-
C语言-入门-语法-结构体(十三)
为什么要有结构体?
因为在实际问题中,一组数据往往有很多种不同的数据类型。例如,登记学生的信息,可能需要用到 char型的姓名,int型或 char型的学号,int型的年龄,char型的性别,float型的成绩。又例如,对于记录一本书,需要 char型的书名,char型的作者名,float型的价格。在这些情况下,使用简单的基本数据类型甚至是数组都是很困难的。而结构体(类似Pascal中的“记录”),则可以有效的解决这个问题。
结构体本质上还是一种数据类型,但它可以包括若干个“成员”,每个成员的类型可以相同也可以不同,也可以是基本数据类型或者又是一个构造类型。
结构体的优点:结构体不仅可以记录不同类型的数据,而且使得数据结构是“高内聚,低耦合”的,更利于程序的阅读理解和移植,而且结构体的存储方式可以提高CPU对内存的访问速度。
定义结构体
结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量,当我们面对的事物有多个不同的数据类型的时候,我们就可以使用结构体来组织了。比如说,一本书有书名、作者、售价、出版日期等等不同的数据类型,这时候我们可以创建结构体来包含书的不同数据类型。而结构体声明是描述结构体组合的主要方法,语法格式为:
struct 结构体名称{ 结构体成员1; 结构体成员2; 结构体成员3; … };//分号不能丢- 1
- 2
- 3
- 4
- 5
- 6
列:
struct Student { char *name; // 姓名 int age; // 年龄 float height; // 身高 };- 1
- 2
- 3
- 4
- 5
结构体成员既可以是任何一种基本的数据类型,也可以是另一种结构体,如果是后者就相当于结构体的嵌套。(俗称套娃)
结构成员的类型可以是标量、数组、指针、甚至是其他结构体。定义结构体变量
结构体的声明只是进行一个简单的描述,实际上在没有定义结构体类型变量之前,它是不会在内存中分配空间的。也就是说,它还没有被真正使用,虚拟存在,只有定义了结构体类型变量,才真实存在。
格式:struct 结构体名 结构体变量名;

先定义结构体类型,再定义变量
//定义结构体 struct Student { char *name; int age; }; //定义结构体变量 struct Student stu;- 1
- 2
- 3
- 4
- 5
- 6
- 7
定义结构体类型的同时定义变量
struct Student { char *name; int age; } stu;- 1
- 2
- 3
- 4
匿名结构体定义结构体变量
第三种方法与第二种方法的区别在于,第三种方法中省去了结构体类型名称,而直接给出结构变量,这种结构体最大的问题是结构体类型不能复用
struct { char *name; int age; } stu;- 1
- 2
- 3
- 4
结构体成员访问
一般对结构体变量的操作是以成员为单位进行的,引用的一般形式为:
结构体变量名.成员名struct Student { char *name; int age; }; struct Student stu; // 访问stu的age成员 stu.age = 27; //赋值 //获取和打印 printf("age = %d", stu.age);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
结构体变量的初始化
定义的同时按顺序初始化
无须指定变量的名称,只需要按照结构体变量的顺序进行赋值就行了
struct Student { char *name; int age; }; //初始化 struct Student stu = {"lnj", 27};- 1
- 2
- 3
- 4
- 5
- 6
定义的同时不按顺序初始化
如果不按照顺序的话, 需要指定变量的名称
struct Student { char *name; int age; }; struct Student stu = {.age=27,.name="lnj"};- 1
- 2
- 3
- 4
先定义后逐个初始化
struct Student { char *name; int age; }; struct Student stu; stu.name = "lnj"; stu.age = 35;- 1
- 2
- 3
- 4
- 5
- 6
先定义后一次性初始化
