-
数据库学习之表的增删查改
引入
CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
Create(创建)
INSERT [INTO] table_name [(column [, column] ...)] VALUES (value_list) [, (value_list)] ... value_list: value, [, value] ...- 1
- 2
- 3
- 4
单行数据 + 全列插入
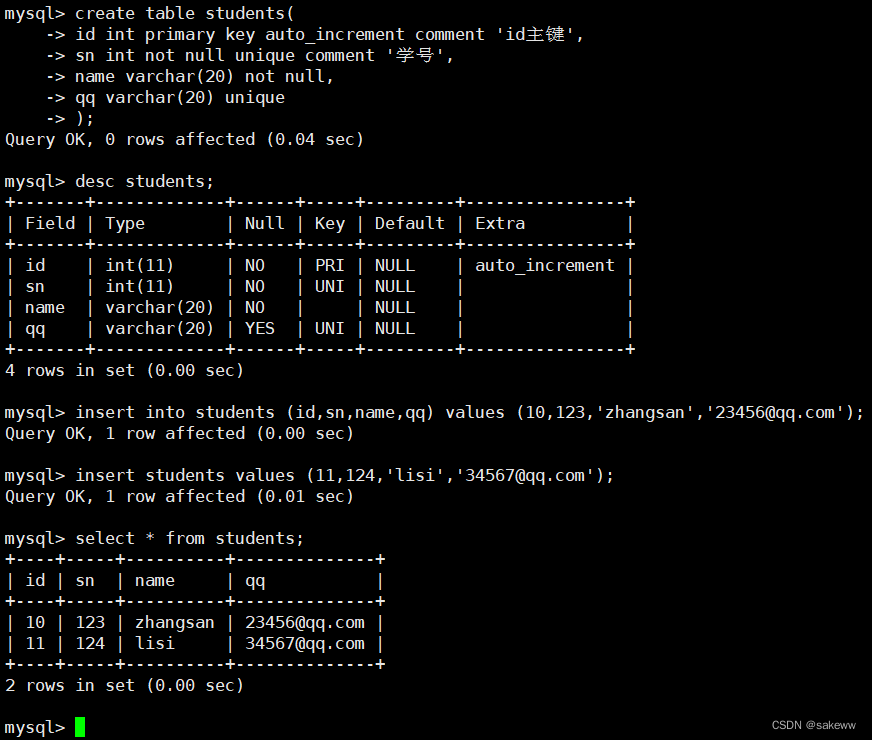
多行数据 + 指定列插入
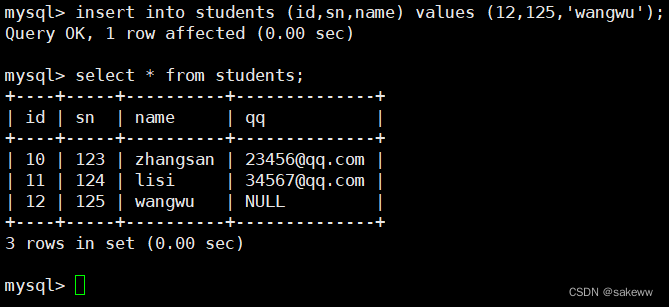

