-
tensor类型、属性、torch.tensor与torch.Tensor的区别
一、tensor(张量)
1. tensor简介
在深度学习中,可以理解为Tensor是一个多维度的矩阵。张量是一个不随参照系的坐标变换(其实就是基向量变化)而变化的东西。
2. 类型
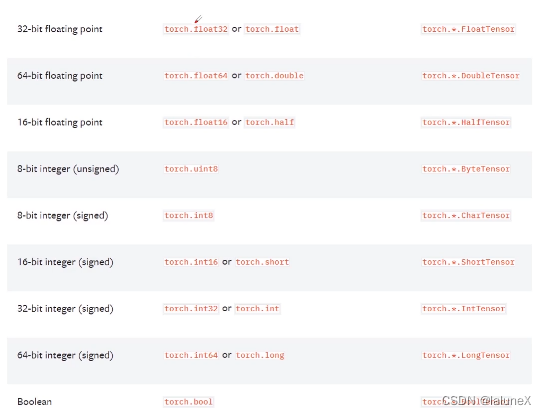
3. 属性
每一个Tensor都有torch.dtype、torch.device、torch.layout
- torch.dtype:数据类型
- torch.device:是指torch.Tensor分配到的设备('cpu’或’cuda’设备类型)的对象
- torch.layout:表示torch.Tensor内存布局的对象,分别是稀疏和密集。要注意的是稀疏化时需要提供元素的索引和值。可用torch.sparse_coo_tensor()和torch.sparse_csr_tensor()来实现
dev = torch.device("cpu") # 使用cpu print(torch.tensor([1, 2], device=dev)) # 将张量放在cpu上 dev = torch.device("cuda:0") # 使用gpu print(torch.tensor([1, 2], device=dev)) # 将张量放在gpu上 # 张量的稀疏化 indexs = torch.tensor([[0, 1, 1], [2, 0, 2]]) # 索引 values = torch.tensor([3, 4, 5], dtype=torch.float32) # 值 x = torch.sparse_coo_tensor(indexs, values, [2, 4]) # 稀疏化 print(x) print(x.to_dense()) # 将稀疏张量转化为稠密张量(含有多个0) # 输出 tensor([1, 2]) # cpu上的张量 tensor([1, 2], device='cuda:0') # gpu上的张量 tensor(indices=tensor([[0, 1, 1], [2, 0, 2]]), values=tensor([3., 4., 5.]), size=(2, 4), nnz=3, layout=torch.sparse_coo) # 稀疏张量的存储 tensor([[0., 0., 3., 0.], # 稀疏转稠密 [4., 0., 5., 0.]])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
4. torch.tensor与torch.Tensor的区别
- torch.Tensor是将输入的data转化torch.FloatTensor,而对于 torch.tensor(当你未指定dtype的类型时) 将依据data类型转化为torch.FloatTensor、torch.LongTensor或torch.DoubleTensor等
- torch.Tensor是torch.empty(会随机产生垃圾数组,详见实例)和torch.tensor之间的一种混合
本文只用于个人学习与记录,侵权立删
-
相关阅读:
腾讯云服务器linux+CentOS7.9+yum源+nginx搭建网站
Anaconda安装及入门教程(Windows、Ubuntu)
哪些 GPTs 应用让我眼前一亮?你又该如何找到它们?
摸鱼也摸鱼之点灯游戏自动求解
【5GC】5G PDU会话以及会话类型
力扣leetcode算法-第一个错误的版本
【Redis】Zset 有序集合内部编码方式
Mysql Explain
【爬虫实战】利用代理爬取电商数据
JS高级 之 事件循环
- 原文地址:https://blog.csdn.net/weixin_45969777/article/details/126286211