struct Student { char *name; int age; }; struct Student stu; stu2 = (struct Student){"lnj", 35};- 1
- 2
- 3
- 4
- 5
- 6
定义结构体类型的同时定义变量同时初始化
struct Student{ //声明结构体 Student char name[20]; int num; float score; }stu = {"Mike", 15, 91}; //注意初始化值的类型和顺序要与结构体声明时成员的类型和顺序一致- 1
- 2
- 3
- 4
- 5
结构体类型作用域
① 定义在函数外面:全局有效(从定义类型的那行开始,一直到文件结尾)
② 定义在函数(代码块)内部:局部有效(从定义类型的那行开始,一直到代码块结束)//定义一个全局结构体,作用域到文件末尾 struct Person{ int age; char *name; }; void test() { //使用全局的结构体定义结构体变量 struct Person p = {10,"sb"}; printf("%d,%s\n",p.age,p.name); } int main() { //定义局部结构体名为Person,会屏蔽全局同名结构体 //局部结构体作用域,从定义开始到“}”块结束 struct Person{ int age; char *name; }; // 使用局部结构体类型 struct Person pp; pp.age = 50; pp.name = "zbz"; test(); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
结构体数组
结构体数组和普通数组并无太大差异, 只不过是数组中的元素都是结构体而已
格式:struct 结构体类型名称 数组名称[元素个数]struct Student { char *name; int age; }; struct Student stu[2];- 1
- 2
- 3
- 4
- 5
结构体数组初始化和普通数组也一样, 分为先定义后初始化和定义同时初始化
定义同时初始化
struct Student { char *name; int age; }; struct Student stu[2] = {{"lnj", 35},{"zs", 18}};- 1
- 2
- 3
- 4
- 5
先定义后初始化
struct Student { char *name; int age; }; struct Student stu[2]; stu[0] = (struct Student){"lnj", 35}; stu[1] = (struct Student){"zs", 18};- 1
- 2
- 3
- 4
- 5
- 6
- 7
或者将结构体变量的成员逐个赋值
struct Student { char *name; int age; }; struct Student stu[2]; stu[0].name="Smith"; stu[0].age = 18;- 1
- 2
- 3
- 4
- 5
- 6
- 7
结构体指针
一个指针变量当用来指向一个结构体变量时,称之为结构体指针变量,格式:
struct 结构名 *结构指针变量名// 定义一个结构体类型 struct Student { char *name; int age; }; // 定义一个结构体变量 struct Student stu = {"lnj", 18}; // 定义一个指向结构体的指针变量 struct Student *p; // 指向结构体变量stu p = &stu; /*这时候可以用3种方式访问结构体的成员 */ // 方式1:结构体变量名.成员名 printf("name=%s, age = %d \n", stu.name, stu.age); // 方式2:(*指针变量名).成员名 printf("name=%s, age = %d \n", (*p).name, (*p).age); // 方式3:指针变量名->成员名 printf("name=%s, age = %d \n", p->name, p->age);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
通过结构体指针访问结构体成员, 可以通过以下两种方式
