-
【大数据】大数据期末速通 (一)
本文
本文基于厦门大学的大数据技术原理与应用MOOC,推荐时间充足的同学认真学习。
https://www.icourse163.org/course/XMU-1002335004大数据综述
处理架构Hadoop
分布式文件系统HDFS
分布式数据库HBASE
简介
谷歌以前内部大规模网页搜索使用BigTable,HBASE是BigTable的一个开源实现。
HBASE是一个可以用来存储非结构化和半结构化的松散数据的分布式数据库。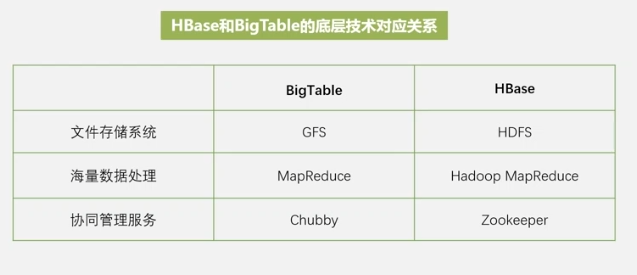
HBASE的诞生意义

传统数据库,当数据量增大时,使用“主从服务器”的方法优化,使读的负载分散到相同内容的从服务器,实现性能扩展。然而无法优化“写”负载。
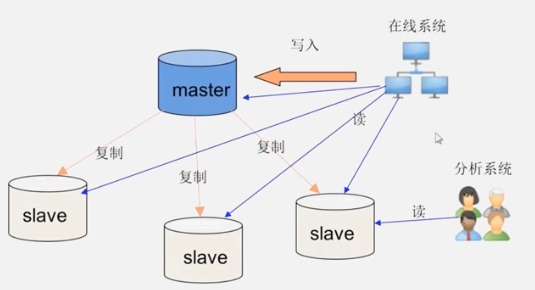
另外的优化方案有- 分库:一个业务部门一个库 (无法从根本解决,仍会不断增加)
- 手动切片,部署到不同服务器(麻烦,要人工操作,效率低)
HBASE与传统数据库的区别

- 数据操作:耗时的连结等操作被HBASE废弃
- 数据索引:只支持对行键的简单索引
- 数据维护:旧版本保留,有时间戳,过期限删除。
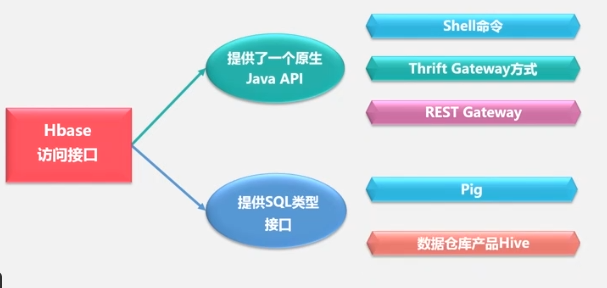
