5加密实例:
/*MD5不可逆*/ CREATE TABLE `testmd5`( `id` INT(4) NOT NULL, `name` VARCHAR(20) NOT NULL, `pwd` VARCHAR(50) NOT NULL, PRIMARY KEY(`id`) )ENGINE=INNODB DEFAULT CHARSET=utf8 INSERT INTO `testmd5` VALUES (1,'张三','123456'), (2,'李四','123456'), (3,'王五','123456') -- 传入时加密 INSERT INTO `testmd5` VALUES (4,'赵六',MD5('123456')) UPDATE `testmd5` SET pwd=MD5('1234567') WHERE `id`=4 AND `name`='赵六' -- 加密全部密码 UPDATE `testmd5` SET pwd=MD5(pwd) SELECT * FROM `testmd5` WHERE `name`='赵六' AND pwd=MD5('1234567')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
知识点二十五 : 事务
-
事务实例 :
/* 什么是事物:要么都成功,要么都失败(转账问题) ACID原则(事务原则):原子性,一致性,隔离性,持久性 */ /*MySQL默认开启事务自动提交*/ SET autocommit = 0 -- 关闭 SET autocommit = 1 -- 开启(默认) SAVEPOINT 保存点名 -- 设置一个事务的保存点 ROLLBACK TO SAVEPOINT 保存点名 -- 回滚到保存点 RELEASE SAVEPOINT 保存点名 -- 撤销保存点 /*1.手动处理事务*/ SET autocommit = 0 -- 关闭自动提交 /*2.事务开启*/ START TRANSACTION -- 标志一个事务的开始,从该行语句之后的sql都视为在同一事务内 COMMIT -- 提交:持久化(成功情况) ROLLBACK -- 回滚:回到原来的样子(失败情况) /*3.事务结束*/ SET autocommit = 1 -- 开启自动提交 /*应用场景:转帐*/ -- 1.创建数据库 CREATE DATABASE `bank` CHARACTER SET utf8 COLLATE utf8_general_ci USE `bank` -- 2.创建数据表 CREATE TABLE `account`( `id` INT(3) NOT NULL AUTO_INCREMENT, `name` VARCHAR(30) NOT NULL, `money` DECIMAL(9,2) NOT NULL, PRIMARY KEY(`id`) ) ENGINE=INNODB DEFAULT CHARSET=utf8 -- 3.插入数据 INSERT INTO `account` (`name`,`money`) VALUES ('A',2000.00), ('B',10000.00) -- 4.模拟转账:事务 SET autocommit = 0; START TRANSACTION UPDATE account SET money=money-500 WHERE `name` = 'A' UPDATE account SET money=money+500 WHERE `name` = 'B' COMMIT; ROLLBACK; SET autocommit = 1;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
知识点二十六 : 索引
-
索引实例 :
/* 主键索引-PRIMARY KEY:唯一标识不可重复 唯一索引-UNIQUE KEY:避免重复的字段出现,唯一索引可重复,多个列可以标识为唯一索引 常规索引-KEY/INDEX:默认,通过index,key关键字来设置 全文索引-FullText:快速定位数据 */ SHOW INDEX FROM `student` -- 显示所有的索引信息 ALTER TABLE school.student ADD FULLTEXT `studentName`(`studentName`) -- 增加一个全文索引(索引名) 列名 /*非全文索引*/ EXPLAIN SELECT * FROM student; -- 分析sql的执行情况- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
知识点二十七 : 权限管理
-
权限管理实例 :
-- 创建用户 CREATE USER baimao IDENTIFIED BY '123456' -- 修改当前用户密码 SET PASSWORD = PASSWORD('111111') -- 修改指定用户密码 SET PASSWORD FOR root@localhost = PASSWORD('123456') -- 重命名(旧名 to 新名) RENAME USER baimao TO baimao2 -- 用户授权 ALL PRIVILEGES 全部的权限(全部库,全部表:*.*) -- [注:这种用户无法给别的账户授权,其他的权限与root一致] GRANT ALL PRIVILEGES ON *.* TO baimao2 -- 查询权限(指定用户) SHOW GRANTS FOR baimao2 -- 查询权限(root用户) SHOW GRANTS FOR root@localhost -- 撤销权限 REVOKE ALL PRIVILEGES ON *.* FROM baimao2 -- 删除用户 DROP USER baimao- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
知识点二十八 : 数据库备份
-
数据库备份实例:
/* 方式一:直接拷贝物理文件 方式二:在可视化工具中手动导出 方式三:使用命令行导出 [单数据表导出]C:\Users\Administrator.DESKTOP-SG01GTP>mysqldump -hlocalhost -uroot -p123456 school student > G:/a.sql [多数据表导出]C:\Users\Administrator.DESKTOP-SG01GTP>mysqldump -hlocalhost -uroot -p123456 school student result> G:/b.sql [数据库导出]C:\Users\Administrator.DESKTOP-SG01GTP>mysqldump -hlocalhost -uroot -p123456 school > G:/c.sql */ /* 命令行导入数据库: mysql>use school; mysql>source G:/a.sql */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
