-
yolov7训练自定义数据集时的注意事项
慢慢记录吧
yolov7的数据集格式和yolov5是一样的,基本上直接将yolov5的数据集拿过来用即可
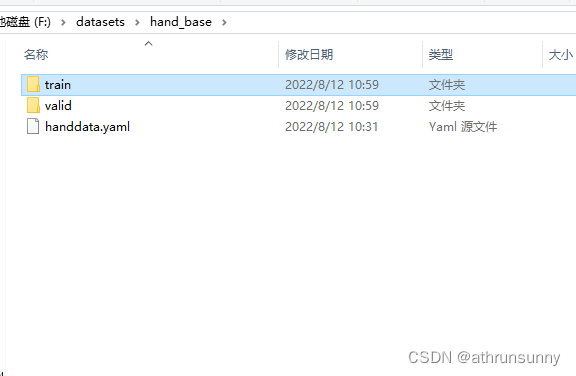
文件层级:
├—data │ ├—train │ │ ├—images │ │ │ ├—000000000001.jpg │ │ │ ├—000000000002.jpg │ │ ├—labels │ │ │ ├—000000000001.txt │ │ │ ├—000000000002.txt │ ├—valid │ │ ├—images │ │ ├—labels
区别就在yaml文件上,
yolov5的文件格式:

yolov7的文件格式:
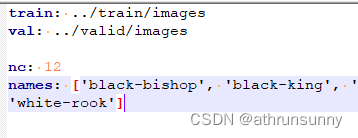
区别就是没了path,主要是有些数据比较大,不想移来移去,所以直接修改v7的代码
主要修改的是yolov7\utils\general.py
将以下代码加入check_dataset函数即可:
- FILE = Path(__file__).resolve()
- ROOT = FILE.parents[1]
- path = Path(dict.get('path') or '')
- if not path.is_absolute():
- path = (ROOT / path).resolve()
- for k in 'train', 'val', 'test':
- if dict.get(k): # prepend path
- dict[k] = str(path / dict[k]) if isinstance(dict[k], str) else [str(path / x) for x in dict[k]]
- def check_dataset(dict):
- FILE = Path(__file__).resolve()
- ROOT = FILE.parents[1]
- path = Path(dict.get('path') or '')
- if not path.is_absolute():
- path = (ROOT / path).resolve()
- for k in 'train', 'val', 'test':
- if dict.get(k): # prepend path
- dict[k] = str(path / dict[k]) if isinstance(dict[k], str) else [str(path / x) for x in dict[k]]
- # Download dataset if not found locally
- val, s = dict.get('val'), dict.get('download')
- if val and len(val):
- val = [Path(x).resolve() for x in (val if isinstance(val, list) else [val])] # val path
- if not all(x.exists() for x in val):
- print('\nWARNING: Dataset not found, nonexistent paths: %s' % [str(x) for x in val if not x.exists()])
- if s and len(s): # download script
- print('Downloading %s ...' % s)
- if s.startswith('http') and s.endswith('.zip'): # URL
- f = Path(s).name # filename
- torch.hub.download_url_to_file(s, f)
- r = os.system('unzip -q %s -d ../ && rm %s' % (f, f)) # unzip
- else: # bash script
- r = os.system(s)
- print('Dataset autodownload %s\n' % ('success' if r == 0 else 'failure')) # analyze return value
- else:
- raise Exception('Dataset not found.')
这样就只需要在配置文件中改数据集路径即可。
还有点需要注意就是用yolov5训练后的cache文件,在训练yolov7时要删除,不然会报_pickle.UnpicklingError: STACK_GLOBAL requires str
-
相关阅读:
RocketMq5 消息消费及相关源码浅阅
.NET开源、跨平台的本地日记APP - SwashbucklerDiary
网格切割算法
第8天:Django Admin高级配置
【已解决】EOFError: Ran out of input
Linux内核顶层Makefile的make过程说明二
27-Openwrt rtc htpdate system
软件数据采集使用代理IP的好处用哪些?
DicomObjects COM 8.XX.1102.0: 2022-10-18
通过Python pypdf库轻松拆分大型PDF文件
- 原文地址:https://blog.csdn.net/athrunsunny/article/details/126307321