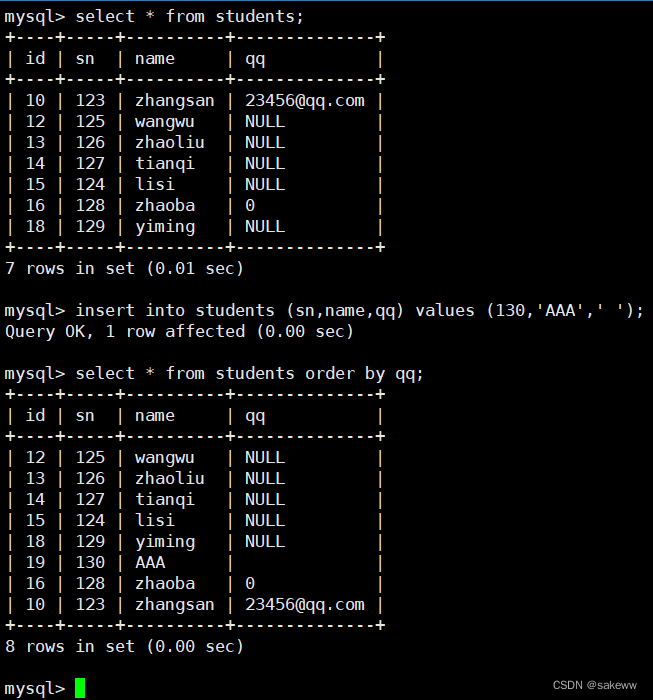
6.1.3 插入否则更新–on duplicate key update
INSERT ... ON DUPLICATE KEY UPDATE column = value [, column = value] ...- 1
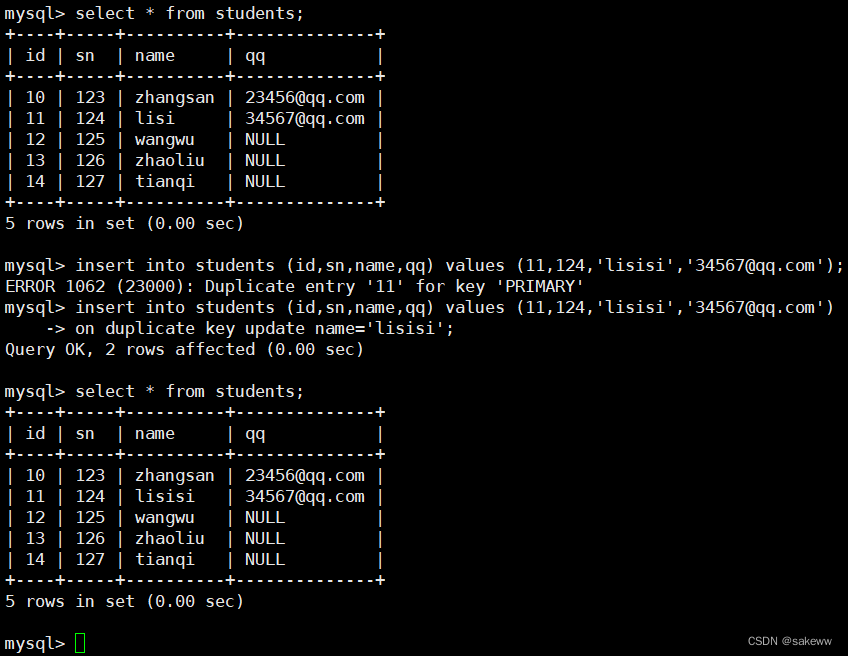
替换