HBASE访问接口:
HBASE的数据模型
稀疏的多维度的排序的映射表
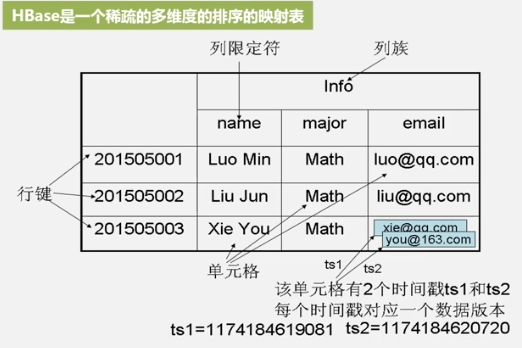
- 通过行键+列族+列限定符+时间戳=某一个具体的数据。
- 每个值都是未经解释的Bytes数组,需要开发者自行解析。
- 一行有一个行键和多个列。
- 列族支持动态扩展,增加减少,支持保留旧版本(HDFS只允许增加,不允许修改)。
- 列限定符支持动态扩展,增加减少。
- 一个单元格保留多个时间戳的数据。
定位一个数据需要4个键

数据概念视图
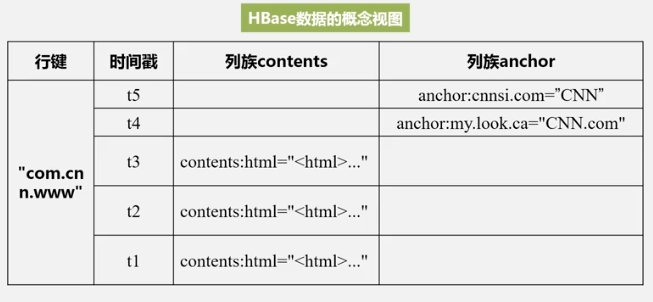
contents为列族,html为列限定符,引号内为值,可以看到,4键确定一个数据 ,且稀疏,这就是为啥称为稀疏的多维度的排序的映射表.数据物理存储视图

可以看出来,HBASE是列式存储。 列式存储优点在于,取数据的时候一般是提取某个属性分析的,如只需要学生的成绩而不需要住址、籍贯等其他列的信息,行式存储就需要取出一行再提取某几个数据,每行都扫码,相当于全部遍历了一遍。
另外,一般一列数据的数据类型是相关的,按列存储可以带来很高的数据压缩率。如何选择存储方式?
若以分析型应用为主,则使用列存储。
若以事务型操作较多,则使用行存储。HBASE的实现原理