(*结构指针变量).成员名括号不可少,因为成员符“.”的优先级高于“*”结构指针变量->成员名
结构体和函数
- 结构体虽然是构造类型, 但是结构体之间赋值是值拷贝, 而不是地址传递
- 所以结构体变量作为函数形参时也是值传递, 在函数内修改形参, 不会影响外界实参
struct Person { char *name; int age; }; void setPerson(struct Person per){ per.name = "zs"; } int main() { struct Person p1 = {"lnj", 35}; printf("p1.name = %s\n", p1.name); // lnj setPerson(p1); printf("p1.name = %s\n", p1.name); // lnj return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
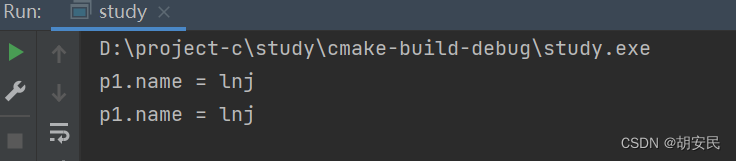
如果想要将结构体地址传递传入,我们可以使用参数指针struct Person { char *name; int age; }; void setPerson(struct Person *per){ per->name = "zs"; } int main() { struct Person p1 = {"lnj", 35}; printf("p1.name = %s\n", p1.name); // lnj setPerson(&p1); printf("p1.name = %s\n", p1.name); // lnj return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

结构体内存优化
为什么要有字节对齐
有些CPU可以访问任意地址上的任意数据,而有些CPU只能在特定地址访问数据,因此不同硬件平台具有差异性,这样的代码就不具有移植性,如果在编译时,将分配的内存进行对齐,这就具有平台可以移植性了
CPU每次寻址都是要消费时间的,并且CPU 访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问,所以数据结构应该尽可能地在自然边界上对齐,如果访问未对齐的内存,处理器需要做两次内存访问,而对齐的内存访问仅需要一次访问,内存对齐后可以提升性能。举个例子:
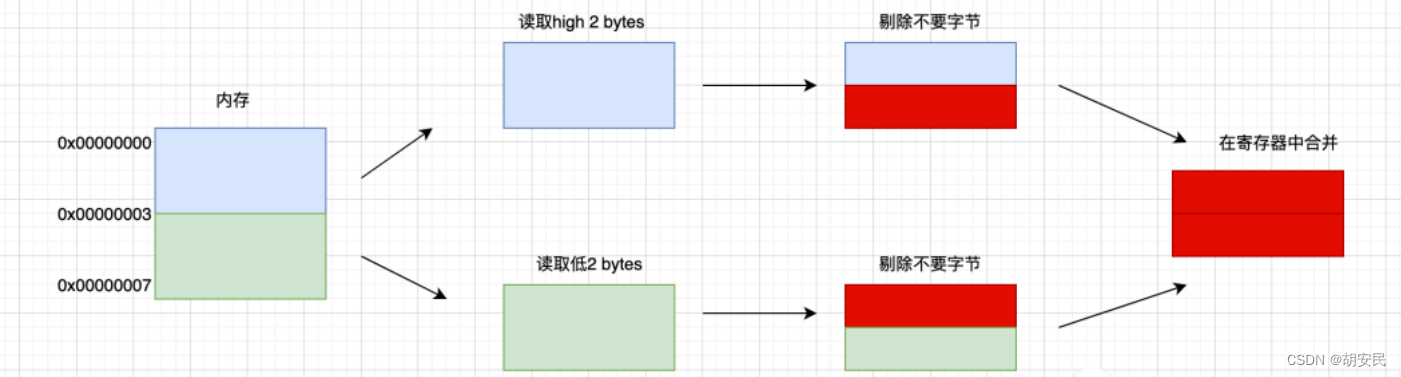
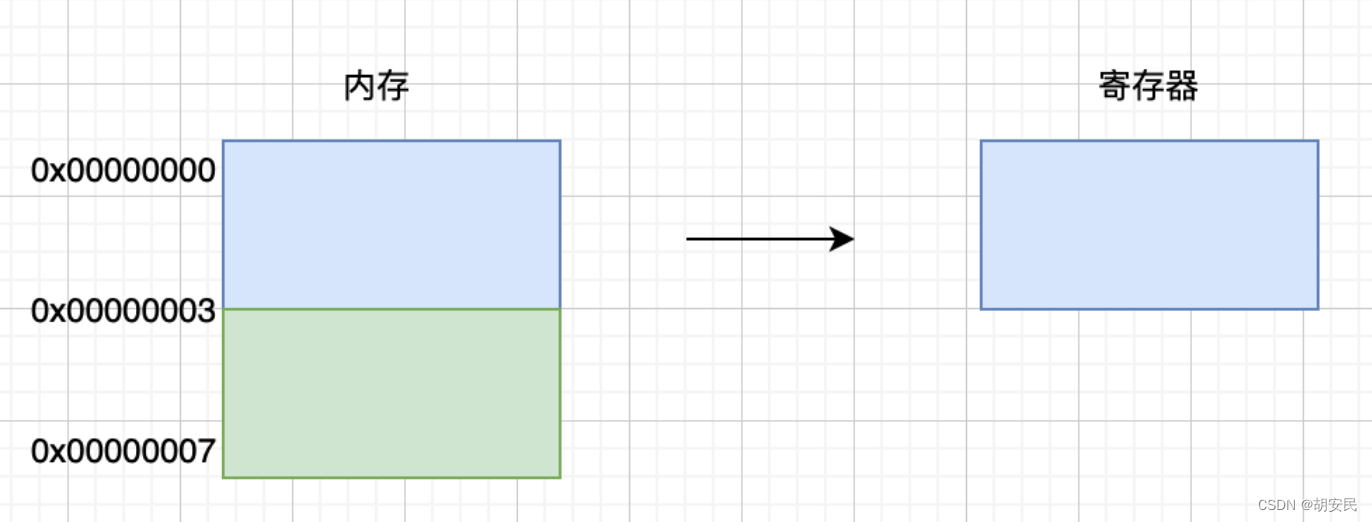
假设当前CPU是32位的,并且没有内存对齐机制,数据可以任意存放,现在有一个int32变量占4byte,存放地址在[0x00000002 - 0x00000005],这种情况下,每次取4字节的CPU第一次取到[0x00000000 - 0x00000003],只得到变量1/2的数据,所以还需要取第二次,为了得到一个int32类型的变量,需要访问两次内存并做拼接处理,影响性能。如果有内存对齐了,int32类型数据就会按照对齐规则在内存中,上面这个例子就会存在地址0x00000000处开始,那么处理器在取数据时一次性就能将数据读出来了,而且不需要做额外的操作,使用空间换时间,提高了效率。没有内存对齐机制(二次取完):
内存对齐后(一次取完):
对齐系数
每个特定平台上的编译器都有自己的默认"对齐系数",常用平台默认对齐系数如下:- 32位系统对齐系数是4
- 64位系统对齐系数是8
注意:不同硬件平台占用的大小和对齐值都可能是不一样的。实际上对齐系数我们是可以修改的,可以通过预编译指令#pragma pack(n)来修改对齐系数
结构体的内存对齐规则
提到内存对齐,大家都喜欢拿结构体的内存对齐来举例子,这里要提醒大家一下,不要混淆了一个概念,其他类型也都是要内存对齐的,只不过拿结构体来举例子能更好的理解内存对齐,并且结构体中的成员变量对齐有自己的规则,我们需要搞清这个对齐规则。
struct Student { char a; //1 int b; //4 }- 1
- 2
- 3
- 4
1+4=5 需要对齐8的倍数 (8)
struct Student { char a; //1 int b; //4 double c;//8- 1
- 2
- 3
- 4
1+4+8=13 <16 需要对齐8的倍数 (16)