Retrieve(读取)
SELECT [DISTINCT] {* | {column [, column] ...} [FROM table_name] [WHERE ...] [ORDER BY column [ASC | DESC], ...] LIMIT ...- 1
- 2
- 3
- 4
- 5
- 6
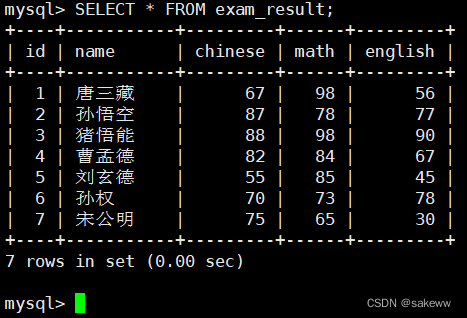
准备工作
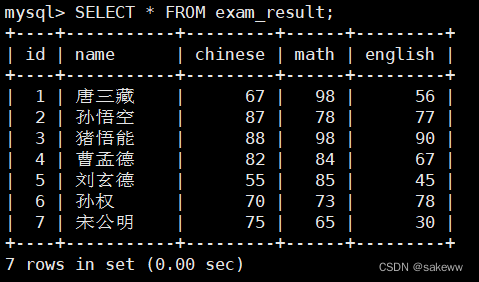
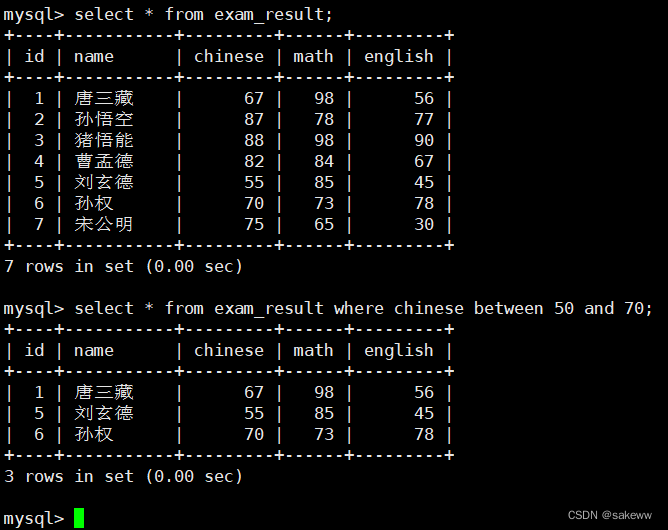
CREATE TABLE exam_result ( id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT, name VARCHAR(20) NOT NULL COMMENT '同学姓名', chinese float DEFAULT 0.0 COMMENT '语文成绩', math float DEFAULT 0.0 COMMENT '数学成绩', english float DEFAULT 0.0 COMMENT '英语成绩' ); INSERT INTO exam_result (name, chinese, math, english) VALUES ('唐三藏', 67, 98, 56), ('孙悟空', 87, 78, 77), ('猪悟能', 88, 98, 90), ('曹孟德', 82, 84, 67), ('刘玄德', 55, 85, 45), ('孙权', 70, 73, 78), ('宋公明', 75, 65, 30);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
列
全列查询
指定列查询
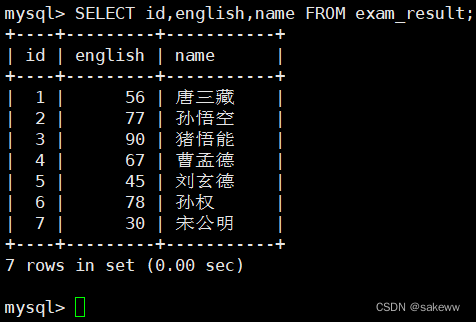
查询字段为表达式

表达式包含多个字段

为查询结果指定别名 空格
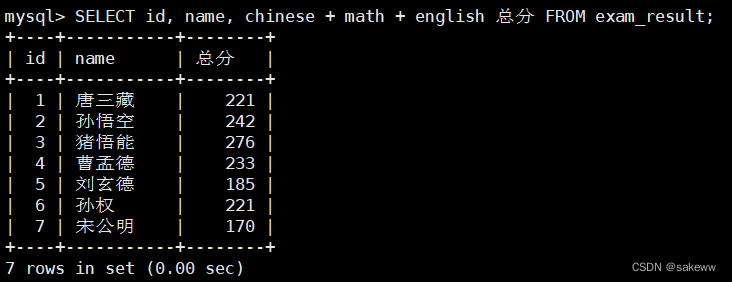
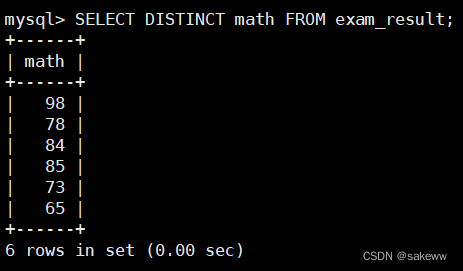
结果去重–distinct
排序 order by 列 默认(asc升序)/desc(降序)
如果你的数据本身就是有序的,那么查询是也是需要有排序的
因为:返回的顺序是未定义的,别人可能会修改你的数据