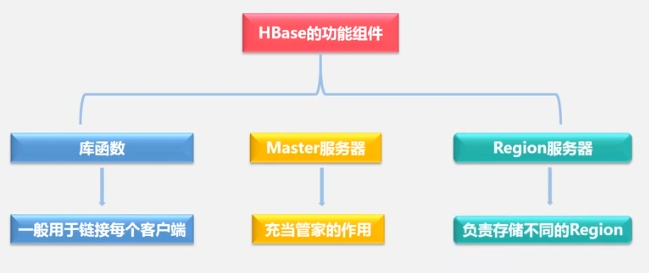
master服务器负责:- 分区信息维护管理
- Region服务器列表维护
- Region服务器哪些在工作,哪些在维护。
- 对表Region分配到哪个region服务器进行分配。
- 负载均衡
Region服务器负责:
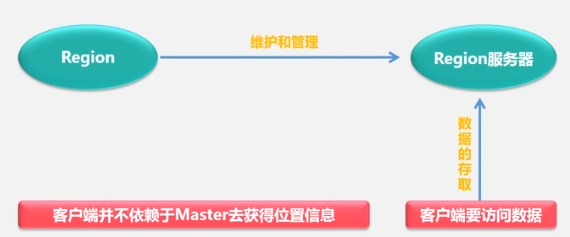
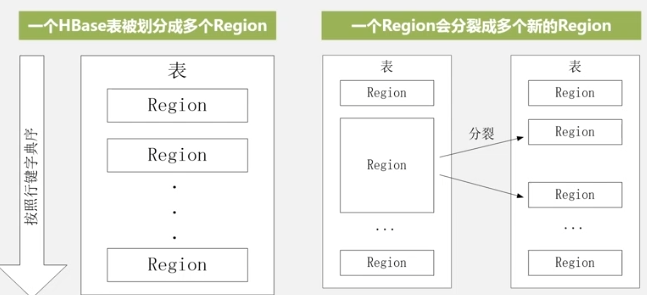
某表刚创建的时候只有一个Region,当某个表的某个Region过大时,进行快速拆分,数据首先指向原地址,当合并结束后生成新文件再指向新地址。不同的Region可能在不同的Region服务器,但同个Region一定在同一个Region服务器。Region的定位

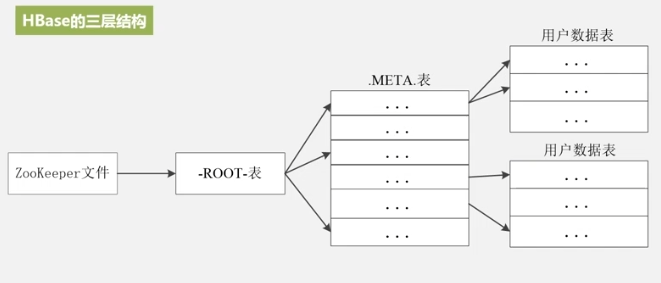
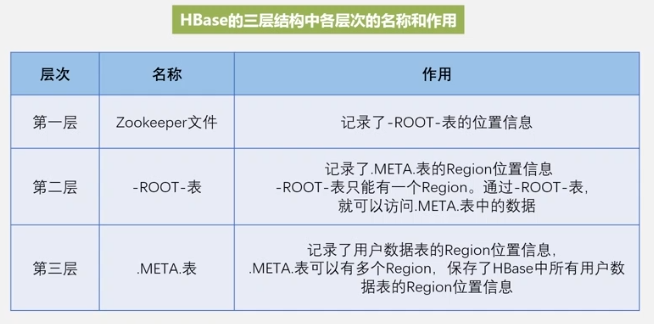
即访问ZooKeeper服务器知道Root表在哪,
查Root表知道Meta表存哪了,
然后查meta表知道数据表存哪了,
这即三层结构。
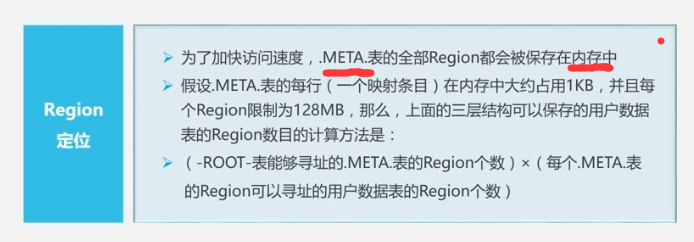