知识点二十九 : 通过sql文件插入百万条数据
CREATE TABLE `app_user` ( `id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT, `name` VARCHAR(50) DEFAULT'' COMMENT'用户昵称', `email` VARCHAR(50) NOT NULL COMMENT'用户邮箱', `phone` VARCHAR(20) DEFAULT'' COMMENT'手机号', `gender` TINYINT(4) UNSIGNED DEFAULT '0'COMMENT '性别(0:男;1:女)', `password` VARCHAR(100) NOT NULL COMMENT '密码', `age` TINYINT(4) DEFAULT'0' COMMENT '年龄', `create_time` DATETIME DEFAULT CURRENT_TIMESTAMP, `update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=INNODB DEFAULT CHARSET=utf8 COMMENT = 'app用户表' /*插入100万条数据*/ /**/ DELIMITER $$ -- 写函数前必写 CREATE FUNCTION mock_data() RETURNS INT BEGIN DECLARE num INT DEFAULT 1000000; DECLARE i INT DEFAULT 0; WHILE i<num DO INSERT INTO app_user(`name`,`email`,`phone`,`gender`,`password`,`age`) VALUES (CONCAT('用户',i),'test123@qq.com',CONCAT('18',FLOOR(RAND()*((999999999-100000000)+100000000))),FLOOR(RAND()*2),UUID(),FLOOR(RAND()*100)); SET i = i+1; END WHILE; RETURN i; END; SELECT mock_data(); -- 耗时:24.390 sec(秒) -- ============================索引操作============================ SELECT * FROM app_user WHERE `name` = '用户10000'; -- 耗时:0.594 sec(秒) SELECT * FROM app_user WHERE `name` = '用户100000'; -- 耗时:0.566 sec(秒) EXPLAIN SELECT * FROM app_user WHERE `name` = '用户10000'; -- row:99783 SELECT * FROM student -- create index 索引名 on 表(字段 ) -- 索引名: id_表名_字段名 CREATE INDEX id_app_user_name ON app_user(`name`); SELECT * FROM app_user WHERE `name` = '用户10000'; -- 耗时:0.012 sec(秒) SELECT * FROM app_user WHERE `name` = '用户100000'; -- 耗时:0 sec(秒) EXPLAIN SELECT * FROM app_user WHERE `name` = '用户10000'; -- row:1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
知识点三十 : 通过 pymysql 模块操作数据库
import pymysql """1.使用connect()函授创建数据库连接""" conn = pymysql.connect( host='127.0.0.1', # 设置MySQL系统IP地址 port=3306, # 设置MySQL系统端口 user='root', # 设置登录用户名 password='root', # 设置登录密码 database='test', # 设置要连接的数据库名称 charset='utf8' # 设置数据编码格式 ) """2.创建游标,通过游标来选择和取出数据""" # 创建元组类型游标 sursor = conn.cursor() # 创建字典类型游标 cursor = conn.cursor(pymysql.cursors.DictCursor) """3.通过execute()函数执行SQL命令""" name = '张三' sql = 'SELECT * FROM staff WHERE name=%s;' # 在staff表中根据员工姓名查询数据记录 res = cursor.execute(sql, (name)) # 将参数值"张三"拼接到sql命令中并执行命令 """4.通过fetchall()函数取出所有数据""" print(cursor.fetchall()) # fetchone()是取出一条数据,fetchmany(3)取出三条数据 """5.关闭游标和数据库连接""" cursor.close() # 关闭游标 conn.close() # 关闭数据库- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
-
相关阅读:
MYSQL的触发器
vim 从嫌弃到依赖(20)——global 命令
几种后端开发中常用的语言。
http-response返回数据被截断,返回不完全
[附源码]java毕业设计商场日常维修管理系统
静态HTML旅行主题网页作业——青岛民俗7页html+css+javascript+jquery 地方民俗网页设计与实现
游戏行业需要堡垒机吗?用哪款堡垒机好?
NISP二级证书换CISP证书是怎么回事?
Python-ONNX 相关
Nginx入门指南:轻松掌握Web服务器技术
- 原文地址:https://blog.csdn.net/m0_56126722/article/details/126310497