where
简单运算符比较
运算符 说明
>, >=, <, <= 大于,大于等于,小于,小于等于
= 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL
<=> 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1)
!=, <> 不等于
BETWEEN a0 AND a1 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1)
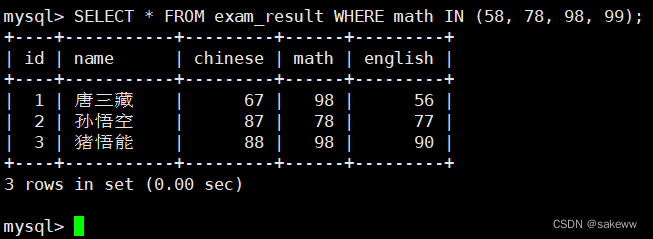
IN (option, …) 如果是 option 中的任意一个,返回 TRUE(1)
IS NULL 是 NULL
IS NOT NULL 不是 NULL
LIKE 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符AND 多个条件必须都为 TRUE(1),结果才是 TRUE(1)
OR 任意一个条件为 TRUE(1), 结果为 TRUE(1)
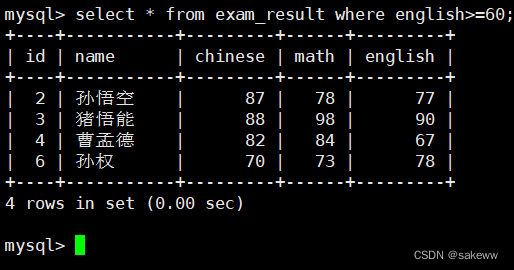
NOT 条件为 TRUE(1),结果为 FALSE(0)英语成绩及格的
= and <=>

= <=> != <>
<=>不建议使用,建议使用 IS NULL和IS NOT NULL
BETWEEN a0 AND a1
[a0,a1]
IN
LIKE

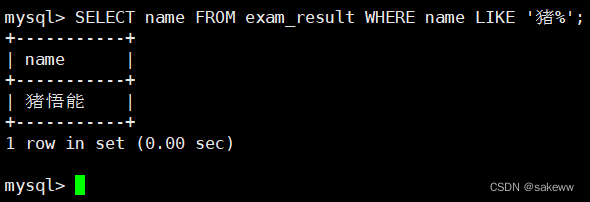
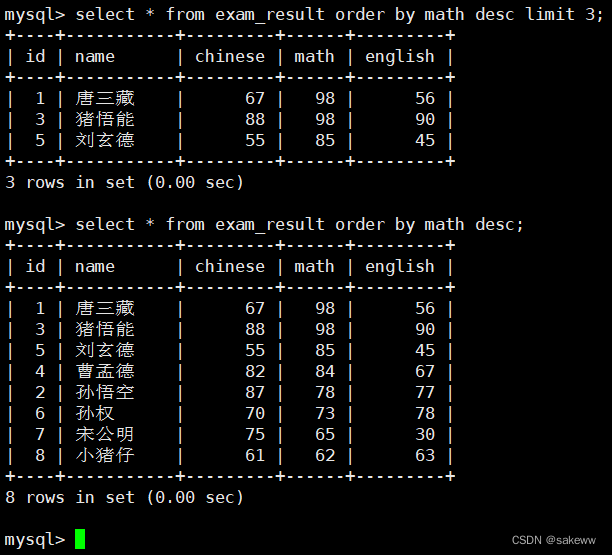
筛选分页结果 limit 数字 offset 数字/limit 数字,数字
limit永远在最后的未知
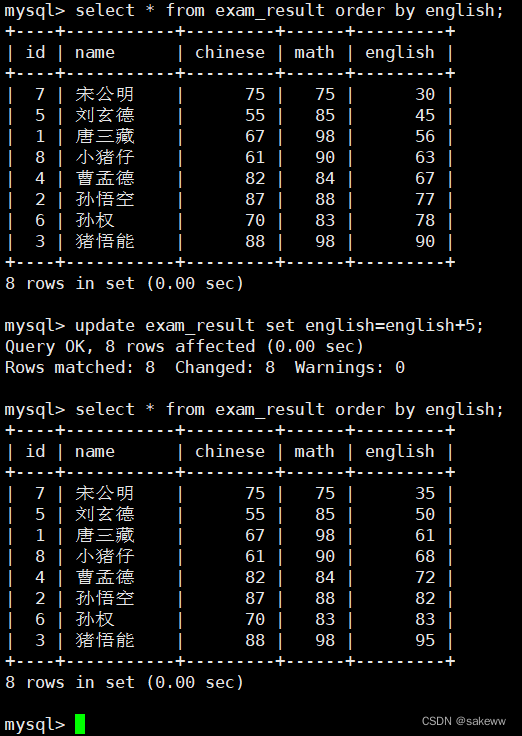
Update(更新)
UPDATE table_name SET column = expr [, column = expr ...] [WHERE ...] [ORDER BY ...] [LIMIT ...]- 1
- 2
更新一列一个数据
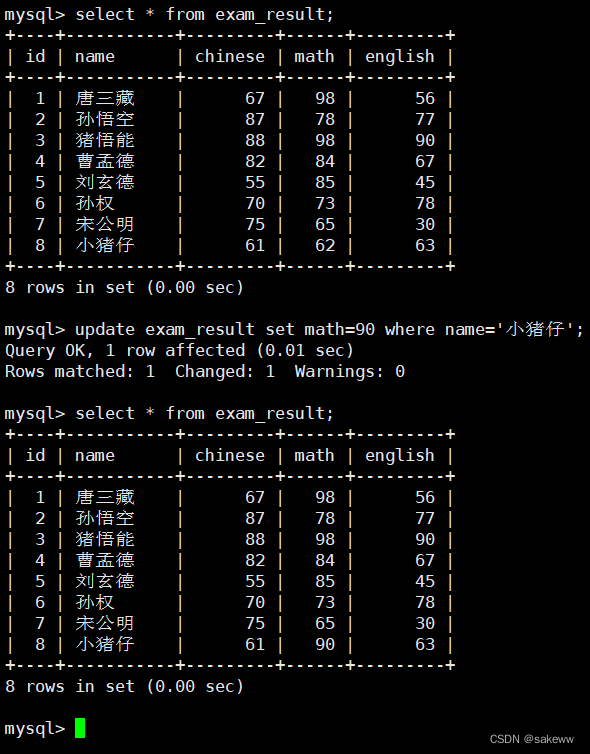
更改一列多个数据