为了加速寻址,客户端会缓存位置信息,同时,出现缓存失效问题,再重新三层寻址。HBASE运行机制
HBASE系统架构
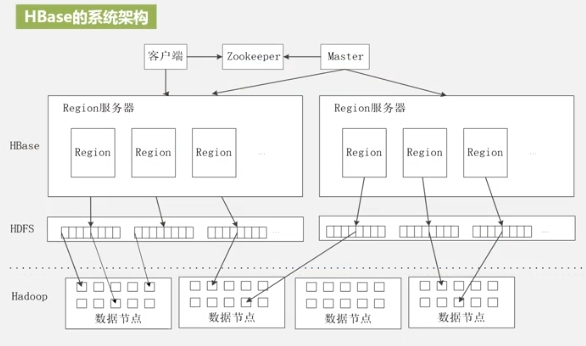
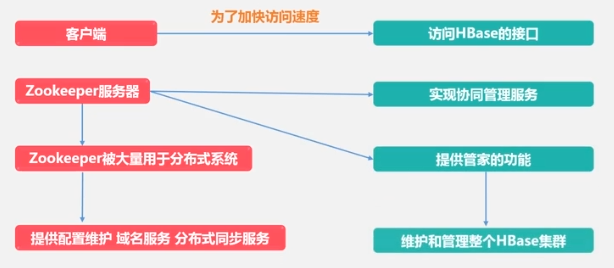
ZooKeeper保证当前只有一个主服务器(Master)运行(可能有多个备用)。
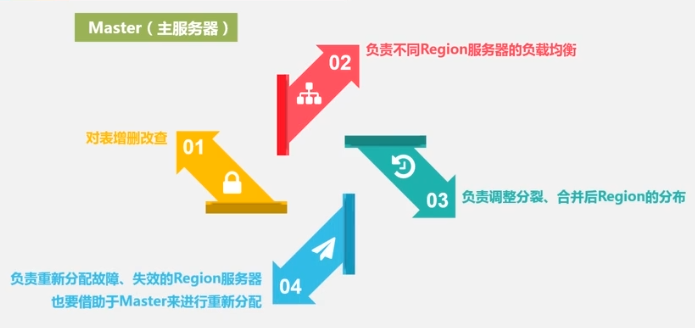
Region服务器工作原理
负责用户数据的存储和管理。
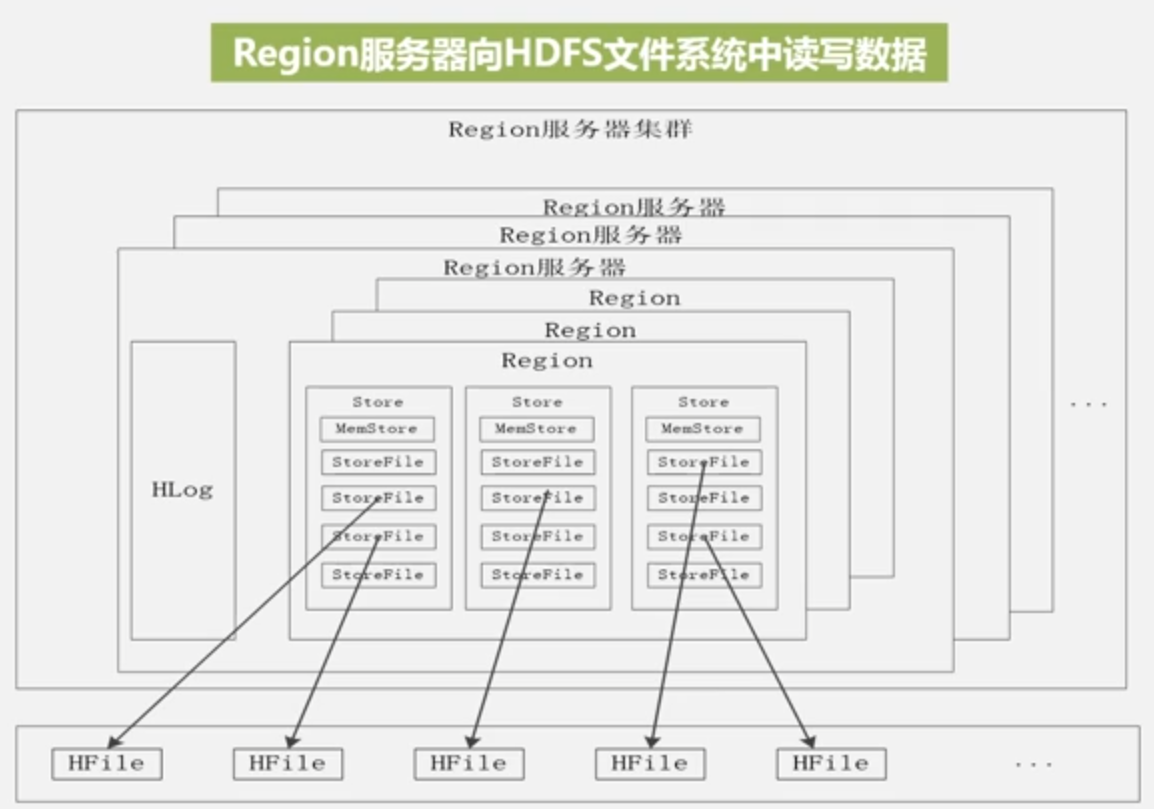
一个Region服务器集群有10-1000个Region服务器
一个Store表示一个列族,Store先写入MemStore,之后周期性写入StoreFile,StoreFile是HDFS的存储格式,使用HFile存储。
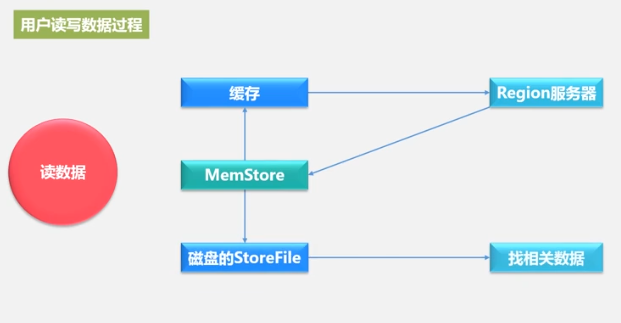
Store工作原理
Store即列族,回顾一下列族的物理存储:
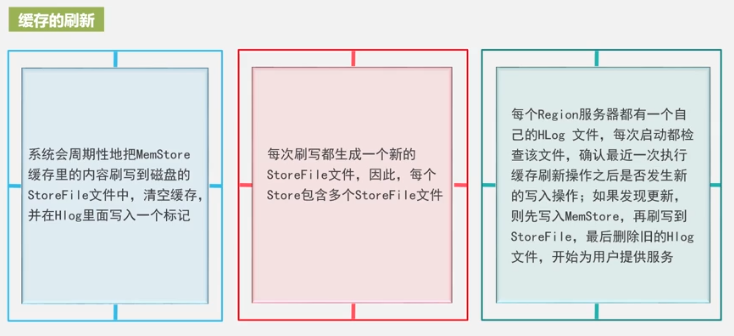
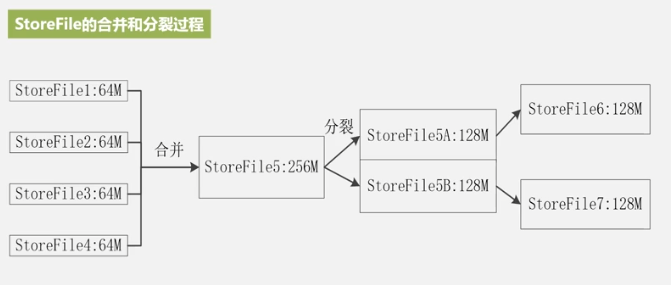