struct Student { int a; //4 int b; //4 double c;//8 char *d;//8- 1
- 2
- 3
- 4
- 5
4+4+8+8=24 满足8的倍数无须对齐
嵌套结构体
struct Student { int a; //4 int b; //4 double c;//8 char *d;//8 //24 struct { //16 int q; //4 int u; //4 double i; //8 } str; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
4+4+8+8+4+4+8=40 满足8的倍数无须对齐
计算含有数组的结构体大小,需要注意的是,如果下一个成员是数组,则不需要对象,只要连续开辟空间。
struct Student { //44 int a; //4 int d[10]; // 10*4=40 };- 1
- 2
- 3
- 4
4 +40=44
编译器为了满足内存对齐要求,会在各个数据成员之间留下额外的内存空间,这会造成很小的浪费。有些时候但是这种浪费是可以容忍的,但是如果是面向硬件开发而且内存很紧缺,我们就需要计算好结构体的大小,避免造成自动对齐导致的浪费内存空间
共用体
结构体和共用体的区别在于:结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,允许您在相同的内存位置存储不同的数据类型,修改一个成员会影响其余所有成员(其他成员的值会被覆盖)。
共用体占用的内存等于最大的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。
想了想发现没啥场景需要用到共用体的呢? 那么共用体到底干啥的呢, 主要用在资源有限的硬件系统,比如嵌入式,单片机等。 想想如果想使在程序用多种类型,那么是需要用多个内存空间,如果使用共用体只需要一个内存空间可以让不同类型共享,这样就节省了很多的内存了
定义共用体类型格式:
union 共用体名{ 数据类型 属性名称; 数据类型 属性名称; ... .... };- 1
- 2
- 3
- 4
- 5
定义共用体类型变量格式:
union 共用体名 共用体变量名称;- 1
使用演示
union Test{ int age;//4 char ch;//1 double t;//8 int t1[10];//80 }; union Test t; printf("sizeof(p) = %llu\n", sizeof(t));//80 t.age = 33; printf("t.age = %i\n", t.age); // 33 t.ch = 'a'; printf("t.ch = %c\n", t.ch); // a printf("t.age = %i\n", t.age); // 97 printf("t.age = %f\n", t.t); // 0.000000 printf("t.age = %d\n", *t.t1); // 97- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

点赞 -收藏-关注-便于以后复习和收到最新内容 有其他问题在评论区讨论-或者私信我-收到会在第一时间回复 在本博客学习的技术不得以任何方式直接或者间接的从事违反中华人民共和国法律,内容仅供学习、交流与参考 免责声明:本文部分素材来源于网络,版权归原创者所有,如存在文章/图片/音视频等使用不当的情况,请随时私信联系我、以迅速采取适当措施,避免给双方造成不必要的经济损失。 感谢,配合,希望我的努力对你有帮助^_^ -
相关阅读:
225页10万字政务大数据能力平台项目建议书
【户外】东莞-银瓶山-常规路线-登山游记+攻略
【WebRTC】【Unity】局域网UDP通信为何不通
通过电商项目,详解抓包到接口测试,附图片验证码 +cookie 问题处理!
uniapp AES加密解密
【网关路由测试】——路由表一致性测试
零基础电气专业毕业生,花费9.9元自学前端,成都月薪6.5K
[开源精品] C#.NET im 聊天通讯架构设计 -- FreeIM 支持集群、职责分明、高性能
Spring WebSocket实现实时通信的详细教程
vue3封装弹窗组件实现父子双向绑定
- 原文地址:https://blog.csdn.net/weixin_45203607/article/details/126096525