更新全列
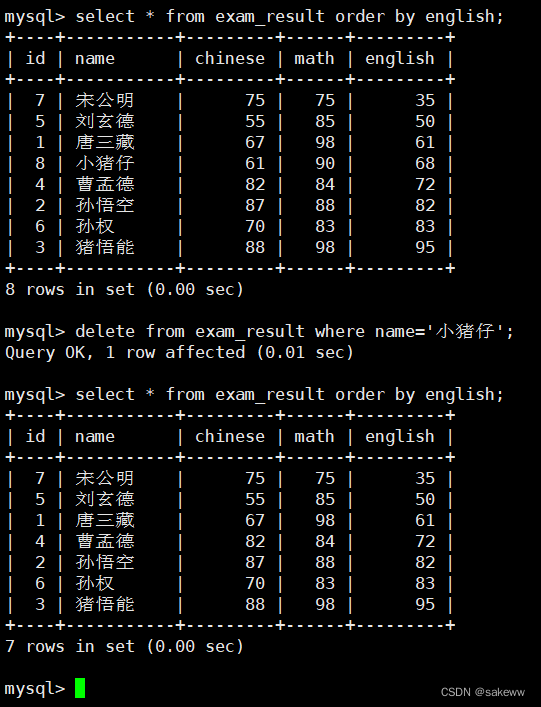
Delete(删除)
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]- 1
删除某一行数据
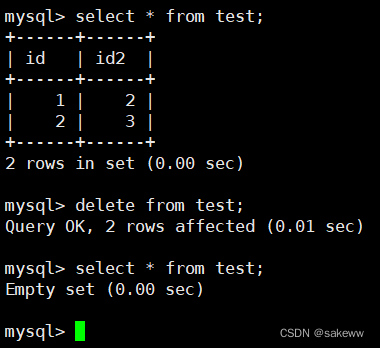
删除整张表的数据
职业素养:
别人让你删除表
先备份(给表起个别名,然后保存)
然后输出表的数据TRUNCATE

delete vs truncate(了解)
日志:承担很大的功能要求
- bin log:几乎所有的sql操作,MySQL服务器都会给我们记录下来!用来进行多主机同步增量备份
- redo log:MySQL持久化和crash-safe(崩溃)功能
- undo log:在事物中承担回滚的日志,数据操作恢复功能
delete会更新bin
truncate不更新bin插入查询结果
删除表内重复数据