每次都生成新storeFile,文件多了,遍历起来就慢,所以合并,文件大了,于是分裂。这就是StoreFile的合并和分裂,同时也是Region的合并和拆分的原因。
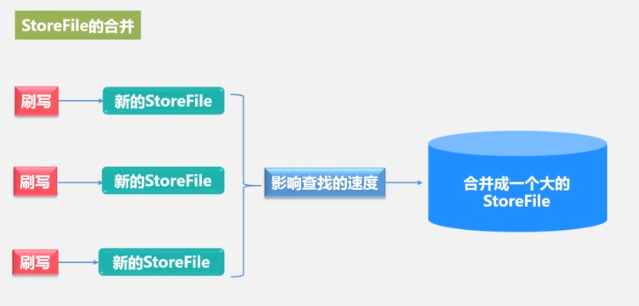
合并很耗资源,一般在StoreFile文件数高于某阈值时才合并。
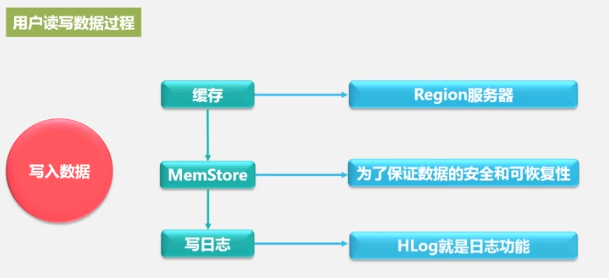
HLog工作原理
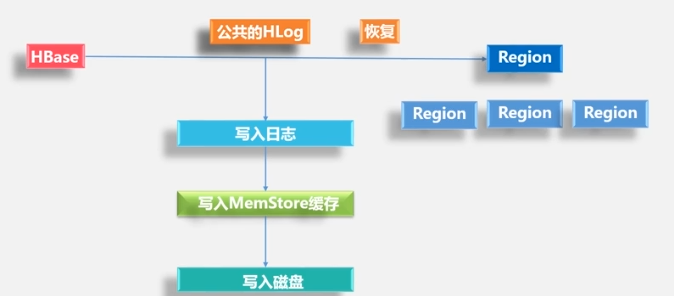
先写入日志,再写MemStore,
一个Region服务器拥有多个Region,一个HLog,一个HLog保证写性能较高。HLog应用方案
性能优化
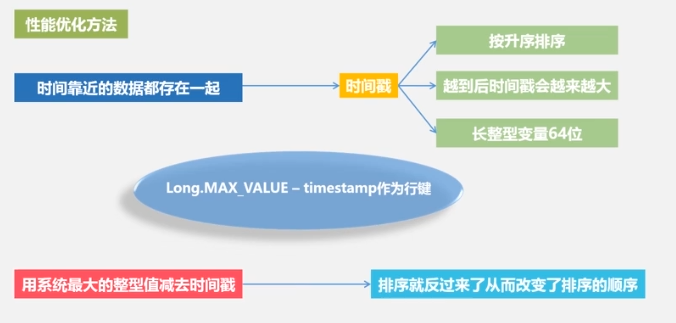
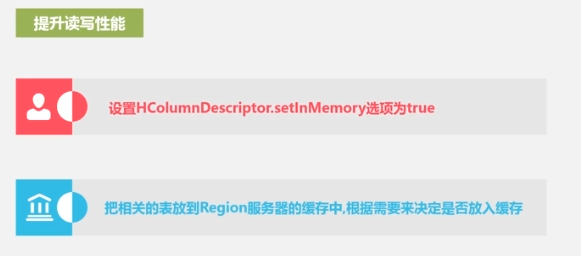
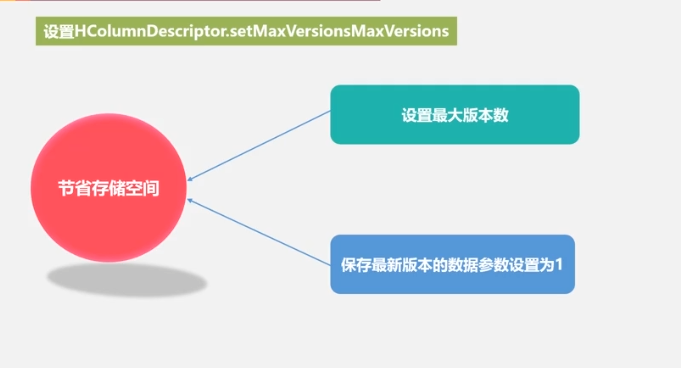
性能检测
可以使用SQL语句对HBase进行数据查询
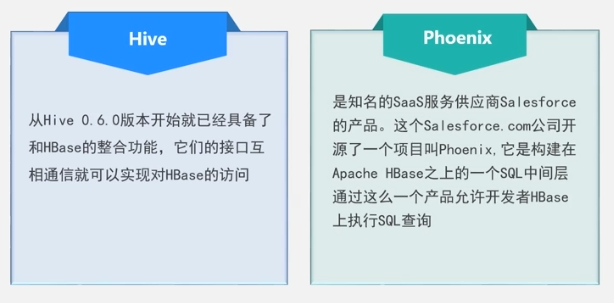
二级索引:
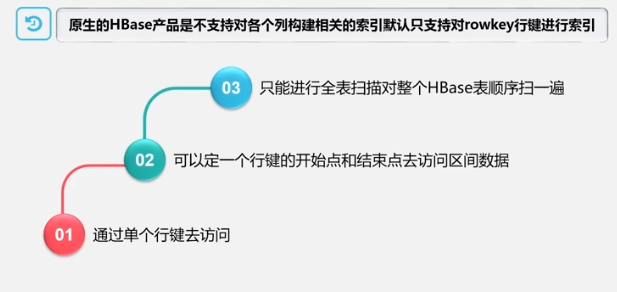
通过索引表进行索引(插入数据时同时插入索引,插两次,性能降低)操作
http://dblab.xmu.edu.cn/blog/2442-2/
