-
线索二叉树以及哈夫曼树
- 线索二叉树有前驱结点和后继节点的概念,
线索二叉树分为中序线索二叉树,前序线索二叉树,后序线索二叉树。中序线索二叉树就是根据中序遍历的结果,把中序遍历的结果看成一个线性表,对于线性表来说,每一个节点都会有一个前驱节点和一个后继节点。
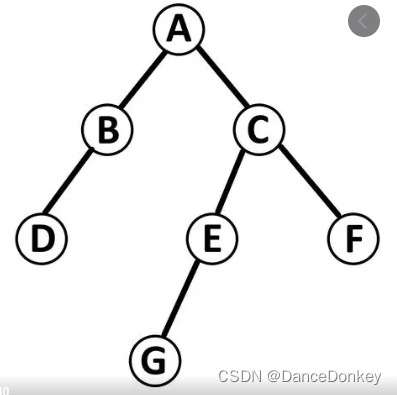
上图二叉树的中序遍历结果是:DBAGECF。
D没有前驱节点,F没有后继节点。如果想找一个节点的前驱节点,例如想找E的前驱节点,只能从根节点开始再进行一次中序遍历,用两个指针,一个指向当前节点,一个指向当前节点的上一个遍历的节点。对普通二叉树结构进行改造,升级为线索二叉树。
typedef struct Node{ int data; struct Node * left; struct Node * right; int ltag;//表示左节点的指向类型 指向的是真正的左节点还是前驱节点 int rtag;//表示右节点的指向类型 指向的是真正的右节点还是后继节点 (如果指向的不是真正自己节点的指针成为线索指针) //两个tag标识为0的时候,表示指向的为其子节点,标识为1的时候表示指向是线索节点。 }*TreeNode;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
最终的目的还是得到二叉树的中序遍历序列后,能够挨个遍历所有节点,如果只是单纯的一个中序遍历序列,则无法根据一个元素找到下一个元素,因为没有指针,而将这些叶子节点的空指针线索化以后,则可以很顺利的遍历二叉树。
理解中序前驱,中序后继,先序前驱,先序后继节点的概念,中序前驱就是在中序遍历的序列中某个节点的前驱节点。
- 中序线索化实现代码
//pre节点,保存中序遍历时某节点的前驱节点 Tree pre = NULL; //将tree节点线索化 void clue(Tree tree) { //如果当前节点的左节点为空,则应该让当前节点的左节点线索化 if(tree->left == NULL){ tree->left = pre; tree->ltag = 1; } if(pre != NULL && pre->right == NULL){ //这种情况是当前节点的前驱节点不是NULL(pre指针已经移动过了,并且pre指针的right是NULL,说明是个叶子节点right是NULL,则此时需要将pre节点指向的节点的right) pre->right = tree; pre->rtag = 1; } //重新赋值前驱节点 pre = tree; } void visit(Tree tree) { if (tree != NULL) { visit(tree->left); //printf("%d,", tree->data); clue(tree);//中序线索话二叉树 visit(tree->right); } } void zhongxu(Tree tree) { visit(tree); //判断最后一个节点的rchild指针是否为NULL,如果是则更正为1 if(pre ->right == NULL){ pre->rtag = 1; } } int main() { //定义一个二叉树 Tree tree; tree = NULL; //添加元素 addNode(tree, 20); addNode(tree, 15); addNode(tree, 33); addNode(tree, 42); addNode(tree, 1); addNode(tree, 9); //中序遍历 zhongxu(tree); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
处理完所有节点的线索化以后,最后一个节点的线索化要单独处理,在中序遍历的过程中最后一个访问的节点肯定没有子节点了,所以转换成中序线索序列后,该节点肯定也没有后继节点了,所以要让最后一个节点的后继节点设置为null,并将rtag设置为1,表示没有后继节点。
前序遍历时要单独注意,上图二叉树的前序遍历结果是:ABDCEGF。 B的前驱节点是A,后继节点是D,由于在前驱遍历时是先访问根节点再访问左节点,再访问右节点,所以在根节点会被访问2次,此时在访问左节点时需要判断左节点的类型是不是ltag == 0 。
- 中序线索二叉树找后继。
在中序遍历下,访问顺序是左根右,所以一个节点的后继节点应该是该节点的最后一个不为null的左节点。
//找到以p节点为根节点的二叉树在中序遍历序列中最开始的节点 Tree findNextNode(TNode * p){ Tree lNode = p->left; while (lNode->ltag == 0){ lNode = lNode->left; } return lNode; } Tree nextNode(TNode * p ){ if(p->rtag == 0){ return findNextNode(p->right); } return p->right; } //使用后继节点遍历这颗树 void inOrder(Tree tree){ //先找到这颗树在中序遍历序列中的首个节点 TNode * firstNode = findNextNode(tree); //从这个节点开始一次后继遍历 while (firstNode != NULL){ printf(" %s \n", firstNode->data ); firstNode = nextNode(firstNode); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