聚合函数
COUNT([DISTINCT] expr) 返回查询到的数据的 数量。NULL不计入总数 ,‘ ’计入总数
SUM([DISTINCT] expr) 返回查询到的数据的 总和,不是数字没有意义
AVG([DISTINCT] expr) 返回查询到的数据的 平均值,不是数字没有意义
MAX([DISTINCT] expr) 返回查询到的数据的 最大值,不是数字没有意义
MIN([DISTINCT] expr) 返回查询到的数据的 最小值,不是数字没有意义聚合函数不能和特定函数放在一起,容易出错的
但是因为一些版本的原因,有些会直接报错,有些则会错误输出group by
select column1, column2, .. from table group by column;- 1
将外界数据库导入本地–数据恢复

实战训练
准备工作
EMP员工表
DEPT部门表
SALGRADE工资等级表
相关查询
如何显示每个部门的平均工资和最高工资

显示每个部门的每种岗位的平均工资和最低工资
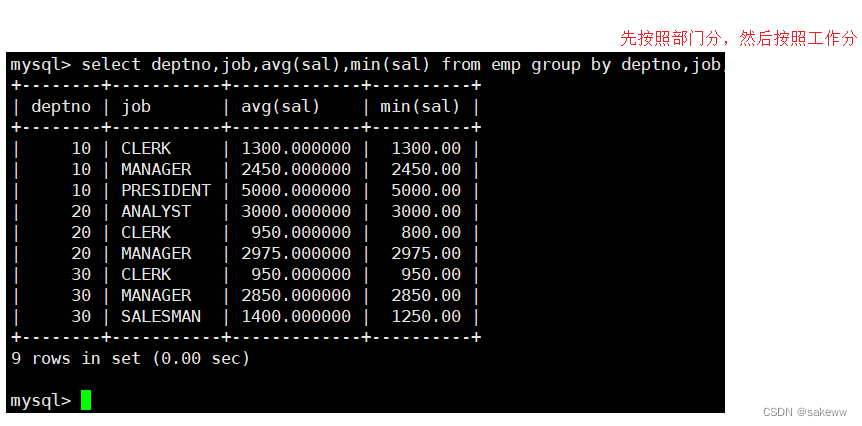
group by先对数据进行分组显示平均工资低于2000的部门和它的平均工资
having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where
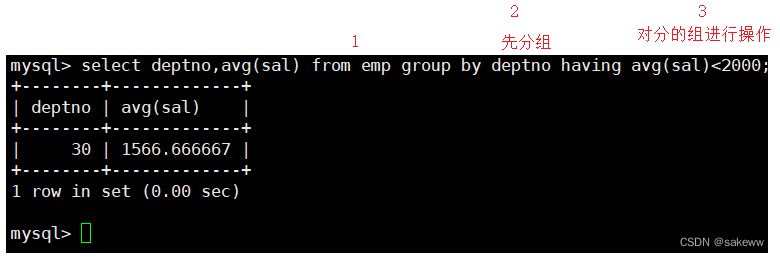
where vs having
两者的执行位置,次序时不同的!
where:过滤表中数据
having:过滤分组数据 -
相关阅读:
Redis之主从复制
Python代码部署的三种加密方案:代码混淆、代码编译、代码打包
Mining Association Rules between Sets of Items in Large Databases
电动机保护器的作用
【错误记录】Navigation 导航组件报错 ( Activity xxActivity@3f does not have a NavController set on 2131xx )
SpringBoot配置全局异常处理
提升80%上云集成效率, TA是如何做到的
@Configuration详解
CodeTON Round 3 (Div. 1 + Div. 2, Rated, Prizes!) A~D 题解
运行mbedtls自带Demo ssl_client的记录
- 原文地址:https://blog.csdn.net/sakeww/article/details/126256547