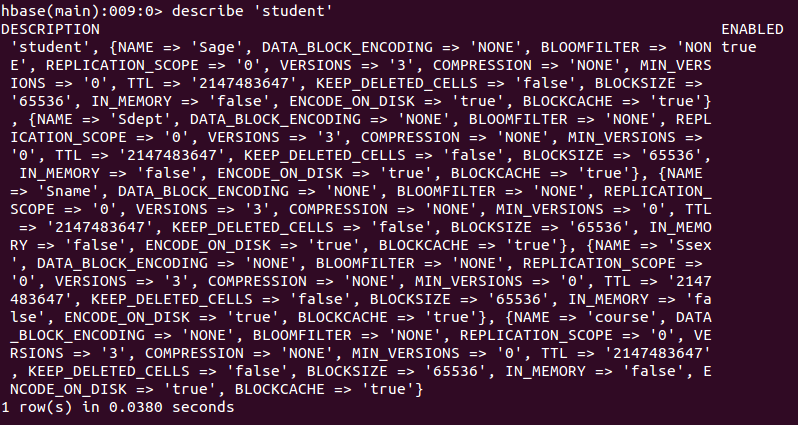
HBase中用create命令创建表,具体如下:create 'student','Sname','Ssex','Sage','Sdept','course'- 1

此时,即创建了一个“student”表,属性有:Sname,Ssex,Sage,Sdept,course。因为HBase的表中会有一个系统默认的属性作为行键,无需自行创建,默认为put命令操作中表名后第一个数据。创建完“student”表后,可通过describe命令查看“student”表的基本信息。
在添加数据时,HBase会自动为添加的数据添加一个时间戳,故在需要修改数据时,只需直接添加数据,HBase即会生成一个新的版本,从而完成“改”操作,旧的版本依旧保留,系统会定时回收垃圾数据,只留下最新的几个版本,保存的版本数可以在创建表的时候指定。- 添加数据
put 'student','95001','Sname','LiYing'- 1
即为student表添加了学号为95001,名字为LiYing的一行数据,其行键为95001。
put 'student','95001','course:math','80'- 1
即为95001行下的course列族的math列添加了一个数据。