这里要注意的是,使用中序线索序列遍历二叉树的时候,在找下一个节点的时候,也就是后继节点的时候需要判断这个节点的ltag是否是0,如果是0,则需要一次循环找到左子节点的中序遍历序列的首个节点,如果是1,则说明已经被线索化,那么直接返回左子节点即可。
- 树的存储方式
1.(双亲表示法) 这里以广义上的树来说,可以使用顺序存储来实现,定义一个数组,每个元素的parent保存了父节点的下标。这种表示方法为双亲表示法。
typedef struct Node { int parent = -1; int data; } ThreadNode; int main() { ThreadNode threadNode[10]; threadNode[0].data = 5; threadNode[1].data = 10; threadNode[1].parent = 0; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2.(孩子表示法,使用了顺序+链式存储)
同样是有个数组,是一个结构体数组,结构体数组保存了每个树节点的真正的数据,以及一个结构体,结构体是一个孩子结构体,保存了当前是父节点的第几个孩子以及下一个孩子的指针。
struct CTNode{ int child;//当前是父节点的第几个孩子 struct CTNode *next;//下一个孩子 }; typedef struct { int data; struct CTNode * firstChild;//第一个孩子指针 } CTBOX; typedef struct { CTBOX nodes[20];//顺序存储方式实现数组 int n,r;//节点数和根的位置 };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- (孩子兄弟表示法,纯链式存储方式)
typedef struct CSNode{ int data;//节点数据 struct CSNode * firstchild;//该指针保存第一个孩子节点 struct CSNode * nextsibling;// 该指针保存当前节点的右兄弟指针 };- 1
- 2
- 3
- 4
- 5
- 6
firstchild表示当前节点的第一个孩子节点,而nextsibling保存了当前节点的右兄弟节点。利用这种存储方式可以将多叉树转换为2叉树(树和二叉树相互转换问题)。
上述过程可以将树转换为二叉树,而根据转换思想,我们也可以逆推出将二叉树转换为树。- 二叉树和森林转换
森林:森林是m(m >= 0)颗互不相交的树的集合。
将森林转换成二叉树:将每个森林先转换成二叉树,那么每个森林的根节点可以看成是一系列的兄弟节点,将这些兄弟节点连起来就组成了二叉树。
将二叉树转换为森林:可以将二叉树的没一个节点的右节点都看成兄弟节点,依次把这些兄弟节点看成头节点拆开,变成了森林。
- 树和森林的遍历
树的遍历方式有先根遍历,后根遍历,层次遍历。
先根遍历就是先访问树的根节点,如果有下一颗子树,继续访问下一颗子树。其遍历的结果应等于将该树转化为二叉树以后的前序遍历结果。
树的后根遍历其遍历结果等同于转换成二叉树以后的中序遍历。先根遍历和后根遍历为深度优先遍历 (优先往深处走),而层次遍历是一种广度优先遍历(优先往广度走)。
森林的遍历方式有先序遍历和后序遍历。
对于森林的先序遍历来说,先序遍历就是把森林中的每颗子树用先跟遍历的方式遍历一遍。
森林的中序遍历,效果等同于依次对各个子树实现后根遍历,注意是后根遍历!!!!!!!哈夫曼树
- 带权路径
-
节点的权:将树中的某些节点赋值上权重,则带权路径长度就等于从根节点出发到达该节点经过的边 * 该节点的权重
-
树的带权路径长度:从根节点出发到每一个叶子节点的带权路径长度之和成为树的带权路径长度。成为WPL。
-
哈夫曼树定义:在含有n个带权叶子节点的二叉树中,其中带权路径长度最小的二叉树成为哈夫曼树,也称最优二叉树。
- 如何构造一个哈夫曼树
将最开始n个带权节点找出两个小的,两两结合,新生成的节点的权重继续和剩余的节点进行凉凉结合,直到把所有节点都结合完成。
- 哈夫曼树的性质
- n个带权节点构建的哈夫曼树共有 2n-1个节点。
- 权重大的节点层级低,权重小的节点层级高。
- 哈夫曼树中,不存在度为1的节点。
- 哈夫曼树并不唯一。
- 哈夫曼编码
哈夫曼编码解决的是多次出现的某个东西,以最小综合实现数据传输。编码之后如何表示? 由于是二叉树,往左走记为0,往右走记为1,那么每个节点就可以得到一个唯一的编码,这就是哈夫曼编码。!
-
相关阅读:
Django学习笔记
PyTorch搭建Transformer实现多变量多步长时间序列预测(负荷预测)
常用排序方法、sort的实现原理、快排的优化
全员“拉踩”苹果,入局一年多的苹果芯片已成“行业标杆”?
【Zabbix监控二】之zabbix自定义监控内容案例(自动发现、自动注册)
LeetCode动态规划
案例题-系统开发
leetcode 39. 组合总和(完全背包问题)
支持向量机 (SVM) 算法详解
Visual Studio自定义模板参数、备注
- 原文地址:https://blog.csdn.net/qq_43750656/article/details/125940070