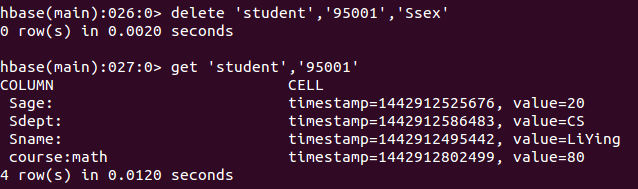
- 删除数据
delete 'student','95001','Ssex'- 1
即删除了student表中95001行下的Ssex列的所有数据。
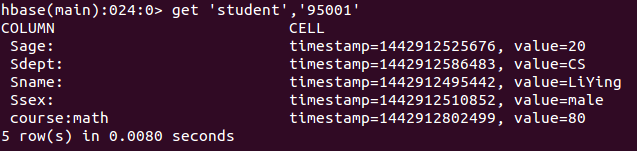
- 查看数据
get 'student','95001'- 1
命令执行截图如下, 返回的是‘student’表‘95001’行的数据。
-
相关阅读:
Bash编程语法
idea创建类报:Unable to parse template “Class“之解决方法
学习笔记-java代码审计-文件操作
spring cloud微服务中多线程下,子线程通过feign调用其它服务,请求头token等丢失
Word处理控件Aspose.Words功能演示:使用 Java 将文本转换为 PDF
javascript二维数组(9)toString的用法
[附源码]java毕业设计校园拓展活动管理系统
javascript算法之从会用到理解 - 数组反转
零基础学习大数据分析难吗?
基于bat脚本的前端发布流程的优化
- 原文地址:https://blog.csdn.net/gongfpp/article/details/125151958